概述
论文地址:https://arxiv.org/pdf/2404.00152.pdf
大规模语言模型在零拍摄和四拍摄任务中表现出色,但在生物医学文本的独特表达识别(NER)方面仍有改进空间。例如,Gutiérrez 等人(2022 年)的一项研究表明,即使使用相同数量的数据,采用上下文学习(In-Context Learning)的 GPT-3 的性能也不如小型微调模型。生物医学文本充满了专业术语,需要专业知识才能解读。然而,标注任务成本高、耗时长、难度大,而且标注数据的可用性有限。
在此背景下,本文旨在利用一种新颖的生物医学专用知识扩展方法来提高大规模语言模型的性能。该方法的重点是动态纳入相关生物医学概念的定义,使模型能够在推理过程中纠正实体提取错误。我们还试用了两种方法,即单转和迭代提示,结果发现扩展定义有助于提高各种模型的性能。例如,GPT-4 的性能平均提高了 15%。
它还利用大规模语言模型评估了经人工整理的信息源和自动生成的定义的有效性,并发现经人工整理的信息能带来更高的性能提升。这些结果引发了新的争论,即在数据有限的各种任务和领域中,定义知识如何有助于提高大规模语言模型的性能。
下图概述了使用零样本的方法。根据提取实体的定义(黄色),可以看出错误提取(红色)和正确提取(绿色)。

实验概述
实验中使用了多个模型,包括可通过 API 访问的封闭模型(如 OpenAI 的 GPT-3.5 和 GPT-4、Anthropic 的 Claude 2)和开源的 Llama 2。谷歌的 PaLM 则被排除在外,因为它在早期测试中表现不够出色。请注意,评估是基于实体级别的 F1 分数。
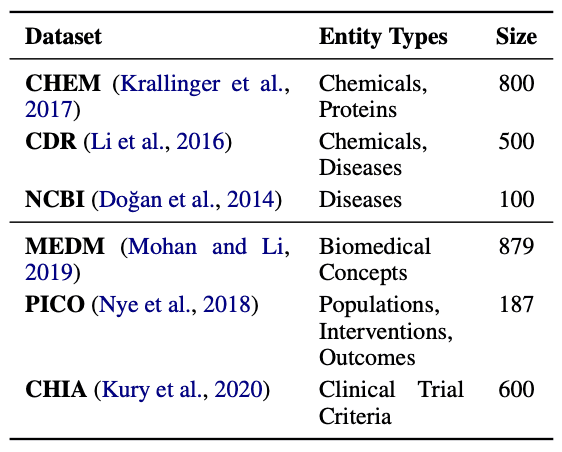
实验中使用的数据集也选自 BigBIO 基准,来自广泛的生物医学学科。该基准包含 100 多个数据集,涵盖 12 种任务类型和 10 多种语言;NER 是 BigBIO 的主要任务类别,包含 76 个数据集。首先排除临床数据和非英语数据集,为每种实体类型选择具有代表性的数据集。这样就将选择范围缩小到包含特别有趣的信息提取现象或具有挑战性案例的 16 个数据集。这些选定的数据集包含在最常见的生物医学基准中,是提供新见解的理想基础。通过这些努力,我们深入了解了大规模语言模型如何满足生物医学领域的特定需求。
实验结果
首先,研究了大型语言模型在零拍和四拍 NER 任务中的性能。此外,还报告了一个较小的微调模型(Flan-T5 XL)的性能。
零镜头评估侧重于两个要素:输入格式和输出格式。输入格式定义了如何向模型提供任务描述和预期类别。输出格式控制模型如何构建结果。
输入格式也有两种方法:文本(Text)和模式定义(Schema Def)。文本(Text)使用标准提示,包含任务简要说明和有效目标实体类型列表。模式定义使用的提示包含对所有目标实体类型的额外详细描述,以先前的研究为基础。
输出格式还包括两种结构化格式,即JSON 和代码片段;JSON 有助于数据的结构化,便于后期处理和评估。代码片段使用具体的编程示例来表示结果。事实证明,这种格式可以提高模型的零点信息提取(IE)性能。通过这些设置,我们对除 GPT-4 之外的所有模型的性能进行了评估。
此外,"四拍 "评估采用在 "零拍 "中表现最佳的输入/输出格式,并在特定数据集(如 CDR)上进行验证。最后,对专门针对每个数据集进行微调的小规模模型的性能进行评估。
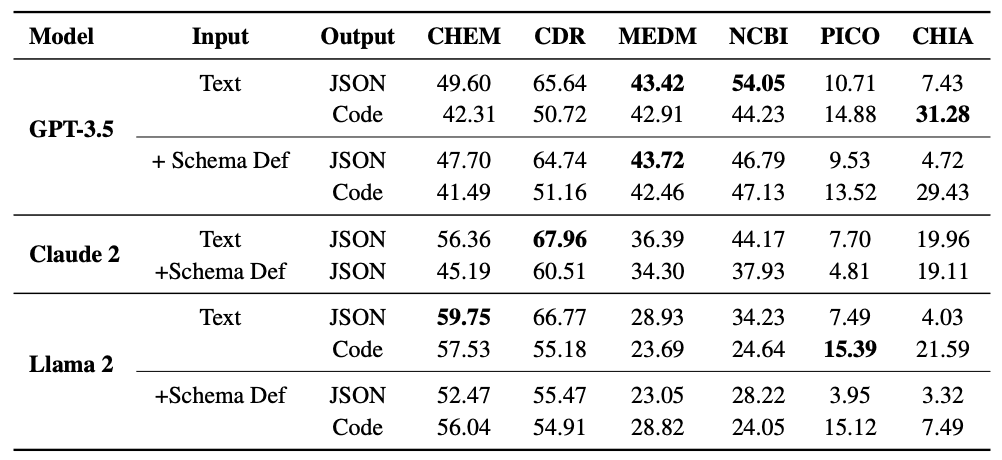
下表显示了 GPT-3.5、Claude 2 和 Llama 2 所有数据集的结果。下表列出了按文本输入和 JSON 输出、文本输入和代码输出、定义输入和 JSON 输出以及定义输入和代码输出分列的零点得分。
我们发现,对于所有模型和数据集,添加模式定义的提示都会降低性能。在输出格式方面,除 PICO 和 CHIA 外,JSON 是大多数数据集的首选输出格式。这一观察结果在所有模型中都是一致的。
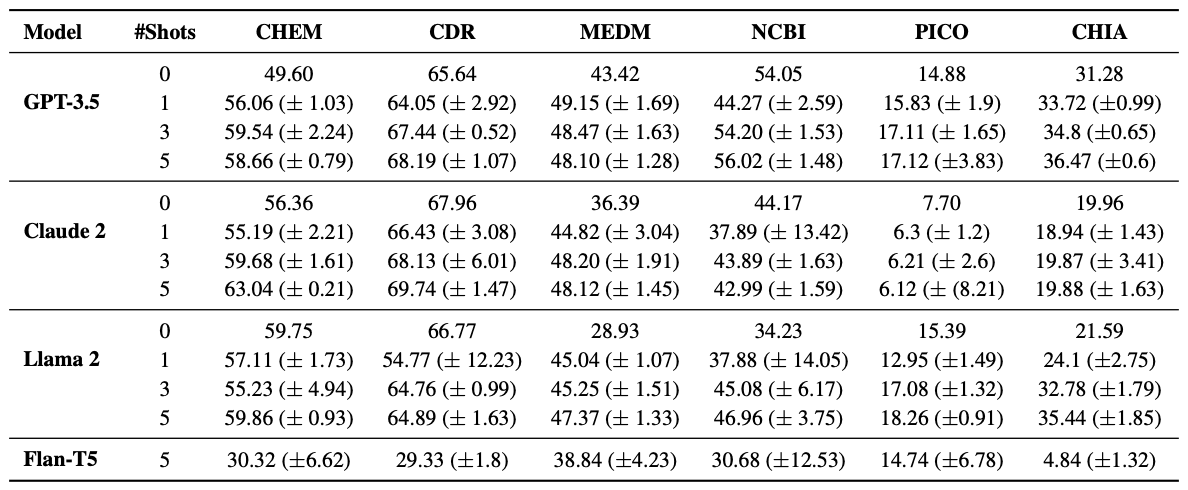
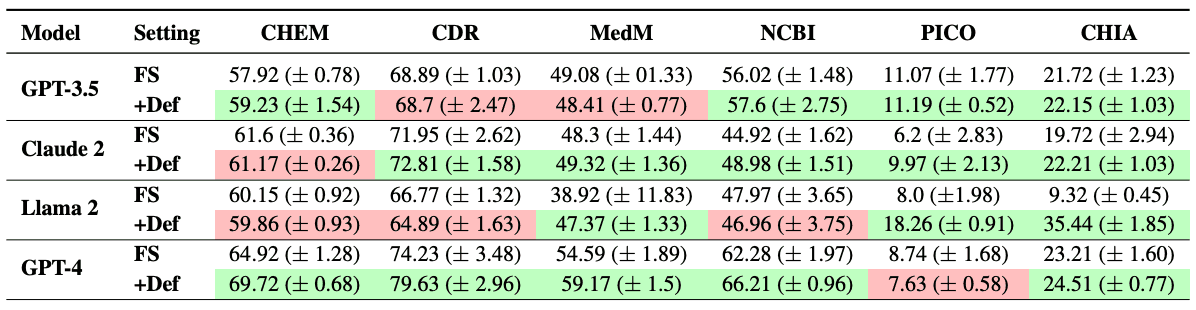
不出所料,随着拍摄次数的增加,füshot 的性能也趋于改善(见下表)。最后,我们发现在相同的五个实例中,使用经过调整的大规模语言模型进行的 füshot 训练明显优于经过微调的小规模语言模型。
然后再进行用定义扩展提示的实验。语境中学习(In-Context Learning)利用大规模语言模型通过先前学习获得的知识。然而,这些知识有时会包含错误或缺失。为了解决这个问题,人们尝试了用相关事实知识立即扩展提示语的方法,以提高语言理解任务的准确性。
特别是,在 NER 任务的提示中动态添加文本中生物医学概念的定义有望提高模型的性能。在生物医学领域,重要的是在测试时提供特定信息,以弥补大型语言模型普遍不足的地方。
实验的第一步是创建知识库。我们建立了一个生物医学概念定义知识库,并使用商业实体链接器对文本中的概念进行了映射。接下来是提示推理。在初始实体提取之后,包含概念定义的提示会要求对模型进行修改。在这一阶段,实体被添加、删除或重新分配到类型中。
使用了统一医学语言系统(UMLS)中的概念定义,但并非所有概念都有用。属于宽泛类别的概念被排除在外,重点放在更精细的类别上。
Zero-shot 还尝试用单个定义的提示来修改实体。Few-shot 的目标是通过包含多个示例和概念定义的提示进行更高级的修改,但采用的是单轮方法,而不是一次性处理大量信息,以避免增加成本。
这种方法以模型修改自身输出结果的能力为基础,旨在通过自我验证提取更准确的信息。它探索了通过提供上下文知识来支持自我验证过程的潜力,从而提高临床信息提取的准确性。
为了保持一致性,所有实验都以 JSON 格式输出,并在所有数据集的统一设置下进行。特别值得注意的是 “少数镜头”,每个测试实例都使用了随机选择的五个镜头;每个实验都使用了三个不同的随机种子,并报告了它们的平均性能。
该实验还包括对 GPT-4 的评估;鉴于 API 成本较高,测试集的子样本为 100 个实例。
下面两个表格显示了 GPT-3.5、Claude 2、Llama 2 和所有使用 GPT-4 定义扩展的数据集在零次和四次拍摄设置下的性能。在零镜头设置中,Llama 2 和 GPT-4 在单圈和迭代提示策略中都持续实现了显著的性能提升。相反,Claude 2 和 GPT-3.5仅在使用迭代提示时有所改进,平均性能分别提高了 12% 和 29.5%。
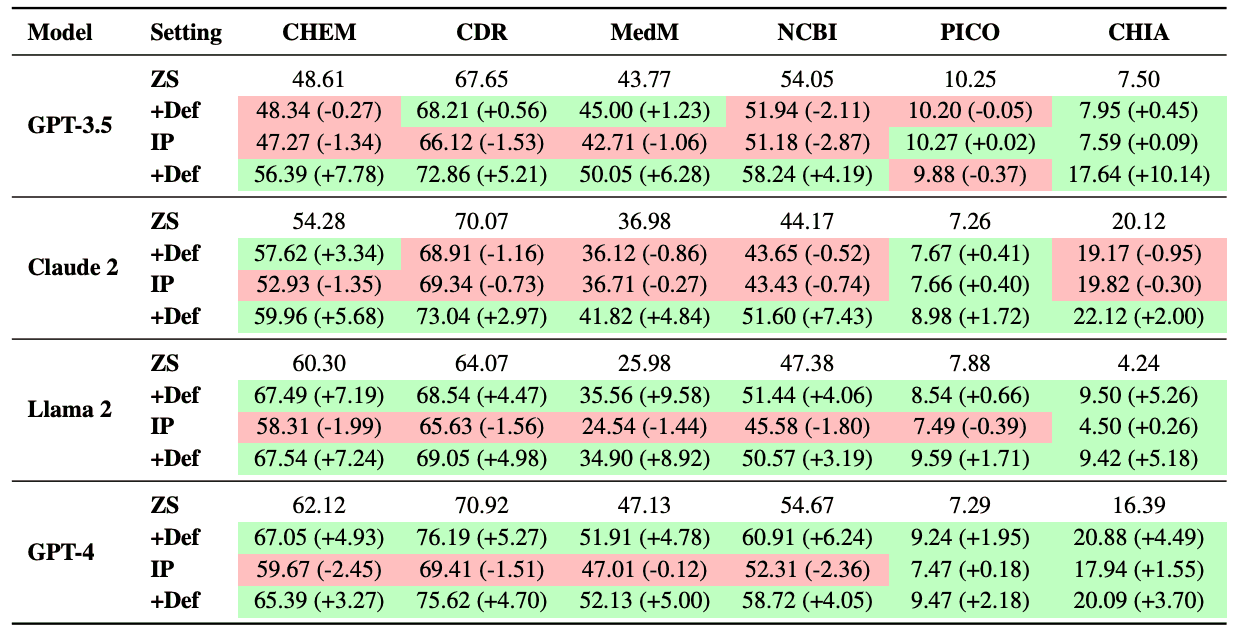
在 fuchsot 设置中,Claude 2 和 GPT-4 也在六个数据集中的五个数据集上取得了进步;Llama 2 和 GPT-3.5 也分别在三个和四个数据集上表现出色。总体而言,采用迭代提示的 GPT-4 表现最佳。这些结果证实,使用扩展概念定义进行提示可提高 NER 性能。
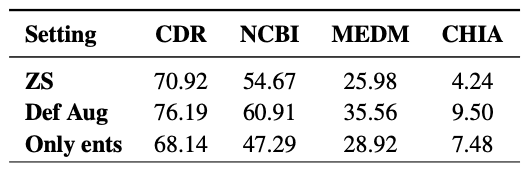
此外,我们还测试了单独使用实体链接器模型是否会带来很大的增益。结果表明,在相同的测试集上,单独使用实体链接器的性能较低,平均 F1 为 1.05,这并不是因为使用了实体链接器。下表中的结果表明,在没有概念定义的情况下添加候选实体的方法效果有限,在某些情况下,其性能还不如零镜头基线。
总结
本文利用大规模语言模型广泛评估了上下文学习(In-Context Learning)的有效性,重点关注生物医学土著表达识别(NER)领域。对不同形式的输入和输出进行了比较,以确定这些模型所犯的主要错误类型。它还提出了一种新方法,通过动态提供来自外部知识库的概念定义,快速调整通用大规模语言模型,使其适应生物医学 NER 任务,并测试了这种方法的有效性。
该过程使用一系列提示让模型修正其预测,并使用关键概念的定义来提高准确性。首先,要求模型提取实体,然后添加生物医学概念定义,促使模型修改预测。
对六个数据集进行的评估显示,与基线相比,特别是在零注射设置中,该模型有了持续而显著的改进。消融研究表明,模型利用概念定义的能力是改进的关键驱动力,如果没有这些定义,就无法实现有意义的预测改进。
虽然只考虑了生物医学专业领域的数据集,但研究表明,这种方法也可应用于维基数据等更广泛的知识库。这表明这种方法在其他领域也有潜在的优势,并可在未来的研究中进一步应用。