
文章链接:https://arxiv.org/pdf/2409.12957
项目链接:https://3dtopia.github.io/3DTopia-XL/
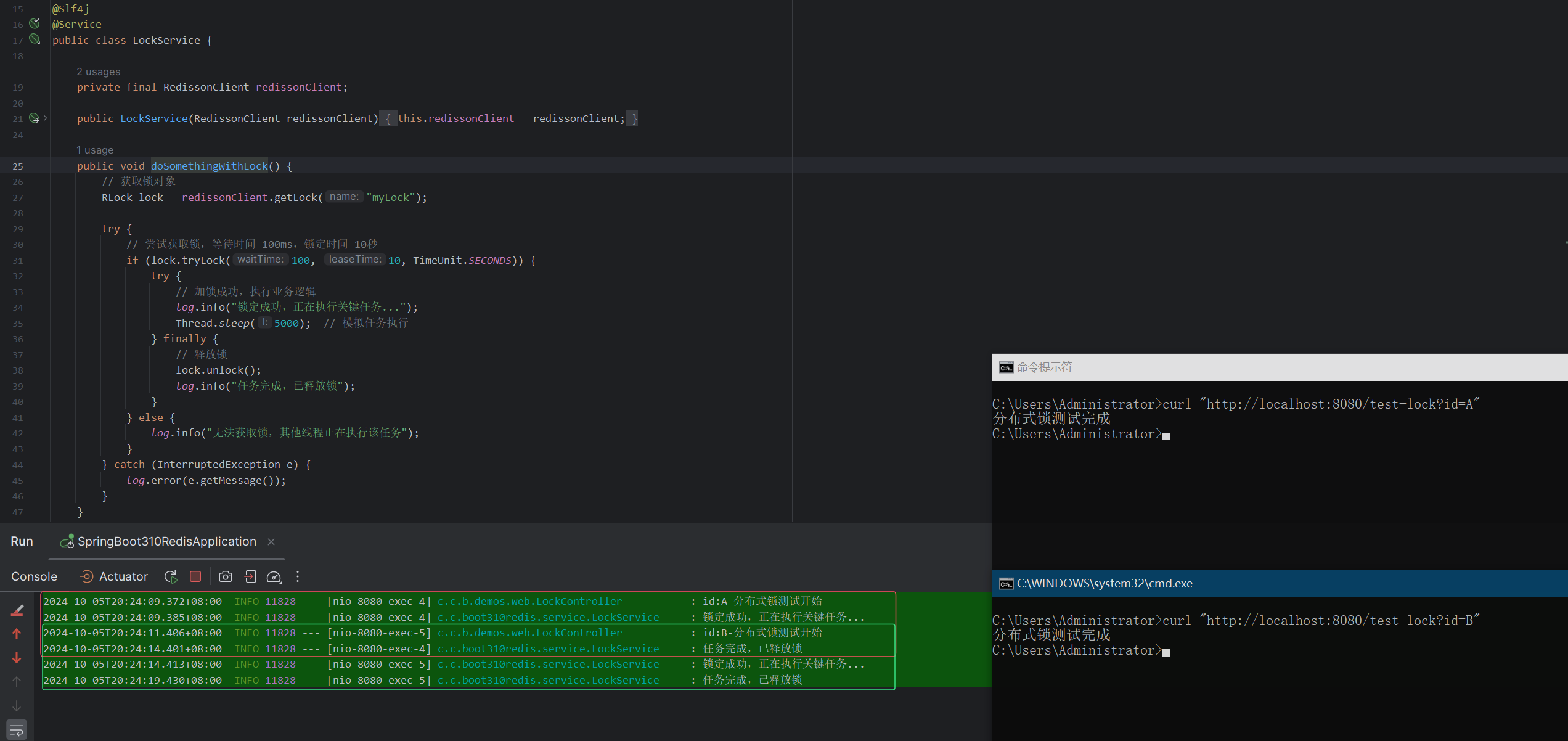
今天AI生成未来和大家分享的是南洋理工、北大、上海AI Lab和港中文联合发布的3D PBR资产生成最新工作3DTopia-XL。通过基于高效且表达力强的3D表示方法PrimX的扩散Transformer(DiT),实现高质量3D资产生成的规模化。去噪过程只需5秒钟,就能从文本或图像输入生成可用于图形pipeline的3D PBR(物理渲染)资产。
关键思想是一种新颖的3D表示,即PrimX。它明确地将纹理网格的3D形状、纹理和材质编码为紧凑的N x D张量。此表示中的每个token都是一个体积图元,通过体素化有效载荷anchor到形状表面,以编码SDF、RGB和材质。
亮点直击
- 提出了一种新颖的3D表示方法PrimX,用于高质量3D内容的创建,它高效、张量性强且可渲染。
- 引入了一个可扩展的生成框架3DTopia-XL,只需5秒,专为生成具有高分辨率几何图形、纹理和材质的高质量3D资产而设计。
- 提出了实用的资产提取技术,将3D表示转化为实体资产,以避免质量损失。
- 展示了3DTopia-XL在图像到3D和文本到3D任务中的卓越质量和令人印象深刻的应用。
解决的问题
3DTopia-XL主要解决的问题是现有3D生成模型在优化速度、几何细节保真度以及物理基础渲染(PBR)资产生成方面的挑战。它旨在提高3D内容创作的效率和质量,满足游戏开发、电影制作、虚拟现实等各行各业对高质量3D资产的日益增长的需求。
提出的方案
3DTopia-XL提出了一种可扩展的原生3D生成模型,利用了一种新颖的基于原始的3D表示方法PrimX,该方法将详细的形状、反照率和材料场编码为紧凑的张量格式,从而促进了高分辨率几何体与PBR资产的建模。此外,提出了一个基于扩散Transformer(DiT)的生成框架,包括原始补丁压缩和潜在原始扩散,从文本或视觉输入中学习生成高质量的3D资产。
应用的技术
- PrimX表示法:一种新颖的基于原语的3D表示方法,将3D物体的形状、反照率(albedo)、材质信息编码到一个紧凑的张量格式中。
- 原始补丁压缩:使用三维变分自编码器(VAE)对每个原语的空间信息进行压缩,得到潜在的原语标记。
- 潜在原语扩散(Latent Primitive Diffusion):基于Diffusion Transformer(DiT)框架,模型学习了如何从随机噪声中逐步去除噪声,生成符合输入条件的潜在原语token。
- 可微分渲染:PrimX表示法支持可微分渲染,模型可以直接从二维图像数据中学习,提高了模型从现有图像资源中学习的能力 。
达到的效果
3DTopia-XL在生成具有细致纹理和材料的高质量3D资产方面显著优于现有方法,有效弥合了生成模型与现实世界应用之间的质量差距。生成的三维物体具有平滑的几何形状和空间变化的纹理和材质,接近真实物理材质感。此外,模型能在五秒内完成从输入到三维模型的转换,大幅提高创作效率 。
方法
PrimX:形状、纹理和材质的高效表示
在高质量大规模3D生成模型的背景下,3D表示的以下设计原则:
- 参数高效:在近似误差和参数数量之间提供良好的折衷;
- 快速张量化:可以高效地转化为张量结构,这有助于利用现代神经架构进行生成建模;
- 可微分渲染:与可微分渲染器兼容,使得可以从3D和2D数据中进行学习。
定义
预备知识。给定一个带有纹理的3D网格,将其3D形状表示为 S ∈ R 3 S \in \mathbb{R}^3 S∈R3,其中 x ∈ S x \in S x∈S 是形状占据空间内的点,而 $x \in \partial S $ 是形状边界上的点,即形状的表面。我们将3D形状建模为SDF如下:
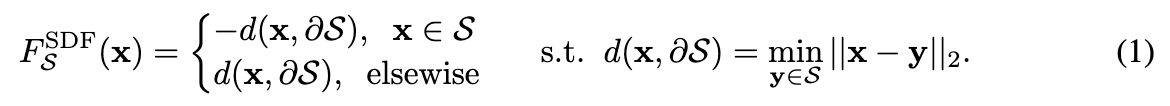
此外,给定形状表面的邻域 U ( ∂ S , δ ) = { x ∣ d ( x , ∂ S ) < δ } U(\partial S, \delta) = \{x \,|\, d(x, \partial S) < \delta\} U(∂S,δ)={x∣d(x,∂S)<δ},目标网格的空间变化颜色函数和材质函数定义如下:
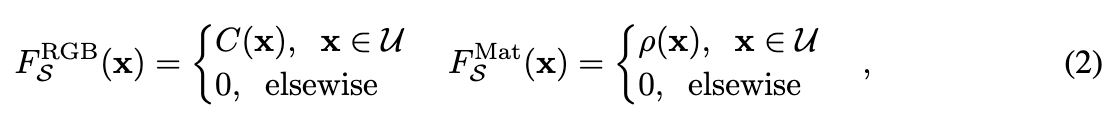
其中 C ( x ) : R 3 → R 3 C(x) : \mathbb{R}^3 \rightarrow \mathbb{R}^3 C(x):R3→R3 和 ρ ( x ) : R 3 → R 2 \rho(x) : \mathbb{R}^3 \rightarrow \mathbb{R}^2 ρ(x):R3→R2 是相应的纹理采样函数,用于从与UV对齐的纹理图中获取3D点 x x x的反照率和材质(金属度和粗糙度)。最终,3D网格的所有形状、纹理和材质信息可以由体积函数 F S = ( F S D ⊕ F S R G B ⊕ F S M a t ) : R 3 → R 6 F_S = (F_S^D \oplus F_S^{RGB} \oplus F_S^{Mat}) : \mathbb{R}^3 \rightarrow \mathbb{R}^6 FS=(FSD⊕FSRGB⊕FSMat):R3→R6 参数化,其中 ⊕ \oplus ⊕ 表示拼接操作。
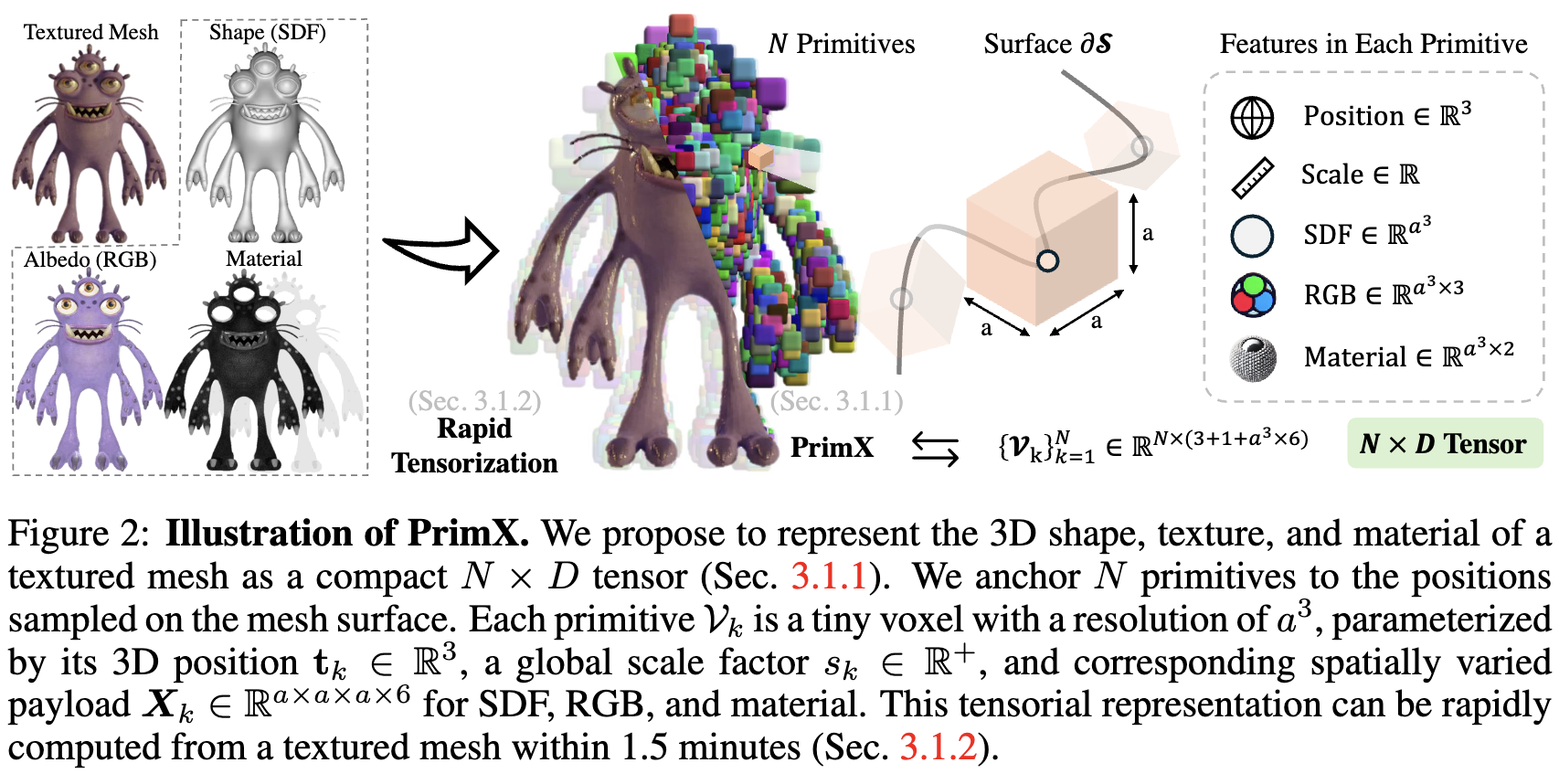
PrimX表示法。用一个由 N × D N \times D N×D 张量 V V V 参数化的神经体积函数 F V : R 3 → R 6 F_V : \mathbb{R}^3 \rightarrow \mathbb{R}^6 FV:R3→R6 来逼近 F S F_S FS。为了提高效率,我们的关键见解是将 F V F_V FV 定义为一组分布在网格表面上的 N N N 个体积原语。
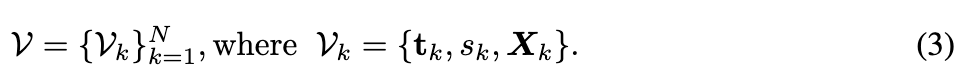
每个原语 V k V_k Vk 是一个分辨率为 a 3 a^3 a3 的小体素,通过其3D位置 t k ∈ R 3 t_k \in \mathbb{R}^3 tk∈R3、全局缩放因子 s k ∈ R + s_k \in \mathbb{R}^+ sk∈R+ 以及相应的空间变化特征载荷 X k ∈ R a × a × a × 6 X_k \in \mathbb{R}^{a \times a \times a \times 6} Xk∈Ra×a×a×6 进行参数化。请注意,PrimX中的载荷可以是具有任意维度的空间变化特征。我们在此实例化的是使用一个六通道的局部网格 X k = { X k S D F , X k R G B , X k M a t } X_k = \{X_k^{SDF}, X_k^{RGB}, X_k^{Mat}\} Xk={XkSDF,XkRGB,XkMat} 来分别参数化SDF、RGB颜色和材质。
受Yariv等人的启发,其中马赛克体素通过全局加权来获得光滑的表面,纹理化网格的近似定义为原语的加权组合。
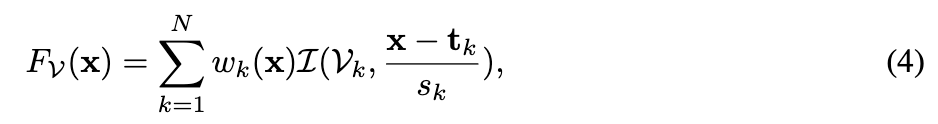
其中 I ( V k , x ) I(V_k, x) I(Vk,x) 表示在位置 x x x 处对体素网格 X k X_k Xk 进行三线性插值。每个原语的加权函数 w k ( x ) w_k(x) wk(x) 定义为
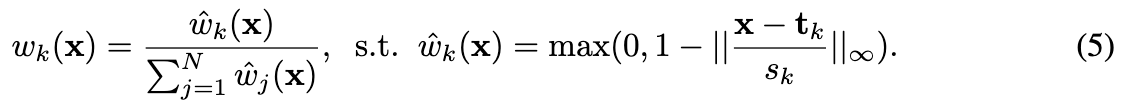
一旦确定了原语的载荷,可以利用高效的可微渲染器将 PrimX 转换为2D图像。具体来说,给定一个摄像机光线
r
(
t
)
=
o
+
t
d
r(t) = o + t d
r(t)=o+td,其中
o
o
o 为摄像机原点,
d
d
d 为光线方向,对应的像素值
I
I
I 通过以下积分求解:
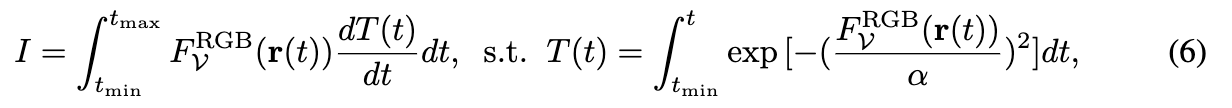
其中,使用SDF场的指数来表示不透明度场。 α \alpha α 是控制这种转换过程中不透明度场方差的超参数,我们设置 α = 0.005 \alpha = 0.005 α=0.005。总结来说,PrimX建模的纹理化3D网格的可学习参数包括原语位置 t ∈ R N × 3 t \in \mathbb{R}^{N \times 3} t∈RN×3、原语尺度 s ∈ R N × 1 s \in \mathbb{R}^{N \times 1} s∈RN×1,以及用于SDF、颜色和材质的体素载荷 X ∈ R N × a 3 × 6 X \in \mathbb{R}^{N \times a^3 \times 6} X∈RN×a3×6。因此,每个纹理化网格可以表示为紧凑的 N × D N \times D N×D 张量,其中通过拼接 D = 3 + 1 + a 3 × 6 D = 3 + 1 + a^3 \times 6 D=3+1+a3×6。
PBR 资产提取。一旦构建了PrimX,它将在 N × D N \times D N×D 中编码目标网格的所有几何和外观信息。现在介绍将PrimX转换回GLB文件格式纹理网格的高效算法。对于几何信息,我们可以通过在 F V S D F F_V^{SDF} FVSDF 的零水平集上使用 Marching Cubes 算法轻松提取相应的3D形状。对于PBR纹理贴图,我们首先使用xatlas在1k分辨率的UV空间进行UV展开。接着,使用nvdiffrast获取3D采样点,并查询 F V R G B F_V^{RGB} FVRGB 和 F V M a t F_V^{Mat} FVMat 来获取相应的反照率和材质值。请注意,我们对UV空间进行mask处理,以获取有效顶点的索引以便进行高效查询。此外,扩展UV纹理贴图,并用现有纹理的最近邻点填充扩展区域,确保反照率和材质贴图平滑地向外融合,以实现抗锯齿效果。最后,将几何信息、UV映射、反照率、金属度和粗糙度贴图打包到GLB文件中,准备好供图形引擎和各种下游任务使用。
从纹理网格计算PrimX
该拟合算法可以在短时间内从输入的纹理网格计算PrimX,使其可以在大规模数据集上扩展用于生成建模。给定一个纹理化3D网格 F S F_S FS,目标是计算PrimX,使得 F V ( x ) ≈ F S ( x ) F_V(x) \approx F_S(x) FV(x)≈FS(x),其中 x ∈ U ( ∂ S , δ ) x \in U(\partial S, \delta) x∈U(∂S,δ)。通过良好的初始化,随后进行轻量级微调来高效实现拟合过程。
初始化。假设所有纹理化网格都以GLB格式提供,包含三角网格、纹理和材质贴图以及相应的UV映射。首先,将目标网格的顶点归一化到单位立方体内。为了初始化原语的位置,在网格表面进行均匀随机采样,得到 N ^ \hat{N} N^ 个候选初始点。然后,在此候选点集中执行最远点采样,得到 N N N 个有效初始位置用于所有原语。这种两步位置初始化确保了 F V F_V FV 在边界邻域 U U U 上的良好覆盖,同时尽可能保留高频的形状细节。接着,计算每个原语与其最近邻的L2距离,并将相应的值作为每个原语的初始尺度因子。
为了初始化原语的载荷,首先使用初始化的位置 t k t_k tk 和尺度 s k s_k sk 计算全局坐标中的候选点,公式为 t k + s k I t_k + s_k I tk+skI,其中 I I I 是分辨率为 a 3 a^3 a3 的单位局部体素网格。为了初始化SDF值,在每个候选点处查询从3D形状转换而来的SDF函数,即 X k S D F = F S S D F ( t k + s k I ) X_k^{SDF} = F_S^{SDF}(t_k + s_k I) XkSDF=FSSDF(tk+skI)。值得注意的是,从任意3D形状转换为体积SDF函数并非易事。我们的实现基于一种高效的光线行进与包围体层次结构(BVH),这在非闭合拓扑中表现良好。为了初始化颜色和材质值,使用几何函数 F S R G B F_S^{RGB} FSRGB 和 F S M a t F_S^{Mat} FSMat 从UV空间采样相应的反照率颜色和材质值。具体来说,为每个候选点计算3D网格上的最近面和相应的重心坐标,然后插值UV坐标并从纹理贴图中采样以获取对应的值。
微调。即使上述初始化已提供了一个相当不错的 F S F_S FS 估计值,通过快速的微调过程仍然可以通过梯度下降进一步减少近似误差。具体来说,我们对经过良好初始化的 PrimX 进行优化,使用基于回归的损失函数来针对 SDF、反照率和材质值进行微调。
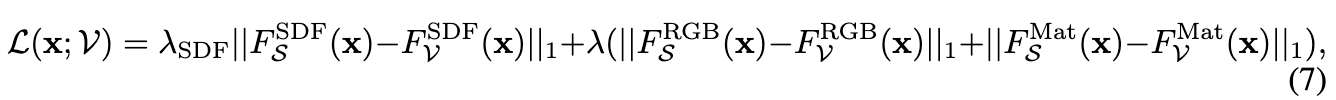
其中, ∀ x ∈ U \forall x \in U ∀x∈U,并且 λ S D F \lambda_{SDF} λSDF 和 λ \lambda λ 是损失权重。我们采用两阶段的微调策略,在前 1000 次迭代中优化 λ S D F = 10 \lambda_{SDF} = 10 λSDF=10 且 λ = 0 \lambda = 0 λ=0,而在接下来的 1000 次迭代中优化 λ S D F = 0 \lambda_{SDF} = 0 λSDF=0 且 λ = 1 \lambda = 1 λ=1。
原语补丁压缩
本节介绍基于补丁的原语压缩方案,主要有两个目的:
- 融合几何、颜色和材质之间的通道相关性;
- 将 3D 原语压缩为潜在令牌,以实现高效的潜在生成建模。
选择使用变分自编码器(VAE)在局部体素补丁上运行,将每个原语的有效载荷压缩为潜在令牌,即 F a e : R D → R d F_{ae} : \mathbb{R}^D \rightarrow \mathbb{R}^d Fae:RD→Rd。具体来说,自编码器 F a e F_{ae} Fae 包括由 3D 卷积层构建的编码器 E E E 和解码器 D D D。编码器 F a e F_{ae} Fae 的下采样率为 48,将体素有效载荷 X k ∈ R a 3 × 6 X_k \in \mathbb{R}^{a^3 \times 6} Xk∈Ra3×6 压缩为体素潜变量 X ^ k ∈ R ( a / 2 ) 3 × 1 \hat{X}_k \in \mathbb{R}^{(a/2)^3 \times 1} X^k∈R(a/2)3×1。我们通过 KL 正则化的重建损失来训练该变分自编码器 F a e = { E , D } F_{ae} = \{E, D\} Fae={E,D}。
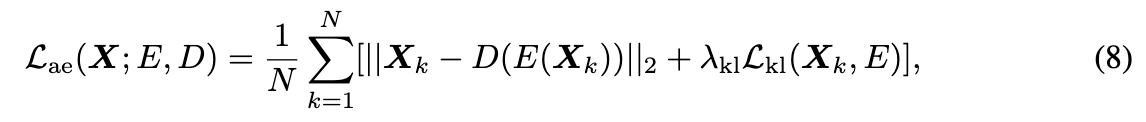
其中, λ k l \lambda_{kl} λkl 是针对自编码器潜在空间中 KL 正则化的权重。需要注意的是,与其他2D/3D潜在扩散模型在补丁集合或全局3D潜变量上执行全局压缩不同,所提出的方法仅对每个局部原语补丁独立进行压缩,并将全局语义和补丁间相关性的建模推迟到功能强大的扩散模型中。一旦训练好 VAE,我们就可以将原始 PrimX 压缩为 V k = { t k , s k , E ( X k ) } V_k = \{t_k, s_k, E(X_k)\} Vk={tk,sk,E(Xk)}。这将导致扩散模型的低维参数空间为 V ∈ R N × d V \in \mathbb{R}^{N \times d} V∈RN×d,其中 d = 3 + 1 + ( a / 2 ) 3 d = 3 + 1 + (a/2)^3 d=3+1+(a/2)3。在实际操作中,这种紧凑的参数空间显著提高了在给定固定计算预算下分配更多模型参数的能力,这对于扩展高分辨率3D生成模型至关重要。
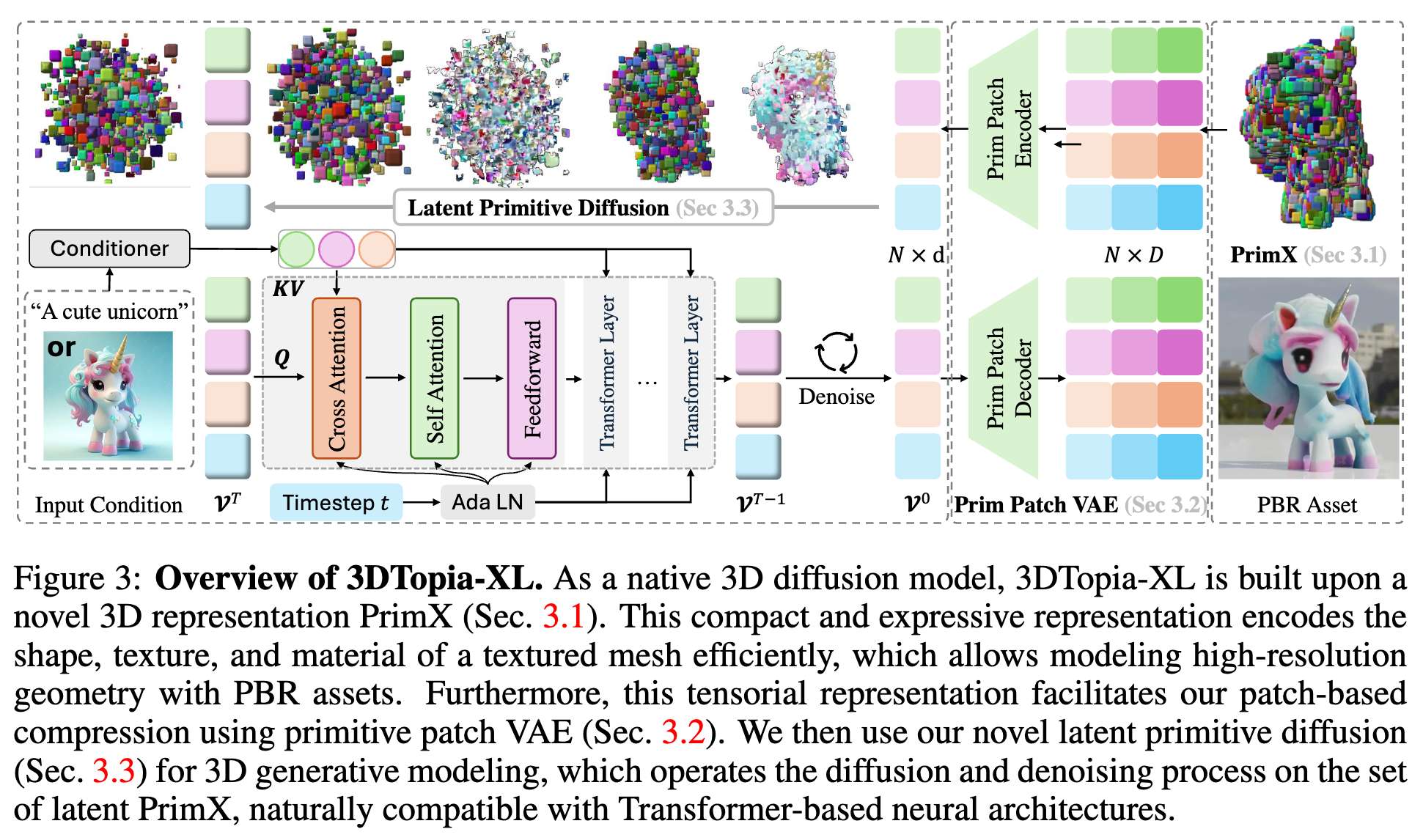
潜在原语扩散
在 PrimX及其对应的 VAE的基础上,3D 对象生成问题被转换为学习大规模数据集上的分布 p ( V ) p(V) p(V)。目标是训练一个扩散模型,该模型以随机噪声 V T V_T VT 和条件 c c c 作为输入,并预测 PrimX 样本。注意,去噪的目标空间为 V T ∈ R N × d V_T \in \mathbb{R}^{N \times d} VT∈RN×d,其中 d = 3 + 1 + ( a / 2 ) 3 d = 3 + 1 + (a/2)^3 d=3+1+(a/2)3。具体来说,扩散模型通过去噪步骤 { V T − 1 , … , V 0 } \{V_{T-1}, \dots, V_0\} {VT−1,…,V0} 学习去噪 V T ∼ N ( 0 , I ) V_T \sim N(0, I) VT∼N(0,I),并给定条件信号 c c c。
作为一组原语,PrimX 自然兼容基于 Transformer 的架构,在这种架构中,我们将每个原语视为一个 token。此外,PrimX 的置换等变性消除了 Transformer 中对任何位置编码的需求。我们最大的潜在原语扩散模型 g Φ g_\Phi gΦ 是一个28层的 Transformer,包含交叉注意力层来整合条件信号,自注意力层用于建模原语间的相关性,以及自适应层归一化用于注入时间步条件。模型 g Φ g_\Phi gΦ 学习在时间步 t t t 给定输入条件信号进行预测。
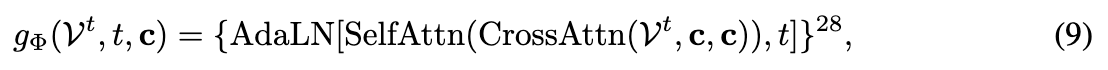
其中 C r o s s A t t n ( q , k , v ) CrossAttn(q,k,v) CrossAttn(q,k,v) 表示以查询、键和值作为输入的交叉注意力层。 S e l f A t t n ( ⋅ ) SelfAttn(\cdot) SelfAttn(⋅) 表示自注意力层。 A d a L N ( ⋅ , t ) AdaLN(\cdot,t) AdaLN(⋅,t) 表示自适应层归一化层,用于向交叉注意力、自注意力和前馈层注入时间步条件调制。此外,采用预归一化方案以提高训练稳定性。
对于噪声调度,在训练期间使用 1,000 个离散噪声步骤,并使用余弦调度器。我们选择“v-预测”与无分类器引导(CFG)作为训练目标,以提高条件生成质量和加快收敛速度。
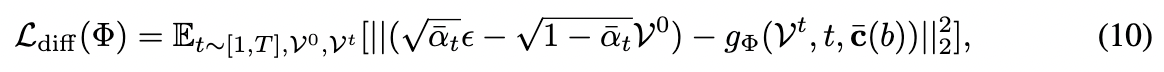
其中 ϵ \epsilon ϵ 是从高斯分布中采样的噪声, α ˉ t = ∏ i = 0 t ( 1 − β i ) \bar{\alpha}_t = \prod_{i=0}^{t}(1 - \beta_i) αˉt=∏i=0t(1−βi),而 β t \beta_t βt 来自我们的余弦 β \beta β 调度器。并且 b ∼ B ( p 0 ) b \sim B(p_0) b∼B(p0) 是从伯努利分布中采样的随机变量,以概率 p 0 p_0 p0 和 1 − p 0 1 - p_0 1−p0 取值 0 或 1。CFG 下的条件信号定义为 c ˉ ( b ) = b ⋅ c + ( 1 − b ) ⋅ ∅ \bar{c}(b) = b \cdot c + (1 - b) \cdot \emptyset cˉ(b)=b⋅c+(1−b)⋅∅,其中 ∅ \emptyset ∅ 是用于无条件生成的可学习嵌入。
实验
实现细节
数据标准化
数据集。3D 数据的规模和质量决定了大规模 3D 生成模型的质量和有效性。过滤掉低质量的网格,如碎片状形状和大规模场景,最终得到来自 Objaverse的 256,000 个物体的精炼集合。在大规模数据集上计算 PrimX 涉及两个关键步骤:1) 从 GLB 文件实例化采样函数 {FSDFS, FRGBS, FMatS},2) 执行前面的拟合算法。鉴于 Objaverse 中来自不同来源的大量网格,存在以通用方式正确实例化采样函数的挑战,如碎片状网格、非水密形状和不一致的 UV。标准化程序从将 GLB 文件加载为连接图开始。过滤掉面相邻度小于 3 的子组件,这通常表示孤立的平面或地面。之后,所有网格子组件都被全局归一化到单位立方体 [ − 1 , 1 ] [-1,1] [−1,1],给定一个独特的全局边界框。然后,我们为每个网格子组件实例化几何采样函数,以获取 SDF、纹理和材料值。
PrimX 超参数。为了在计算复杂性和近似误差之间取得平衡,我们选择 PrimX 具有 N = 2048 N = 2048 N=2048 的原语,其中每个原语的负载具有 a = 8 a = 8 a=8 的分辨率。这意味着我们原语扩散 Transformer 的序列长度也是 2048,其中每个标记的维度为 d = 3 + 1 + ( a / 2 ) 3 = 68 d = 3 + 1 + (a/2)^3 = 68 d=3+1+(a/2)3=68。在计算 PrimX 的快速微调阶段,从目标网格中采样 500,000 个点,其中 300,000 个点在表面上采样,200,000 个点以标准差 0.01 在表面附近采样。微调阶段运行 2,000 次迭代,批大小为 16,000 个点,使用 Adam(Kingma & Ba, 2014)优化器,学习率为 1 × 1 0 − 4 1 \times 10^{-4} 1×10−4。
条件信号
条件生成器。前面的条件生成公式与大多数模态兼容。本文主要探索了两种模态的条件生成,即图像和文本。
图像。对于图像条件模型,我们利用预训练的 DINOv2 模型,具体是“DINOv2-ViT-B/14”,从输入图像中提取视觉标记,并将其作为输入条件 c c c。得益于我们高质量的表示 PrimX 及其高效渲染的能力,我们不需要经历像其他工作那样复杂且昂贵的渲染过程,这些工作将所有原始网格渲染为 2D 图像进行训练。相反,选择使用 Eq. 6 渲染的前视图图像,1) 计算上足够高效,2) 与底层表示一致,相比于从原始网格渲染的结果。
文本标题。从 Objaverse 中采样 200,000 个数据点来生成文本标题。对于每个物体,渲染六个不同的视图,并以白色背景为背景。然后,使用 GPT-4V 根据这些图像生成关键词,重点关注几何、纹理和风格等方面。虽然我们为每个方面预定义了某些关键词,但模型也鼓励生成更多上下文特定的关键词。一旦获得关键词,便使用 GPT-4 将其总结为一个完整的句子,开头为“一个 3D 模型…”。这些文本标题随后被准备为输入条件。
模型细节
训练。使用基于 Transformer 的架构训练潜在原语扩散模型 g Φ g_\Phi gΦ 以提高可扩展性。最终模型由 28 层组成,具有 16 个头的注意力和 1152 的隐藏维度,导致总参数量约为 10 亿个。我们以批大小为 1024 的方式训练 g Φ g_\Phi gΦ,使用 AdamW(Loshchilov & Hutter, 2017)优化器。学习率设置为 1 × 1 0 − 4 1 \times 10^{-4} 1×10−4,并在 3000 次迭代中采用余弦学习率预热。条件丢弃的概率设置为 b = 0.1 b = 0.1 b=0.1。在训练过程中,我们对模型权重应用 EMA(指数移动平均),衰减率为 0.9999,以提高稳定性。图像条件模型在 16 个节点的 8 个 A100 GPU 上训练 350,000 次迭代,约需 14 天才能收敛。文本条件模型在 16 个节点的 8 个 A100 GPU 上训练 200,000 次迭代,约需 5 天才能收敛。
3D VAE训练。用于逐片原语压缩的 3D VAE 采用 3D 卷积层构建。我们在整个数据集的一个子集上训练 VAE,包含 98,000 个样本,发现它在未见过的数据上表现良好。训练进行 60,000 次迭代,批量大小为 256,使用 Adam 优化器,学习率设置为 1 × 1 0 − 4 1 \times 10^{-4} 1×10−4。需要注意的是,这个批量大小指的是每次迭代中 PrimX 样本的总数。由于VAE 独立于每个原语操作,因此实际批量大小为 N × 256 N \times 256 N×256。将 KL 正则化的权重设置为 λ k l = 5 × 1 0 − 4 \lambda_{kl} = 5 \times 10^{-4} λkl=5×10−4。训练分布在 8 个节点的 8 个 A100 GPU 上,耗时约 18 小时。
推理。默认情况下,使用 25 步 DDIM采样器和 CFG 缩放因子为 6 来评估我们的模型。我们发现 DDIM 采样步骤的最佳范围是 25 到 100,而 CFG 缩放因子的最佳范围是 4 到 10。推理过程可以在单个 A100 GPU 上高效完成,时间约为 5 秒。
表示评估
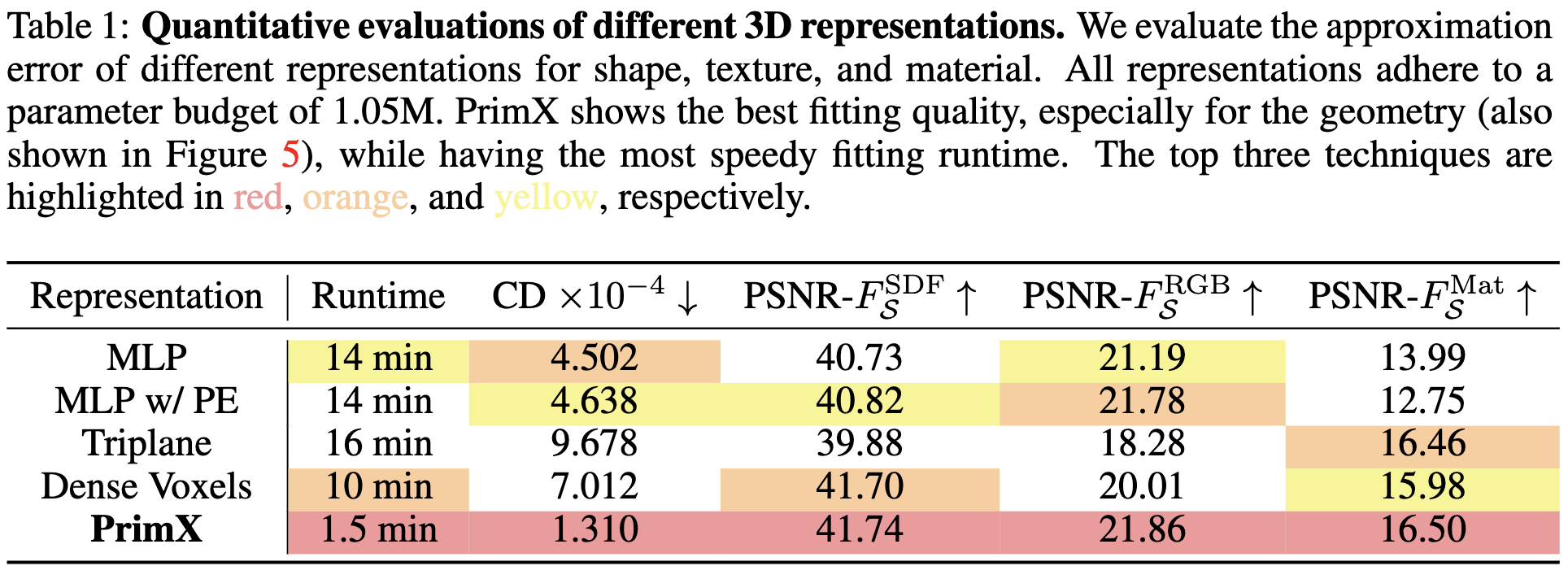
评估协议。首先在 3D 生成建模的背景下评估不同的 3D 表示设计。我们的评估原则集中在两个方面:1) 从 GLB 网格到表示的运行时,2) 在固定计算预算下,给定形状、纹理和材料的近似误差。我们随机从训练数据集中抽取 30 个 GLB 网格,记录至收敛的平均拟合时间作为运行时,测量方式为在 A100 GPU 上的墙面时间。对于几何质量,我们评估真实网格与拟合后提取网格之间的 Chamfer 距离(CD),以及在形状表面附近采样的 500,000 个点的 SDF 值的峰值信噪比(PSNR)。对于外观质量,我们评估在表面附近采样的 500,000 个点的 RGB(反照率)和材料值的 PSNR。
基线。给定PrimX的最终超参数,其中N=2048,a=8,我们将所有表示的参数数量固定为2048 × 83 ≈ 1.05M,以便进行比较。我们比较四种替代表示:1)MLP:一个纯多层感知器,包含3层和1024个隐藏维度;2)带PE的MLP:在输入坐标上添加位置编码(PE)(Mildenhall等,2020)的MLP基线;3)三平面(Chan等,2022):三个正交的2D平面,分辨率为128 × 128和16个通道,随后是一个具有512个隐藏维度的两层MLP解码器;4)密集体素:分辨率为100 × 100 × 100的密集3D体素。所有方法都使用与我们相同的目标(方程7)和点采样策略(第4.1.1节)进行训练。
结果。定量结果见下表1,显示PrimX在所有方法中实现了最低的近似误差,特别是在几何方面(由CD指示)。除了最佳质量外,所提议的表示在运行时效率方面表现显著,收敛速度比第二好的方法快近7倍,使其在大规模数据集上可扩展。图5展示了定性比较。基于MLP的隐式方法似乎存在周期性伪影,特别是在几何方面。三平面和密集体素产生了凹凸不平的表面以及形状表面周围的网格伪影。相反,PrimX则产生了最佳质量,具备光滑的几何形状和细致的细节,如纤细而逐渐变细的胡须。

图像到3D生成
本节将单视图条件生成模型与适合图像到3D合成的最先进方法进行比较。
比较方法。对两种类型的方法进行了评估:1)稀疏视图重建模型和2)图像条件扩散模型。基于重建的方法,如LGM、InstantMesh、Real3D和CRM,是确定性方法,旨在根据四个或六个输入视图重建3D对象。它们通过利用预训练的扩散模型从输入单一图像生成多个视图,从而实现单视图到3D的合成。然而,重建方法严重依赖输入的多视图图像,因此会受到前端2D扩散模型导致的多视图不一致性影响。前馈扩散模型,如CraftsMan、Shap-E和LN3Diff,是概率方法,旨在根据输入图像条件生成3D对象。上述所有方法仅建模形状和颜色,而不考虑粗糙度和金属质感,而我们的方法适合生成这些资产。
结果。下图6展示了定性结果。为了公平比较生成适合渲染的3D资产的能力,我们将每种方法导出的纹理网格导入Blender并使用目标环境贴图进行渲染。对于无法生成PBR材料的方法,我们分配默认的漫反射材料。现有的基于重建的模型未能产生良好的结果,可能受到多视图不一致性和无法支持空间变化材料的影响。此外,这些重建模型基于三平面表示,这在参数效率上表现不佳。这一缺点限制了底层3D表示的空间分辨率,导致渲染法线指示的凹凸不平的表面。另一方面,现有的3D扩散模型未能生成与输入条件视觉对齐的对象。虽然CraftsMan是唯一与我们具有可比表面质量的方法,但它们仅能生成没有纹理和材料的3D形状。相比之下,3DTopia-XL在所有方法中实现了最佳的视觉和几何质量。得益于我们生成空间变化的PBR资产(如金属质感和粗糙度)的能力,我们生成的网格即使在恶劣环境照明下也能产生生动的反射和镜面高光。

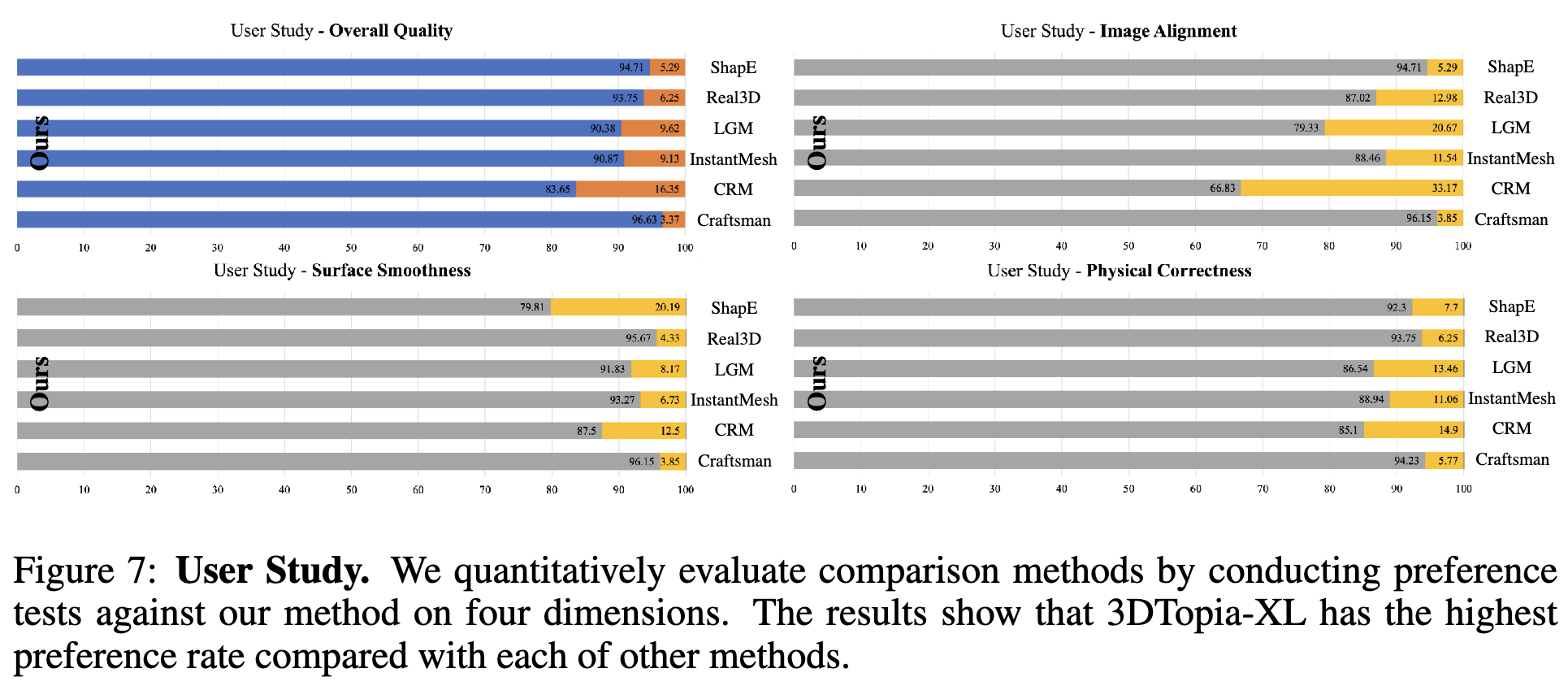
用户研究。我们进行了一项广泛的用户研究,以定量评估图像到3D的性能。我们选择了输出评估(Bylinskii等,2022)作为用户研究,在该研究中,每位志愿者会看到一对结果,比较随机方法与我们的方法,并被要求在四个方面选择更好的一个:1)整体质量,2)图像对齐,3)表面光滑度和4)物理正确性。共提供48对样本给27位志愿者进行翻转测试。我们在图7中总结了所有四个维度的平均偏好百分比。3DTopia-XL在所有方法中表现最佳。尽管我们方法的图像对齐仅比基于重建的方法(如CRM)有所改进,但几何质量的优越性和建模基于物理材料的能力是最终渲染中产生最佳整体质量的关键。
文本到3D生成
展示了原生文本到3D生成的能力,如下图4所示。作为一个3D原生扩散模型,我们的文本驱动生成是通过直接对模型进行文本输入的条件,而不依赖于复杂的文本到多视图再到重建模型的流程。

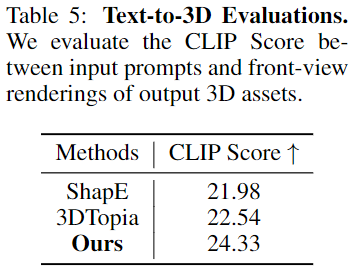
此外,还针对原生文本到3D生成模型进行了定量评估。为此,我们采用CLIP评分作为评估指标,测量文本嵌入和图像嵌入在CLIP模型的联合文本-图像空间中的余弦相似度。使用每种方法的前视图渲染来计算图像嵌入。主要比较了两个具有开源实现的方法:Shap-E和3DTopia。Shap-E直接根据文本生成3D物体的隐式函数,而3DTopia则采用了混合的2D和3D扩散先验,使用前馈三平面扩散,然后进行基于优化的精炼。正如表5所示,我们的方法在输入文本和生成资产的渲染之间实现了更好的对齐。
进一步分析
原语的数量和分辨率
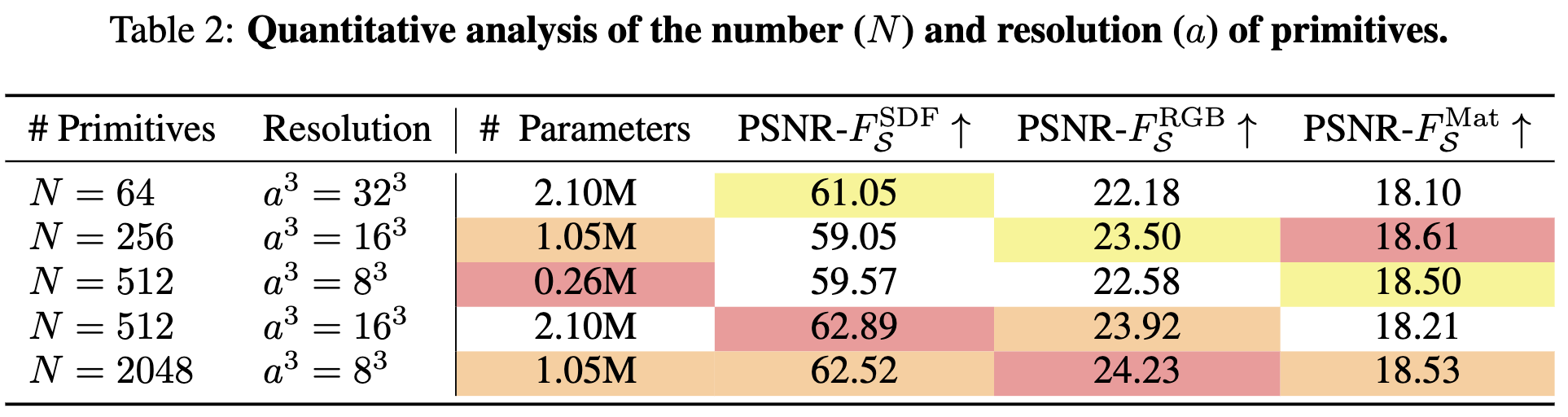
原语的数量 N N N 和每个原语的分辨率 a a a 是影响PrimX效率-质量权衡的关键因素,既是结构化的3D表示,也是序列化的表示。增加更多和更大的原语通常会导致更好的近似质量;然而,这也会导致序列长度增加和特征维度更深,从而导致长上下文注意力计算效率低下和扩散模型训练困难。
为了评估原语数量和分辨率的影响,在离表面500k个采样点上评估了签名距离函数(SDF)、反照率和材料值的PSNR。结果如下表2所示,给定固定的参数数量,较长的原语序列能更好地近似SDF、纹理和材料。此外,增加每个原语的分辨率可以减少近似误差,但当原语数量充足时,这种好处会变得边际化。
下图8中的可视化结果也支持这些发现。

例如,使用 N = 64, a = 32 的替代方案即使在参数数量较高的情况下也会产生较差的几何形状,因为较大的局部原语更容易在空白空间中浪费参数。此外,较长的序列会增加扩散模型(DiT)的GFlops,导致生成质量更好(见下表3)。因此,我们的方法倾向于使用较长的原语序列,同时保持相对较小的局部分辨率。值得注意的是,我们的变分自编码器(VAE)压缩率也会影响PrimX的超参数,我们将在下一节中进一步探讨。

patch压缩率
基于原语的patch变分自编码器(VAE)的压缩率也是一个重要的设计选择。总体而言,作为一种patch压缩方法,目标是对每个原语进行空间压缩,以节省计算资源,而不是进行语义压缩。经验上,更高的压缩率会导致更高效的潜在扩散模型,在扩大规模时可以指示更大的批量大小或更大的模型。相反,极端的压缩往往伴随着信息的丢失。
因此,分析了在保持PrimX参数数量相同的情况下,给定两种不同序列长度 N = 256 和 N = 2048 的不同压缩率。作为评估指标,计算了VAE输出与输入之间在数据集中随机抽取的1000个样本上的PSNR,以测量其重建质量。表4展示了结果,其中最终选择的 N = 2048 和压缩率 f = 48 达到了最佳的VAE重建。设置为 N = 256, f = 48 的情况具有相同的压缩率,但重建质量较低,并且潜在空间的分辨率更高,这导致我们在潜在原语扩散模型 g Φ g_{\Phi} gΦ 的收敛上遇到困难。
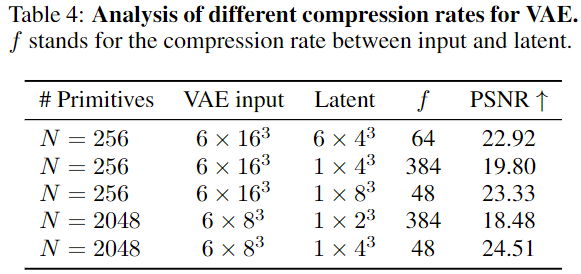
扩展性
进一步研究了3DTopia-XL的扩展性规律,关注模型大小和迭代次数。作为指标,使用在没有条件生成(CFG)指导下,对5000个随机样本计算的Fréchet Inception Distance(FID)。具体而言,考虑在VAE潜在空间中计算的Latent-FID和在使用公式6渲染的图像提取的DINO嵌入上计算的Rendering-FID。下图9展示了随着模型规模的增加,Latent-FID和Rendering-FID的变化。观察到随着模型的加深和加宽,性能有了一致的提升。表3还表明,较长的序列(较小的patch)会导致更好的性能,这可能与原始DiT中的发现有关,即增加GFlops会提高性能。
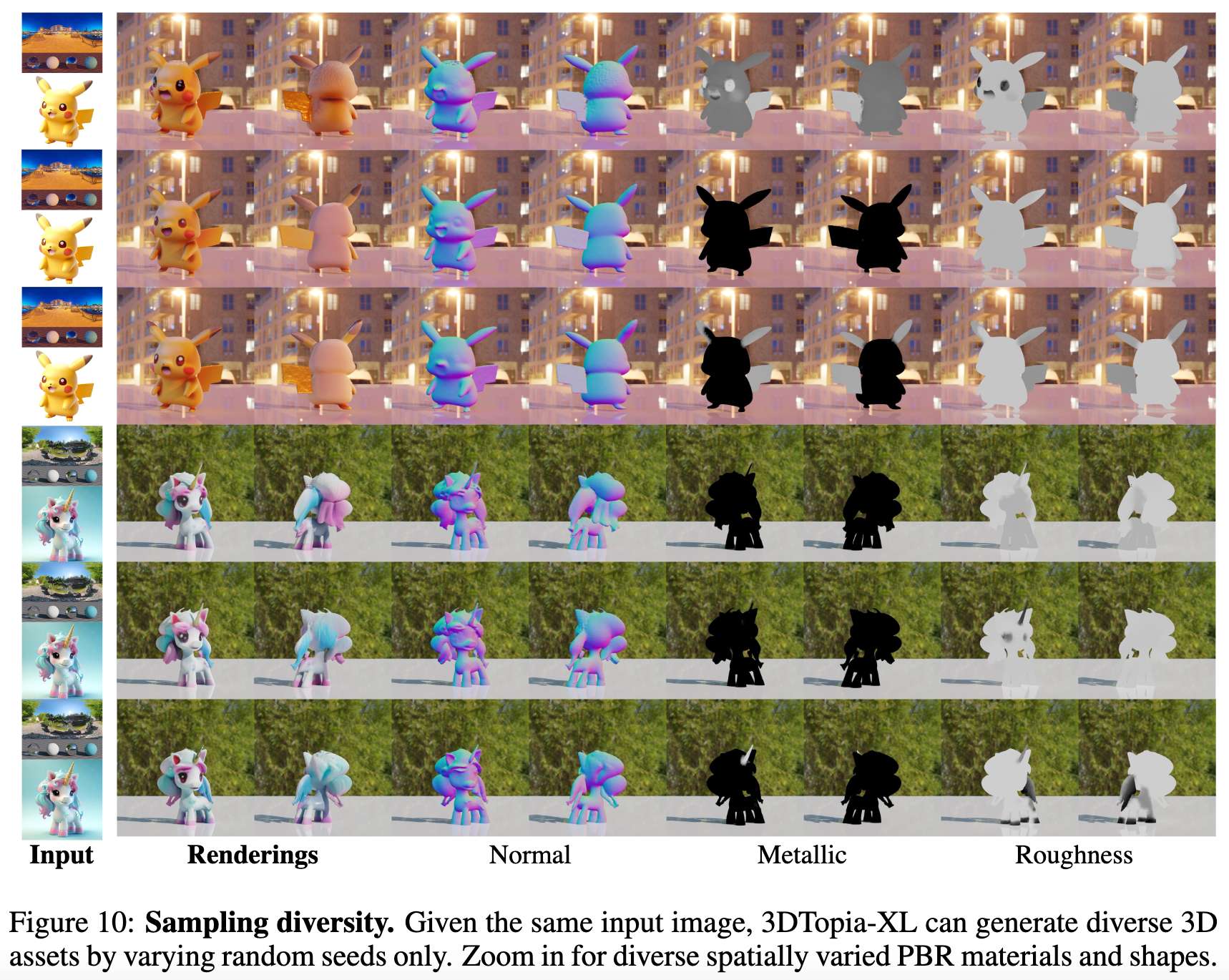
采样多样性
最后,展示了3DTopia-XL作为生成模型所展现出的令人印象深刻的采样多样性,如下图10所示。给定相同的输入图像和不同的随机种子,模型能够生成多样化的高质量3D资产,这些资产具有不同的几何形状和空间变化的PBR材料。
讨论
3DTopia-XL,这是一个针对给定文本或视觉输入的原生3D扩散模型,用于PBR资产生成。方法的核心是PrimX,这是一种创新的基于原语的3D表示,具有参数高效、张量化和可渲染的特点。它将形状、反照率和材质编码为一个紧凑的 ( N × D ) (N \times D) (N×D) 张量,使得能够对具有PBR资产的高分辨率几何体进行建模。
为了适应PrimX,引入了几种训练和推理技术,以确保生成的结果可以高质量地打包到GLB文件中,便于在图形引擎中的后续应用。广泛的评估表明,3DTopia-XL在文本到3D和图像到3D的任务中表现优越,展现了其作为3D生成基础模型的巨大潜力。
参考文献
[1] 3DTopia-XL: Scaling High-quality 3D Asset Generation via Primitive Diffusion














![[论文笔记]DAPR: A Benchmark on Document-Aware Passage Retrieval](https://img-blog.csdnimg.cn/img_convert/1cf1e967a9a7d2df718b3a64987cf6e0.png)

