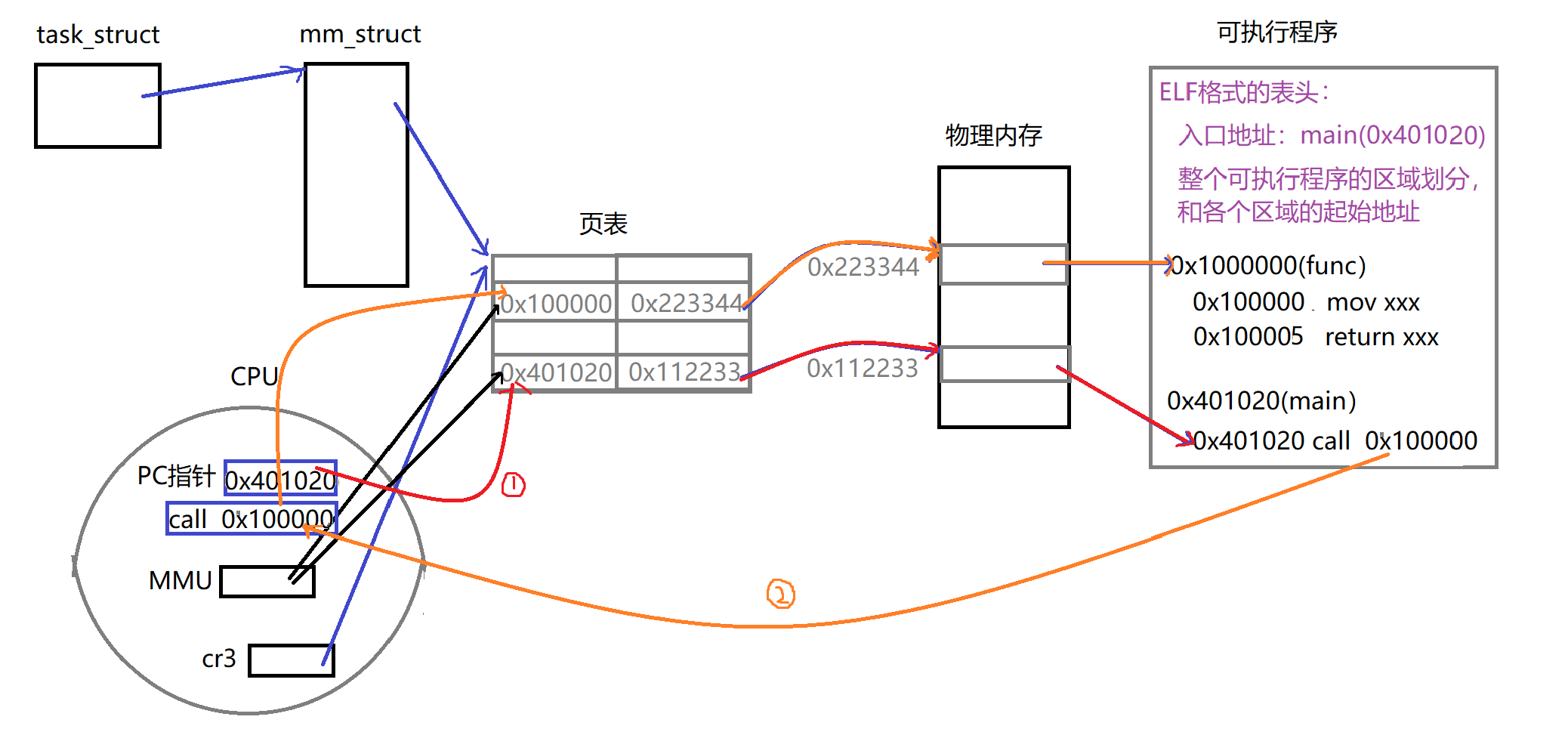
在大数据时代的浪潮中,MapReduce作为一种高效处理海量数据的编程模型,自其诞生以来便成为了数据处理领域的基石。本文旨在深入探讨MapReduce的基本原理、典型应用以及其在未来技术发展趋势中的展望,帮助读者更好地理解并应用这一关键技术。

一、MapReduce的基本原理
MapReduce由Google在2004年提出,其核心思想是将复杂的数据处理任务分解为两个简单的阶段:Map(映射)和Reduce(归约)。在Map阶段,输入数据被分割成多个小块,每个小块独立地在不同的节点上并行处理,生成一系列键值对作为中间结果。随后,在Reduce阶段,具有相同键的中间结果会被聚合到同一个节点上,进行合并处理,最终输出最终结果。
这种“分而治之”的策略极大地提高了数据处理的效率和可扩展性,使得MapReduce能够轻松应对PB级甚至EB级的数据处理需求。同时,MapReduce还通过抽象化底层细节,降低了并行编程的复杂度,使得开发者能够专注于业务逻辑的实现。
二、MapReduce的典型应用
- 大规模日志分析:在Web服务、电商平台等场景中,日志数据是宝贵的资源。MapReduce能够高效地处理这些海量日志,提取出用户行为、系统性能等关键信息,为产品优化、故障排查提供有力支持。
- 搜索引擎索引构建:搜索引擎需要对互联网上的海量网页进行索引,以便快速响应用户的查询请求。MapReduce能够并行化地处理网页数据,提取关键词、计算权重等,构建出高效、准确的索引库。
- 大数据分析:在金融、医疗、科研等领域,大数据分析已成为常态。MapReduce能够处理复杂的数据分析任务,如关联分析、聚类分析等,帮助发现数据背后的规律和趋势。
三、MapReduce的未来展望
尽管MapReduce在大数据处理领域取得了巨大成功,但随着技术的不断进步,它也面临着一些挑战和机遇。
- 性能优化:随着硬件性能的提升和新型存储技术的出现,如何进一步优化MapReduce的性能成为了一个重要课题。例如,通过引入更高效的调度算法、优化数据布局等方式,可以进一步提升MapReduce的并行处理能力和资源利用率。
- 与其他技术的融合:MapReduce正在与流处理、图计算、机器学习等技术深度融合,形成更加全面、强大的数据处理和分析能力。例如,将MapReduce与Spark等内存计算框架结合,可以显著提升数据处理的速度和效率。
- 云原生支持:随着云计算的普及和发展,云原生MapReduce服务逐渐成为主流。这些服务提供了更加灵活、便捷的数据处理解决方案,使得用户无需关心底层基础设施的搭建和维护,即可轻松实现大规模数据处理和分析。
总之,MapReduce作为大数据处理领域的基石之一,其重要性不言而喻。未来,随着技术的不断进步和应用场景的不断拓展,MapReduce将继续发挥其独特优势,为数据驱动的世界注入新的活力。同时,我们也期待看到更多创新性的技术和解决方案涌现出来,共同推动大数据处理和分析领域的发展。