Day-06-数据库存储引擎知识
- 1、数据库联合索引应用
- 2、数据库索引扩展信息(扩展列信息说明)
- 3、数据库索引应用总结
- 4、数据库存储引擎概述
- 5、数据库存储引擎种类
- 6、数据库存储引擎特性(Innodb)Innodb vs MyISAM
- 7、数据库存储引擎应用
- 8、数据库存储引擎结构
01.数据库联合索引应用
02.数据库索引扩展信息
03.数据库索引应用总结(索引引擎知识补充-菜单)
04.数据库存储引擎概述
05.数据库存储引擎种类 MyISAM Innodb
06.数据库存储引擎特性
07.数据库存储引擎应用
08.数据库存储引擎结构(磁盘结构部分–表空间–一大波名词知识–底层原理知识)
1、数据库联合索引应用
作业题目:
01 利用子查询,实现以下效果
#建表语句
CREATE TABLE empsalary(
`depname` varchar(20),
`empno` bigint(20),
`salary` int(10),
`enroll_date` date
);
#插入测试数据
INSERT INTO empsalary VALUES('develop',10,5200,'2007/08/01');
INSERT INTO empsalary VALUES('sales',1,5000,'2006/10/01');
INSERT INTO empsalary VALUES('personnel',5,3500,'2007/12/10');
INSERT INTO empsalary VALUES('sales',4,4800,'2007/08/08');
INSERT INTO empsalary VALUES('sales',6,5500,'2007/01/02');
INSERT INTO empsalary VALUES('personnel',2,3900,'2006/12/23');
INSERT INTO empsalary VALUES('develop',7,4200,'2008/01/01');
INSERT INTO empsalary VALUES('develop',9,4500,'2008/01/01');
INSERT INTO empsalary VALUES('sales',3,4800,'2007/08/01');
INSERT INTO empsalary VALUES('develop',8,6000,'2006/10/01');
INSERT INTO empsalary VALUES('develop',11,5200,'2007/08/15');
# 查询数据信息;
mysql> select * from empsalary;
+-----------+-------+--------+-------------+
| depname | empno | salary | enroll_date |
+-----------+-------+--------+-------------+
| develop | 10 | 5200 | 2007-08-01 |
| sales | 1 | 5000 | 2006-10-01 |
| personnel | 5 | 3500 | 2007-12-10 |
| sales | 4 | 4800 | 2007-08-08 |
| sales | 6 | 5500 | 2007-01-02 |
| personnel | 2 | 3900 | 2006-12-23 |
| develop | 7 | 4200 | 2008-01-01 |
| develop | 9 | 4500 | 2008-01-01 |
| sales | 3 | 4800 | 2007-08-01 |
| develop | 8 | 6000 | 2006-10-01 |
| develop | 11 | 5200 | 2007-08-15 |
+-----------+-------+--------+-------------+
# 想要的结果
# 实现要求如下
+-------+-----------+-----------+-------+--------+-------------+
| sum | avg | depname | empno | salary | enroll_date |
+-------+-----------+-----------+-------+--------+-------------+
| 25100 | 5020.0000 | develop | 10 | 5200 | 2007-08-01 |
| 25100 | 5020.0000 | develop | 7 | 4200 | 2008-01-01 |
| 25100 | 5020.0000 | develop | 9 | 4500 | 2008-01-01 |
| 25100 | 5020.0000 | develop | 8 | 6000 | 2006-10-01 |
| 25100 | 5020.0000 | develop | 11 | 5200 | 2007-08-15 |
| 7400 | 3700.0000 | personnel | 5 | 3500 | 2007-12-10 |
| 7400 | 3700.0000 | personnel | 2 | 3900 | 2006-12-23 |
| 20100 | 5025.0000 | sales | 1 | 5000 | 2006-10-01 |
| 20100 | 5025.0000 | sales | 4 | 4800 | 2007-08-08 |
| 20100 | 5025.0000 | sales | 6 | 5500 | 2007-01-02 |
| 20100 | 5025.0000 | sales | 3 | 4800 | 2007-08-01 |
+-------+-----------+-----------+-------+--------+-------------+
方法一:左外连接
select aa.sum,aa.avg,b.depname,b.empno,b.salary,b.enroll_date
from empsalary b
left join
( select t.depname,sum(salary) sum,count(1) cn,sum(salary)/count(1) avg
from empsalary t
group by t.depname) aa
on b.depname=aa.depname order by aa.sum desc;
方法二:内连接
select * from
(select sum(salary),avg(salary),depname
from oldboy.empsalary
group by depname) as b ,oldboy.empsalary as c
where b.depname=c.depname;
方法三:(PostgreSQL解题方法)
select sum(salary) OVER (PARTITION BY depname) as sum,avg(salary) OVER (PARTITION By depname) as avg ,depname,empno,salary,enroll_date from empsalary;
-- partition by与分组函数 group by的区别在于
group by 会合并聚合分组信息
partition by 不会合并聚合分组信息,结合开窗函数over会对应字段重复显示
- 联合索引部分覆盖
- 需要满足最左原则;
- 需要定义条件信息时,将所有联合索引条件部分引用;
情况一:联合索引列没有全部用上
mysql> desc select * from t100w where num=339934;

– 联合索引列只应用了部分信息
说明:进行联合索引覆盖查询时,区间范围列不是最后一列,索引查询匹配只统计到区间范围匹配(不等值)列,也属于部分覆盖;
desc select * from t100w where num=339934 and k2='ej';

说明:进行联合索引覆盖查询时,查询索引列是不连续的,索引查询匹配只统计到缺失列前,也属于部分覆盖;
– 联合索引列应用有缺失,也会出现部分覆盖
情况二:联合索引中间列,应用了范围或模糊查询
mysql > desc select * from t100w where num=339934 and k1<'yb' and k2='nokl';

- 联合索引全不覆盖
- 需要定义条件信息时,将所有联合索引条件都不做引用;
情况一:查询数据没有应用联合索引列;
mysql> desc select * from t100w;
情况二:联合索引最左列应用了范围查询;
mysql> desc select * from t100w where num<339934 ;
说明:进行联合索引全不覆盖查询时,区间范围列出现在了第一列,也属于全不覆盖索引
情况三:联合索引最左列没有应用,但是应用了其它列信息;
mysql> desc select * from t100w where k2='ej';
说明:进行联合索引全不覆盖查询时,缺失最左列索引条件信息时,也属于全不覆盖索引
2、数据库索引扩展信息(扩展列信息说明)
Extar:在此列会显示索引优化功能是否使用,显示是否应用临时表,显示排序信息
PS:一旦出现排序信息,就会对CPU资源有消耗,
哪些查询语句情况涉及到排序操作:
- 情况一:查询语句中含有 order by ,表示触发式的排序;
- 情况二:查询语句中含有 group by,表示隐藏式的排序;
- 情况三:查询语句中含有 DISTINCT,表示会先进行排序后再取消重复;
mysql> desc select * from city where countrycode='CHN' order by population;
+----+-------------+-------+------------+------+---------------+-------------+---------+-------+------+----------+---------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+-------------+---------+-------+------+----------+---------------------------------------+
| 1 | SIMPLE | city | NULL | ref | CountryCode | CountryCode | 12 | const | 363 | 100.00 | Using index condition; Using filesort |
+----+-------------+-------+------------+------+---------------+-------------+---------+-------+------+----------+---------------------------------------+
1 row in set, 1 warning (0.00 sec)
# 如何解决排序问题
mysql> alter table city add index idx_co_po(countrycode,population);
Query OK, 0 rows affected (0.03 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> desc select * from city where countrycode='CHN' order by population;
+----+-------------+-------+------------+------+-----------------------+-----------+---------+-------+------+----------+-----------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+-----------------------+-----------+---------+-------+------+----------+-----------------------+
| 1 | SIMPLE | city | NULL | ref | CountryCode,idx_co_po | idx_co_po | 12 | const | 363 | 100.00 | Using index condition |
+----+-------------+-------+------------+------+-----------------------+-----------+---------+-------+------+----------+-----------------------+
1 row in set, 1 warning (0.00 sec)
# 特殊情况说明:在order by信息出现在group by之后,是无法实现索引优化处理的
3、数据库索引应用总结
01 建立索引原则规范(DBA运维规范)
- 数据表中必须要有主键索引(创建表时指定),建议是与业务无关的自增列;
- 数据表中某些列若经常作为 where/order by/group by/join on/distinct条件信息,最好将相应列设置索引(产品功能/用户行为)
- 数据表中最好使用唯一值多的列作为索引,如果索引列重复值较多,可以考虑使用联合索引;(最左列-减少回表次数 - 减少磁盘IO)
- 数据表中列值长度较长的索引列,建议可以使用前缀索引;(防止索引树层次过高)
- 数据表中不建议建立大量索引,最好降低索引条目,不要创建无用索引,不常用的索引要定期清理(percona toolkit)
- 数据表中的索引信息做调整维护时,尽量避开业务繁忙期,或者通过软件工具做调整维护(pt-ost)
- 数据表中的联合索引创建过程要遵循索引最左原则;
02 索引应用失效情况(开发工作规范)
- 数据表信息查询时,没有设置查询条件信息;
- 数据表信息查询时,查询的条件没有建立索引;
select * from t1;
select * from t1 where id=1001 or 1=1; -- 执行SQL注入语句问题
03 查询结果规范要求
当查询结果集数据是原表中的大部分数据,超过了总行数的25%,优化器便自动判断没必要走索引了,因为可以借助预读功能获取数据
可以通过精细查找指定数据的范围,从而达到优化的效果;(read_head预读相关参数)
04 索引失效情况处理
当频繁的对数据表中索引列值做修改、删除等操作时,会导致索引统计信息过旧或不真实,最终造成索引功能失效;
本身索引是有自我维护的机制能力,但并不是实时调整更新的,需要有一定的间隔时间做调整;
一般索引失效的表现情况为:select查询语句平常查询时很快,但突然某天执行就变慢了,就是索引失效了,统计数据不真实;
索引统计的信息存储位置:
innodb_index_stats
innodb_table_stats
-- mysql库中的相应表
当索引失效时,可以使用命令重新进行统计信息获取,使索引功能再次生效:
mysql > analyze table world.city; -- 手动重新构建索引树
-- 表示立即更新过久的统计信息(也可以将索引删除重建)
在查询条件过程中,使用了函数信息在索引列上,或者对索引进行了运算(+ - * / !等),都会导致索引功能失效,建议尽量避免;
# 错误举例:
select * from test where id-1=9;
# 正确举例:
select * from test where id=10;
-- 总之尽量避免条件信息出现 算数运算 函数运算 子查询
# 子查询补充:
# 子查询指一个查询语句嵌套在另一个查询语句内部的查询
# SQL 中子查询的使用大大增强了 SELECT 查询的能力,因为很多时候查询需要从结果集中获取数据
# 查询中国城市人口大于北京人口数量的城市信息
查询01:查询中国 北京的人口数量
select population from city where countrycode='CHN' and name='Peking';
查询02:查询中国 基于北京人口数量 大于北京人口数量城市
select * from city where countrycode='CHN' and population > 'xxx'
mysql> select * from city where CountryCode='CHN' and population > (select population from city where CountryCode='CHN' and name='Peking');
在查询数据信息过程中,出现了隐式转换也会导致索引失效;
# 创建测试数据表
mysql> create table test (id int,name varchar(20),telno char(11));
mysql> insert into test values (1,'a','110'),(2,'b','123'),(3,'c','120'),(4,'d','119'),(5,'e','130');
# 创建索引信息
mysql> alter table test add index idx(telno);
# 查询数据信息
mysql> select * from test where telno='110';
mysql> select * from test where telno=110;
-- 上面两条语句都能查看到结果信息,但是有一条语句是没有走索引的
在查询条件过程中,应用了特殊数据匹配方法时,也会导致索引失效,一般是辅助索引失效;
<> , not in , like "%_"
-- 应用以上特殊符号信息,也会导致辅助索引失效
索引失效情况:
情况一:有大量的更新或删除操作,会导致索引失效
analyze table world.city;--手动重新构建索引树
情况二:条件中应用了运算符或者 应用了函数信息
参考文档资料
数据库索引知识补充-彩蛋:
01 数据库服务索引功能特性 8.0
- 在新的数据库服务中,支持不可见索引功能
应用场景
案例:企业中某个业务的表结构做了调整(添加列)-> 创建索引 -> 批量修改操作 (操作一半报错中断了);
触发索引锁机制
设置方法:
# 在创建索引或修改索引时,可以设置不可见或可见索引(默认)
mysql> alter table test alter index idx invisible/visible;
-- 已经有索引了,进行调整
mysql> alter table test add index idx1(name) invisible/visible;
-- 创建索引时,设置索引可见功能
-- 在做批量数据导入时,辅助索引信息可以设置为不可见,优化器就不会加载识别索引信息
mysql> alter table city alter index CountryCode invisible;
- 索引倒序
在早期数据库中,所有索引列创建索引信息,都是按照从小到大顺序进行排序,在最新数据库中,可以灵活调整索引排序方式;
mysql> alter table xiaoQ add index idx01(k1,k2 desc,k3);
Query OK, 0 rows affected (0.04 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> desc select * from xiaoQ order by k1,k2 desc,k3;
+----+-------------+-------+------------+-------+---------------+-------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+-------+---------+------+------+----------+-------------+
| 1 | SIMPLE | xiaoQ | NULL | index | NULL | idx01 | 15 | NULL | 4 | 100.00 | Using index |
+----+-------------+-------+------------+-------+---------------+-------+---------+------+------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
02 数据库服务自主优化能力
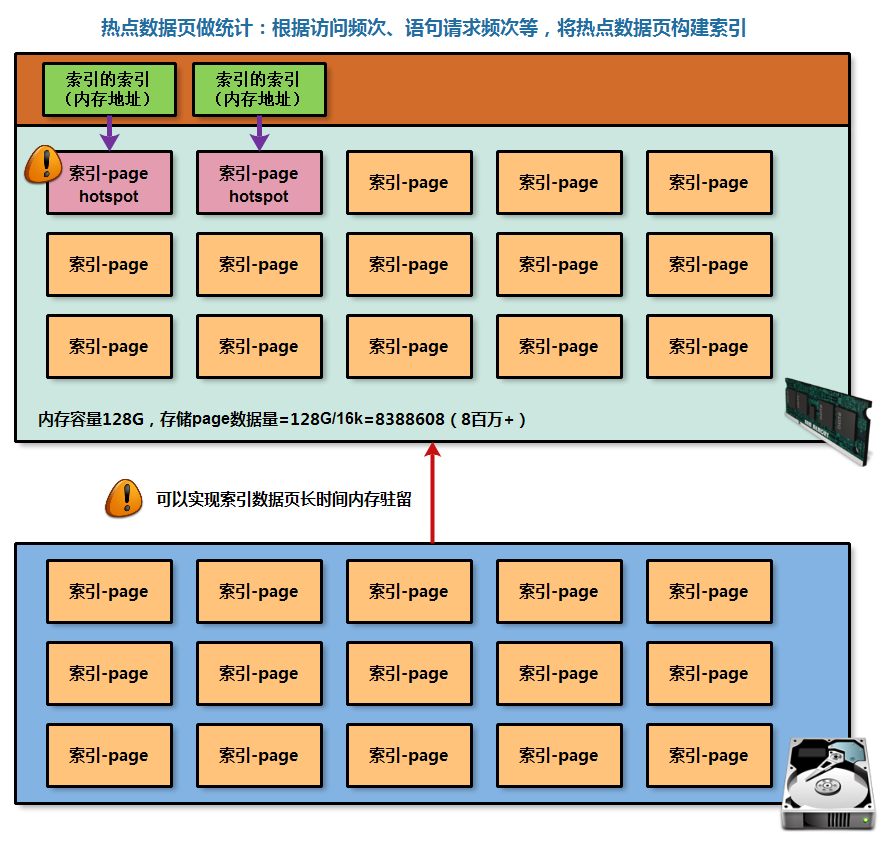
- 自主优化功能一:AHI(索引的索引)
AHI全称(中文名称)为自适应的hash索引/散列索引,用于在内存中建立索引,快速锁定内存中的热点数据索引页位置;
正常情况下,所有数据都是存储在磁盘中的,如果想访问读取相应磁盘的数据信息,都是会将磁盘数据调取存放在内存中,即消耗IO;
对于数据库服务而言,想要读取数据信息,也是会从磁盘中读取存储页,在放入内存中被数据库服务进行访问,索引访问也是一样的;
但是当数据页大量的被存放在内存中后,从大量内存中的数据页找到想要的,也是比较困难的事情;
因此,可以对内存中经常被访问数据索引页建立一个hash索引,从而可以帮助数据库服务快速定位内存中想要找的索引数据页;
作用说明:
给索引创建索引;
配置参数:
mysql> show variables like 'innodb_adaptive_hash_index';
+----------------------------+-------+
| Variable_name | Value |
+----------------------------+-------+
| innodb_adaptive_hash_index | ON |
+----------------------------+-------+
1 row in set (0.05 sec)
- 自主优化功能二:CHANGE BUFFER
作用说明:
临时缓存变化索引数据信息
配置参数:
mysql> show variables like '%change_buffer%';
+-------------------------------+-------+
| Variable_name | Value |
+-------------------------------+-------+
| innodb_change_buffer_max_size | 25 | -- 设置缓冲区大小
| innodb_change_buffering | all | -- none 关闭
+-------------------------------+-------+
2 rows in set (0.01 sec)
-- all: 默认值。开启buffer inserts、delete-marking operations、purges
-- none: 不开启change buffer
- 自主优化功能三:ICP (索引下推)
作用说明:
索引下推功能:主要在查询数据时,用于减少IO消耗,减少回表次数
配置参数:
mysql> show variables like '%switch%';
mysql> set global optimizer_switch='index_condition_pushdown=off/on';
-- 实现测试练习完,需要恢复开启(操作可以省略)
# 测试练习
mysql> select * from t100w where k1='qj' and k2 like '%v%';
mysql> desc select * from t100w where k1='qj' and k2 like '%v%';
-- extra列显示using index condition信息,表示应用了索引下推
# 进行压测
mysqlslap --defaults-file=/etc/my.cnf --concurrency=100 --iterations=1 --create-schema='oldboy' --query="select * from t100w where k1='qj' and k2 like '%v%" engine=innodb --number-of-queries=20000 -uroot -p123456 -h192.168.30.101 -verbose
- 自主优化功能四:MRR
MRR,全称(Multi-Range Read Optimization 多范围读取操作);
简单来说:MRR 通过把「随机磁盘读」,转化为「顺序磁盘读」,从而提高了索引查询的性能。
描述说明中涉及到的问题:
① 为什么要把随机读转换为顺序读? 减少磁盘压力
② 为什么顺序读就能提升读取性能?
③ 如何将随机读去转换为顺序读取? MRR
MRR功能配置信息:
mysql > set optimizer_switch='mrr=on';
mysql > set global optimizer_switch='mrr_cost_based=off/on';
-- 用来告诉优化器,要不要基于使用 MRR的成本,考虑使用MRR是否值得(cost-based choice)
对于只返回一行数据的查询,是没有必要 MRR 的,而如果你把 mrr_cost_based 设为 off,那优化器就会通通使用 MRR,这在有些情况下是很傻的,所以建议这个配置还是设为on,毕竟优化器在绝大多数情况下都是正确的。

4、数据库存储引擎概述
作用:数据库存储引擎主要负责数据信息有序存储和调取(类似文件系统)
存储引擎结构
- 存储数据角度-段区页 - 磁道 - block - 扇区
- 存储架构角度-表空间信息 - 各种表空间文件
5、数据库存储引擎种类
在各种版本的数据库服务中,是有多种存储引擎可以应用的,以MySQL数据库服务为例,可以使用命令查看可以应用存储引擎:
mysql> show engines;
+--------------------+---------+----------------------------------------------------------------+--------
| Engine | Support | Comment | Transac
+--------------------+---------+----------------------------------------------------------------+--------
| FEDERATED | NO | Federated MySQL storage engine | NULL
| MEMORY | YES | Hash based, stored in memory, useful for temporary tables | NO
| InnoDB | DEFAULT | Supports transactions, row-level locking, and foreign keys | YES
| PERFORMANCE_SCHEMA | YES | Performance Schema | NO
| MyISAM | YES | MyISAM storage engine | NO
| MRG_MYISAM | YES | Collection of identical MyISAM tables | NO
| BLACKHOLE | YES | /dev/null storage engine (anything you write to it disappears) | NO
| CSV | YES | CSV storage engine | NO
| ARCHIVE | YES | Archive storage engine | NO
+--------------------+---------+----------------------------------------------------------------+--------
9 rows in set (0.00 sec)
在实际场景中,99.9%都是使用innodb存储引擎,并且在最新版8.0数据库中,所有mysql数据库中的表对应的引擎也都改为了innodb;
如果在面试环节中,面试官询问你:
-
列举出mysql中支持的存储引擎种类:InnoDB、MyISAM、CSV、MEMORY;
-
列举出mysql分支产品的存储引擎种类:在percone、mariadb数据库中,可能还会应用TokuDB MyRocks Rocksdb存储引擎
从特点上可以支持innodb引擎的特性(支持事务),并且数据压缩比比较高(15倍),数据插入性能比较强(5~6倍);
以上存储引擎就比较适合于zabbix监控类的平台,归档数据、历史数据存储业务等,数据量级比较大的情况;
监控服务部署tokuDB存储引擎参考链接:https://www.cnblogs.com/oldboy-heqing/articles/16891210.html
6、数据库存储引擎特性(Innodb)Innodb vs MyISAM
在数据库服务领域,大部分场景下都会使用innodb存储引擎,是因为innodb存储引擎具有一定优秀特性:
| 序号 | 特性 | 解释说明 |
|---|---|---|
| 01 | 数据访问特性 | 支持多版本并发控制特性(MVCC),支持行级锁控制并发 |
| 02 | 数据索引特性 | 支持聚簇索引/辅助索引特性,可以组织存储数据和优化查询(IOT) |
| 03 | 数据事务特性 | 支持事务概念特性,可以实现数据的安全保证 |
| 04 | 数据缓冲特性 | 支持多缓冲区功能,自适应hash索引(AHI) |
| 05 | 数据迁移特性 | 支持复制数据中的高级功能特性,支持数据备份恢复的热备 |
| 06 | 服务自愈特性 | 支持自动故障恢复(CR-Crash Recovery) |
| 07 | 数据存储特性 | 支持数据双写机制(Double write) 数据存储有关的安全机制 |
如果在面试环节中,面试官询问你:
-
InnoDB核心特性有哪些,以及与MyISAM存储引擎之间的区别:
InnoBD支持:事务、mvcc、聚簇索引、外键、缓冲区、AHI、DW;MyISAM均不支持
InnoDB支持:行级锁,MyISAM只支持表级锁;
InnoDB支持:数据热备,可以保证业务正常运行,对业务影响低,MyISAM只支持温备份,需要锁表备份;
InnoDB支持:支持CR自动故障恢复,宕机自动恢复,数据安全和一致性可以得到保证;MyISAM不支持,宕机可能丢失当前数据;
企业实际场景案例分析说明:
案例说明01:某期学员负责运维+MySQL相关工作;
平台环境:zabbix 3.2 + centos 7.3 + mariadb 5.5(InnoDB引擎),利用监控平台,监控了2000多个节点服务;
问题现象:每隔一段时间zabbix服务就会运行操作很卡,每隔3-4个月,都要重新部署zabbix,存储空间经常爆满(ibdata1 400~500G);ibdate1 ibdata1-01
异常分析:
- zabbix版本过低,建议将zabbix程序进行升级更新;
- zabbix使用的数据版本过低,建议将数据库版本进行升级,因为新版本数据库的原生态环境就比旧版本好些;
- 在数据库5.5版本中,在没有做数据存储调配时,数据库所有数据都会保存到ibdata1文件中;
- 在ibdata1文件中的数据空间,不会因为数据库中的数据删除,产生数据回缩的效果,即空间不释放;
优化建议:
- 数据库版本升级到percona 5.7+(mariadb 10.x+),zabbix软件升级更高版本;
- 数据库服务存储引擎改为tokudb;
- 监控数据最好按月份进行数据切割(二次开发zabbix程序,数据保留机制功能重写,并且数据库分表存储)
- 将数据库服务的binlog功能关闭(双1);
- 数据库服务相关内存优化参数调整;
优化思路:
- zabbix程序原生态支持TokuDB,经过压力测试,5.7要比5.5数据库版本性能高出 2~3倍;
- 使用TokuDB作为数据库存储引擎,insert数据比innodb要快的多,数据压缩比也要比Innodb高;
- 监控数据按月份进行切割(分区),为了能够truncate每个分区表,以便立即释放存储空间;
- 将数据库服务binlog关闭,是为了减少无关日志的记录,避免磁盘IO的消耗,以及节省磁盘空间的使用;
- 参数优化调整,主要是对安全性参数或内存相关参数调整,提高数据库服务运行性能;
企业案例资料参考:
https://mariadb.com/kb/en/installing-tokudb
https://docs.percona.com/percona-server/5.7/tokudb/tokudb_intro.html
https://www.percona.com/doc/percona-server/5.7/tokudb/tokudb_installation.html
案例说明02:企业客户实际数据库需求
平台环境:centos 5.8+mysql 5.0版本,MyISAM存储引擎+网站架构LNMP,数据量50G左右
问题现象:业务并发压力大的时候,整体网站访问非常卡,还会出现数据库服务宕机情况,造成部分数据丢失
问题分析:
- MyISAM存储引擎具有表级锁,在高并发访问时,会频繁出现锁等待情况;
- MyISAM存储引擎不支持事务机制,在断电或宕机时,会有可能丢失数据信息;
优化建议:
- 数据库服务版本进行升级,从5.0升级到更高的版本;ok
- 数据库服务升级后,迁移所有表数据到新环境(表空间迁移),调整存储引擎为InnoDB;
- 数据库服务开启双1安全参数;
- 数据库服务进行重构主从架构
7、数据库存储引擎应用
命令操作:
存储引擎设置:
# 永久修改存储引擎配置
[root@xiaoQ-01 ~]# vim /etc/my.cnf
[mysqld]
default_storage_engine=InnoDB
-- 重启数据库服务生效
存储引擎查看:
# 查看数据库可用存储引擎
mysql> show engines;
# 查看数据库默认存储引擎
mysql> select @@default_storage_engine;
+--------------------------+
| @@default_storage_engine |
+--------------------------+
| InnoDB |
+--------------------------+
1 row in set (0.00 sec)
数据表存储引擎配置修改:(具体表的存储引擎)
# 创建表时设置存储引擎
mysql > create table xxx (id int) engine=innodb charset=utf8mb4;
-- 常见表信息时,单独设置存储引擎
# 修改表示设置存储引擎
mysql > alter table world.xxx engine=myisam;
mysql > alter table world.xxx engine=innodb;
-- 修改表中存储引擎信息
数据表存储引擎信息查看:(具体表的存储引擎)
# 查看建表语句获取存储引擎信息
mysql > show create table city;
# 查看information_schema数据库获取存储引擎信息
mysql > select table_schema,table_name,engine from information_schema.tables where table_schema not in('sys','mysql','information_schema','performance_schema')
8、数据库存储引擎结构
什么是表空间:
表空间概念是出自于Oracle数据库机制,主要利用表空间可以灵活扩容存储数据
不同版本演变过程:了解
数据库服务存储引擎结构的介绍,可以依据官方图示参考说明:
https://dev.mysql.com/doc/refman/8.0/en/innodb-architecture.html
1 On-Disk Structures(磁盘结构部分)
在磁盘存储结构中,会使用表空间模式进行数据信息的管理,经常提到的段 区 页概念也是属于表空间的逻辑结构;
表空间的概念源于oracle数据库,最初的目的是为了能够更好的做存储的扩容;因此数据库的表空间技术类似磁盘管理的LVM技术;
在数据库服务中所使用的表空间也被划分出几种种类:
类型一:共享(系统)表空间
属于数据库服务5.5版本时默认的表空间应用,具体数据存储数据方式为:ibdata1~ibdataN
ibdata共享表空间在各个版本之间的作用区别:
| 数据库版本 | 存储数据 | 解释说明 |
|---|---|---|
| MySQL 5.5版本 | 系统相关数据 | 全局数据字典信息(表基本结构信息、状态系统参数、属性)、undo回滚日志(记录撤销操作); Double write buffer信息、临时表信息、changer buffer |
| 用户相关数据 | 业务表数据行、表的索引数据均统一存储在ibdata1中,实现集中管理 数据表中数据清理后,ibdata1也不会释放磁盘空间 | |
| MySQL 5.6版本 | 系统相关数据 | 全局数据字典信息(表基本结构信息、状态系统参数、属性)、undo回滚日志(记录撤销操作); Double write buffer信息、临时表信息、changer buffer |
| 用户相关数据 | 共享表空间只存储系统数据,用户相关数据被独立管理了(独立表空间管理) | |
| MySQL 5.7版本 | 系统相关数据 | 全局数据字典信息 undo回滚日志 Double write buffer信息、changer buffer 临时表信息被独立出来了,undo也可以设定为独立 |
| 用户相关数据 | 共享表空间只存储系统数据,用户相关数据被独立管理了(独立表空间管理) | |
| MySQL 8.0.11 | 系统相关数据 | Double write buffer信息、changer buffer undo回滚日志信息被独立出来了,数据字典信息也不再集中存储管理了 |
| 用户相关数据 | 共享表空间只存储系统数据,用户相关数据被独立管理了(独立表空间管理) | |
| MySQL 8.0.20 | 系统相关数据 | changer buffer Double write buffer信息被独立出来了 |
结构一:共享表空间中(ibdata1 ibdata2 ibdata)
对应的文件信息:ibdata1
早期:所有数据库有关的数据统一存储在共享表空间文件中
目前:共享表空间中数据已经做了拆分,此时只保留change buffer数据信息进行保存
- 扩容共享表空间操作:
扩容前共享表空间信息查看:
mysql> select @@innodb_data_file_path;
+-------------------------+
| @@innodb_data_file_path |
+-------------------------+
| ibdata1:12M:autoextend |
+-------------------------+
1 row in set (0.00 sec)
-- 可以在初始安装好数据库服务后,进行修改配置为两个ibdate文件,每个共享表空间文件占用2G,总共占用4个G空间
mysql> select @@innodb_autoextend_increment;
+-------------------------------+
| @@innodb_autoextend_increment |
+-------------------------------+
| 64 |
+-------------------------------+
1 row in set (0.00 sec)
-- 查看参数信息说明:ibdata1文件,默认初始大小12M,不够用会自动扩展,默认每次扩展64M
共享表空间的扩容操作方法:
# 编写数据库配置文件信息
vim /etc/my.cnf
[mysqld]
innodb_data_file_path=ibdata1:12M;ibdata2:100M;ibdata3:100M:autoextend
-- 需要注意的是ibdata1文件大小必须和实际数据库要存储的数据相匹配,否则会出现如下报错信息
[ERROR] [MY-012264] [InnoDB] The innodb_system data file './ibdata1' is of a different size 768 pages (rounded down to MB) than the 4864 pages specified in the .cnf file!
-- 表示ibdate1指定大小超过了原有ibdata1实际的大小尺寸
# 查看配置信息是否生效
mysql> select @@innodb_data_file_path;
+---------------------------------------------------------------------+
| @@innodb_data_file_path |
+---------------------------------------------------------------------+
| ibdata1:12M;/data02/ibdata2:100M;/data03/ibdata3:100M:autoextend |
+---------------------------------------------------------------------+
1 row in set (0.00 sec)
数据库初始化时设置共享表空间容量建议:
| 序号 | 版本信息 | 建议说明 |
|---|---|---|
| 01 | MySQL 5.7 | 设置共享表空间2~3个,大小建议512M或1G,最后一个指定为自动扩展 |
| 02 | MySQL 8.0 | 设置共享表空间1个即可,大小建议512M或1G |
共享表空间的初始设置方法:
# 模拟初始化清理数据
[root@xiaoQ-01 ~]# /etc/init.d/mysqld stop
[root@xiaoQ-01 ~]# rm -rf /data/3306/data/*
# 模拟初始化配置文件
[root@xiaoQ-01 ~]# vim /etc/my.cnf
[mysqld]
innodb_data_file_path=ibdata1:100M;ibdata2:100M;ibdata3:100M:autoextend
# 模拟初始化操作命令
[root@xiaoQ-01 ~]# mysqld --initialize-insecure --user=mysql --basedir=/usr/local/mysql --datadir=/data/3306/data
# 模拟初始化重启服务
[root@xiaoQ-01 ~]# /etc/init.d/mysqld start
结构二:独立表空间
对应文件信息:表名.ibd
作用:主要用于存储表的结构和数据信息
在数据库服务5.6版本中,针对用户数据,可以进行单独的存储管理,存储表的数据行和索引等相关信息;
独立表空间在各个版本之间的作用区别:
- 在数据库服务8.0版本前
用户表包含三个部分组成(表.ibd 表.frm ibdata1-全局数据字典信息存储);
所以在8.0之前,如果想修改表数据结构信息(元数据修改),都会修改frm和ibdata文件信息,每次更新都会锁表(元数据锁);
因为要保证数据一致性,并且两个表均更新完,才能释放解锁,因此在8.0前修改元数据信息,要避开业务繁忙时间段;
- 在数据库服务8.0版本后
用户表数据进行统一存储(表.ibd); 如果想修改表数据结构信息(元数据修改),只会修改ibd文件信息;
此时不需要对两个表文件均更新,只要更新一个文件即可,因此对文件锁的代价降低了,降低了对业务的影响;
独立表空间管理:
- 表空间配置参数信息查看
mysql > select @@innodb_file_per_table;
+---------------------------------+
| @@innodb_file_per_table |
+---------------------------------+
| 1 |
+---------------------------------+
1 row in set (0.00 sec)
-- 表示每个表就是一个独立文件,进行数据信息的独立存储,不建议进行修改,如果改为0就是所有数据统一存储在共享表空间
-- 当默认设置为1表示所有用户数据,单独存储到ibd文件中/ 当设置为0,会将数据信息存储到ibdata文件
[root@db01 school]# file sc.ibd
sc.ibd: data
[root@db01 school]# ibd2sdi sc.ibd
-- 可以查看独立表空间文件信息(表结构信息)
["ibd2sdi"
,
{
"type": 1,
"id": 393,
"object":
{
"mysqld_version_id": 80026,
"dd_version": 80023,
"sdi_version": 80019,
"dd_object_type": "Table",
"dd_object": {
......
-- 可以看到文件中存储的元数据信息(数据字典信息),并且数据库8.0之后不再有表对应的frm文件信息了
-- 在数据库5.7环境中,每个表数据信息会存储生成两个表 frm ibd
-- frm文件中存储数据表的数据字典信息(元数据信息)
-- ibd文件中存储数据行信息和索引信息
- 表空间配置参数信息修改
mysql > set global innodb_file_per_table=0
-- 设置为0表示利用共享表空间存储用户数据 1表示利用独立表空间存储用户数据
独立表空间文件作用:备份-1天 恢复-1天
01 可以实现快速迁移数据 1000w数据 1行1M 1000w*1M
数据库服务器A oldboy大表 ----- 数据库服务器B oldboy大表
02 当服务程序异常时,可以利用表空间文件修复数据
数据库备份恢复(物理备份-热备/冷备 逻辑备份-mysqldump-热备)
PS:要恢复数据的表结构需要清楚 ibd数据 – 创建好表
实践操作:
步骤一:环境准备
部署两个数据库服务(3306 3307 – 8.0.26)
步骤二:在3306实例中创建数据信息
将t100w数据恢复
获取表结构信息:
CREATE TABLE `t100w` (
`id` int DEFAULT NULL,
`num` int DEFAULT NULL,
`k1` char(2) DEFAULT NULL
`k2` char (4) DEFAULT NULL,
`dt` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
步骤三:在3307实例中创建相同表信息(空表)
CREATE TABLE `t100w` (
`id` int DEFAULT NULL,
`num` int DEFAULT NULL,
`k1` char(2) DEFAULT NULL
`k2` char (4) DEFAULT NULL,
`dt` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
步骤四:在3307实例中,需要解除自己的独立表空间的关系
mysql> alter table oldboy.t100w discard tablespace;
-- 删除t100w表的ibd数据文件信息,但是保留t100w的frm,ibdata1中关于t100w的系统数据
步骤五:将3306实例中独立表空间文件做迁移
cp /data/3306/data/oldboy/t100w.ibd /data/3307/data/oldboy/
chown -R mysql.mysql /data/*
步骤六:在3307实例中,加载迁移后的独立表空间文件
mysql> alter table oldboy.t100w import tablespace;
-- 在目标端加载识别迁移过来的数据文件信息
mysql> select count(*) from t100w;
+----------+
| count(*) |
+----------+
| 1000000 |
+----------+
1 row in set (0.04 sec)
-- 查看数据表中是否有迁移古来的数据信息
案例02:利用表空间迁移功能实现数据损坏恢复
说明:操作系统突然断电了,启动完成后 / 变为只读了,fsck修复文件系统,系统再次重新启动后,mysql启动不了了
结果:造成confulence库在、jira库不见了(备份没有 日志也没开)
服务:jira(bug追踪)、confluence(内部知识库) 、mysql 5.6.33(innodb引擎 使用独立表空间) – LNMT架构
硬件:联想服务器(8核 16G内存 500G存储空间 没有raid),centos 6.8系统
对话描述:
学生:这种情况怎么恢复?
老师:有备份吗?
学生:连二进制日志都没有,没有备份,没有主从
老师:jira数据库数据没什么办法了,只能进行硬盘数据恢复了
学生:jira数据库数据先不用关注,数据磁盘已经拉到中关村处理了
主要是confulence库还想使用,但将生成中的库目录,导入到其他主机上(var/lib/mysql),无法直接访问数据库中数据? /data/3306/data/confulence
老师有没有工具能直接读取数据库目录中的ibd文件内容
老师:我查查,最后发现没有
我们可以尝试下独立表空间迁移
create table xx
alter table coufulence.t1 discard tablespace;
alter table coufulence.t1 import tablespace;
虚拟环境测试可行
问题:confulence库中总共有107张表
困惑:如何创建107张和原来一模一样的表
解决:学生环境中有2016年的历史库,让学生利用mysqldump命令备份confulence历史库
mysqldump -uroot -ppassw0rd -B confulence --no-date > test.sql 只获取所有表结构信息
如果是自研数据库,没有备份怎么办
mysql工具包中,拥有mysqlfrm工具也可以读取frm文件获取表结构
操作步骤一:备份历史数据库的所有表结构信息,并进行恢复
[root@xiaoQ-01 ~]# mysqldump -uroot -ppassw0rd -B confulence --no-date > test.sql
mysql > create database confulence
mysql > source test.sql
操作步骤二:删除空表的独立表空间
select concat("alter table ",table_schema,".",table_name," discard tablespace;") from information_schema.tables where table_schema='confulence'; into outfile '/tmp/discard.sql';
source /tmp/discard.sql
实际执行过程发现,有20-30张表无法成功,主外键关系问题,如果一个表一个表分析表结构,处理外键关系很痛苦
set foreign_key_checks=0
-- 跳过外键检查,从而把有问题的20-30张表的独立表空间也删除了
操作步骤三:拷贝生成中confulence库下的所有表的ibd文件到准备好的环境中并加载识别
select concat("alter table ",table_schema,".",table_name," import tablespace;") from information_schema.tables where table_schema='confulence' into outfile '/tmp/import.sql';
source /tmp/import.sql
操作步骤四:进行数据信息验证
表都可以访问了,数据挽回了出现问题时刻的状态
案例03:mysql 5.7中误删除了ibdata1数据文件,导致数据库服务无法启动;(作业)
说明:如何恢复t100w表中数据,并且假设库中有100张表,而且表结构无法通过show create table获得;
提示:有可能是自研数据库,并且没有数据备份
思路:先获取表结构信息,然后重新建表,删除空表的独立表空间,导入表的数据文件,加载识别表数据信息
操作步骤一:mysql工具包中含有mysqlfrm工具,可以读取frm文件获得表结构;
[root@xiaoQ-01 ~]# ./mysqlfrm /data/3306/data/test/t100w.frm --diagnostic
操作步骤二:将新库中所有独立表空间进行删除
select concat('alter table ',table_schema,'.'table_name,' discard tablespace;') from informatin_schema.tables where table_schema='confluence' into outfile '/tmp/discard.sql';
source /tmp/discard.sql
表空间企业应用案例:
案例01:利用独立表空间进行快速数据迁移(源端 3306/test/t100w --> 目标端 3307/test/t100w)
说明:可以在需要某个表中的数据信息时,可以将数据表的独立表空间数据信息做迁移,在另一个数据库中进行恢复即可
e库下的所有表的ibd文件到准备好的环境中并加载识别**
select concat("alter table ",table_schema,".",table_name," import tablespace;") from information_schema.tables where table_schema='confulence' into outfile '/tmp/import.sql';
source /tmp/import.sql
操作步骤四:进行数据信息验证
表都可以访问了,数据挽回了出现问题时刻的状态
案例03:mysql 5.7中误删除了ibdata1数据文件,导致数据库服务无法启动;(作业)
说明:如何恢复t100w表中数据,并且假设库中有100张表,而且表结构无法通过show create table获得;
提示:有可能是自研数据库,并且没有数据备份
思路:先获取表结构信息,然后重新建表,删除空表的独立表空间,导入表的数据文件,加载识别表数据信息
操作步骤一:mysql工具包中含有mysqlfrm工具,可以读取frm文件获得表结构;
[root@xiaoQ-01 ~]# ./mysqlfrm /data/3306/data/test/t100w.frm --diagnostic
操作步骤二:将新库中所有独立表空间进行删除
select concat('alter table ',table_schema,'.'table_name,' discard tablespace;') from informatin_schema.tables where table_schema='confluence' into outfile '/tmp/discard.sql';
source /tmp/discard.sql
表空间企业应用案例:
案例01:利用独立表空间进行快速数据迁移(源端 3306/test/t100w --> 目标端 3307/test/t100w)
说明:可以在需要某个表中的数据信息时,可以将数据表的独立表空间数据信息做迁移,在另一个数据库中进行恢复即可