🚴前言
对于ChatGPT来说,RLHF是其训练的核心。所谓RLHF,即Reinforcement Learning with Human Feedback,基于人类反馈的强化学习。这项技术通过结合模型自身的生成能力和人类专家的反馈,为改进文本生成质量提供了新的途径。在下面的文章中,将对 大模型与AIGC分论坛 最后一部分做整理与归纳。
在整篇文章中,我们将介绍RLHF这一方法的背景简介、训练数据的收集与清洗、RLHF基础介绍,以及当下流行的开源RLHF的实现。下面开始本文的讲解~👻
一、🎬背景简介
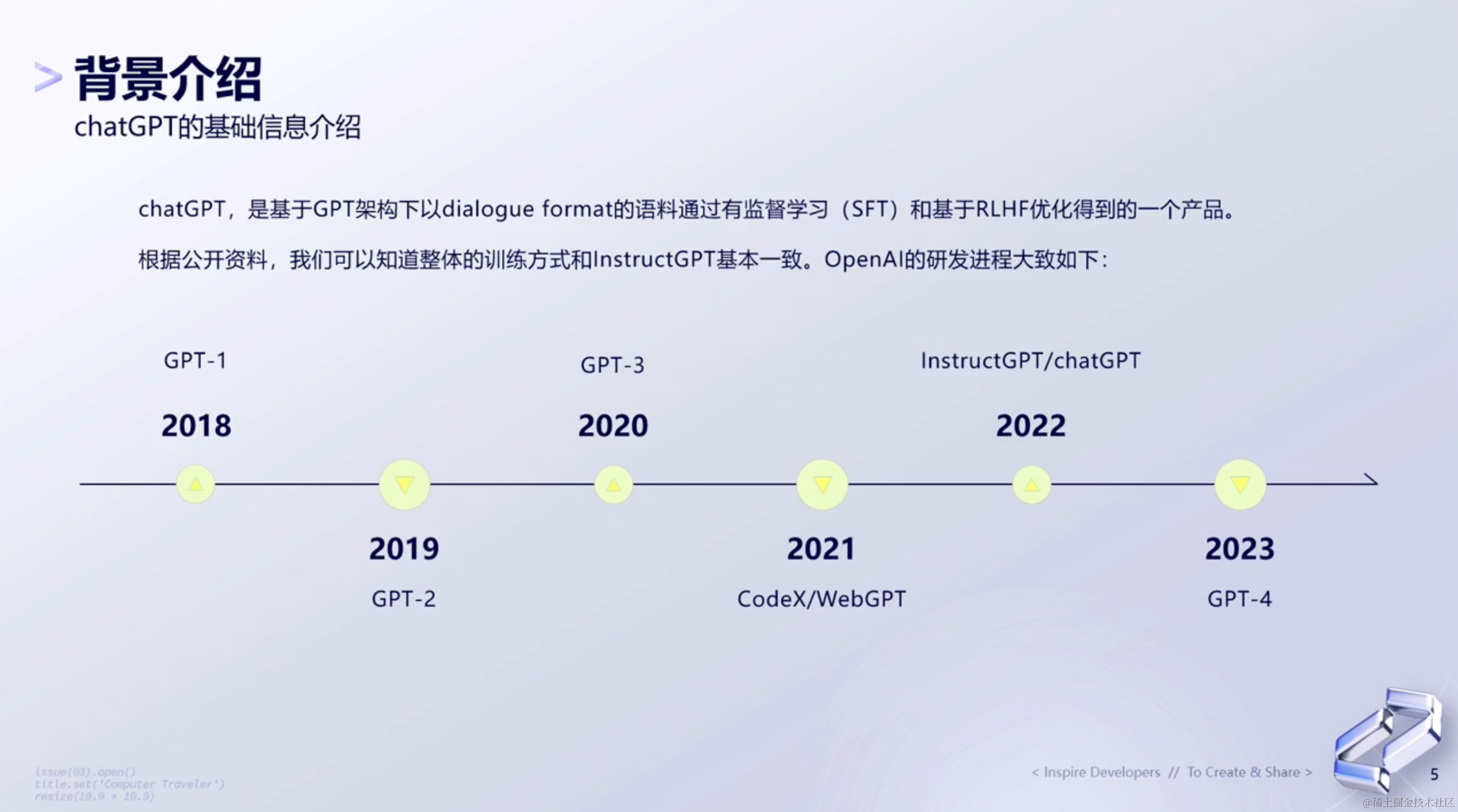
1.1 ChatGPT的基础信息介绍
从GPT1 到 GPT3,全世界几乎很多与ai相关的工作都是在follow openai的。到后面呢,openai其实就不再开源了,很多东西也就都没有放出来了。到2022年的时候,就出现了ChatGPT,然后就引爆了现在大模型的风潮。
从CodeX开始,验证的是语言模型coding的能力,以及推演的能力。而在WebGPT里面,其实就已经在尝试决策上面的能力,它某种意义上是为后续的plugin做前置的验证。
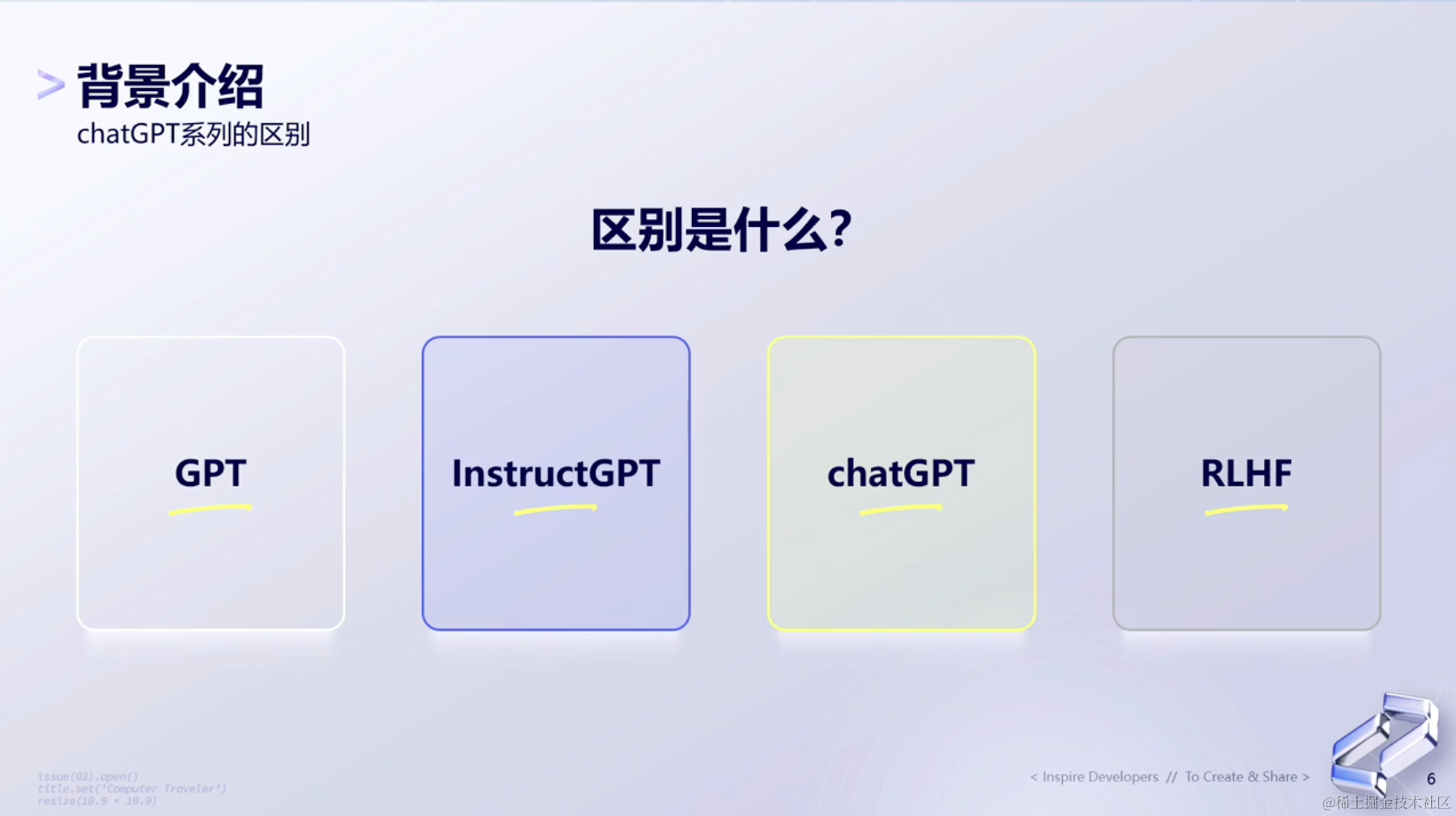
1.2 ChatGPT系列的区别
GPT是个语言模型,而InstructGPT相比于GPT来说,其实是在训练参数上做了一个变换,也就是做Prompt Fine Tune,在指令上面做了一层变化。到这一层开始,用户就可以去下些指令给模型了。
到ChatGPT的时候,算是一个产品化。
然后来到RLHF,它本质上是一个产品化的核心和关键,怎么才能让一个语言模型变得可用,这是RLHF做的事情。
1.3 ChatGPT的训练介绍
ChatGPT的训练需要经过四个步骤:数据收集、Pretrain、SFT和RLHF。四个过程都要经历哪些事情呢?
如下图所示👇🏻:
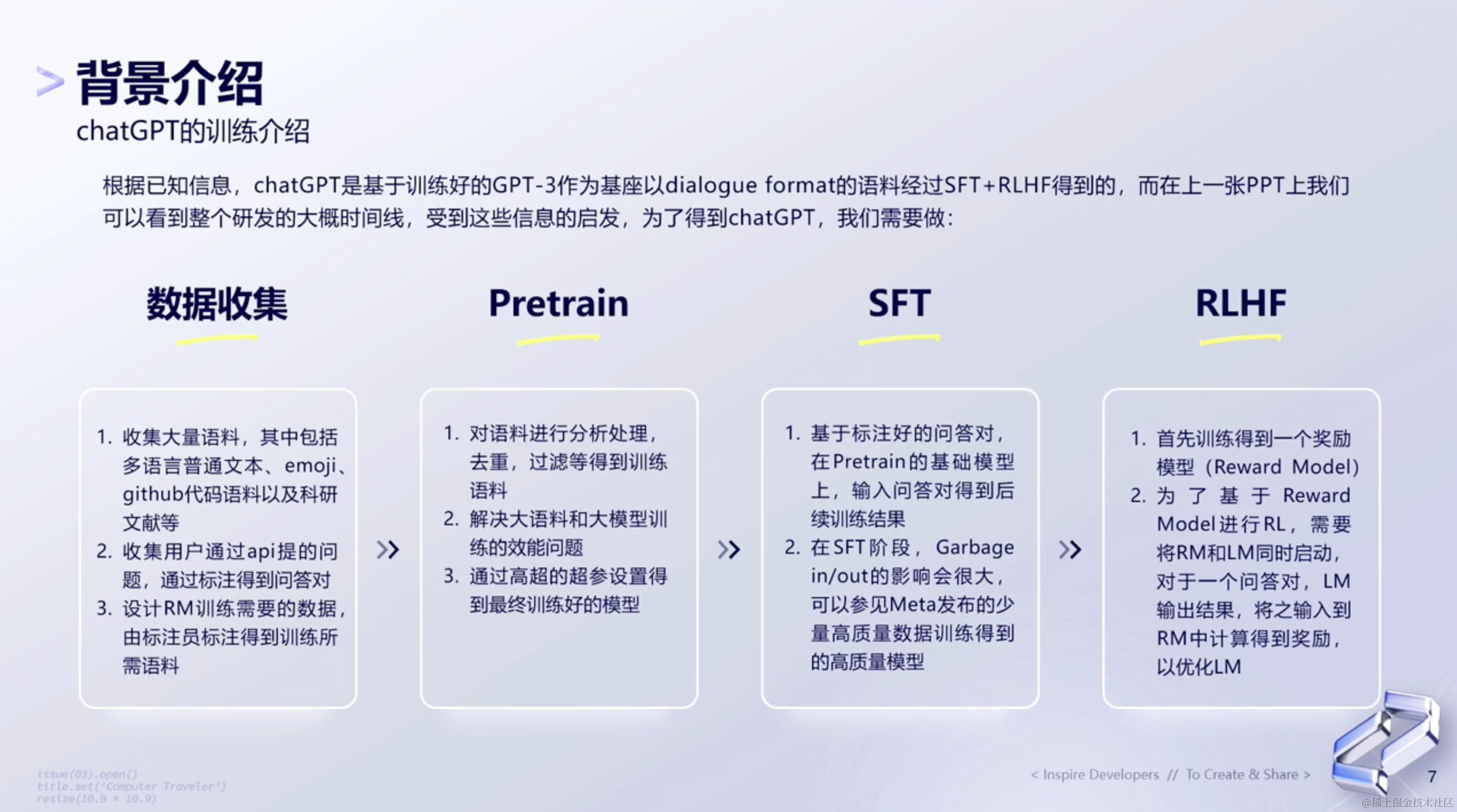
以下是openai提供的关于GPT训练的一个过程图:

二、🎹数据工作:训练数据收集与清洗
2.1 概览
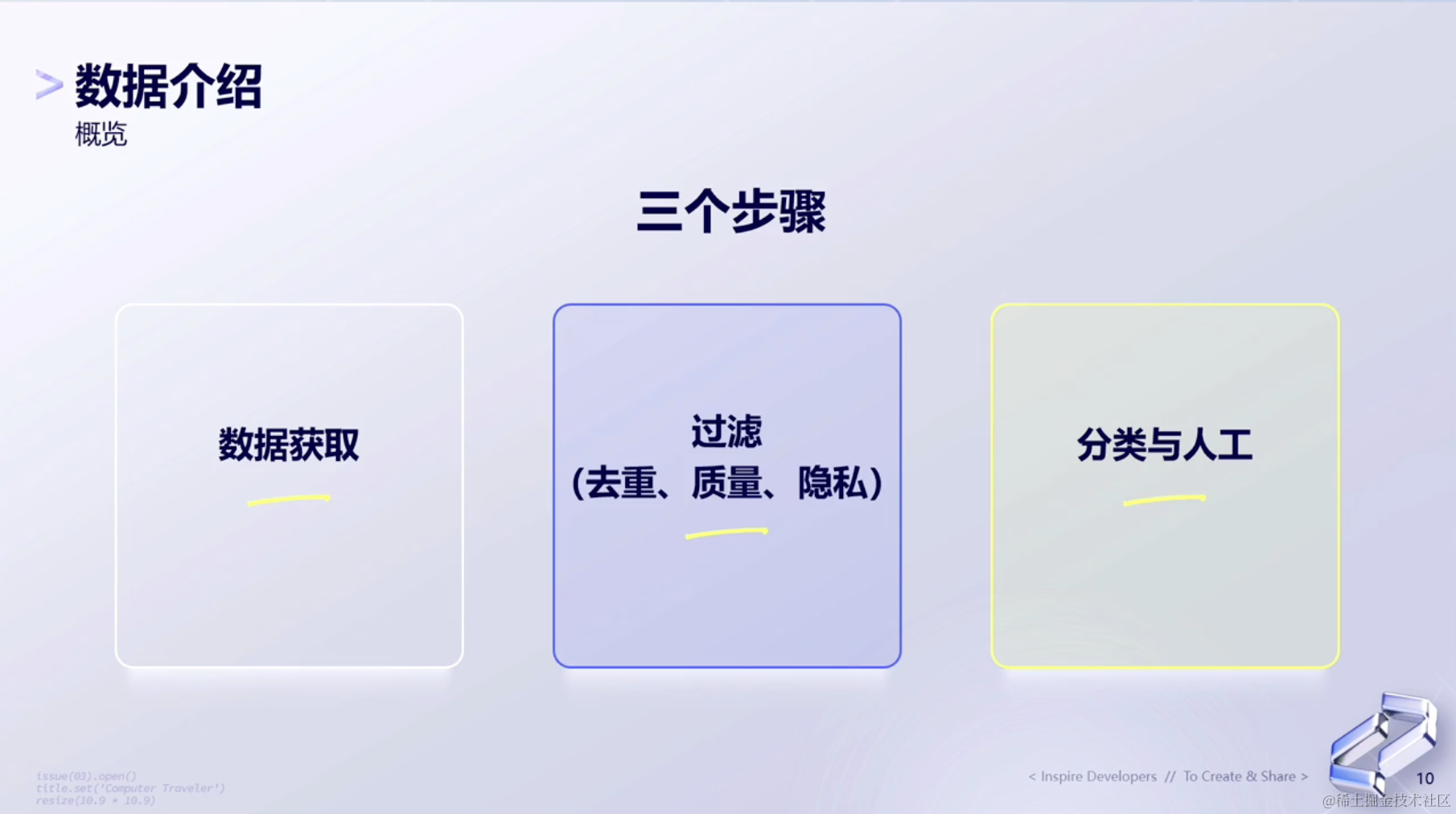
1、 三个步骤
对于数据工作来说,它包含三个步骤:
- 数据获取 —— 如何拿到训练数据。
- 过滤 —— 包括数据的去重、数据质量的提升、以及隐私相关的保护。
- 分类与人工 —— 我们需要对我们已有的Prompt做分类,人工指的是人工标注。
2、几个训练步骤对数据的偏好
那对于上面这三个步骤,它们对于数据的偏好都是不一样的。有什么不同呢,如下所示👇🏻:
Pretrain:
- 目标是拿到一个强大的语言模型。
- 重点步骤在于数据的获取和过滤,也就是前面谈到的数据处理的前两步。
SFT(PF · PromptFinetune):
- 目的是让模型能够理解用户的指令,并让模型知道好的回答是什么样的。
- 里面非常关键的一步是数据的分类,以及人工去构造训练数据
RLHF:
- 目标是释放人力,并让模型对齐人类期待,不去做不好的回答。
- 重点步骤在于数据分类与人工标注。

2.2 数据获取
1、业内公开数据
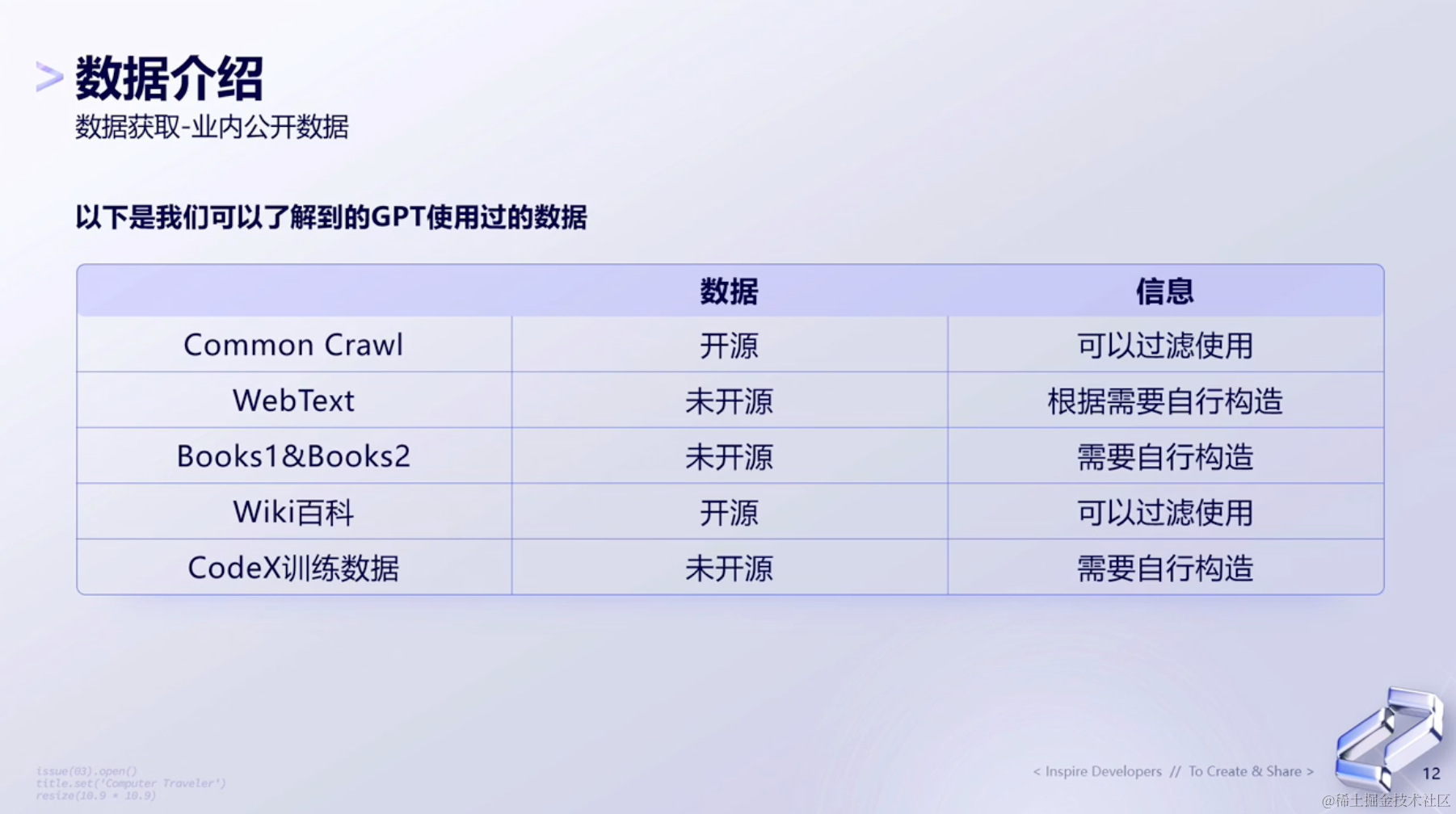
(1)了解GPT使用过的数据
接下来将展示GPT公开过的一些数据,以及介绍当我们要去训练像ChatGPT这样子的一个大模型时,该怎么做。
Common Crawl和Wiki百科是目前已经开源的数据,且直接直接过滤使用。
而对于另外三种,则需要自行构造。
首先是WebText,它是来源于互联网上的数据。但因为数据没有开源,我们就不太清楚,openai是怎么去对待互联网上这份数据的。而对于当前整个互联网环境来说,不管是英文互联网还是中文互联网,里面的数据都是非常杂乱的。但是数据里面的细节怎么处理,我们可能都不是很清晰。而怎么处理,就会影响到模型整体的表现。
最下面的CodeX,也是非常关键的一步。对于我们日常写的代码来说,它的结构化和逻辑性是非常严密的,这个东西对模型的推理能力带来的影响是非常大的。这些东西包括一些科学文献的实现,到目前都还没有做公开。
(2)业内已经开源过的数据
如果我们需要自己去做的话,那刚开始我们要怎么办呢?
除了我们要自己去做大量的实验外,还要尽可能地去用到一些开源的数据,特别是对于中文互联网来说。
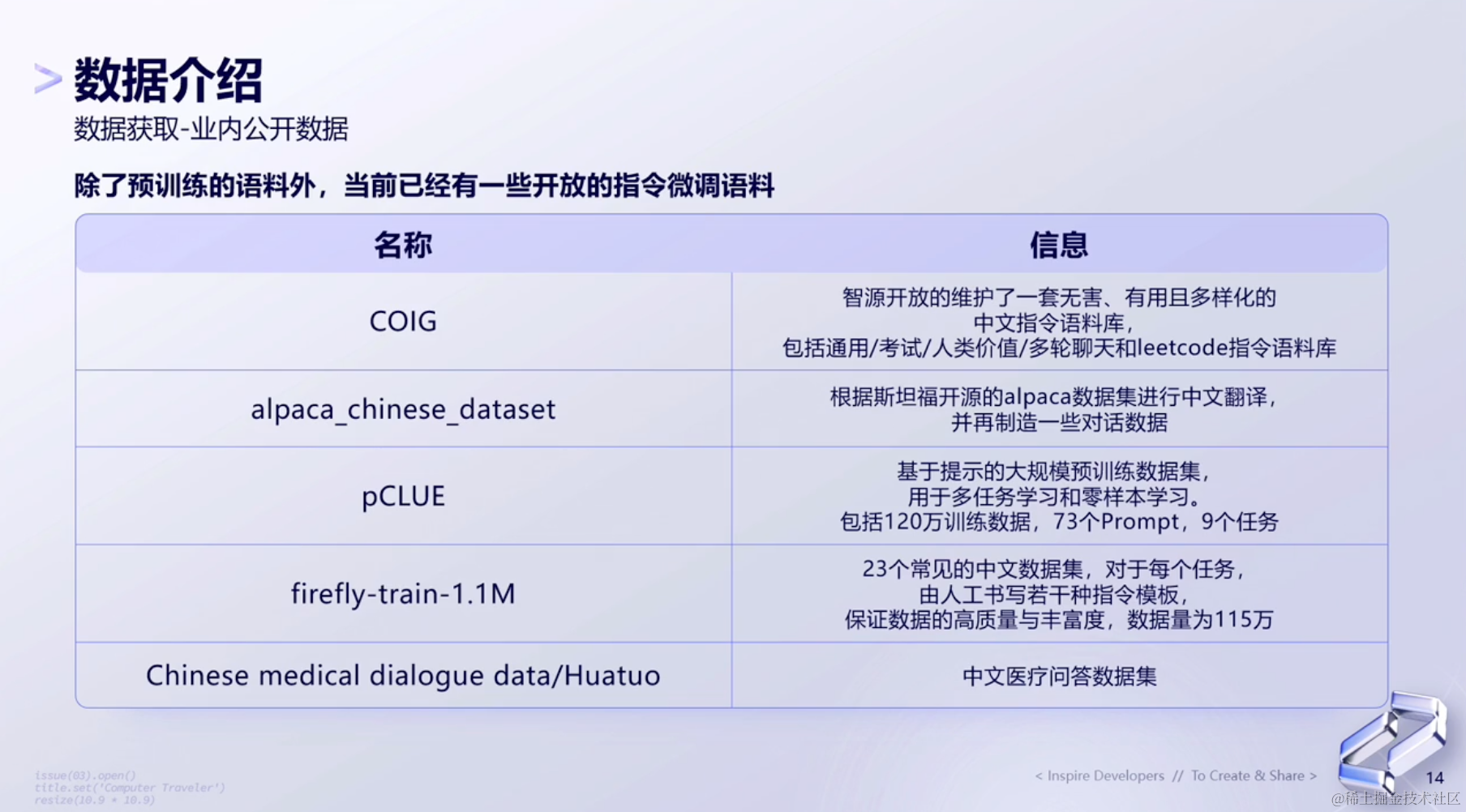
以下展示目前业内已经开源过的数据:

(3)开放的指令微调语料
除了预训练之外,我们还有一些指令微调数据。这些数据从某种意义上来说,是给大家做冷启动的。
因为很关键的一点是,我们需要给大模型输入prompt,然后它给出一个answer。
具体如果要落地到我们业务上使用的话,那用户自己的prompt、通用的prompt和网上的prompt,肯定是有大量差异的。
那上面这些数据就可以帮助我们在构建大模型时,做到很好的很启动。
2、iGPT
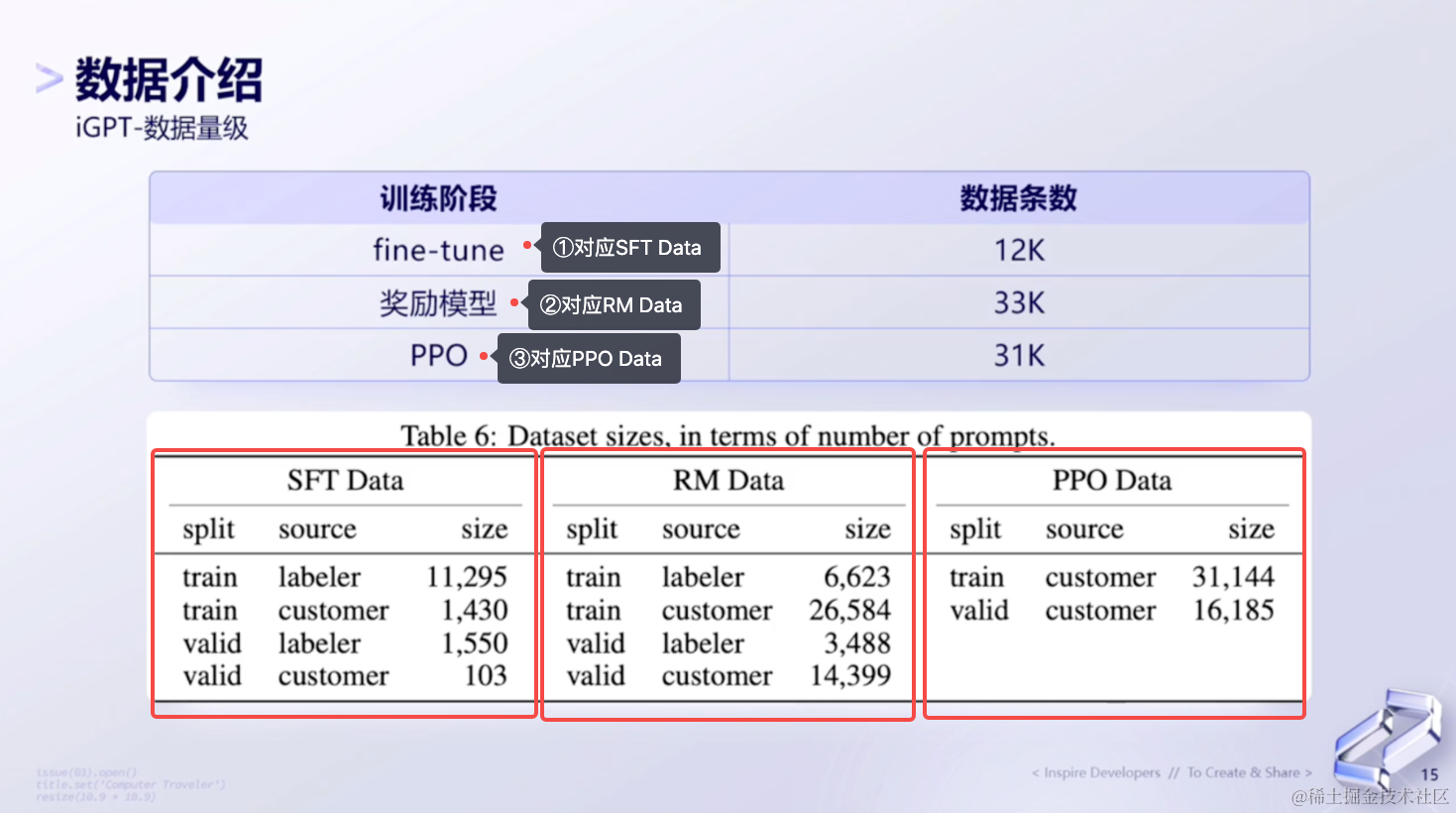
(1)iGPT - 数据量级
接下来,我们看下数据量级。除了要知道有哪些数据之外,还要知道数据量级大概是什么样的。下面举例出三种:
- Fine-Tune —— SFT Data,数据条款大概在12K左右
- 奖励模型 —— RM Data,数据条款大概在33K左右
- PPO —— PPO Data。数据条款大概在31K左右
(2)iGPT - 数据多样性
数据多样性的一个点在于Prompt的多样性,对于prompt来说,一开始Prompt主要以文本生成(generation)的形式呈现,这在一定程度上是由于之前开放的API是用于文本生成的API。ChatGPT后来也开放了API,且主要也以文本生成为主。因此,文本生成API的普及和ChatGPT的API开放进一步推动了Prompt的多样性发展。

2.3 数据过滤
数据过滤有三种类型:
数据去重 —— 主要是担心overfiting过拟合,所以会去做去重。
质量提升 —— 根据用户自己的诉求,做一些标点符号和目标语言的过滤。与此同时,也还会做一些当前互联网世界里,比较有问题的一些短文本做过滤。理论上来说,我们的模型在刚开始的时候,会生成大量无用的短文本信息,而这些信息,我们并不能像tokenier那样子去全部删除掉。在这过程中,我们就需要有过滤性地,去做好这些信息的质量提升。另外我们也可以使用二分类的方式,把数据分为两类,一类是低质量的,一类是高质量的,然后挑选出高质量的来进行训练。
隐私 —— 隐私也是非常关键的一个点,特别是我们要把很多产品给业务化和商业化,这一点更为重要。比如说,在刚开始我们要去训练模型的时候,打个比方会去爬取github上面的各种代码库。但里面有一些是公开的,一些是未公开的,这个时候就需要我们去做筛选,以及数据清洗。哪些数据是可以用来训练的,哪些数据是不能用来做训练的。

2.4 分类与人工
数据工作的最后一部分,来到了分类与人工。
1、几个步骤
分类与人工包含以下四个步骤。
第一种,分类:
- 目标是对Prompt进行任务分类。
- 我们需要让模型知道我们需要去处理哪些类型的任务,换个话题来说,就是我们想让我们的模型去处理哪些任务,以及模型对哪些任务的处理是不够好的。那这些地方我们就需要做分类。
第二种,人工编辑:
- 本质上是人工在构造批量的数据。
- 一方面,我们需要基于第一个步骤中提到的不同类别的
Prompt,来去丰富Prompt。 - 另一方面,
Prompt都有其对应生成的结果,这里面很关键的一个点是,当Prompt有一些变化的时候,我们的标签也需要察觉到。也就是说我们的prompt有step by step这样的顺序,那么我们所生成的答案,也要有一定的顺序。
第三种,人工标注:
- 人工编辑的话,更倾向于用户可能会直接去编辑
Prompt或者答案。 - 那对于标注的话,更多的是倾向于01。比如用户输入
Prompt,然后会生成好的答案或者不好的答案。然后我们需要去对这些答案做些排序,选出最好的答案,也就是Reward Model。
第四种,人工评估:
- 在前面,我们谈到了
Pretrain、SFT、Reward和RLHF这几种训练方式。这几种训练方式每个阶段都有对应的模型训练,那我们要做的是,每个阶段都对这个模型进行一次评估,才知道这个模型做的好不好。 - 所以我们是需要去构造这样的一个评估数据集的,比如说,在SFT阶段的话,我们需要一个严格意义上的
Prompt,需要覆盖到所有相关的类别,然后这个数量要足够的多。 - 然后呢,每次模型生成的时候,我们都需要人工去判断,去判断哪个类别的
prompt效果不好,它为什么会不好的原因,这些都需要人工去评估。

2、数据标注
(1)标注的方式
标注数据是指对数据进行标记、分类的过程,它是机器学习和人工智能应用中的一项关键任务。根据不同的获取方式,标注数据可以采取以下几种方式。
第一种,人工标注:
- 人工标注是最常用和可靠的方法。它涉及专业人员或专家对数据进行逐一审核和标记。
- 人工标注的优点是可以保证数据质量,缺点是费时费力,成本较高。为了保证标注效率和准确性,可以通过一些标注工具来辅助人们进行标注。
第二种,基于接口获取:
- 一些数据源提供商会提供
API接口,可以方便地获取到数据并自动进行标注。这种方式可以大大提高标注效率,同时避免了一些人为因素带来的误差。 - 但是,这种方式的缺点是需要依赖数据源提供商,如果他们无法提供足够的接口,或者接口质量不高,就会影响到数据的质量和数量。
第三种,利用别的服务获取:
- 除了上述两种方式外,还可以利用一些服务来获取和标注数据。
- 例如,利用自然语言处理技术,可以从网页中提取文本信息;利用语音识别技术,可以将语音转化为文本信息;利用图像识别技术,可以自动识别图像中的物体和文字等。
- 这些技术可以帮助我们从不同的渠道获取数据,并进行自动化的标注。
- 但是,这种方式的缺点是数据的质量和数量都受到技术算法的影响,同时还需要考虑版权和隐私等问题。

(2)人工标注Prompt
人工标注的Prompt主要根据被标注数据的性质、标注者的能力以及特定的标注情境来设计。以下是对这三种类型提示语的简要分析。
第一种,直白清晰提示语:
- 直白清晰提示语通常是被明确地用来帮助标注者理解数据的简单、直观的描述。
- 这些提示语会直接指明需要标注的内容或特征,以便标注者可以准确地理解和标记数据。
- 例如,对于图像数据集,直白清晰的提示语可能会包括:“标注这张图片中的人物、物品、场景等信息。”
- 对于文本数据集,提示语则可能包括:“根据这个段落的语义,将其标记为‘积极’或‘消极’。” 这种类型的提示语对于保证标注数据的一致性和准确性非常有帮助。
第二种,用于少样本学习的提示语:
- 用于少样本学习的提示语旨在为标注者提供一种通过少量样本来理解和标记数据的方法。
- 这些提示语通常会引入一些特定的标注策略或启发式规则,以便标注者在只有少量标记样本的情况下也能有效地进行标注。
- 例如,如果一个数据集包含了不同情绪的文本,但只有很少的样本,那么提示语可能会是:“首先,请仔细阅读这段文本并尝试理解其情绪。
- 然后,根据您对这段文本的理解,将其标记为‘积极’、‘消极’或其他情绪。”
第三种,用户导向的提示语:
- 用户导向的提示语主要是从用户的角度出发,考虑他们的需求、背景知识和经验水平来设计的。
- 这些提示语通常会更加详细和复杂,以帮助标注者更好地理解数据和标注任务的背景信息。
- 例如,对于一个医学图像数据集,用户导向的提示语可能会是:“请根据这张脑部
MRI图像,标注出肿瘤的位置和大小。 - 同时,请注意图像中的噪声和其他可能影响肿瘤检测的因素。” 这些提示语通常需要更多的专业知识,但可以帮助提高标注数据的质量和准确性。

(3)标注员如何标注信息
标注员在标注Prompt信息时,可能会考虑以下三种标注方式。
第一种,Prompt标注:
- Prompt标注是一种通过向标注者提供一些提示或指导来帮助他们更好地理解和标注数据的方法。
- 这些提示可以包括一些示例、关键词或特定的标注规则,以便标注者可以更准确地执行标注任务。
- 例如,在标注图像数据集时,可以向标注者提供一些标注框和标注标签的示例,以及标注不同物体的关键点和特征的指导。
- 这种方法的优点是可以帮助标注者更好地理解标注任务和数据,从而减少标注错误和不一致性。
第二种,从API获取prompt:
- 从
API获取prompt是一种通过调用数据标注API接口来自动生成标注任务提示的方法。 - 这些
API接口通常是由数据标注平台或服务商提供的,可以根据数据集的特点和标注任务的要求自动生成相应的标注提示。 - 例如,在标注语音数据时,可以从API获取标注语音的文本转录和关键点提示,以便标注者可以更快速和准确地执行标注任务。
- 这种方法的优点是可以提高标注效率和准确性,但需要依赖数据标注API接口的可用性和质量。
第三种,有害提示语标注方式:
- 有害提示语标注方式是一种通过识别和消除有害标注提示语来提高数据质量的方法。这些有害提示语通常包括错误、模糊或误导性的信息,可能会影响标注者的判断和标注结果。
- 例如,在一些图像标注任务中,可能会存在一些模糊不清或与实际图像内容无关的标注标签,这些标签可能会误导标注者做出错误的标注决策。
- 有害提示语标注方式的目标就是识别并消除这些有害标签,以提高数据的质量和准确性。这种方法的优点是可以提高数据质量,但需要专门的算法和技术来识别和处理有害标签。
(4)标注界面
这里openai的论文里面给出的一个标注界面,里面罗列了在标注过程中的一些详细步骤。
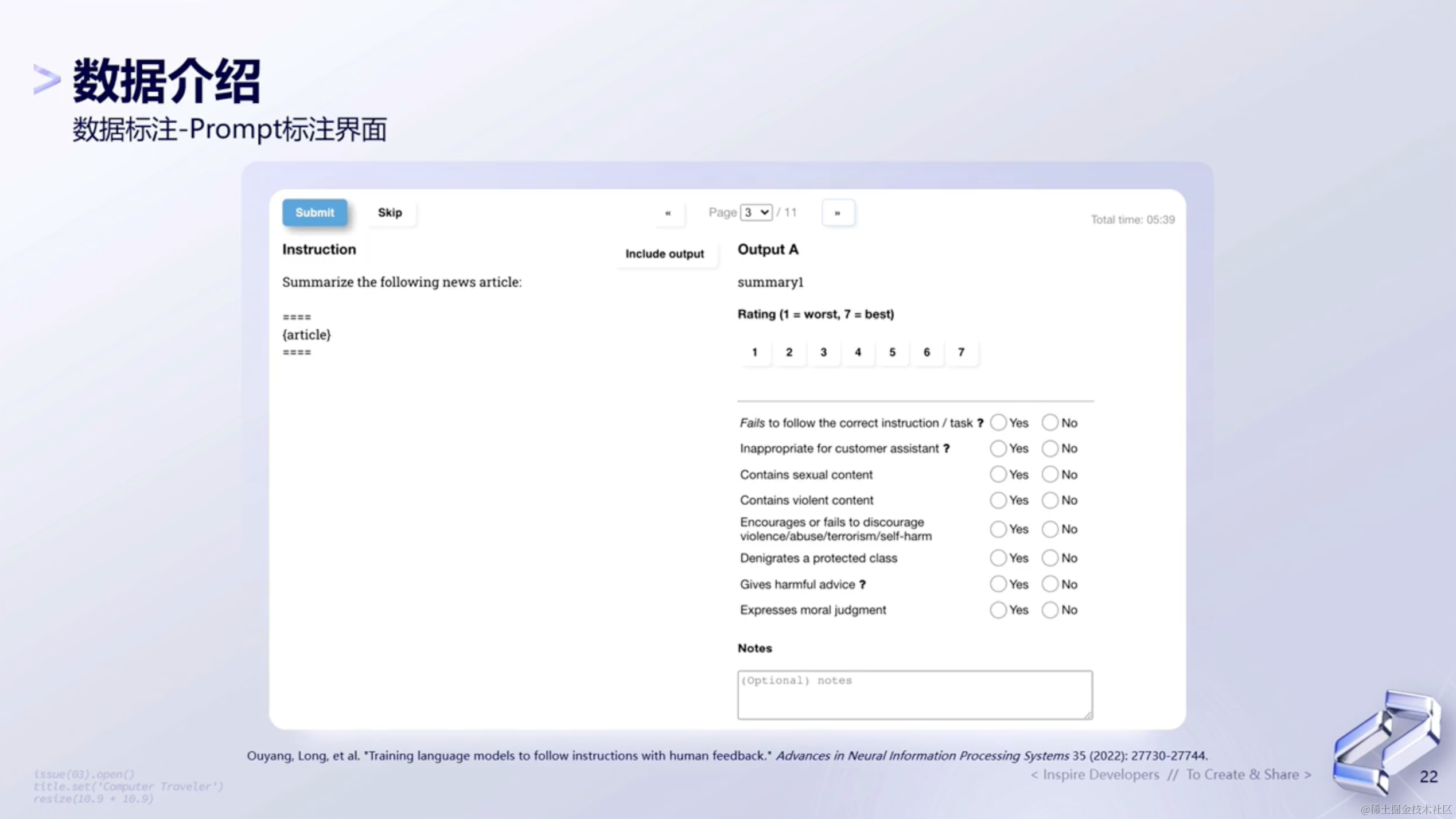
下面给出的是openai对reward model的一个标注方式。

三、🛰RLHF介绍
3.1 基础介绍
SFT后的能力,如果我们做的好的话,就已经是一个非常强的语言模型了。但是呢它有两个缺点,第一个缺点是它的效果可能没有那么好,第二个是泛化能力还没有那么好。所以RLHF本质上就是在解决这样的问题。
另外我们会发现,SFT有极端的依赖,因为它是监督训练,所以会极端地依赖到我们原始训练的数据和资源。
但是RLHF就不是这样的了,它中间有一个Reward Model,需要人工不断地去构造这一整个模型,所以模型就可以跑起来。

3.2 RLHF基础
1、RLHF的作用
RLHF具有四个作用:
- 满足难以定义的目标,赋予模型足够好的泛化性
- 降低胡编乱造的可能性
- 保证模型持续更新的正确轨道
- 多样化与负反馈

2、希望的case
因此,我们希望经过RLHF之后,把一些不符合价值观的内容给筛选掉。比如下面这个case,它给出了5个答案。即使说有可能五个答案都是对的,但是我们希望它能回答的更有礼貌性一点,就会让用户去挑选出最好的那一个。

3、实验效果
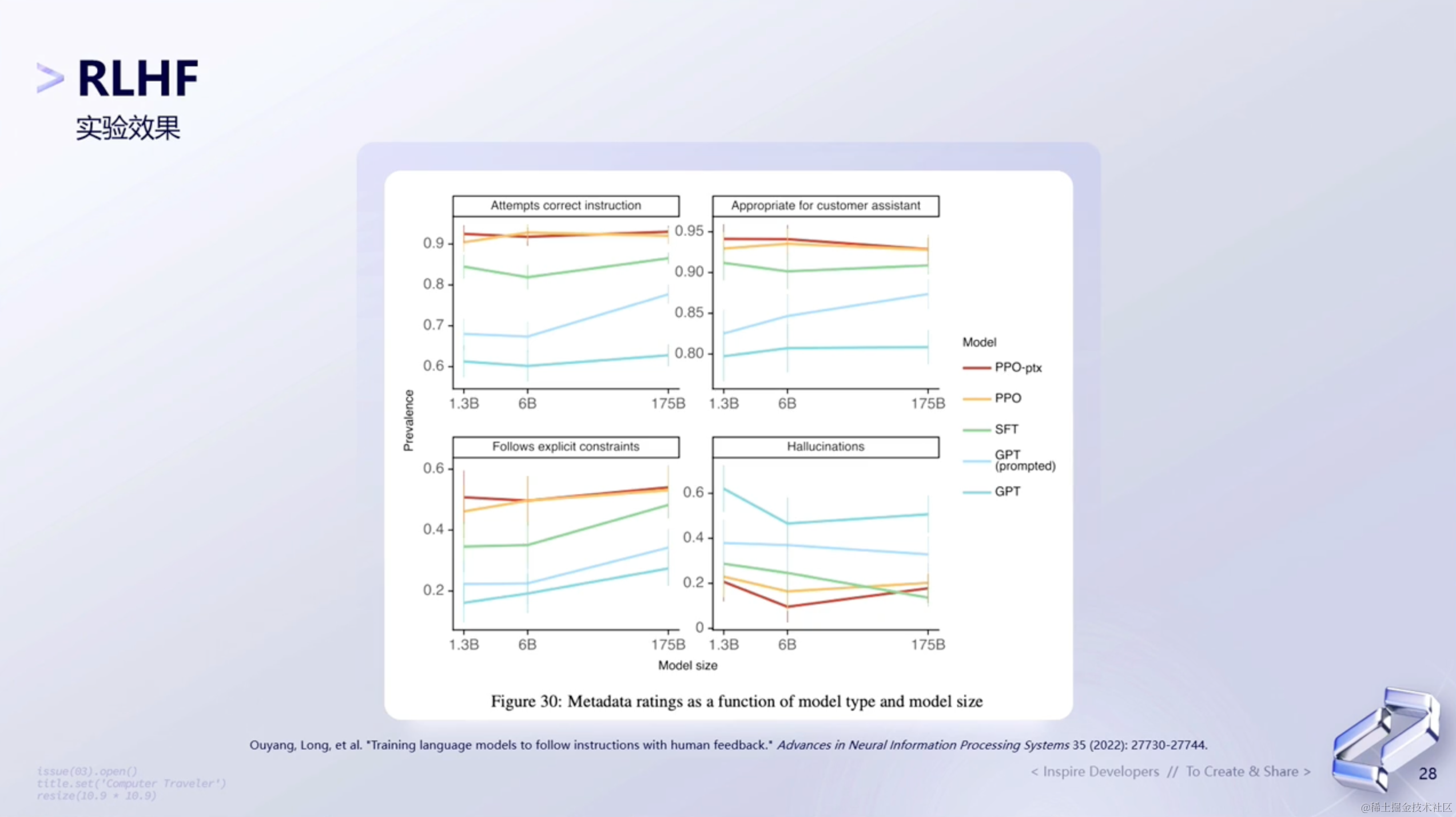
3.3 RLHF训练
1、训练流程
下面这张图是网上的一个关于训练流程的图片。主要传达两个点:
- 第一个点是
Step1,里面的SFT是收集了用户数据的。 - 第二个点是
Step2,这里面收集了Comparison Data,这部分的数据是需要去进行标注的。
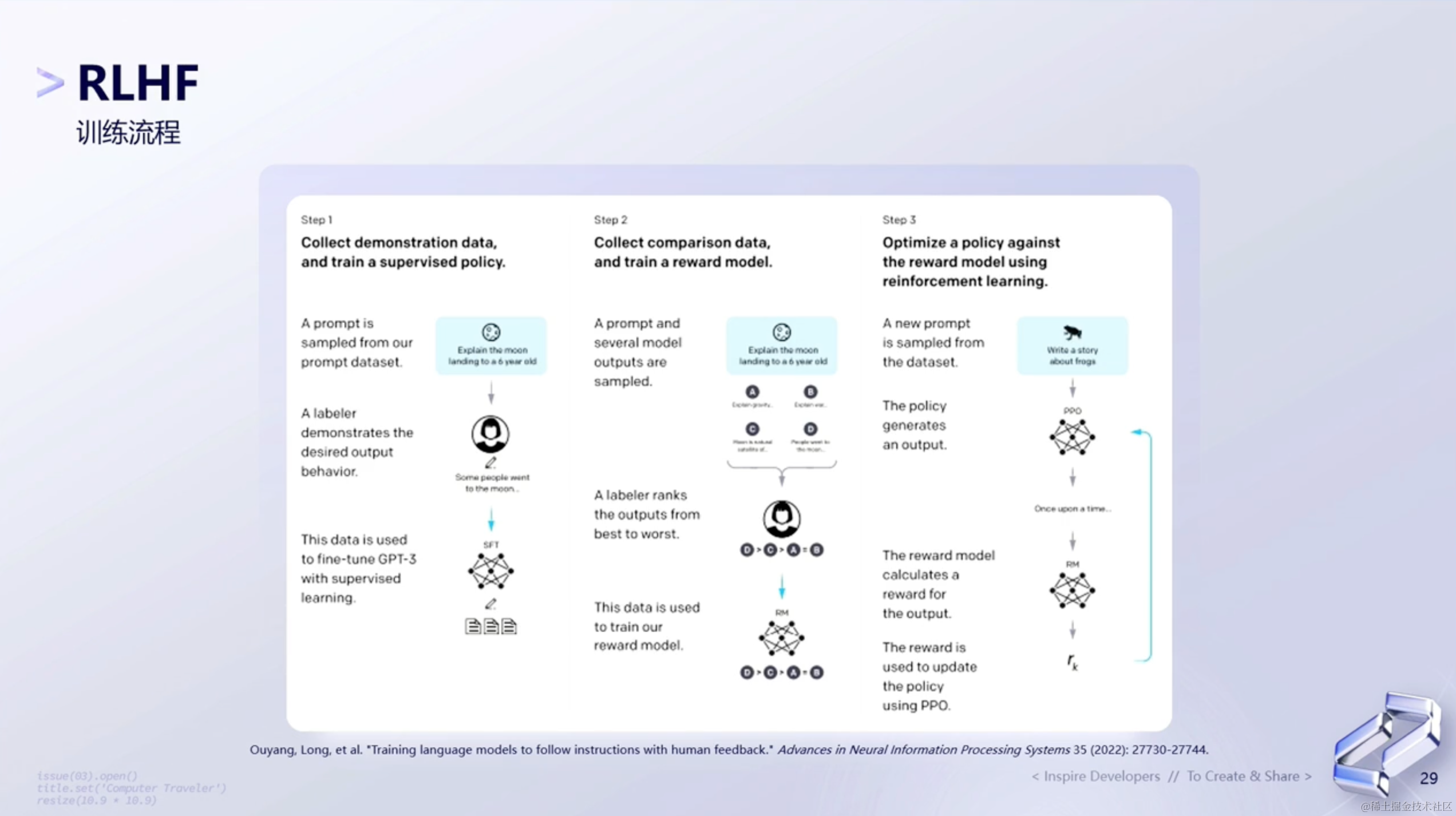
那具体的整个训练流程如下图所示:
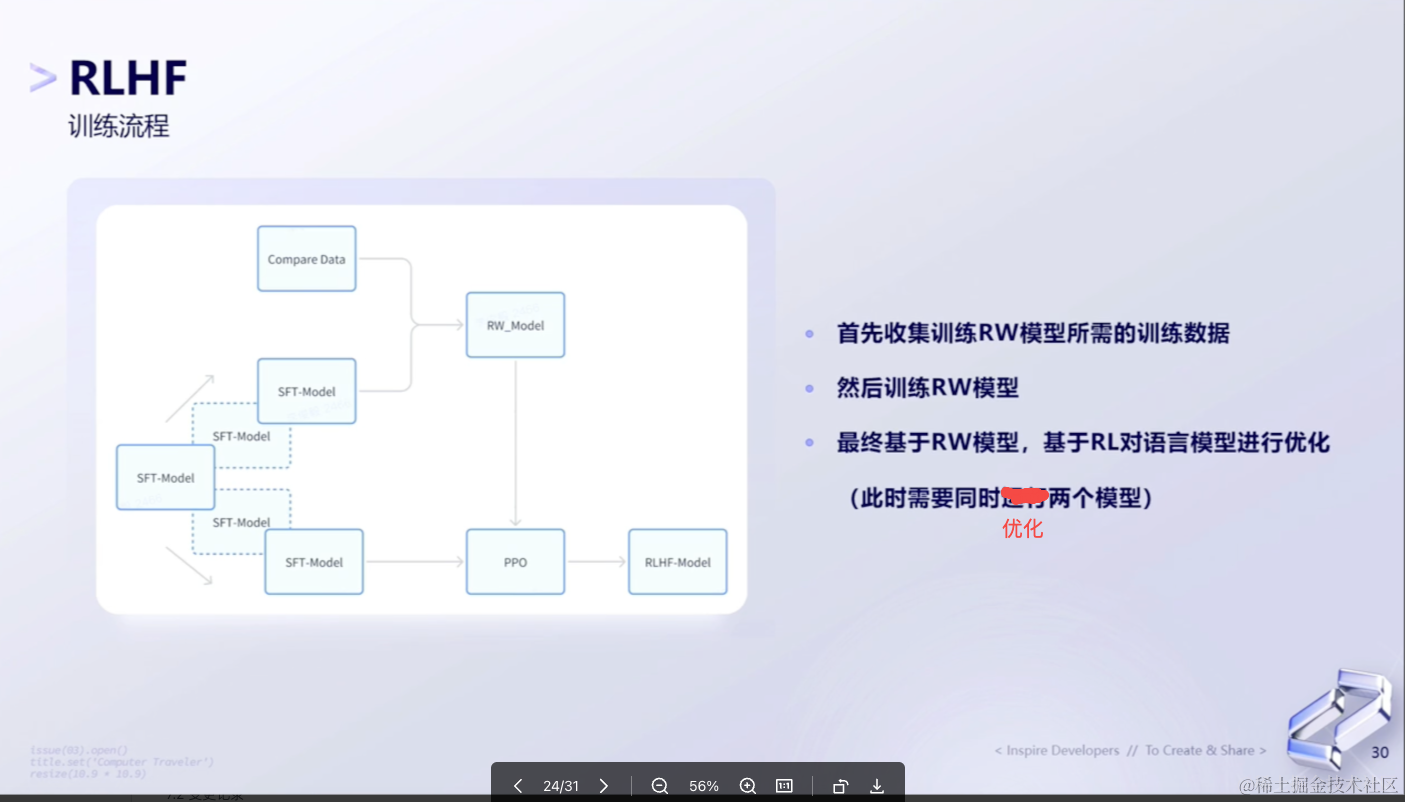
2、RM训练
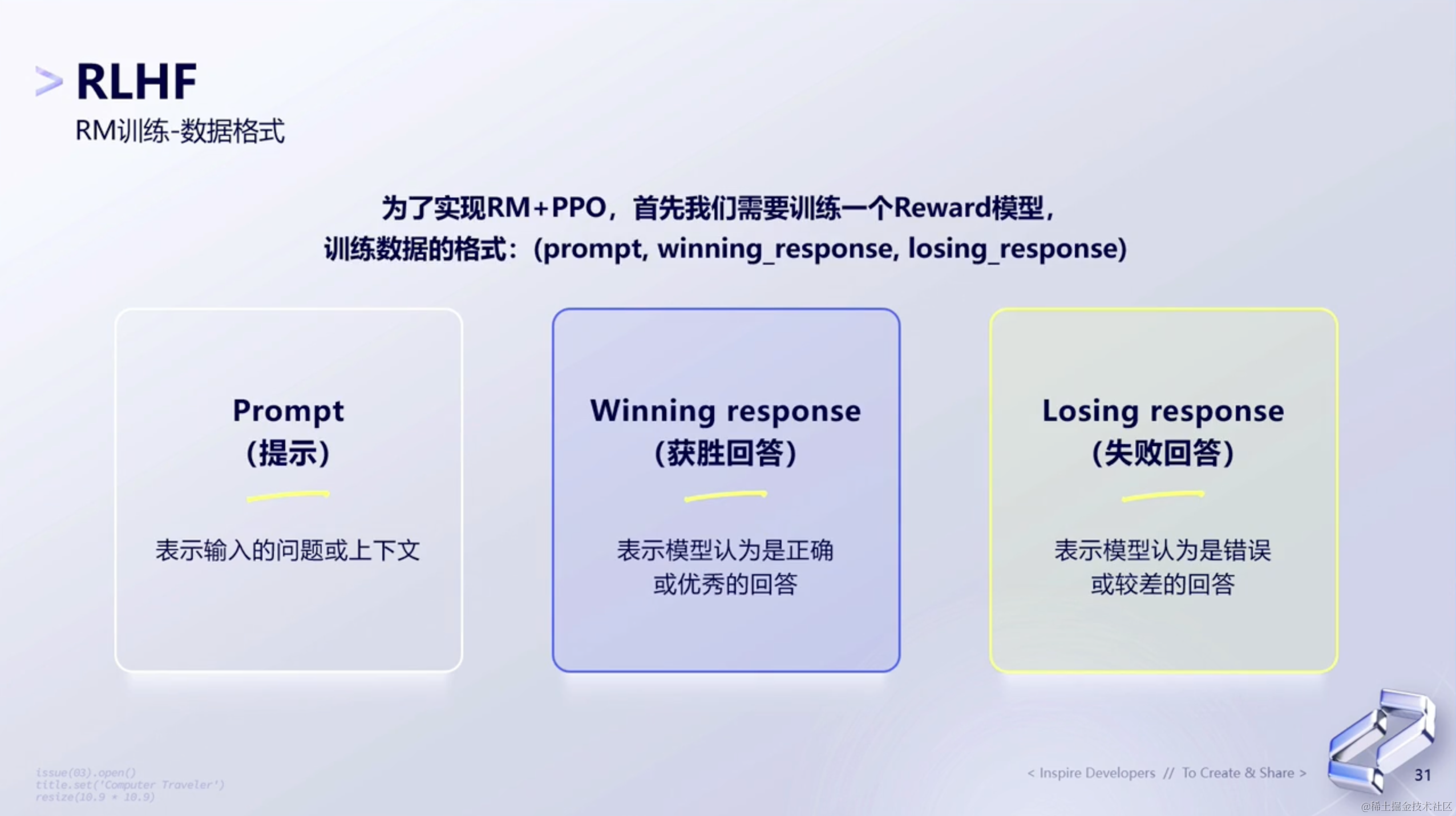
(1)数据格式
Reward Model整个训练过程相对会比较简单,它就是给模型一个Prompt,然后在一个Winning 和一个 Losing里面找出最终的Response。
但实际上,我们期望的是在一个Prompt下面能够得到4~9个response,但目前在网上的公开数据来看,这部分暂时还没有得到这样的效果,所以这其实对于目前我们在训练过程中,也是一个挑战。
(2)RM目标
那对于整个训练的话,就希望最终Reward Model能够给出一个值,来判断回答问题质量的高低。如下图所示:

3、PPO
PPO是基于传统的强化学习做了一些改进的一种算法,在RLHF过程中引入这个算法,目的是为了获得更高质量的回答。具体细节如下:

4、数学建模
整个数学建模的详细训练步骤如下图所示:

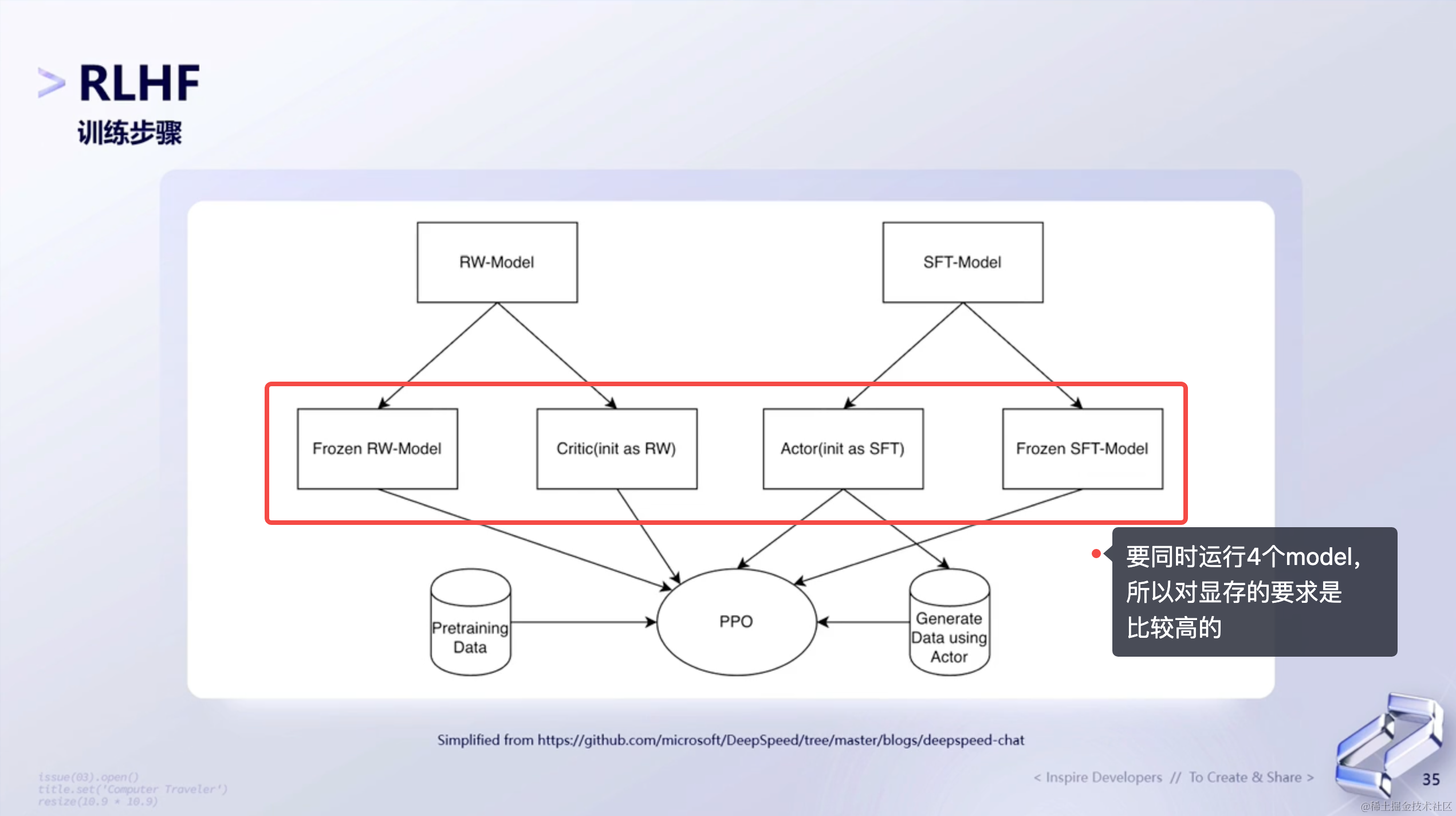
5、训练步骤
实际上,目前RLHF在训练过程中效果并不一定是最好的,这个情况在OpenAI的WebGPT中也同样有所讨论。那下面我们简单介绍下RLHF的整个训练步骤:
四、🎤流行的开源RLHF的实现
下面我们来简单说下一些流行的开源RLHF的实现。
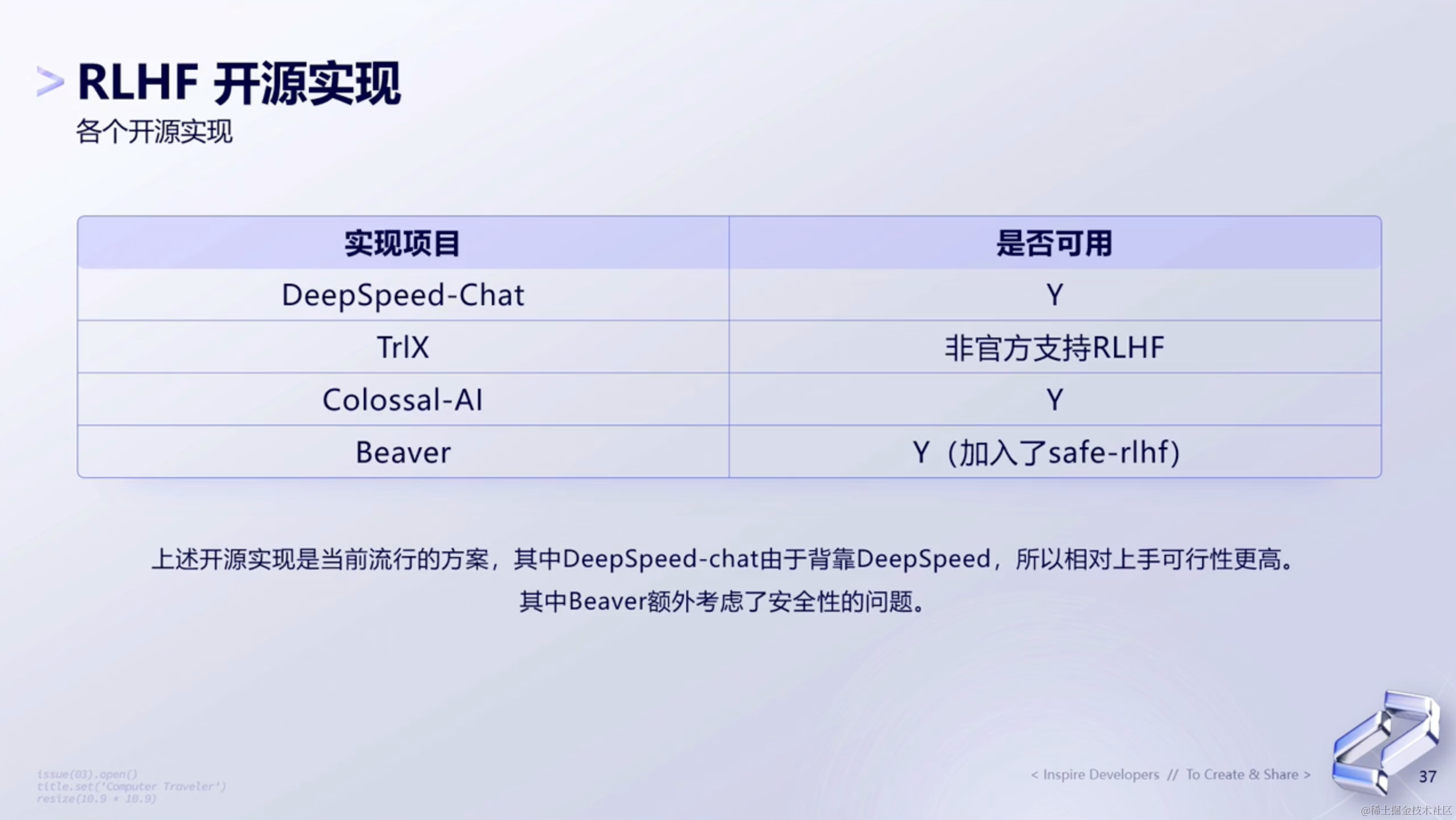
4.1 各个开源实现
- DeepSpeed-Chat ——
DeepSpeed-Chat背后靠的是DeepSpeed,因此它的工程是比较完善的,这个也是会比较推荐的。 - TrlX —— 然后是
TrlX,它是个开源库,然后它更多谈到的是实现整个RLHF的一个整体的pipeline。这里谈到了一个非官方支持,所以相比于DeepSped来说,里面还会有很多东西还需要我们再进一步去封装和处理。 - Colossal-AI —— 跟上面两个的实现会稍微有一点点不一样,但是整个大的流程是一样的。它本质上就是在我们更新的时候,考虑是一个
seq level为粒度,还是一个token level为粒度。这个更多的会涉及到多轮对话,在多轮对话的时候,模型在生成答案时,需要考虑要以之前的答案来考虑,还是以一个token一个token的形式来考虑。这两种形式在多轮对话里面,面临的难度就可能会不同。 - Beaver —— 最后一个是北大开源的一个库,里面多做了一个安全性的考量。
4.2 设计开发重点
Reward Model的关键点:
- 训练数据丰富,数据是
query到answer之间的映射,同一个query下接了一个高分答案和一个低分答案;同时最好是一个query对应4-9个答案。 - 在
Reward Model之前会先训练一个PreTrain或者SFT的模型,这里建议使用SFT的模型。
RLHF的关键点:
- 算法实现:目前细节披露不太清晰;
- 工程挑战:多模型的内存消耗和训练的高效进行(同时有
Actor、Critic、SFT、RM四个模型存在,两个需要更新,对显存的要求会更高)

五、🥍讨论
讨论1: RLHF是否是最优解?
Answer1: 并没有完全解决了实际上的问题,不管是工程上的,还是实际带来的效果上的。
讨论2: 模型是否真的不能有自己的偏见?
Answer2: 人在学习的时候是有偏见的,那模型在学习的时候也是会存在偏见的。
讨论3: 基于RLHF,ChatGPT类模型如何作用?
Answer3: 人类给到的反馈会给到SFT和Reward里面,然后模型会基于整个人类的反馈,去做优化。另外,假如我是一个产品开发者,那么我可以将我期望的Reward Model,给去引入到产品最终期待的模型中。这样的话,整个模型的训练、迭代和优化,就会走的更加自然,且持续处于进步状态。
六、🚀结束语
到这里,文章的讲解就接近尾声啦!相信通过上文的学习,小伙伴们已经更加了解如何更好地利用RLHF来提高大语言模型的性能,从而实现更自然、准确的文本生成。
以上就是本文的全部内容,我们下期见~🍻
七、⛽️彩蛋One More Things
参考材料:
-
稀土开发者大会2023·大模型与AIGC-掘金
-
🎬 PPT下载&回放链接|2023稀土开发者大会大模型与 AIGC 分论坛
-
欢迎交流:Zelina的个人说明书