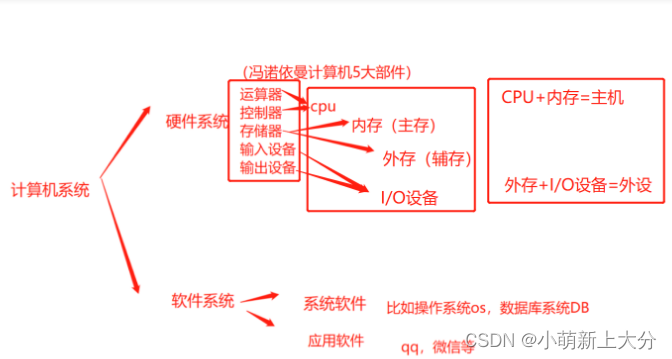
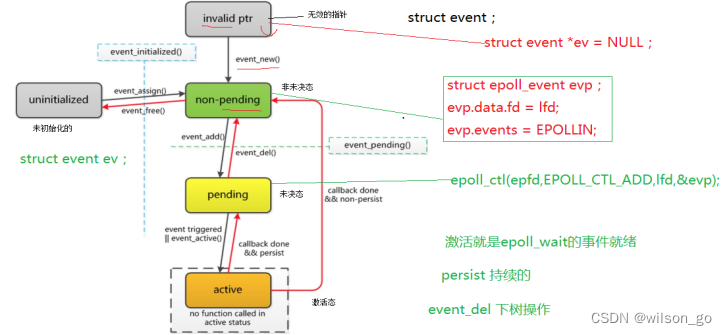
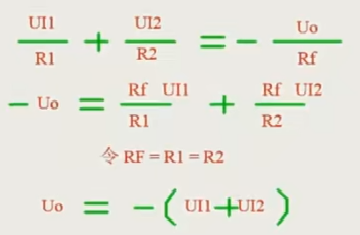
在使用mysql的过程中,经常会听到mysql具有数据恢复能力,当我们在业务开发中误删了某些数据后,可以将数据库恢复到误删之前的状态。同时还具有故障恢复能力,当数据库所在的机器突然掉电停机后,mysql也可以保证数据一致性。同时对数据库中事务比较了解的小伙伴也知道,在可重复读的事务隔离级别下,可以支持快照读。在赞叹mysql这么强大的能力时,你可曾想过他是怎么实现的吗?
其实上面这些功能实现的背后,都离不了日志的支持,接下来,我们来一起研究一下,mysql中有哪些日志,这些日志又是如何起作用的?
归档日志-binlog
用过mysql的老铁,多多少少都听说过binlog,binlog的使用范围比较广泛,例如在mysql的主从结构中,从库从主库同步数据,主要就是依靠binlog,上文中提到mysql的数据恢复能力,也是利用binlog实现的。
binlog是mysql中server层的日志模块,与具体的存储引擎:Innodb、MyISAM没有关系。因为binlog是server层的日志,所以日志记录的主要是逻辑层面的内容,比如"给ID=1这一行中的a字段加1","将ID=2这一行数据删除"等,和被操作的数据存放的数据页,物理地址无关。
除此之外,binlog是一直追加写的,当日志文件大小达到一定阈值后,会进行切割,在一个新的文件中继续写。
基于数据库的备份情况以及binlog的保存时间,我们可以将数据库的状态恢复到允许时间范围内的任意时刻。具体来说,DBA会定时的将数据库进行整库备份,可以是一天一备,也可以是一周一备,这个主要取决于系统中数据的重要性,同时在此期间,binlog也会一直保存。
当我们需要将数据库恢复到指定的某一秒时,比如某天下午2点发现上午12点误删了表,需要找回被删除的数据,我们可以按照如下的步骤进行数据恢复:
1.找到距离该天上午12点最近的一次数据备份,并将这个备份恢复到临时库中。
2.从备份的时间点开始,将binlog日志取出进行回放,直到误删表的那一时刻。
此时临时库就恢复到了数据被删除前的状态。

重做日志-redo log
redo log又叫重做日志,可能有些老铁会比较好奇,为什么叫做重做日志呢?重做的内容又是什么呢?接下来我们一起看一下redo log的使用场景,以及它的工作机制。
redo log是存储层中的日志模块,而且是Innodb特有的,因为他是存储层的日志,日志主要记录 “某个数据页上做了什么修改” ,包含了具体的数据页地址,是一个物理层面日志,这是redo log和binlog最明显的差异。
除此之外,redo log可以看做是一个环形缓冲区,有大小的限制,当缓冲区写满后,会对之前写过的区域进行覆盖。和我们平常接触的内存缓冲区不同的是,redo log是有4个1GB大小的文件组成。

redo log使Innodb具备故障恢复的能力,下面我们举例解释一下,redo log是如何实现故障恢复的。
我们在mysql中进行写操作的流程大概如下,为了方便解释,我们以"对ID=2这一行中的C字段进行加1"为例。
1.执行器调用存储层读接口:获取ID=2这一行的数据。存储层负责找到该行数据并返回给执行器,存储层所做的事情具体如下:如果ID=2这一行数据所在的数据页已经存在于内存中了,那么直接从内存中取出,并返回。如果不在内存中,那么引擎直接通过聚簇索引搜索该行数据(此处以Innodb为例),然后将该行所在数据页加载到内存中,同时将该行数据返回给执行器。
2.执行器拿到该行数据后,将该行数据中的C字段进行加1操作,得到新的一行数据,然后调用存储引擎层的写接口,将新数据进行写入。
3.引擎层接收到新的数后,将新的数据更新到内存中,同时将更新操作记录到redo log中,日志内容为:将数据页P中的ID为2的数据行内容更新为N+1,然后整个更新操作就算完成了。
在上面描述的过程中,有几个问题需要说明一下:
1.在3中更新操作,只更新了内存和redo log并没有将最新数据更新到磁盘上的数据页中
此时ID=2这一行数据所在数据页,在内存中是最新的数据,而在磁盘中是旧数据,也就是该数据页在内存和磁盘中的状态是不一致的,此时,我们称内存中的数据页为脏页。
2.内存中脏页,何时更新到磁盘中的数据页?
这里的脏页所占用的内存空间被称为change buffer(有没有很熟悉,不熟悉的化,可以参考"面试官问:普通索引和唯一索引该怎么选择?"),当channge buffer内存压力比较大的时候,默认使用率超过75%,会启动刷脏页操作,其次当redo log空间写满时,也会启动刷脏页,然后更新环形缓冲区中的checkpoint位置(check point位置之前的空间可以使用,之后的位置不能被使用)。
3.以上数据更新过程中,如果没有redo log 好像也没有什么问题?
如果一切操作都是正常的话,写redo log这个操作的确可以省略。但是谁又能保证服务永远不出问题呢?我们先假设上面3中,没有写redo log步骤,数据的写操作只更新内存,我们都知道,内存这种存储介质存储的数据不够稳定,当系统掉电后,内存中的数据就会丢失,那么内存中脏页上的更新就丢失了,这个是不可被接受的。为了保证数据不丢失,只能在更新内存后,同时更新磁盘,这样可以保证每次更新操作都落盘,保证了较高的可用性,但是这样会牺牲写性能,因为每次写盘,需要找到要写的位置,然后再写,是一种随机写操作,性能较低,如果是机械磁盘,效率更低。
而使用redo log 可以很好的解决这个问题,虽然redo log也是写磁盘,但是采用的是顺序写的方式,相比随机写性能较高。写入到redo log后,即使系统掉电,脏页中的数据丢失,更新的数据也不会丢,因为在mysql重启后,会通过回放 redo log中的日志,将业务层面的更新 “重做” 一遍(到这里终于知道为啥redo log叫重做日志了吧),来保证数据的完整性。
到这里,相信大家对binlog 和 redo log的认识应该更深一些了吧,不过细心的老铁可能会有一个疑问:在一个写操作的过程中,如果binlog写成功redo log写失败,或者redo log写成功binlog 写失败的情况下,使用binlog同步数据的从库就和使用redo log的主库的数据就不一致了?
是的,但是mysql在设计的时候也想到了这个问题,关于这个问题的具体方案,以及undo log(回滚日志),我们放在下一篇文章中来做说明。