一、考虑促销因素的医药电商平台需求预测研究

一、引言
1. 互联网+医疗健康的发展
- 内容:介绍了在互联网+的大背景下,医疗健康行业如何迅速发展,举例了1药网和叮当快药等平台提供的服务。
- 重点:互联网医疗用户规模和市场规模的快速增长,以及新冠疫情对需求的进一步推动。
2. 药品需求预测的挑战
- 内容:不同于其他快消品,医疗保健药品如中西药品、维生素钙剂或保健品都具有特定用药疗程(即服用周期),消费者在服用周期结束后可自行前往医院复诊,若病痛已根除则无需继续服用药品,药品的特殊属性导致其需求预测更具挑战性。
- 重点:需求预测中需要考虑药品的特殊属性,如服用周期。
3. 促销活动的复杂性
- 内容:描述了促销活动如何通过各种线上线下方式吸引消费者,并举例了大型促销活动如双十一、6·18。
- 重点:促销活动对销量的显著影响,以及促销信息对销量预测的重要性。
4. 现有研究的局限性
- 内容:总结了目前需求预测研究中考虑的因素,如价格策略、消费者行为、库存指标等。
- 重点:现有研究未充分考虑药品的服用周期和促销活动的复杂性。
5. 研究缺口和本文目标
- 内容:指出了医药电商平台需求预测领域的研究缺口,即缺乏考虑药品特性和促销活动的需求预测模型。本文旨在建立一个考虑药品服用周期和促销因素的需求预测模型。
二、模型建立
1. 模型建立的目的和方法
在已有文献的基础上,建立一个新的时间序列-机器学习组合预测模型,用于更准确地预测促销阶段的药品销量。
2. 时间序列模型
-
ETS模型(指数平滑模型):这是一个简单的时间序列预测方法,它通过给过去的数据赋予不同的权重(最近的权重高,之前的权重低)来预测未来的数据点。
通过对历史数据的指数平滑来预测未来的常规销量。
-
SARIMA模型(季节性自回归移动平均模型):这是一个更复杂的模型,它不仅可以处理
趋势和季节性变化,还可以处理数据中的不规则变化。这个模型适合用于预测那些具有明显周期性的数据,比如药品销量可能每周或每月都有固定的波动模式。
3.机器学习模型
文章中使用的机器学习模型是XGBoost模型。这是一个非常强大的预测工具,它通过构建多个决策树来进行预测。每棵树都会对数据进行分类,并给出一个分数。所有树的分数加起来就得到了最终的预测结果。
4. 为什么要使用组合模型
- 综合优势:时间序列模型擅长处理和预测时间相关的变化,而
机器学习模型擅长从复杂的数据中学习模式。将两者结合起来可以提高预测的准确性。 - 处理促销活动的影响:在电商平台上,促销活动对销量有很大影响。通过将促销变量纳入模型,可以更好地预测促销期间的销量变化。
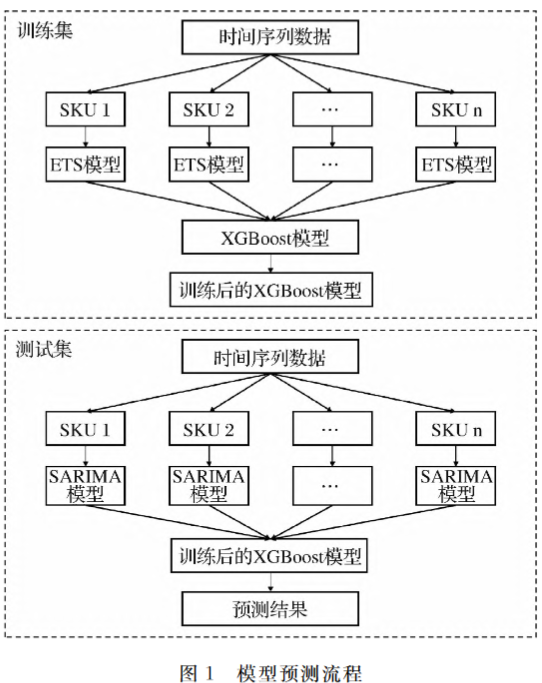
5.组合模型的工作流程
- 步骤1:将历史销售数据分为训练集和测试集。
- 步骤2:使用ETS模型来填补训练集中因促销活动导致的销量数据缺失。
- 步骤3:使用SARIMA模型来预测测试集中的常规销量。
- 步骤4:将预测出的常规销量与促销变量(如折扣和优惠券)一起输入到XGBoost模型中。
- 步骤5:XGBoost模型会对这些数据进行学习,并给出最终的销量预测结果。
根据提供的“数据预处理与特征工程”部分,以下是对内容的归纳总结,按照每一部分的内容和重点进行整理:
三、数据预处理与特征工程
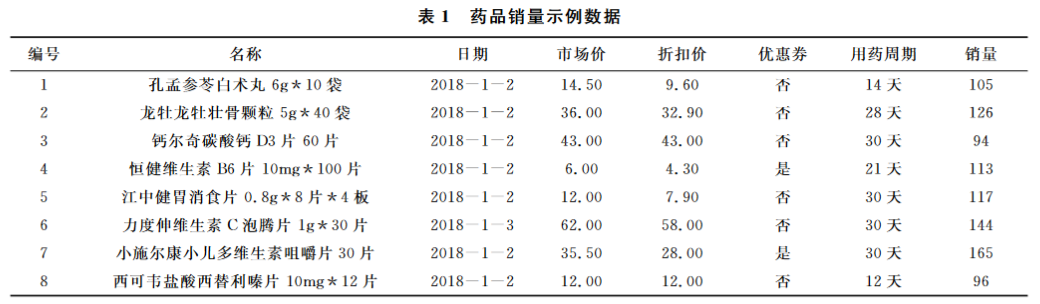
1. 数据收集与清洗
- 内容:收集了2018-2019年150个销量较高的SKU的医药电商销售数据,数据以天为单位统计,共获得101342条有效数据。
- 重点:数据经过清洗和异常值处理,以提高数据质量,为后续分析做准备。
2. 数据预处理
- 缺失值处理:通过查看时间序列前后规律填充或删除缺失数据。
- 异常值处理:使用四分位法识别并处理销量数据的异常值。
- 训练集与测试集划分:按8:2的比例划分数据,得到训练集81074条,测试集20268条。
3. 周期性检验
- 使用STL模型对150个SKU的常规销量按服用周期进行分解,检测销量的周期性波动。发现126个SKU销量呈周期性波动,其余24个无明显周期性,为选择适合的预测模型提供依据。
4. 特征工程
为更有针对性地研究药品特性和促销因素对医药电商销量的影响,本文仅将 SKU 编码同药品的常规销量,优惠券促销和折扣促销两种促销形式字段作为特征变量。将促销活动转化为可量化的特征,以便模型能够理解和利用这些信息进行预测。
-
提取了优惠券促销和折扣促销两种促销形式作为特征变量。
-
将优惠券促销数据二值化编码。
-
计算折扣促销力度作为特征。
-
特征重要度:计算了特征变量在XGBoost模型中的分裂节点使用次数,以评估特征的重要性。识别出对销量预测影响最大的特征,有助于优化模型性能。


四、结果分析
1. 数据集的划分与模型应用
- 将处理后的数据分为训练集(80%)和测试集(20%),使用ETS模型对训练集的常规销量进行拟合,再结合SARIMA模型和XGBoost模型进行预测。采用滚动预测法提升测试集常规销量的预测精确度,并将测试集中所有SKU的常规销量与促销特征变量一同输入XGBoost模型进行预测。

2. 预测结果对比与误差量化
- 使用MAE(平均绝对误差)和MAPE(平均绝对百分比误差)对模型预测效果进行量化衡量,并与经典预测模型的结果进行对比分析。组合模型在促销及非促销阶段的预测效果均优于其他模型,MAE和MAPE的降低表明了预测精度的显著提升。


3. 折扣力度对预测误差的影响
- 分析了不同折扣力度下各模型的需求预测误差,并对比了组合模型在不同折扣力度下的预测误差。组合模型在不同折扣力度下的预测误差均低于其他模型,显示出良好的适应性和准确性。


4. 促销因素对预测结果的影响
- 评估了促销变量对预测结果的影响,比较了剔除和未剔除促销变量的数据集的预测精度变化。包含促销变量的数据集获得了更优的预测结果,促销因素的加入显著降低了预测误差。

5. 数据共享策略对预测精确度的影响
- 探讨了数据共享策略对组合模型预测精确度的影响,比较了采用和未采用数据共享策略的模型预测误差。采用数据共享策略可以显著降低药品各销售阶段的需求预测误差,尤其是当折扣促销和优惠券促销同时发生时,预测误差可降低达18%。

五、结论
- 组合模型能够有效地处理促销活动带来的影响,提供了更准确的需求预测,对于医药电商行业的需求预测具有重要的实际应用价值。介绍了本文针对医药电商行业需求预测问题进行的研究,强调了考虑药品特性和促销活动影响因素的重要性。
1. 模型验证与比较
- 内容:对比了本文提出的组合模型与经典预测模型(改进指数平滑模型、SARIMA模型、XGBoost模型)在药品需求问题中的预测误差。组合模型在促销和非促销阶段的预测精度均优于其他模型,MAE和MAPE的显著降低证明了模型的有效性。
2. 促销模式下的预测精度
- 分析了折扣和优惠券两种促销模式下的预测精度,以及组合模型在这些模式下的优越性。组合模型在涉及折扣及组合促销模式下的预测精度显著优于XGBoost模型,强调了药品服用周期属性在提升预测精度中的作用。
3. 折扣力度与数据共享策略的影响
- 验证了不同折扣力度下组合模型的有效性,以及促销特征变量对预测精确度的正向作用。同时,探讨了数据共享策略对组合模型预测效果的影响。数据共享策略可显著降低药品各销售阶段的需求预测误差,尤其在组合促销时,预测误差可降低达18%。
二、基于推挽模型的生鲜直播销售影响因素:结构方程模型 (SEM) 和人工神经网络 (ANN) 相结合的两阶段方法

一、引言
- 直播销售的兴起:新冠疫情促使传统营销向社交媒体营销转变,直播销售成为热点,企业越来越重视社交媒体作为实时在线互动的新平台。
- 直播电商的优势:直播电商相比传统电商提高了购物的真实性、可视化、娱乐性和互动性,消费者可以通过主播的实时展示和互动减少心理距离和不确定性。
- 中国消费者的休闲时间:根据《2020年中国美好生活调查》报告,中国人每天平均有24分钟更多的休闲时间,近三分之一的人喜欢在休闲时间进行网上购物。
- 研究差距:现有研究主要关注传统电商中产品评论、价格和商家信息对销售的影响,而直播销售的
销售预测研究较少,这是学术界需要填补的空白。 - 研究目的:本研究旨在应用推拉理论,结合传统结构方程模型(SEM)和人工神经网络(ANN)方法,提出一种两阶段方法来预测直播销售的影响因素。
- 研究方法:研究从人-货-场视角出发,考虑了平台的外部吸引力、消费者的内部推动力和产品本身的特性等因素,并将“清洁标签”作为食品安全的重要指标纳入研究框架。
- 大数据与研究模型:研究结合推拉理论和直播电商的大数据,构建了一个研究模型,并基于直播电商数据进行模型和假设验证,提高了研究的可信度。
- 研究方法的优势:研究结合了SEM和ANN方法,不仅覆盖了线性关系的假设检验,还捕捉了神经网络模型中的非线性关系,解决了单一方法的局限性。
二、文献回顾和研究假设
1.推拉理论的起源和发展:
推拉理论(Push-Pull Theory)最初是由Everett Lee在1966年提出的,用于解释人口迁移现象。该理论认为,人们迁移的决策受到一系列“推因素”(Push Factors)和“拉因素”(Pull Factors)的影响。推拉理论后来被广泛应用于多个领域,包括国际教育流动、旅游决策、劳动力市场和电子商务等。
推因素(Push Factors)
推因素是指那些在原居住地产生的负面条件或驱动力,促使个人或群体产生迁移的动机。这些因素可能包括:
- 经济因素: 如高失业率、低收入水平、生活成本高等。
- 社会因素: 如社会不安全、种族或宗教歧视、社会动荡等。
- 环境因素: 如自然灾害、环境污染、资源匮乏等。
- 政治因素: 如政治压迫、战争、政治不稳定等。
推因素通常与原居住地的不利条件相关,它们“推动”人们离开自己的家园,寻找更有利的生活条件。
拉因素(Pull Factors)
拉因素是指那些在目的地产生的正面条件或吸引力,吸引个人或群体迁移。这些因素可能包括:
- 经济机会: 如更好的就业机会、更高的收入水平等。
- 社会福利: 如更好的教育和医疗资源、社会安全网等。
- 文化和生活方式: 如更吸引人的文化环境、生活方式、娱乐设施等。
- 家庭和社区联系: 如与家人或朋友团聚的机会。
拉因素通常与目的地的有利条件相关,它们“吸引”人们迁移到新的地区,以寻求更好的生活质量或实现个人目标。
在电子商务领域: 消费者可能会被在线购物的便利性(拉因素)所吸引,同时可能受到传统购物方式的不便(推因素)的推动。
推拉理论强调了决策过程中的多因素相互作用,为理解和预测人类行为提供了一个有力的工具。在直播电商的背景下,推拉理论可以帮助解释消费者为何选择在线观看直播并进行购买,以及哪些因素会增强或减少他们的购买意愿。
3.有机食品标签的影响:
-
清洁标签(Clean Label)成为食品行业的新趋势,反映了消费者对食品成分信息的关注。
-
Asioli 等人 (2017) 研究了
影响有机食品偏好的六个类别,包括社会文化因素、个人规范、营养属性等。 -
消费者对有机食品的偏好受到多种因素的影响,包括产品的营养特性、感官属性、可持续性和健康声明等。
-
直播销售的研究模型和假设:

- 提出假设1a和1b:商品视频数量和直播带货行为显著影响页面浏览量。
- 提出假设2a和2b:商品视频数量和直播带货行为显著影响直播销售。
- 提出假设3a和3b:平均停留时间显著影响页面浏览量和直播销售。
- 提出假设4a和4b:互动评论数量显著影响页面浏览量和直播销售。
- 提出假设5:页面浏览量显著影响直播销售。
- 提出假设6:清洁标签在页面浏览量和直播销售之间起到调节作用。
-
研究模型的细化:
- 研究模型考虑了
人-货-场三个方面的因素,包括平台的外部吸引力、消费者的内部推动力和产品特性。 - 将“清洁标签”作为一个重要的产品特性,认为它在理论上对消费者行为有特殊且不可或缺的作用。
- 研究模型考虑了
-
研究方法的应用:
- 研究结合了推拉理论和直播电商的大数据,使用结构方程模型(SEM)和人工神经网络(ANN)两种方法。
- 通过两阶段方法,首先使用SEM测试假设和建立理论模型,然后使用ANN捕捉非线性关系并进行预测。
三、研究方法和统计分析
1.数据来源和收集:
- 研究以抖音平台上的新鲜水果为研究对象,收集了2021年11月17日至12月17日连续30天的销售数据。
- 采用了随机抽样方法,以避免主观因素的影响,并最终确定了
460个有效数据项。
2.数据预处理:
- 研究模型包括七个变量:商品视频数量、直播带货行为数量、互动评论数量、平均停留时间、页面浏览量、清洁标签信息和直播销售额。
- 各变量的具体处理方法包括直接从抖音平台获取数据、从直播室页面获取互动评论数量、从产品页面获取页面浏览量和清洁标签信息,以及从产品页面获取直播销售额。
3.样本选择:
- 使用“Houyi Collector”工具从抖音平台收集数据,删除了240个下架产品后,保留了460个有效数据项。
- 样本大小超过了人工神经网络(ANN)分析的50倍规则-of-thumb最小样本大小要求,即对于六个ANN参数,最小样本大小应为300。
4.统计方法:
- 由于数据分布非正态,研究采用了偏最小二乘方差基础的结构方程模型(PLS-SEM),使用SmartPLS 3软件进行验证。
- 进行了单样本Kolmogorov-Smirnov检验和去趋势QQ图,发现数据非正态分布。
- 使用ANOVA测试判断了线性关系,发现页面浏览量、商品视频数量、直播带货行为数量和清洁标签与直播销售额存在线性关系,而平均停留时间和互动评论数量存在非线性关系。
- 评估了多重共线性,发现所有变量的方差膨胀因子(VIF)小于5,容忍度大于0.10,表明不存在多重共线性问题。
- 通过散点图和Levene检验验证了同方差性或方差齐性。
4.测量模型评估:
- 使用SmartPLS 3软件进行了内部负载和复合可靠性评估,确保了测量模型的可靠性和有效性。
- 计算了AVE、SRMR等指标,确认了测量模型的高结构可靠性。
5.结构模型评估:
- 进行了路径分析,发现11个路径中有8个显著,支持了部分研究假设。
- 评估了模型的拟合优度,使用了标准化根均方残差(SRMR)、未加权最小二乘法(duLS)和测地线差异(dG)等指标,结果显示模型具有良好的拟合度。
6.人工神经网络(ANN)分析:
- 使用FFBP多层感知器(MLP)神经网络进行非线性分析和预测,网络结构包括一个输入层、一个隐藏层和五个隐藏节点。
- 进行了十折交叉验证,使用S形激活函数激活输出和隐藏层,计算了训练集和测试集的均方根误差(RMSE),结果显示ANN模型具有良好的预测准确性和拟合度。

7.敏感性分析:
- 使用SPSS Statistics进行了敏感性分析,评估了每个预测变量对直播销售额的贡献,发现
页面浏览量是最重要的预测因素,其次是互动评论数量、直播带货行为数量、商品视频数量和清洁标签。
四、结论
1.研究结果:
- 研究采用了两阶段的SEM-ANN方法,结合了推拉理论和非线性神经网络模型,成功验证了文本对直播销售的影响因素。
- 发现互动评论数量、直播带货行为数量和商品视频数量对页面浏览量有显著影响,而平均停留时间对页面浏览量影响不大。
- 互动评论数量、直播带货行为数量、商品视频数量和页面浏览量对直播销售额有显著影响,但平均停留时间对直播销售额无显著影响。
- 清洁标签对直播销售额有直接影响,但对页面浏览量和直播销售额之间的关系没有显著的调节作用。
2.理论意义:
- 提供了直播销售的新实证贡献,特别是在消费者和商品市场角度的综合模型中。
- 将清洁标签变量纳入理论框架,发现了其对直播销售的直接和显著影响,为未来的研究提供了新的理论视角。
- 采用SEM-ANN方法进行预测分析,揭示了平均停留时间和互动评论数量与直播销售额之间的非线性关系,为研究者提供了新的方法论范式。
3.管理实践意义:
- 对于社交媒体平台、商家和主播来说,了解哪些因素影响直播销售至关重要。
- 商家应考虑如何增加产品曝光度和页面浏览量,因为它们是直播销售的重要预测因素。
- 互动评论数量和直播带货行为数量也是影响直播销售的重要因素,提示商家应促进更多的互动和信息共享。
- 清洁标签对消费者选择有重要影响,特别是在食品安全问题日益受到关注的背景下,供应链管理者应确保产品质量和供应链的透明度。
4.研究局限性:
- 研究基于中国消费者的数据,结果可能不适用于其他国家。
- 研究采用横截面方法,无法判断时间效应。
- 神经网络的激活函数仅限于S形函数,可能限制了分析结果。
- 神经网络模型的预测准确率为83.76%,考虑到研究模型的单一推拉理论,仍有改进空间。