目录
一、项目介绍
1、项目任务
2、评论信息内容
3、待思考问题
1)目标
2)输入字词格式
3)每一次传入的词/字的个数是否就是评论的长度
4)一条评论如果超过32个词/字怎么处理?
5)一条评论如果没有32个词/字怎么处理?
6)如果语料库中的词/字太多是否可以压缩?
7)被压缩的词/字如何处理?
二、项目实施
1、读取文件,建立词表
1)代码内容
2)部分内容拆分解析
3)代码运行结果
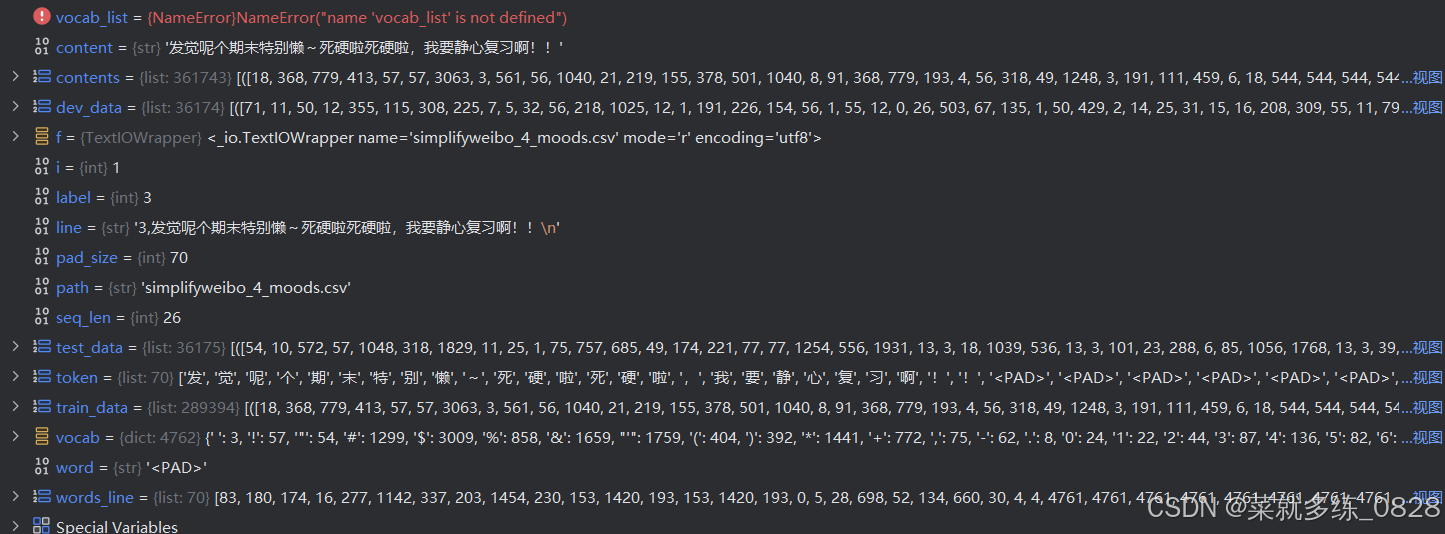
4)调试模式
2、评论删除、填充,切分数据集
1)代码内容
2)运行结果
3)调试模式
一、项目介绍
1、项目任务
对微博评论信息的情感分析,建立模型,自动识别评论信息的情绪状态。
2、评论信息内容
![]()

3、待思考问题
1)目标
将每条评论内容转换为词向量。
2)输入字词格式
每个词/字转换为词向量长度(维度)200,使用腾讯训练好的词向量模型有4960个维度,需要这个模型或者文件可私信发送。
3)每一次传入的词/字的个数是否就是评论的长度
应该是固定长度,如何固定长度接着看,固定长度每次传入数据与图像相似,例如输入评论长度为32,那么传入的数据为32*200的矩阵,表示这一批词的独热编码,200表示维度
4)一条评论如果超过32个词/字怎么处理?
超出的直接删除后面的内容
5)一条评论如果没有32个词/字怎么处理?
缺少的内容,统一使用一个数字(非词/字的数字)替代,项目中使用<PAD>填充
6)如果语料库中的词/字太多是否可以压缩?
可以,某些词/字出现的频率比较低,可能训练不出特征。因此可以选择频率比较高的词来训练,项目中选择4760个。
7)被压缩的词/字如何处理?
可以统一使用一个数字(非词/字的数字)替代,即选择了评论固定长度的文字后,这段文字内可能有频率低的字,将其用一个数字替代,项目内使用<UNK>替代
二、项目实施
1、读取文件,建立词表
1)代码内容
将下列代码写入命名为vocab_create.py的文件内,方便见名知义及调用内部函数
from tqdm import tqdm # 导入进度条函数
import pickle as pkl # 将序列化对象保存为一个二进制字节流文件
MAX_VOCAB_SIZE = 4760 # 词表长度限制长度,总共10000+个无重复的字
UNK,PAD = '<UNK>','<PAD>' # 未知字,padding符号 今天天气真好,我咁要去打球->今天天气真好,我<UNK>要去打球<PAD><PAD><PAD><PAD><PAD>
def build_vocab(file_path,max_size,min_freq): # 参数分别表示,文件地址、词表最大长度、剔除的最小词频数
"""函数功能:基于文本内容建立词表vocab,vocab中包含语料库中的字”"""
tokenizer = lambda x: [y for y in x] # 定义了一个函数tokenizer,功能为分字,返回一个列表,存放每一个字
vocab_dic = {} # 用于保存字的字典,键值对,键为词,值为索引号
with open(file_path,'r',encoding='UTF-8') as f: # 打开评论文件
i = 0
for line in tqdm(f): # 逐行读取文件内容,并显示循环的进度条
if i == 0: # 跳过文件中的第1行表头无用内容,然后使用continue跳过当前当次循环
i += 1
continue
lin = line[2:].strip() # 使用字符串切片,获取评论内容,剔除标签和逗号,不用split分割,因为评论内容中可能会存在逗号。
if not lin: # 如果lin中没有内容则continue,表示没有内容,跳过这一行
continue
for word in tokenizer(lin): # 遍历列表里的每一个元素,tokenizer(lin)将每一行的评论中的每个字符分成单独的一个,然后存入列表
vocab_dic[word] = vocab_dic.get(word,0)+1 # 统计每个字出现的次数,并以字典保存,字典的get用法,读取键word对应的值,如果没有读取到则将其值表示为0,这里的值表示出现次数,因为这里每出现一次值都加1,键独一无二,值可以相同
# 筛选词频大于1的,并排序字典中每个字的值的大小,降序排列,(拆分见下一条代码块)
vocab_list = sorted([_ for _ in vocab_dic.items() if _[1] > min_freq],key=lambda x:x[1],reverse=True)[:max_size] # 先通过for循环加if条件语句筛选出字典的值大于传入参数min_freq的键值对列表,然后对其排序,最后取出前max_size个元素
# 建立新的字典
vocab_dic = {word_count[0]:idx for idx,word_count in enumerate(vocab_list)} # 列表中存放每个元素是一个元组,元组里存放的是键值对的信息,将每个元组遍历出来,给予索引0的值一个索引,以此给每个字符打上索引值,返回一个字典
vocab_dic.update({UNK:len(vocab_dic),PAD:len(vocab_dic)+1}) # 在字典中更新键值对 {'<UNK>':4760,'<PAD>':4761}
print(vocab_dic) # 打印全新的字典
# 保存字典,方便直接使用
pkl.dump(vocab_dic,open('simplifyweibo_4_moods.pkl','wb')) # 此时统计了所有的文字,并将每一个独一无二的文字都赋予了独热编码,将上述的字典保存为一个字节流文件
print(f'Vocab size:{len(vocab_dic)}') # 将评论的内容,根据你现在词表vocab_dic,转换为词向量
return vocab_dic # 输入文件地址,对内部文件进行处理,设定最大长度,返回该文件里的所有独一无二的字符及其对应的索引的字典,其中包含两个填充字符及其索引,一个是填充未知字,一个是填充符号
"""词库的创建"""
# 此处设置下列判断语句来执行的目的是为了防止外部函数调用本文件时运行下列代码
if __name__ == '__main__': # 当自己直接执行本文件代码,会运行main,中的代码
vocab = build_vocab('simplifyweibo_4_moods.csv',MAX_VOCAB_SIZE,1)
print('vocab')
# 如果是调用本代码,则不会执行main中的代码2)部分内容拆分解析
vocab_list = sorted([_ for _ in vocab_dic.items() if _[1] > min_freq],key=lambda x:x[1],reverse=True)[:max_size]
vocab_list = [] # 空列表,存放元组形式的空列表
for a in vocab_dic.items(): # 遍历出来字典中的键值对,用a表示
if a[1] > min_freq: # 判断键值对的值是否大于min_freq
vocab_list.append(a)
vocab_list = sorted(vocab_list,key=lambda x:x[1],reverse=True) # 使用sorted函数排序,key表示排序的依据,使用匿名函数,并索引键值对的值排序,reverse为布尔值,是否降序
vocab_list = vocab_list[ : max_size] # 索引前max_size个值3)代码运行结果

4)调试模式


2、评论删除、填充,切分数据集
1)代码内容
将下列代码放入创建的文件名为load_dataset.py的文件中,后面还有代码需要往里增加
from tqdm import tqdm
import pickle as pkl
import random
import torch
UNK,PAD = '<UNK>','<PAD>' # 未知字,padding符号
def load_dataset(path,pad_size=70): # path为文件地址,pad_size为单条评论字符的最大长度
contents = [] # 用来存储转换为数值标号的句子,元祖类型,里面存放每一行每一个字的对应词库的索引、每一行对应的标签、每一行的实际长度70及以内
vocab = pkl.load(open('simplifyweibo_4_moods.pkl','rb')) # 读取vocab词表文件,rb二进制只读
tokenizer = lambda x:[y for y in x] # 自定义函数用来将字符串分隔成单个字符并存入列表
with open(path,'r',encoding='utf8') as f: # 打开评论文件
i = 0
for line in tqdm(f): # 遍历文件内容的每一行,同时展示进度条
if i == 0: # 此处循环目的为了跳过第一行的无用内容
i += 1
continue
if not line: # 筛选是不是空行,空行则跳过
continue
label = int(line[0]) # 返回当前行的标签,整型
content = line[2:].strip('\n') # 取出标签和逗号后的所有内容,同时去除前后的换行符
words_line = [] # 用于存放每一行评论的每一个字对应词库的索引值
token = tokenizer(content) # 将每一行的内容进行分字,返回一个列表
seq_len = len(token) # 获取一行实际内容的长度
if pad_size: # 非0即True
if len(token) < pad_size: # 如果一行的字符数少于70,则填充字符<PAD>,填充个数为少于的部分的个数
token.extend([PAD]*(pad_size-len(token)))
else: # 如果一行的字大于70,则只取前70个字
token = token[:pad_size] # 如果一条评论种的宁大于或等于70个字,索引的切分
seq_len = pad_size # 当前评论的长度
# word to id
for word in token: # 遍历实际内容的每一个字符
words_line.append(vocab.get(word,vocab.get(UNK))) # vocab为词库,其中为字典形式,使用get去获取遍历出来的字符的值,值可表示索引值,如果该字符不在词库中则将其值增加为字典中键UNK对应的值,words_line中存放的是每一行的每一个字符对应的索引值
contents.append((words_line,int(label),seq_len)) # 将每一行评论的字符对应的索引以及这一行评论的类别,还有当前评论的实际内容的长度,以元组的形式存入列表
random.shuffle(contents) # 随机打乱每一行内容的顺序
"""切分80%训练集、10%验证集、10%测试集"""
train_data = contents[ : int(len(contents)*0.8)] # 前80%的评论数据作为训练集
dev_data = contents[int(len(contents)*0.8):int(len(contents)*0.9)] # 把80%~90%的评论数据集作为验证数热
test_data = contents[int(len(contents)*0.9):] # 90%~最后的数据作为测试数据集
return vocab,train_data,dev_data,test_data # 返回词库、训练集、验证集、测试集,数据集为列表中的元组形式
if __name__ == '__main__':
vocab,train_data,dev_data,test_data = load_dataset('simplifyweibo_4_moods.csv')
print(train_data,dev_data,test_data)
print('结束')
2)运行结果

3)调试模式