学习链接
Linux文本处理器sed - B站视频
文章目录
- 学习链接
- 基础介绍
- 语法格式
- sed的处理过程
- sed的选项
- -n
- -e
- -f
- -r
- -i
- pattern的7种用法
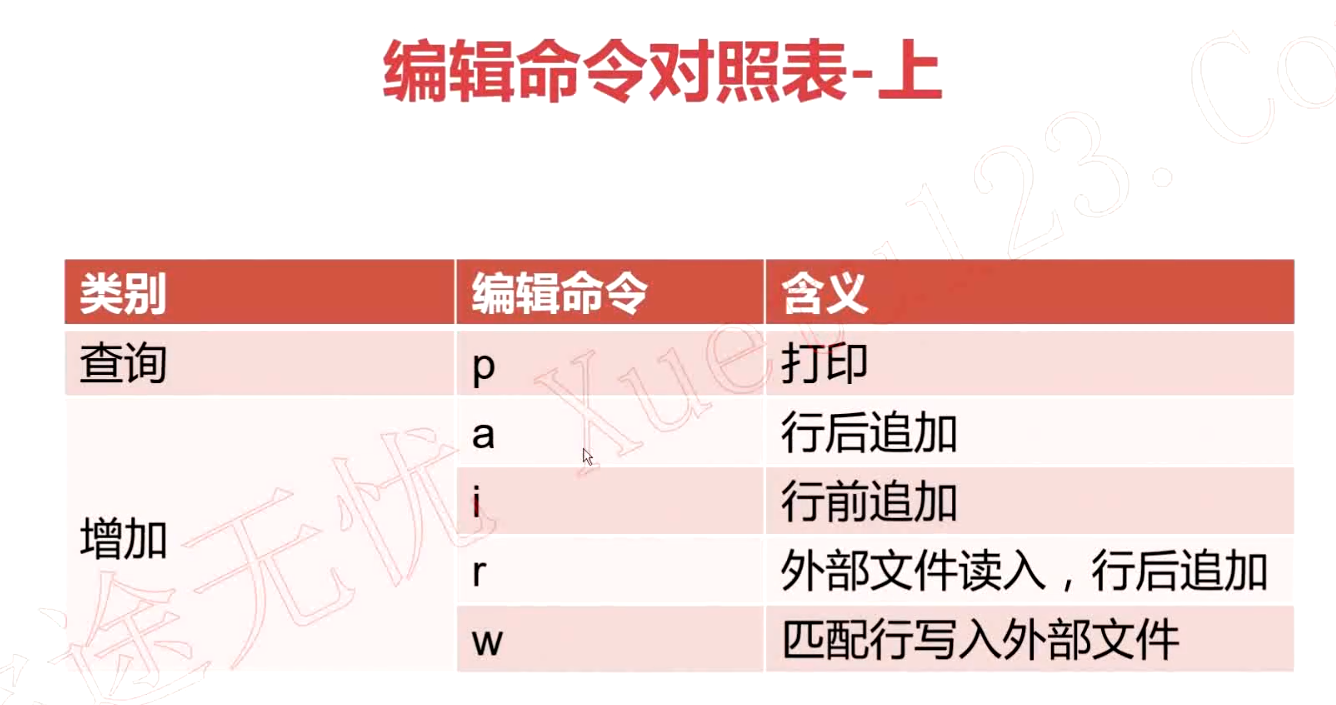
- sed中的编辑命令详解
- p 打印
- d 删除
- a 行后追加
- i 行前追加
- r 行后追加指定文件内容
- w 行追加到其它文件中
- 替换操作
- s/pattern/string
- s/pattern/string/g
- s/pattern/string/2g
- s/pattern/ig
- 行号
- 反向引用
- sed中引用变量注意事项
- 实战
- 利用sed查找文件内容
- 脚本练习
- 分析步骤
- 完成脚本
- 利用sed删除特定的内容
- 利用sed追加文件内容
基础介绍
sed(Stream Editor),流编辑器。对标准输出或文件逐行进行处理

可以对标准输出 或 文件 进行 修改字符串/删除该行 处理
工作模式:sed处理文本的时候,是逐行处理。会首先有个pattern来检查当前行是否匹配,如果该行匹配,那么对该行执行command编辑命令处理。如果该行不匹配,那么就不会对该行处理,而继续下一行。
语法格式

如果未指定pattern,那么会对每一行进行处理。
针对匹配 pattern 的每一行数据,进行 command处理。
sed的处理过程

sed的选项

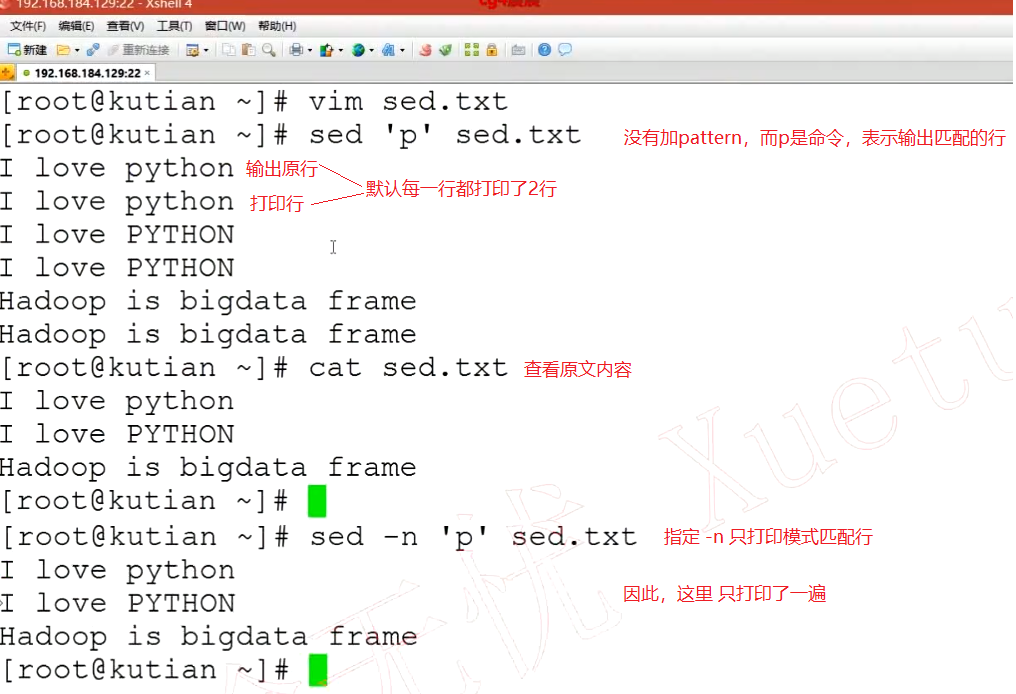
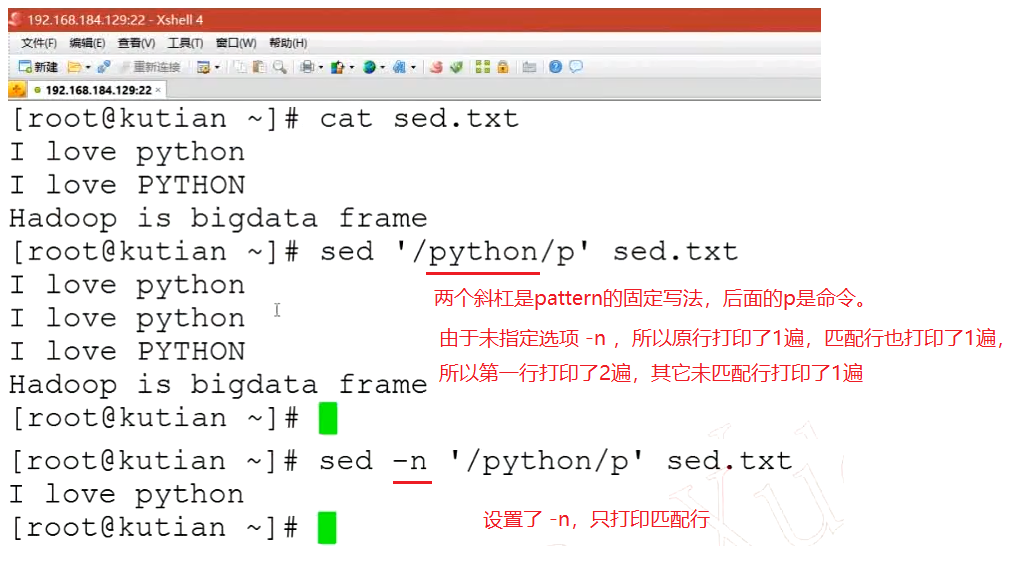
-n
只打印模式匹配的行
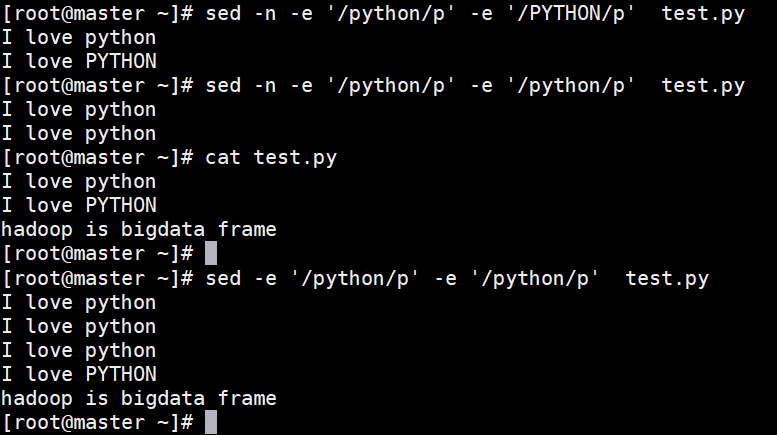
-e
表示直接在命令行进行sed编辑,默认选项
如果只有1个,那就可以不写-e,如果要处理多次,那就需要写-e

看看输入两次一样的会是什么效果
-f
sed的pattern和command可能特别长,所以可以把他们放到文件中,然后使用sed命令指定该文件作为pattern和command

-r
支持扩展正则表达式
使用-r指定支持扩展正则表达式

-i
-i,指定可以直接修改文件内容
未加-i

加了-i

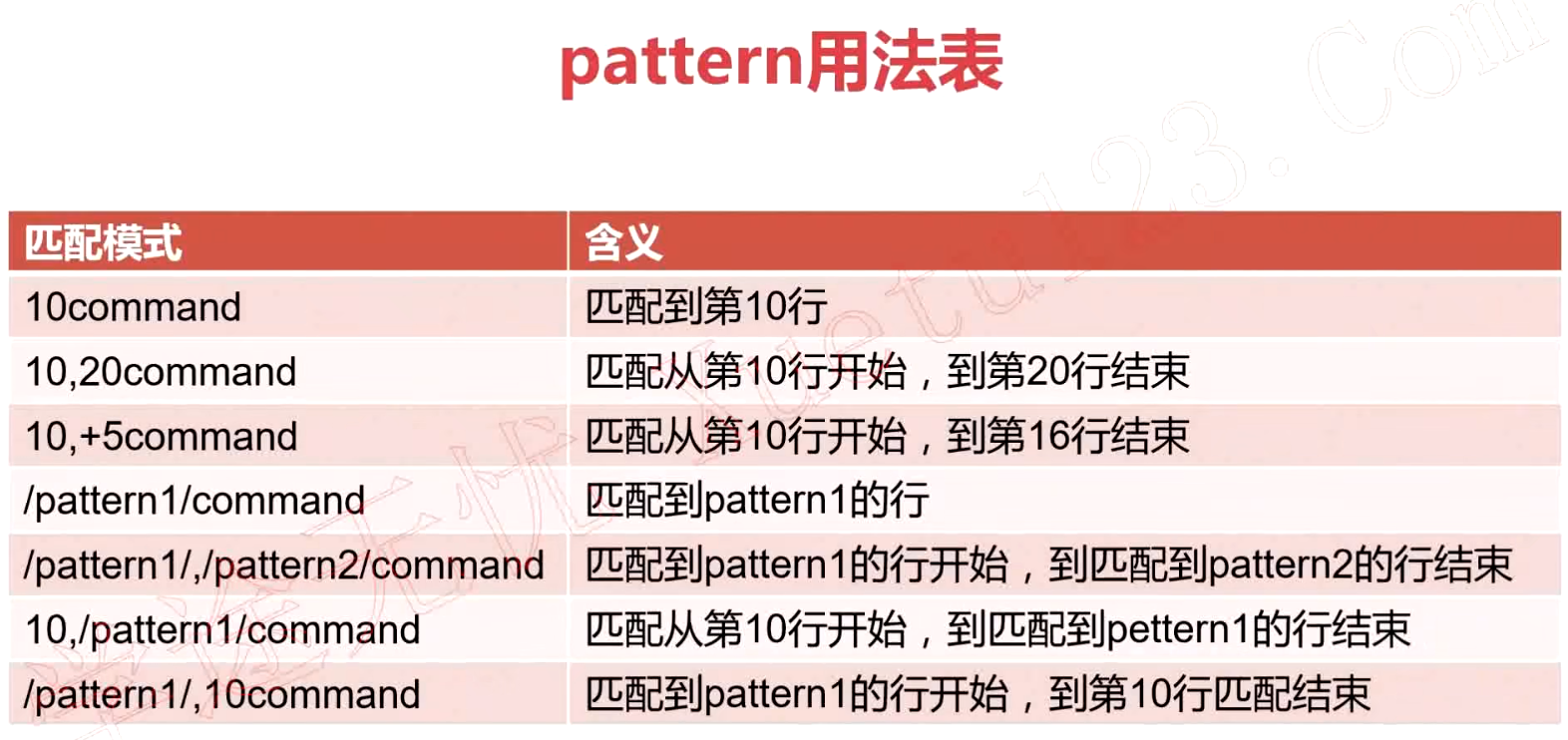
pattern的7种用法
注意:只有这7种用法


sed中的编辑命令详解


p 打印
就是将匹配到的行打印出来,前面已经演示过了。加上-n,只将匹配行输出
# 将包含 usr 的行输出
sed -n '/usr/p' passwd
d 删除
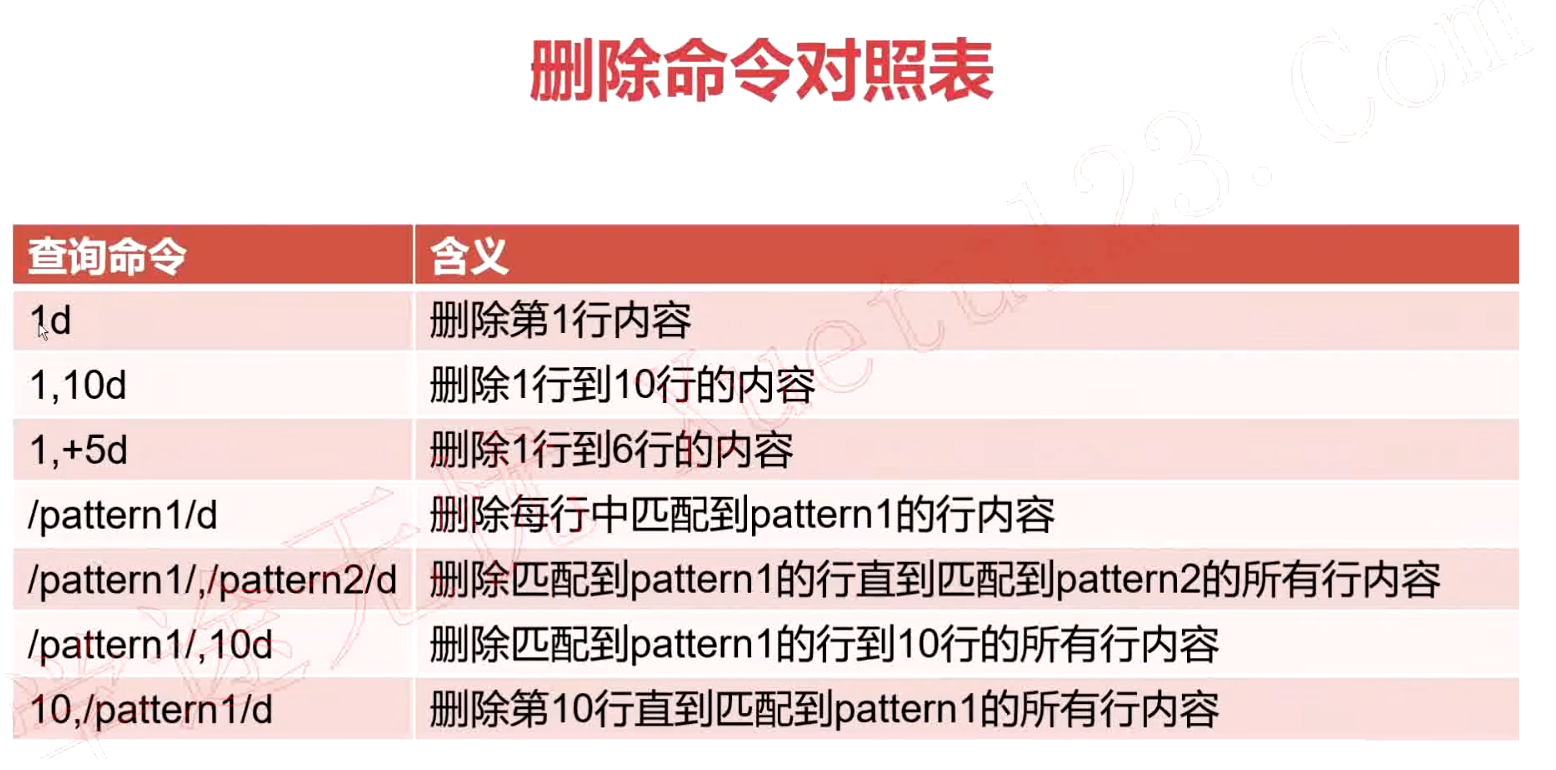
删除匹配的行
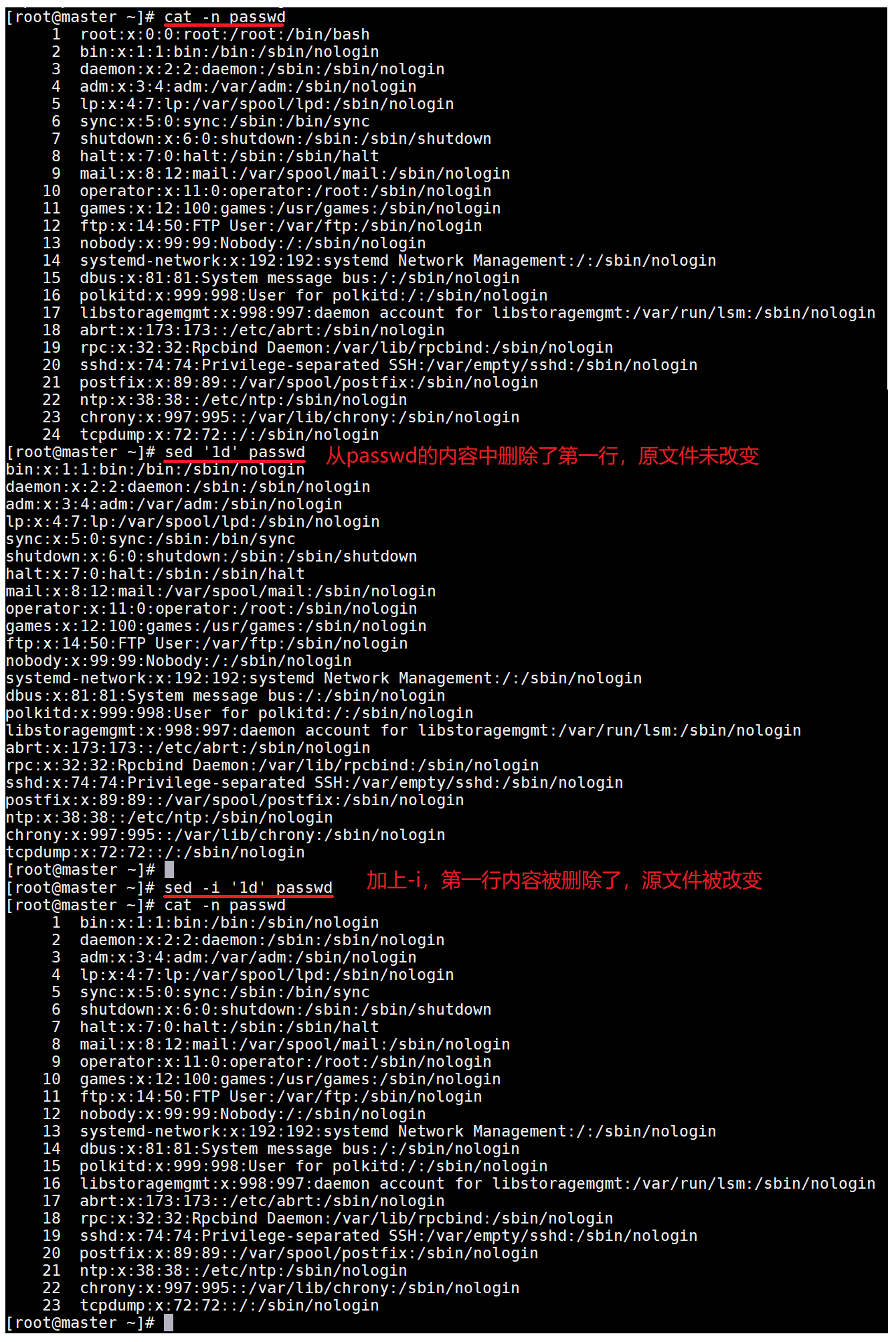
cat -n passwd
# 将第一行的内容删除并输出(不会修改原文件)
sed '1d' passwd
# 将第一行的内容删除, 原文件的第一行被删除(修改了原文件)
sed -i '1d' passwd
# 将原文件的第1行到第3行删掉
sed -i '1,3d' passwd
# 将匹配 /sbin/nologin的行删掉
sed -i '/\/sbin\/nologin/d' passwd
# 将删除匹配a的行到第2行, 如果第一行有a那就删除的是第1行和第2行并且继续找到匹配a的行删掉,直到结束。
# 如果第1行没有a, 那就继续找匹配a的行删掉,直到结束
sed -i '/a/,2d' test.txt
# 将删除从第2行到第一个匹配到a的行。如果最后一行就匹配a, 那就删除从第2行到末尾全部删除。如果最后一行不匹配a,那就删除从第2行到第一个匹配到a的行删除,后面不再继续删除。如果从第2行到最后一行都没有匹配到a的行,那就删除从第2行到末尾的所有行
sed -i '2,/a/d' test.txt
# 将以ftp开头的行开始到(最近的)以dfs开头的行结束之间所有行删掉,
# 然后继续找以ftp开头的行,到以dfs开头的行(假设说此时只找到了ftp开头的行,并未找到dfs开头的行,那么会把找到的ftp开头的行到末尾行全删掉)
sed -i '/^ftp/,/^dfs/d' passwd
...
a 行后追加
在匹配的行后,追加指定的内容
# 在包含/bin/bash的行后,追加指定的内容(注意下面a的后面有1个空格)
sed -i '/\/bin\/bash/a This is user who can login in system' passwd

i 行前追加
匹配到的行前追加内容

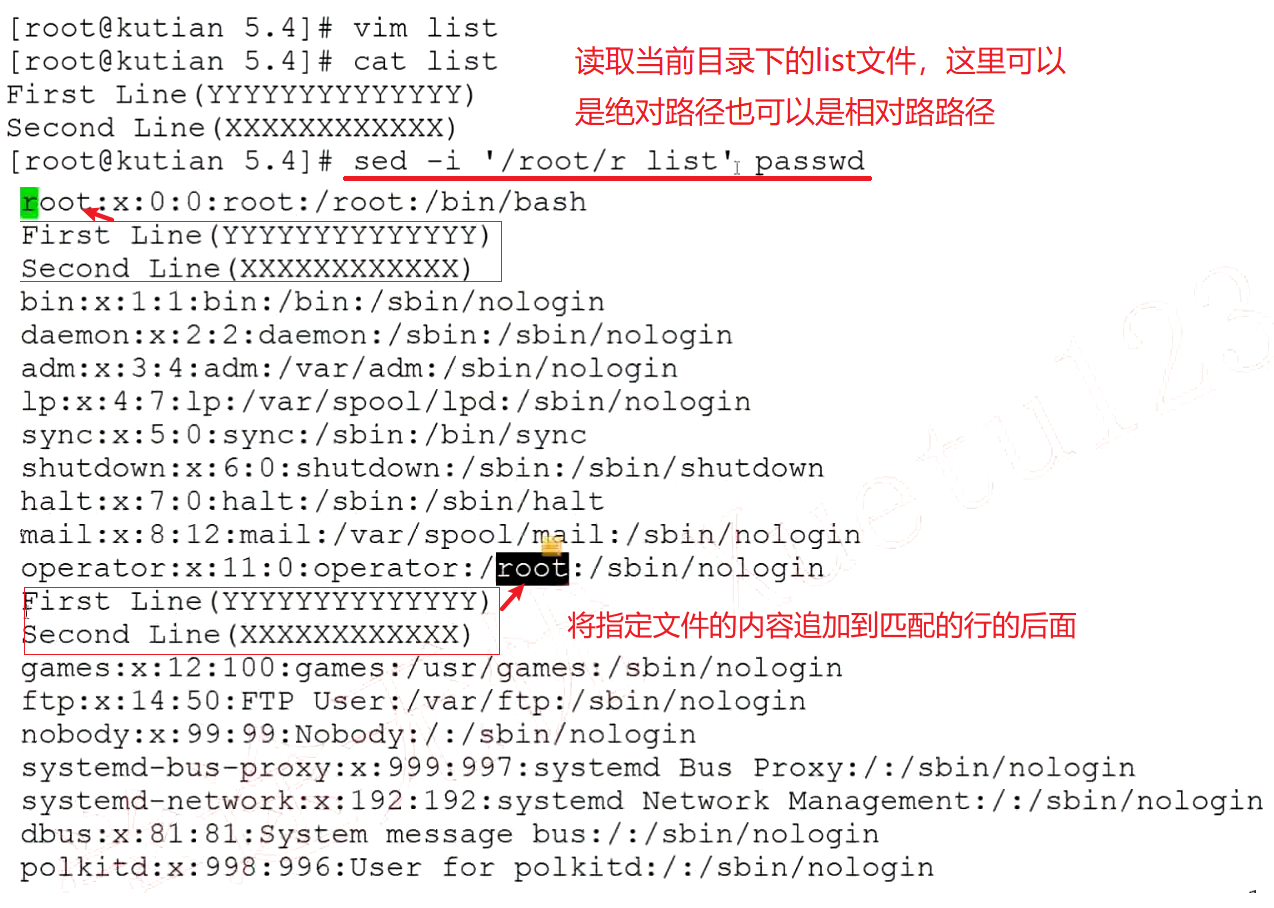
r 行后追加指定文件内容
将后面指定文件的内容追加到匹配到的行后面
sed -i '/root/r list' passwd
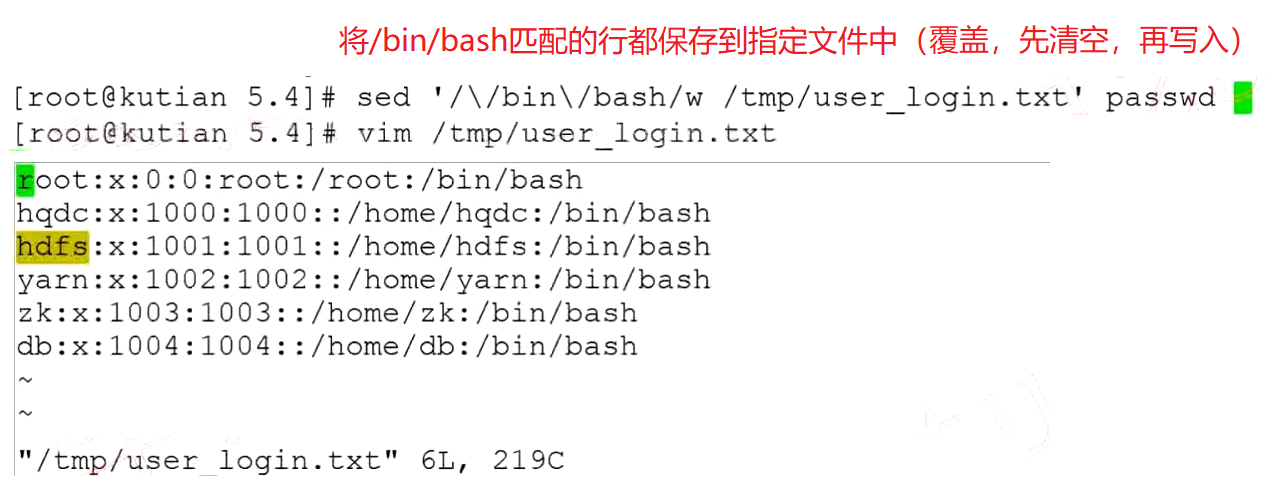
w 行追加到其它文件中
将匹配的行内容另存到其它文件中
# 终端会输出passwd的全部内容(效果与下面相同)
sed '/\/bin\/bash/w /tmp/user_login.txt' passwd
# 终端不会输出内容(效果与上面相同)
sed -n '/\/bin\/bash/w /tmp/user_login.txt' passwd
替换操作
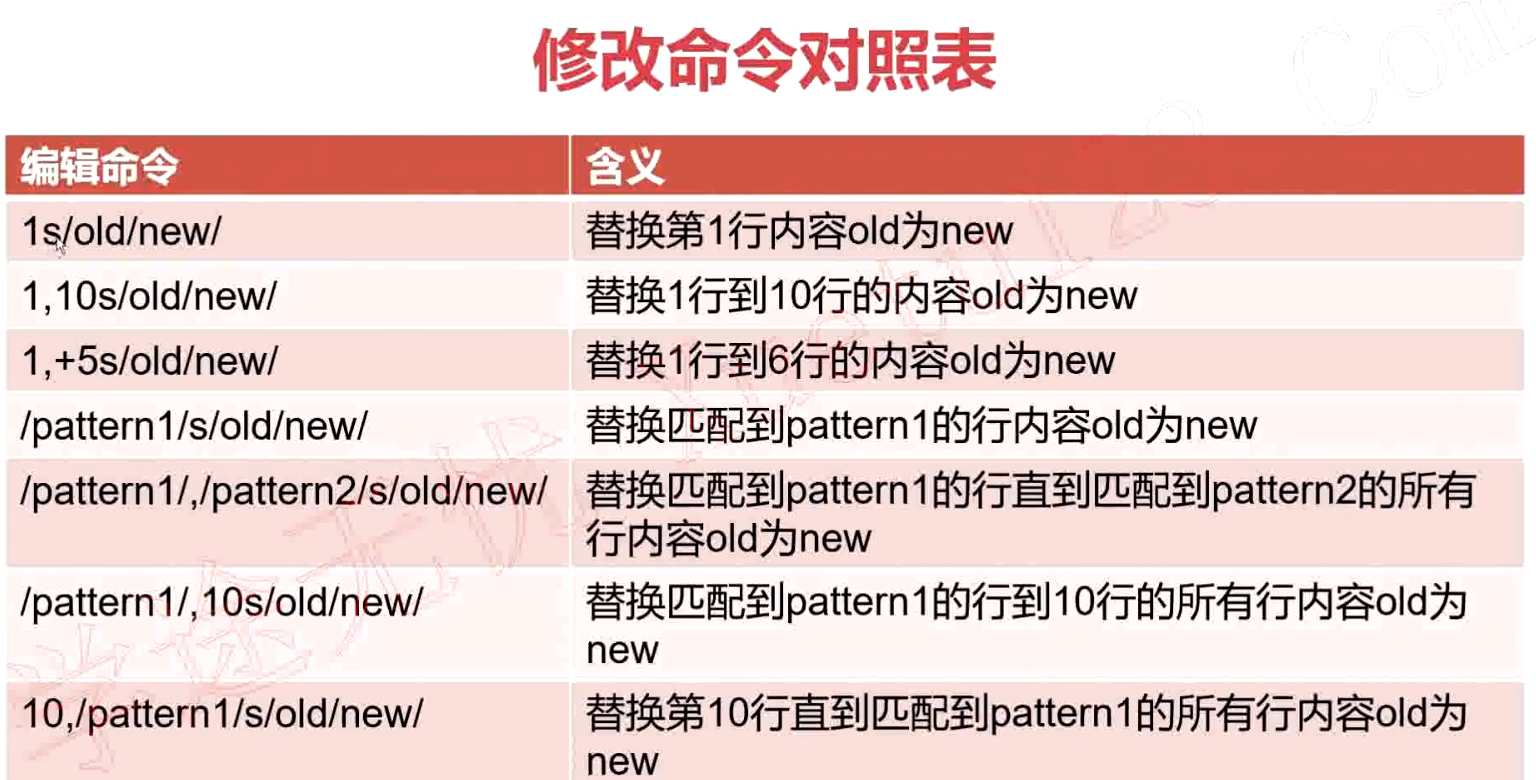

s/pattern/string
s/pattern/string/g
s/pattern/string/2g
注意pattern中如果有斜杠需要加上转义符号\
# 原文内容
[root@master ~]# cat test.txt
aaaaaaa
bbbbbbbb
ccccc
aaa
aaaaaa
# 第一个a替换为A
[root@master ~]# sed 's/a/A/' test.txt
Aaaaaaa
bbbbbbbb
ccccc
Aaa
Aaaaaa
# 每一行的第一个a替换为A
[root@master ~]# sed 's/a/A/1' test.txt
Aaaaaaa
bbbbbbbb
ccccc
Aaa
Aaaaaa
# 每一行的第2个a替换为A
[root@master ~]# sed 's/a/A/2' test.txt
aAaaaaa
bbbbbbbb
ccccc
aAa
aAaaaa
# 每一行的第3个a替换为A
[root@master ~]# sed 's/a/A/3' test.txt
aaAaaaa
bbbbbbbb
ccccc
aaA
aaAaaa
# 每一行的第4个a替换为A
[root@master ~]# sed 's/a/A/4' test.txt
aaaAaaa
bbbbbbbb
ccccc
aaa
aaaAaa
# 每一行的全部a替换为A
[root@master ~]# sed 's/a/A/g' test.txt
AAAAAAA
bbbbbbbb
ccccc
AAA
AAAAAA
# 每一行的第1个a及以后的a替换为A
[root@master ~]# sed 's/a/A/1g' test.txt
AAAAAAA
bbbbbbbb
ccccc
AAA
AAAAAA
# 每一行的第2个a及以后的a替换为A
[root@master ~]# sed 's/a/A/2g' test.txt
aAAAAAA
bbbbbbbb
ccccc
aAA
aAAAAA
# 每一行的第3个a及以后的a替换为A
[root@master ~]# sed 's/a/A/3g' test.txt
aaAAAAA
bbbbbbbb
ccccc
aaA
aaAAAA
s/pattern/ig
[root@master ~]# cat test.txt
adobeAdobeADoBe
AdoBeAdOBEadObE
adobeAdobEAdoBe
cccaaadoebadobe
[root@master ~]# sed 's/adobe/ADOBE/' test.txt
ADOBEAdobeADoBe
AdoBeAdOBEadObE
ADOBEAdobEAdoBe
cccaaadoebADOBE
[root@master ~]# sed 's/adobe/ADOBE/i' test.txt
ADOBEAdobeADoBe
ADOBEAdOBEadObE
ADOBEAdobEAdoBe
cccaaadoebADOBE
[root@master ~]# sed 's/adobe/ADOBE/1i' test.txt
ADOBEAdobeADoBe
ADOBEAdOBEadObE
ADOBEAdobEAdoBe
cccaaadoebADOBE
[root@master ~]# sed 's/adobe/ADOBE/2i' test.txt
adobeADOBEADoBe
AdoBeADOBEadObE
adobeADOBEAdoBe
cccaaadoebadobe
[root@master ~]# sed 's/adobe/ADOBE/3i' test.txt
adobeAdobeADOBE
AdoBeAdOBEADOBE
adobeAdobEADOBE
cccaaadoebadobe
[root@master ~]# sed 's/adobe/ADOBE/gi' test.txt
ADOBEADOBEADOBE
ADOBEADOBEADOBE
ADOBEADOBEADOBE
cccaaadoebADOBE
[root@master ~]# sed 's/adobe/ADOBE/1gi' test.txt
ADOBEADOBEADOBE
ADOBEADOBEADOBE
ADOBEADOBEADOBE
cccaaadoebADOBE
[root@master ~]# sed 's/adobe/ADOBE/2gi' test.txt
adobeADOBEADOBE
AdoBeADOBEADOBE
adobeADOBEADOBE
cccaaadoebadobe
[root@master ~]# sed 's/adobe/ADOBE/3gi' test.txt
adobeAdobeADOBE
AdoBeAdOBEADOBE
adobeAdobEADOBE
cccaaadoebadobe
行号
# 将匹配到的行号输出
sed -n '/\/sbin\/nologin/=' passwd
# 在匹配到的行前加1行, 内容是原来所在行的行号
sed -i '/root/=' passwd

反向引用

# 将每行中匹配到had..p正则的内容,替换为hadoops。(这种会改变掉原来的内容)
sed i 's/had..p/hadoops/g' str.txt

# 将每行中匹配到had..p正则的内容,替换为目标内容,并且使用&来指代原来的全部匹配的内容
sed i 's/had..p/&s/g' str.txt

# 使用 \1 来指代第一个括号中的内容(相比于&指代全部的内容更加灵活)
sed -i 's/\(had..ps\)/\1O/g' str.txt

# 使用 \1 引用前面指定序号的括号中匹配的内容
sed -i 's/\(had\)...../\1doop/g' str.txt

sed中引用变量注意事项

# 执行脚本后,内容没有被替换,这是因为使用的是单引号,其中的$xxx被视为普通字符串,而原文中并没有$符号,因此不会替换
sed -i 's/$old_str/$new_str/g' str.txt
sed -i "s/$old_str/$new_str/g" str.txt
sed -i 's/'$old_str'/'$new_str'/g' str.txt


实战
利用sed查找文件内容

脚本练习
完成对my.cnf文件的每个配置项的可以配置项数量的统计
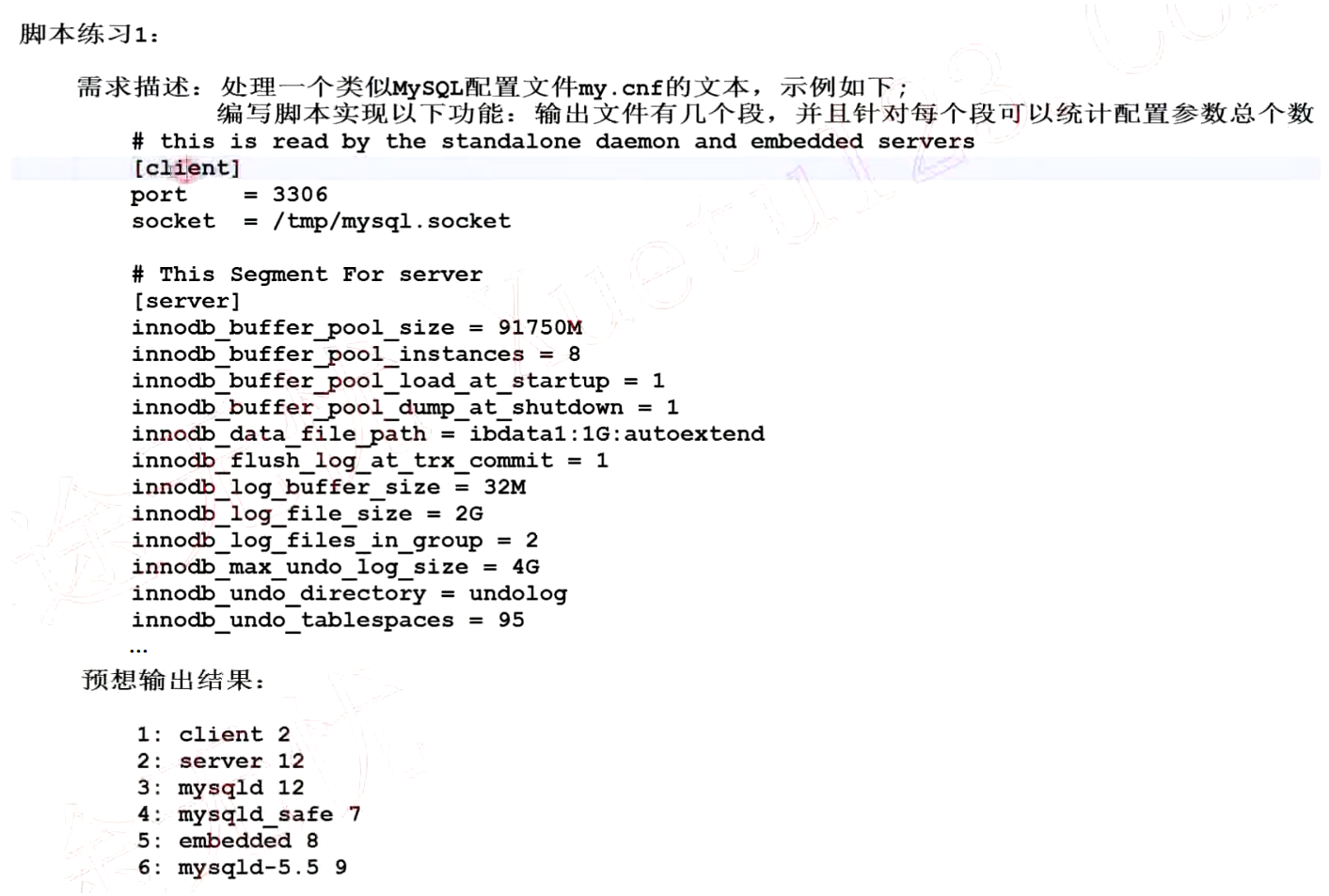
分析步骤
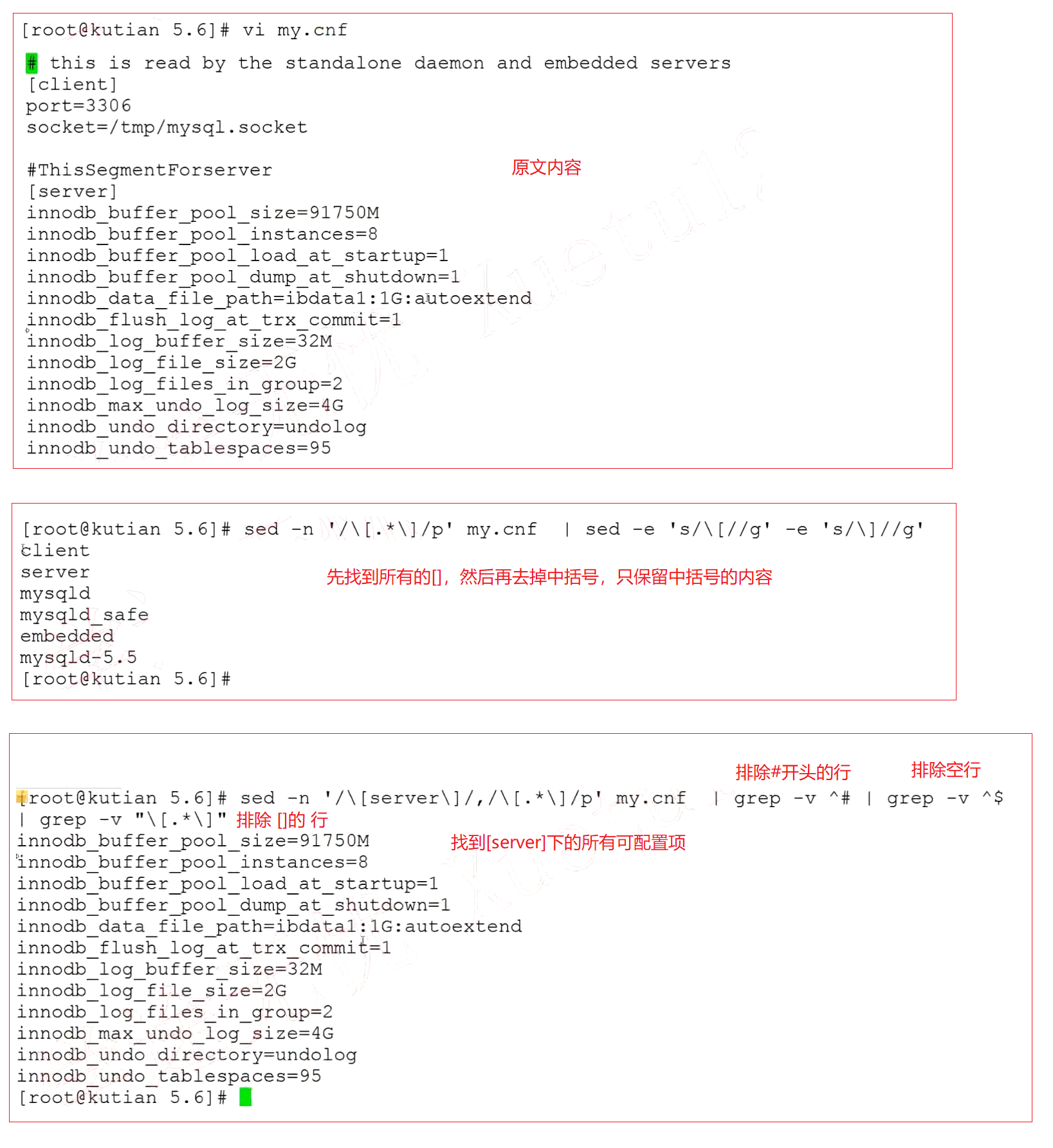
完成脚本

利用sed删除特定的内容

利用sed追加文件内容