✅作者简介:2022年博客新星 第八。热爱国学的Java后端开发者,修心和技术同步精进。
🍎个人主页:Java Fans的博客
🍊个人信条:不迁怒,不贰过。小知识,大智慧。
💞当前专栏:Java案例分享专栏
✨特色专栏:国学周更-心性养成之路
🥭本文内容:SPSS 分类模型实训步骤 (以 Logistic 回归为例)
文章目录
- 一、前言
- 二、什么是SPSS 分类模型
- 三、SPSS 分类模型实训流程
- 1. 明确问题与数据
- 2. 数据预处理 (SPSS 操作)
- 3. 探索性数据分析 (SPSS 操作)
- 4. 构建 Logistic 回归模型 (SPSS 操作)
- 5. 模型评估与解释 (SPSS 输出)
- 6. 模型优化与应用
- 7、学习建议
- 四、总结

一、前言
在本次实训中,我们将以经典的Logistic回归模型为例,通过使用SPSS软件来进行分类模型的构建和分析。Logistic回归是一种常用的统计方法,用于预测和解释二分类变量的概率。它可以帮助我们理解自变量与因变量之间的关系,并用于预测新的观测数据的分类。
本次实训的目标是让您熟悉SPSS软件的使用,并掌握Logistic回归模型的建立和解释。我们将按照一般的实训流程,逐步引导您完成数据准备、模型构建、模型评估和解释等步骤。
在实际应用中,Logistic回归模型广泛应用于医学、社会科学、市场营销等领域。通过本次实训,您将能够掌握Logistic回归模型的基本原理和操作方法,为您未来的研究和实践提供有力的支持。
请跟随我们的指导,一起来探索Logistic回归模型的魅力吧!如果您在实训过程中有任何问题,请随时向我们提问。让我们开始吧!
二、什么是SPSS 分类模型
SPSS分类模型是SPSS软件中用于进行分类分析的功能之一。分类分析是一种统计方法,用于预测或分类因变量的类别。SPSS提供了多种分类模型,包括Logistic回归、决策树、支持向量机、人工神经网络等,以满足不同类型的分类分析需求。
Logistic回归模型:Logistic回归是一种常用的分类模型,用于预测二分类变量的概率。它基于自变量与因变量之间的关系,通过估计参数来建立一个概率模型。SPSS中的Logistic回归模型可以帮助用户选择自变量、拟合模型、评估模型的拟合度,并进行预测。
决策树模型:决策树是一种基于树状结构的分类模型,通过一系列的判断节点和叶节点来进行分类。SPSS中的决策树模型可以帮助用户构建决策树,选择合适的划分变量和划分规则,并进行模型评估和预测。
支持向量机模型:支持向量机是一种常用的分类模型,通过寻找一个最优的超平面来将不同类别的样本分开。SPSS中的支持向量机模型可以帮助用户选择核函数、调整参数,并进行模型训练和预测。
人工神经网络模型:人工神经网络是一种模仿生物神经网络的计算模型,通过学习和训练来进行分类和预测。SPSS中的人工神经网络模型可以帮助用户选择网络结构、设置激活函数和学习算法,并进行模型训练和预测。
在使用SPSS分类模型时,用户需要进行数据准备、模型构建、模型评估和解释等步骤。SPSS提供了直观的用户界面和丰富的功能,使得分类模型的建立和分析变得更加简单和高效。
总之,SPSS分类模型是一种强大的工具,可以帮助用户进行分类分析,理解数据之间的关系,并进行预测和决策。通过合理选择和使用分类模型,用户可以从数据中获取有价值的信息,并做出相应的应用和决策。
三、SPSS 分类模型实训流程
1. 明确问题与数据
定义问题: 明确你的研究问题是什么,即你想预测什么。例如,假设你想预测哪些因素会影响客户是否会购买某个产品。这个问题可以被转化为一个二分类问题,其中因变量是客户是否购买该产品,自变量是可能影响购买决策的因素,如年龄、性别、收入等。
准备数据: 为了进行分类模型的构建和分析,你需要准备包含自变量和因变量的数据集。数据集应该包含以下内容:
- 因变量:这是你想预测的目标变量,即客户是否购买该产品。通常用二进制变量表示,例如1表示购买,0表示不购买。
- 自变量:这些是可能影响因变量的因素。例如,你可以收集客户的年龄、性别、收入等信息作为自变量。确保自变量的数据类型与分析模型的要求相符。
- 样本数据:收集足够数量的样本数据,包含了自变量和因变量的观测值。样本数据应该具有代表性,能够反映整个目标群体的特征。
- 数据清洗:对数据进行清洗和预处理,包括处理缺失值、异常值和重复值等。确保数据的质量和完整性。
- 数据格式:将数据整理为SPSS可识别的格式,如CSV、Excel等。确保数据的结构和变量命名符合SPSS的要求。
准备好数据后,你可以使用SPSS软件进行进一步的数据探索、模型构建和分析。根据你的研究问题和数据特点,选择合适的分类模型(如Logistic回归、决策树等),并进行模型的训练、评估和解释。通过分析模型的结果,你可以得出关于影响客户购买决策的因素的结论,并进行预测和决策支持。
请注意,在实际应用中,数据准备和清洗是非常重要的步骤,对于分类模型的准确性和可靠性有着重要的影响。确保数据的质量和准确性,可以提高模型的预测能力和解释性。
2. 数据预处理 (SPSS 操作)
导入数据: 打开 SPSS,点击“文件” -> “打开” -> “数据”,选择你的数据文件 (e.g., .sav, .csv)。
数据清洗:
- 处理缺失值: 选择需要处理缺失值的变量,点击“转换”-> “替换缺失值”。可以选择均值、中位数等方法进行替换。
- 处理异常值: 可以使用箱线图等方法识别异常值。对于异常值,可以考虑删除、替换或保留。
变量转换 (如果需要):
- 例如,将分类变量转换为哑变量。点击“转换” -> “创建虚变量”。
- 对连续变量进行标准化。点击“分析” -> “描述统计” -> “描述”,勾选“将标准化值另存为变量”。
3. 探索性数据分析 (SPSS 操作)
描述性统计:
- 点击“分析” -> “描述统计” -> “频率”或“描述”,查看数据的基本特征,如均值、标准差、频率分布等。
使用图表可视化数据:例如直方图、散点图等,帮助你直观了解数据分布和变量间的关系。
相关性分析:
- 点击“分析”-> “相关” -> “双变量”,选择你要分析的变量,可以计算 Pearson 相关系数等指标,初步判断变量之间的线性关系。
4. 构建 Logistic 回归模型 (SPSS 操作)
划分训练集和测试集: 点击“数据” -> “分割文件”,选择“按比例随机分配个案”,设置训练集和测试集的比例 (例如 70%/30%)。
拟合模型:
- 点击“分析” -> “回归” -> “二元 Logistic”。
- 在“因变量”框中选择你的二分类因变量。
- 在“协变量”框中选择你的自变量。
- 点击“选项”,选择需要的统计量和输出结果,例如分类图、Hosmer-Lemeshow 检验等。
- 点击“确定”运行分析。
5. 模型评估与解释 (SPSS 输出)
SPSS 会输出很多结果,你需要重点关注以下几个方面:
- 模型拟合优度: 查看 Omnibus Tests of Model Coefficients 表格,判断模型整体是否有效。
- 系数显著性检验: 查看 Variables in the Equation 表格,判断每个自变量对因变量的影响是否显著。
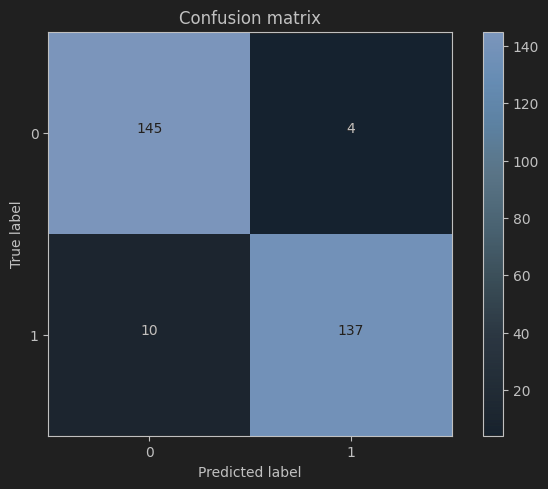
- 模型预测准确率: 查看 Classification Table,评估模型在训练集和测试集上的预测准确率、精确率、召回率等指标。
- 其他指标: 例如 ROC 曲线、AUC 值等,用于评估模型的区分能力。
6. 模型优化与应用
根据评估结果优化模型: 例如,剔除不显著的变量,调整变量转换方式等。
使用模型进行预测: 将新数据输入模型,预测其分类结果。
案例: 预测客户是否会购买产品
假设你有一个数据集 “customer_data.sav”,包含以下变量:
- 购买 (buy): 因变量,0 表示未购买,1 表示购买。
- 年龄 (age): 自变量,客户年龄。
- 收入 (income): 自变量,客户年收入 (单位:千元)。
SPSS 代码示例:
* 导入数据.
GET FILE='C:\customer_data.sav'.
* 数据预处理 (假设数据已经清洗).
* 探索性数据分析.
DESCRIPTIVES VARIABLES=age income buy
/STATISTICS=MEAN STDDEV MIN MAX.
FREQUENCIES VARIABLES=buy
/BARCHART.
* 划分训练集和测试集.
DATA SPLIT FILE RANDOM SEED=12345
/PERCENTAGE TRAINING=70 TEST=30.
* Logistic 回归模型.
LOGISTIC REGRESSION VARIABLES buy WITH age income
/METHOD=ENTER
/CLASSPLOT
/PRINT=GOODFIT CI(95)
/CRITERIA=PIN(.05) POUT(.10) ITERATE(20) CUT(.5).
记住: 这只是一个简单的示例,实际操作中你需要根据具体的数据和问题进行调整。
7、学习建议
当涉及到具体的学习资源时,以下是一些建议:
-
实践案例:寻找一些实际的数据集,并跟着教程一步一步地进行操作。这样可以将理论知识应用到实际情境中,加深对SPSS的理解。你可以在一些开放数据平台上找到各种类型的数据集,例如Kaggle、UCI Machine Learning Repository等。
-
SPSS帮助文档:SPSS自带的帮助文档非常详细,可以作为学习的重要参考资料。你可以通过菜单栏中的"帮助"选项访问到SPSS的帮助文档。文档中包含了对每个功能和操作的详细说明,以及示例和案例。
-
书籍和教材:有很多关于SPSS和数据分析的书籍和教材可以作为参考资料。一些经典的书籍包括《SPSS Survival Manual》、《Discovering Statistics Using SPSS》等。这些书籍通常会从基础知识开始介绍,逐步深入,同时提供实例和练习题供你练习。
-
在线资源:互联网上有很多免费或付费的在线资源可以帮助你学习SPSS和数据分析。一些知名的在线学习平台如Coursera、Udemy、edX等提供了相关的课程和教学视频。此外,还有一些专门的数据分析网站和论坛,如Stack Overflow、Cross Validated等,可以在其中寻找答案和与其他学习者交流。
综上所述,通过实践、查阅SPSS帮助文档、参考书籍和教材以及利用在线资源,你将能够更加深入地学习和掌握SPSS和数据分析的技能。
四、总结
在本次实训中,我们将深入探索Logistic回归模型,这是一种常用的统计方法,用于预测和解释二分类变量的概率。通过使用SPSS软件,我们将学习如何构建和分析分类模型,以便更好地理解自变量与因变量之间的关系,并能够预测新的观测数据的分类。
本次实训的目标是让您熟悉SPSS软件的使用,并掌握Logistic回归模型的建立和解释。我们将按照一般的实训流程,逐步引导您完成数据准备、模型构建、模型评估和解释等步骤。
Logistic回归模型在医学、社会科学、市场营销等领域有着广泛的应用。通过本次实训,您将能够掌握Logistic回归模型的基本原理和操作方法,为未来的研究和实践提供有力的支持。
码文不易,本篇文章就介绍到这里,如果想要学习更多Java系列知识,点击关注博主,博主带你零基础学习Java知识。与此同时,对于日常生活有困扰的朋友,欢迎阅读我的第四栏目:《国学周更—心性养成之路》,学习技术的同时,我们也注重了心性的养成。