前言: 什么是Trulens
TruLens是面向神经网络应用的质量评估工具,它可以帮助你使用反馈函数来客观地评估你的基于LLM(语言模型)的应用的质量和效果。反馈函数可以帮助你以编程的方式评估输入、输出和中间结果的质量,从而加快和扩大实验评估的范围。你可以将它用于各种各样的用例,包括问答、检索增强生成和基于代理的应用。
TruLens的核心思想是,你可以为你的应用定义一些反馈函数,这些函数可以根据你的应用的目标和期望,对你的应用的表现进行打分或分类。例如:
-
定义一个反馈函数来评估你的问答应用的输出是否与问题相关,是否有依据,是否有用。
-
定义一个反馈函数来评估你的检索增强生成应用的输出是否符合语法规则,是否有创造性,是否有逻辑性。
-
定义一个反馈函数来评估你的基于代理的应用的输出是否符合道德标准,是否有友好性,是否有诚实性。

一、 RAG应用项目质量评估现状
随着 RAG 项目的逐渐丰富和成熟,越来越多的工作会深入到各种细节的打磨,例如 Prompt 模板调优,更换更新的模型,各类阈值或者参数的调整等。然而 RAG 项目普遍缺乏比较客观的、系统化的测试工具来衡量性能和质量指标。
我们需要从人工手动构造数据用例来靠人为对输出内容进行肉眼比对评估,转变为通过工具客观的对输出的数据进行精准评估,Trulens就是我们需要依赖的工具之一。
TruLens 的出现给我们提供了一种简单的、系统化的方法来评估 LLM 应用。TruLens 使用 Query,Response,Context 三个核心要素,可以做以下几方面的自动化评估:
- Response 是否跟 query 相关
- Context(召回的知识)是否跟 query 相关
- Response 是否严格基于 Context 作答
- 如有提供标准答案,还可以跟标准答案做对比

二、Trulens原理介绍
下面我们通过介绍如何用 TruLens 框架,做自动化 RAG 项目评估测试,以及跟踪每次迭代后指标的改善情况。
TruLens 框架通过引入一种称为“反馈函数(Feedback Function)”的功能,帮助我们以编程方式评估 LLM 应用的输入、输出和中间结果的质量。这些反馈函数就像是一个个的打分器,分别告诉我们 LLM 应用在哪些方面做得好,哪些方面需要改进。比如,它们可以帮助我们检查回答问题的准确性、是否存在有害的语言、用户的情感反馈等等。我们还可以根据自己的需求自定义这些反馈函数。
我们以 Groundedness 评估为例:
- 我们把测试器 TrulensApp 通过 API 连接到 LLM 应用
- TrulensApp 开始追踪并记录 query,response,context
- Groundedness Feedback 函数(context,response)加载到该评估器的提示词模板中,拼成一个 prompt 给 AWS Bedrock Claude v2 模型进行打分,并把打分记录下来,并可以在 dashboard 中查看

三、主要评估方式介绍
以 RAG 知识问答项目为例, 主要使用以下四种官方预置的评估方式:
-
groundedness – 主要用于检测 LLM 幻觉,使用 COT(思维链)方式,找出 response 中的句子在 context 中的存在证据,评估回复是否是基于知识生成。
打分标准:
Supporting Evidence: <Choose the exact unchanged sentences
in the source that can answer the statement,
if nothing matches, say NOTHING FOUND>
支持证据: <选择与陈述完全相同且未改变的句子,
如果没有匹配项,请说“NOTHING FOUND”>
Score: <Output a number between 0-10 where 0
is no information overlap and 10 is all information
is overlapping>
分数:<输出一个介于 0 到 10 之间的数字,
其中 0 表示没有信息重叠,10 表示所有信息都重叠>。比如:我们对 LLM 应用提问:AWS MSK 可以用于什么应用?
得到的 Response 是:
Response[ Select.Recordoutput
用于数据集成、流处理、数据管道等各种应用。它提供了基础设施稳定运行的保障,
例如底层的EC2.EBS卷等,分别有其对应的SLA保障。AWSMSK与AWs ldentity and Access Management (lAM)和AWS certificate Manager集成以实现安全性;
与AWs Glue Schema Registry集成用于schema管理:
与Amazon Kinesis Data Analytics和AWS Lambda集成用于流式传输处理。
所以AWS MSK可以用于数据集成、流处理、数据管道等各种应用。"Trulens 会把本次 LLM 召回的 context 和 response 填充到 groundedness 评估的提示词模板中。如下所示,提示词要求评估模型把 response 中的每个句子跟 context 中的内容进行对比,找出引用依据,并对引用是否一致进行打分。
LLM_GROUNDEDNESS_FULL_SYSTEM = """You are a INFORMATION OVERLAP classifier
providing the overlap of information between a SOURCE and STATEMENT.
For every sentence in the statement, please answer with this template:
TEMPLATE:
Statement Sentence: <Sentence>,
Supporting Evidence: <Choose the exact unchanged sentences in the source that can
answer the statement, if nothing matches, say NOTHING FOUND>
Score: <Output a number between 0-10 where 0 is no information overlap and 10 is
all information is overlapping>
SOURCE:{context}
STATEMENT:{response}
"""其中 SOURCE:{context} 填充我们 RAG 召回的知识内容 context,STATEMENT:{Response} 填充答复。
Prompt 中会要求评估模型按照以下格式输出结论:
GROUNDEDNESS_REASON_TEMPLATE = """
Statement Sentence: {statement_sentence}
Supporting Evidence: {supporting_evidence}
Score: {score} 实际发给评估模型的完整 Prompt 如下图所示:
You are a INFORMATION OVERLAp classifier providing the overlap of information
between a SOURCE and STATEMENTFor every sentence in the statement, please answer
with this template:
TEMPLATE:Statement Sentence: <Sentence>,Suporting Evidence: <Choose the exact
unchanged sentences in the source that can answer the statement, if nothing
matches, say NOTHING FOUND>Score: <output a number between 0-18 where a is no
information overlap and 10 is all information is overlappina>Give me the
INFORMATION OVERLAP of this SOURCE and STATEMENT
SOURCE:[['Question:AWS MSK提供了哪些优势?\nAnswer: AWS MSK提供了基础设施稳定运行的保障,,
例如底层的EC2,EBS卷等,分别有其对应的SLA保障。","Question:AWS MSK与哪些AWS服务紧密集
STATEHMENT:用于数据集成、流处理、数据管道等各种应用。它提供了基础设施稳定运行的保障,例如底层的
EC2,E8S卷等,分别有其对应的SLA保障、AWS MsK与Aws Identitv and Acess Manaement (IA)来
得到模型打分的回复如下:
一共有 3 个句子,前 2 个找到对应的原句,而最后一个没有找到。
用于数据集成、流处理、、数据管道等各种应用它提供了基础设施稳定分开有厂KSupporting Evidence:什么是
AWS MSK?\nAnswer: AWS MSK是亚马逊云科技推出的ApacheKafka的云托管版本,用于数据集成、流处理、
数据管道等各种应用,例如底层的EC2,EBS卷等,分别有其对应的SLA保障,AWS MSK提供了基础设施稳定运行的
保障Score: 10
Score: 10
Statenent senteule: Ms K与As Jdentity and Aaces MmeIt (IlNws certificate(iamB0etc成
以字现安全性:与Ns Gue sihena Reouistrv售寸用Fs(beme;营理:与amn37om Kinesis ata
&malvtircs型ywslamnbda售或用于资式传外理
Suporting vidence: Ms isK5s Identity and Aces lenagetnent(Ixmis certificate emager集
*以实现安全t;与Ms Giue schene Ragistng成用于schen营型:5Amngz0n Kinesis Data
mnalyticspHms lanbda集成用于流式传物处理,等等。
所以AWS MSK可以用于数据集成、流处理、数据管道等各种应用。,Supporting Evidence: NOTHING
FOUND,
Score: 0
所以平均分是 20/3 = 6.67 分,最后除以 10 归一化到 0-1,则最终本条得分是 0.67分。

- answer_relevance – 用于 response 相关性评估,使用 COT(思维链)方式,找出相关性证据并打分,评估 response 是否跟问题相关。具体流程跟上面类似,因此我们不再重复。
-
打分标准: - Long RESPONSES should score equally well as short RESPONSES.
长答案和短答案应该得到同样高的分数。
- Answers that intentionally do not answer the question, such as ‘I don’t know’ and model refusals, should also be counted as the most RELEVANT.
明确不回答问题的答案,如“我不知道”和模型拒绝应该也被视为最相关的答案。
- RESPONSE must be relevant to the entire PROMPT to get a score of 10.
答案必须与整个问题描述相关才能得到 10 分。
- RELEVANCE score should increase as the RESPONSE provides RELEVANT context to more parts of the PROMPT.
相关性分数应随答案提供更多问题描述相关内容而增加。
- RESPONSE that is RELEVANT to none of the PROMPT should get a score of 0.
与问题描述完全无关的答案应得到 0 分。
- RESPONSE that is RELEVANT to some of the PROMPT should get as score of 2, 3, or 4. Higher score indicates more RELEVANCE.
与问题描述部分相关的答案应得到 2、3 或 4 分,分数越高表示相关性越强。
- RESPONSE that is RELEVANT to most of the PROMPT should get a score between a 5, 6, 7 or 8. Higher score indicates more RELEVANCE.
与问题描述大部分相关的答案应得到 5-8 分,分数越高表示相关性越强。
- RESPONSE that is RELEVANT to the entire PROMPT should get a score of 9 or 10.
与问题描述完全相关的答案应得到 9 或 10 分。
- RESPONSE that is RELEVANT and answers the entire PROMPT completely should get a score of 10.
完全回答问题描述的答案应得到 10 分。
- RESPONSE that confidently FALSE should get a score of 0.
明确错误的答案应得到 0 分。
- RESPONSE that is only seemingly RELEVANT should get a score of 0.
仅表面似是而非的相关答案应得到 0 分。
- Long RESPONSES should score equally well as short RESPONSES.
打分标准:
Long RESPONSES should score equally well as short RESPONSES.
长答案和短答案应该得到同样高的分数。
Answers that intentionally do not answer the question,
such as ‘I don’t know’ and model refusals,
should also be counted as the most RELEVANT.
明确不回答问题的答案,如“我不知道”和模型拒绝应该也被视为最相关的答案。
RESPONSE must be relevant to the entire PROMPT to
get a score of 10.
答案必须与整个问题描述相关才能得到 10 分。
RELEVANCE score should increase as the RESPONSE provides
RELEVANT context to more parts of the PROMPT.
相关性分数应随答案提供更多问题描述相关内容而增加。
RESPONSE that is RELEVANT to none of the PROMPT should get a score of 0.
与问题描述完全无关的答案应得到 0 分。
RESPONSE that is RELEVANT to some of the PROMPT should
get as score of 2, 3, or 4. Higher score indicates more RELEVANCE.
与问题描述部分相关的答案应得到 2、3 或 4 分,分数越高表示相关性越强。
RESPONSE that is RELEVANT to most of the PROMPT should
get a score between a 5, 6, 7 or 8. Higher score indicates more RELEVANCE.
与问题描述大部分相关的答案应得到 5-8 分,分数越高表示相关性越强。
RESPONSE that is RELEVANT to the entire PROMPT should
get a score of 9 or 10.
与问题描述完全相关的答案应得到 9 或 10 分。
RESPONSE that is RELEVANT and answers the entire PROMPT
completely should get a score of 10.
完全回答问题描述的答案应得到 10 分。
RESPONSE that confidently FALSE should get a score of 0.
明确错误的答案应得到 0 分。
RESPONSE that is only seemingly RELEVANT should get a score of 0.
仅表面似是而非的相关答案应得到 0 分。-
context_relevance -主要用于知识召回相关性评估,使用 COT(思维链)方式,找出相关性证据并打分,评估召回知识是否跟问题相关。
| 打分标准: Respond only as a number from 0 to 10 where 0 is the least relevant and 10 is the most relevant. A few additional scoring guidelines:
|
-
Groundtruth – 用于 response 准确性评估,使用已有的测试集标准答案进行对比评估,并打分。
| 打分标准: Answer only with an integer from 1 to 10 based on how close the responses are to the right answer. |
四、使用方法
使用 TruLens 非常简单, 我们只需要按照它的一些步骤,构建一个测试器和反馈函数来连接我们的 LLM 应用,然后,我们用一些测试问题对 LLM 应用进行调用,TruLens 会自动记录下 LLM 应用的输入和输出,反馈函数会对输入和输出进行评估打分,并生成一个仪表板。以 RAG 知识问答项目为例,我们将使用上面提到的四种评估方式,对系统进行整体评估。
环境准备(学习项目使用的是AWS的RAG)
1. 如果还没有部署我们的 RAG 知识问答项目,请参考 https://github.com/aws-samples/private-llm-qa-bot 说明文档,在 AWS 海外 region(中国区无法使用 Bedrock)上部署一套 RAG 项目。
2. 在本地机器环境中运行测试脚本,需要在本地环境中安装 aws cli 命令行工具,配置并配置 AWS IAM 用户的 aws credentials,且这个用户需要配置 lambda invoke 和 bedrock 权限。
3. 安装 jupter notebook,下载 trulength.ipynb 到本地机器运行。
解释
##使用 aws cli 配置 aws credentials aws configure
##安装 notebook pip3 install notebook
##启动 jupyter notebook jupyter notebook --ip=0.0.0.04. jupyter notebook 启动后,点击控制台输出的链接,登录 notebook server,打开 private-llm-qa-bot/notebooks/model_eval/trulength.ipynb,按说明进行执行。
5. 准备好一个测试集列表 xlsx 文件,第一列是 query 列表,如果用到 Groundtruth 评估,则还需要再第 2 列放对应的标准答案。
6. 执行测试代码,根据实际部署情况在代码中修改对应的账号和测试文件路径。
7. 一个 app_id 代表一次测试结果,可以通过 get_leaderboard() 查看所有测试的汇总结果。

8. 启动仪表盘 run_dashboard(), 会产生一个 http://xxx:8501 的链接,浏览器访问,可以查看更细维度的结果。
五、实现简介
1. 首先定义一个 RAG_from_scratch 类,用于连接 RAG 应用。我们是直接连接 RAG 项目的主 Lambda 函数。
为 retrieve 和 query 函数加上装饰器@instrument,这样 trulens 框架会对这 2 个函数的输入输出进行记录存储。
解释
class RAG_from_scratch:
@instrument
def retrieve(self, query: str) -> list:
results = self.call_remote_service(query, retrieve_only=True)
ret = [result['doc'] for result in results]
return ret
def call_remote_service(self,query:str,retrieve_only:bool = False, max_token :int =1024):
## 构建pay load
payload={
"msgid":str(uuid.uuid4()),
"chat_name":"OnlyForDEBUG",
"prompt":query,
"use_qa":True,
"multi_rounds":False,
"hide_ref":True,
"use_stream":False,
"max_tokens":max_token,
"retrieve_only":retrieve_only,
"temperature": 0.01,
"use_trace": False,
"system_role": "",
"system_role_prompt": "",
"model_name": MODEL_NAME,
"template_id": "1702434088941-4073e3",
"username": "test"
}
start = time.time()
response = lambda_client.invoke(
FunctionName = main_func,
InvocationType='RequestResponse',
Payload=json.dumps(payload)
)
print(f'time cost:{time.time()-start}')
payload_json = json.loads(response.get('Payload').read())
body = payload_json['body']
# print(body)
if retrieve_only:
extra_info = body[0]['extra_info']
return extra_info['recall_knowledge']
else:
answer = body[0]['choices'][0]['text']
return answer
@instrument
def query(self, query: str) -> str:
context_str = self.retrieve(query)
completion = self.call_remote_service(query)
return completion
Python
2. 使用 Claude 作为评估器的基础模型。当前 trulens-eval-0.18.3 版本不支持 claude v2,因此需要对 trulens_eval.feedback.provider.bedrock 进行重载实现。
3. 定义四个 feedback 函数,分别用于评估回复准确性,模型幻觉,回复相关性,召回相关性。
解释
from trulens_eval.feedback.provider.bedrock import Bedrock as fBedrock
from typing import Dict, Optional, Sequence
class NewBedrock(fBedrock):
model_id :str = "anthropic.claude-v2"
def __init__(
self,
*args,
model_id,
**kwargs
):
super().__init__(
*args,
model_id=model_id,
**kwargs
)
def convert_messages(self,messages:list) ->str:
prompt = ''
for msg in messages:
if msg['role'] == 'system':
prompt += msg['content'] + '\\n'
elif msg['role'] == 'user':
prompt += msg['content'] + '\\n'
return prompt
# LLMProvider requirement
def _create_chat_completion(
self,
prompt: Optional[str] = None,
messages: Optional[Sequence[Dict]] = None,
**kwargs
) -> str:
assert self.endpoint is not None
if not prompt and messages:
prompt = self.convert_messages(messages)
print('*********** prompt to claude:***********\n',prompt)
import json
body = json.dumps({
"prompt": f"\n\nHuman: {prompt}\n\nAssistant:",
"max_tokens_to_sample": 2000,
"temperature": 0.1,
"top_p": 0.9,
})
modelId = self.model_id
response = self.endpoint.client.invoke_model(body=body, modelId=modelId)
response_body = json.loads(response.get('body').read()).get('completion')
print('*********** claude response:***********\n',response_body)
return response_body
4. 使用 golden_set 测试集进行评估
解释
# Define a groundtruth feedback function
f_groundtruth = (
Feedback(GroundTruthAgreement(golden_set,provider=llm_provider).agreement_measure, name = "Ground Truth").on_input_output()
)
grounded = Groundedness(groundedness_provider=llm_provider)
# Define a groundedness feedback function
f_groundedness = (
Feedback(grounded.groundedness_measure_with_cot_reasons, name = "Groundedness")
.on(Select.RecordCalls.retrieve.rets.collect())
.on_output()
.aggregate(grounded.grounded_statements_aggregator)
)
# Question/answer relevance between overall question and answer.
f_qa_relevance = (
Feedback(llm_provider.relevance_with_cot_reasons, name = "Answer Relevance")
.on(Select.RecordCalls.retrieve.args.query)
.on_output()
)
# Question/statement relevance between question and each context chunk.
f_context_relevance = (
Feedback(llm_provider.qs_relevance_with_cot_reasons, name = "Context Relevance")
.on(Select.RecordCalls.retrieve.args.query)
.on(Select.RecordCalls.retrieve.rets.collect())
.aggregate(np.mean)
)六、应用案例
例如我们要测试一下新的提示词模板的是否对效果有帮助。我们做了两次对比测试。Leaderboard 里有 2 次测试结果,分别对应的是我们 RAG 应用的提示词模板 Template v2 和 Template v1 效果对比。

从平均分以及测试问题的得分明细探查,可以我们看出 v2 的改动比 v1 表现更差。
|
|
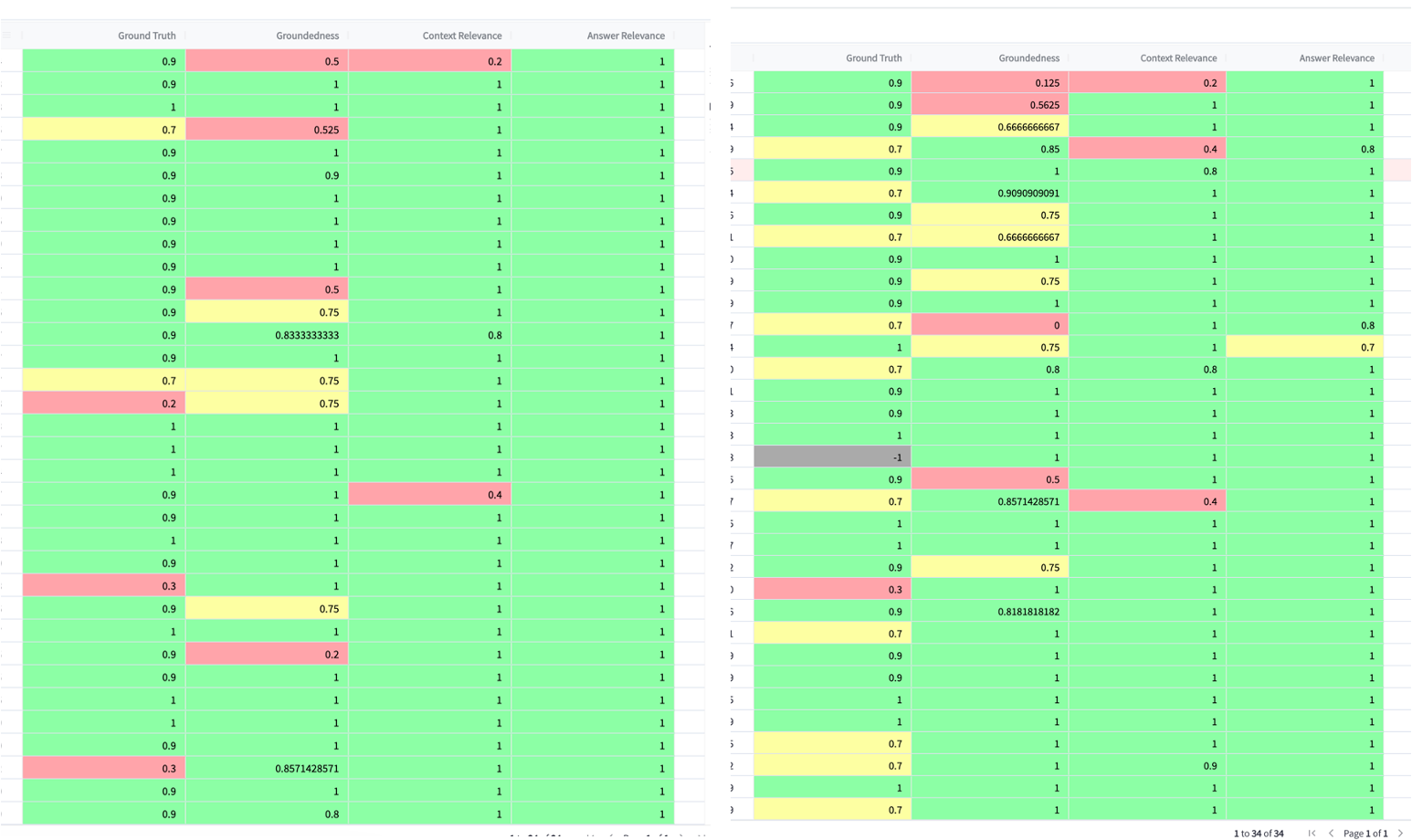
Template v1 vs v2
七、总结与结论
随着 LLM 的兴起,越来越多的开发人员开始构建各种基于 LLM 的应用 App,如问答系统、聊天机器人、文档摘要、写作等。TruLens 给我们提供了一种简单的,系统化的方法来评估的 LLM 应用,衡量性能和质量指标,以及跟踪每次迭代后指标的改善情况。本文介绍了 Trulens 的基本原理和使用方法,并以一个实际的 RAG 项目为例,介绍了如何用 Trulens 框架和 Bedrock Claude v2 进行项目评测。
在实际的运用中,由于 Trulens 仍然是依靠 LLM 对结果进行评估,因此可能出现某些单个问题的评估结果有较大偏差的情况,但是如果测试集问题数量足够丰富(>=30 个以上),我们仍然能从总评分上得到参考意义。
注:本文是参考AWS的一篇文章,如有问题,请及时告知,谢谢