ConcurrentHashMap 在多线程应用程序中被广泛使用。多线程应用程序的示例包括在线游戏应用程序、聊天应用程序,它为应用程序增加了并发性的好处。为了使应用程序本质上更具并发性,ConcurrentHashMap 引入了一个名为“并行性”的概念。
在本文中,我们将了解有关 ConcurrentHashMap 中的并行性的更多信息。
什么是并行性?
基本上,并行计算将问题分解为子问题,然后并行解决这些子问题,最后将子问题的结果合并起来。此时子问题将在单独的线程中运行。
Java 对 ConcurrentHashMap 中的并行性支持
为了利用 ConcurrentHashMap 中的并行性,我们需要使用 Java 1.8 及以上版本。低于 1.8 的 Java 版本不支持并行性。
并行处理的通用框架
Java 引入了一个名为“fork and join”的框架来实现并行计算。它利用java.util.concurrent.ForkJoinPool API 来实现并行计算。此 API 用于在 ConcurrentHashMap 中实现并行性。
ConcurrentHashMap 中的并行方法
ConcurrentHashMap 借助并行度阈值有效地利用了并行计算。它是一个数值,默认值为 2。
以下是 ConcurrentHashMap 中具有并行功能的方法。
- forEach()
- 减少()
- 减少条目()
- forEachEntry()
- forEachKey()
- forEachValue()
ConcurrentHashMap 以稍微不同的方式处理并行性,如果您查看上述方法的方法参数,您就会明白这一点。这些方法中的每一个都可以将并行性阈值作为参数。
首先,并行度是一个可选功能,我们可以通过在代码中添加适当的并行阈值来启用该功能。
不具备并行性的 ConcurrentHashMap 的使用
让我们举一个替换 ConcurrentHashMap 的所有字符串值的例子。这是在没有使用并行性的情况下完成的。
例如:
ConcurrentHashMap.forEach **((k,v) -> v=””); **
这很简单,我们迭代 ConcurrentHashMap 中的所有条目,并用空字符串替换值。在这种情况下,我们不使用并行性
并行使用 ConcurrentHashMap
例如:
ConcurrentHashMap.forEach (2, (k,v) -> v=””);
上面的例子迭代了一个ConcurrentHashMap,并用空字符串替换了map的值。forEach()方法的参数是并行度阈值和一个功能接口。在这种情况下,问题将被分成子问题。
这里的问题是用空字符串替换 ConcurrentHashMap 的值。这是通过将这个问题分成子问题来实现的,即为子问题创建单独的线程,每个线程将专注于用空字符串替换该值。
当启用并行性时会发生什么 ?
当启用并行度阈值时,JVM 将创建线程,每个线程都会运行以解决问题并将所有线程的结果合并在一起。此值的意义在于,如果记录数已达到某个级别(阈值),则只有 JVM 才会启用并行处理。在上面的示例中。如果 Map 中有超过 1 条记录,则应用程序将启用并行处理。
这是一个很酷的功能,我们可以通过调整并行度阈值来控制并行度。这样我们就可以利用应用程序中的并行处理。
看一下下面的另一个例子:
ConcurrentHashMap.forEach (10000,(k,v) -> v=””);
在这种情况下,并行度阈值为 10000,这意味着如果记录数少于 10000,那么 JVM 在用空字符串替换值时将不会启用并行度。
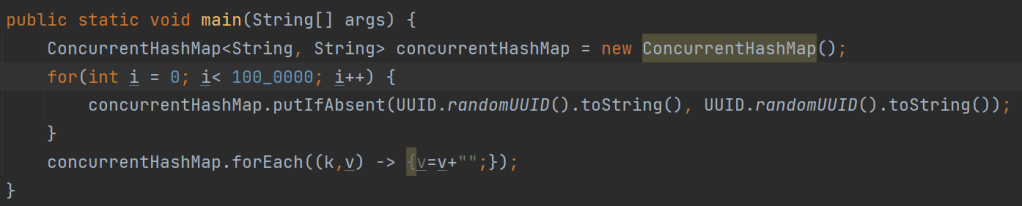
图:没有并行性的完整代码示例
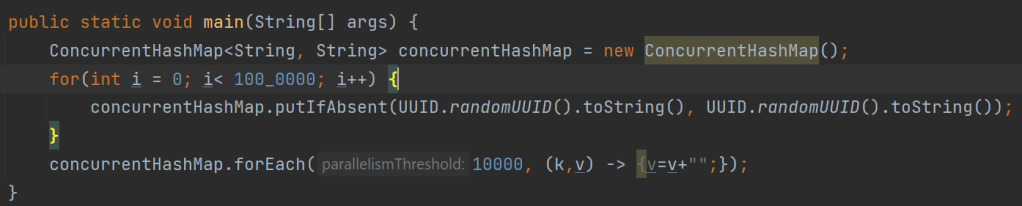
图:具有并行性的完整代码示例
在上面的例子中,并行度阈值是10000。
并行处理性能比较
以下代码只是用空字符串替换映射中的所有值。此 ConcurrentHashMap 包含超过 100000 个条目。让我们比较以下代码在没有并行和有并行的情况下的性能。
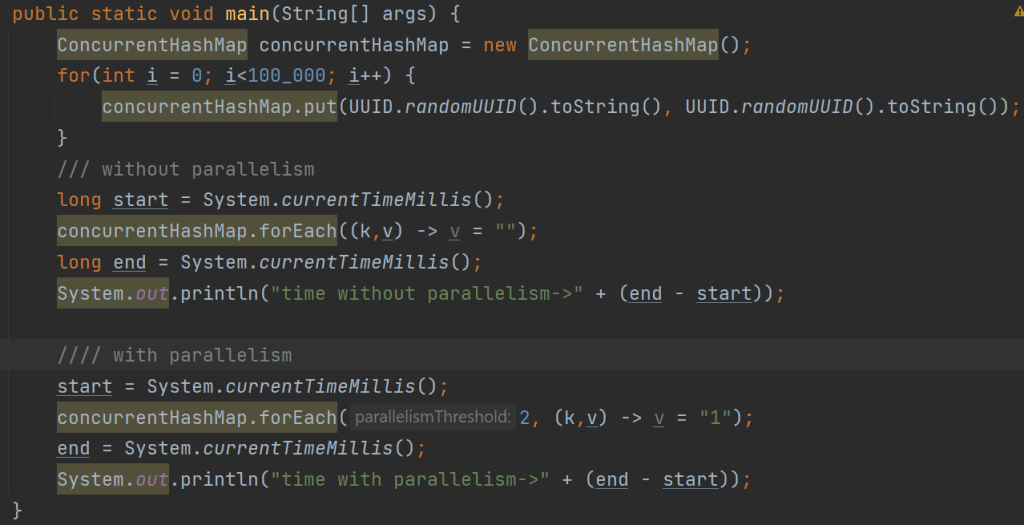
图:有并行性和无并行性的代码比较
运行上述代码后,可以看到在正常的forEach操作的情况下性能略有提升。
非并行时间->20 毫秒
并行时间->30 毫秒
这是因为地图中的记录数量相当少。
但是,如果我们在映射中添加1000 万条记录,那么并行性确实会获胜!处理数据所需的时间更少。看看下图中的代码:
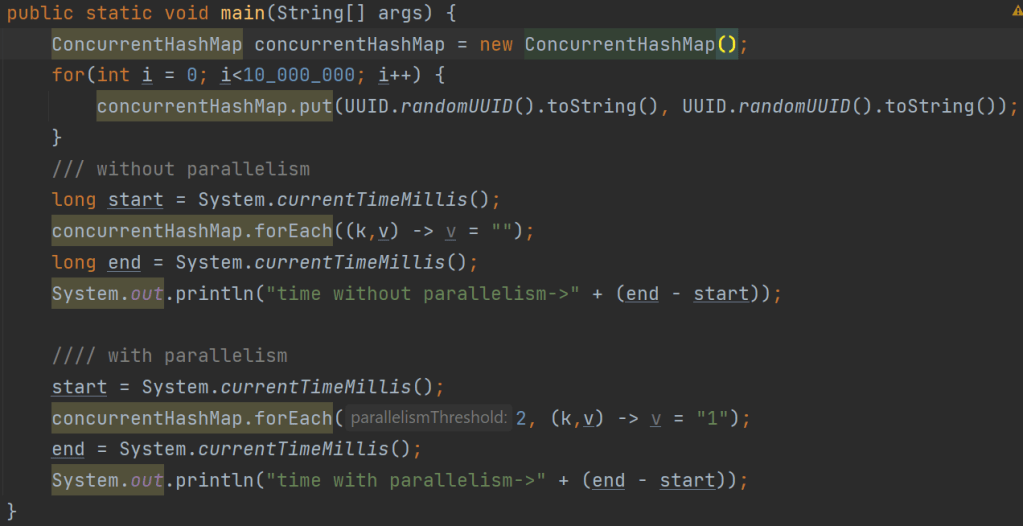
图:有和没有并行性的代码阈值
上述代码不使用并行性,而是将 ConcurrentHashMap 中的所有值替换为空字符串。接下来,它使用并行性将 ConcurrentHashMap 中的所有值替换为字符串 1。输出如下:
无并行性的时间->537 毫秒
有并行性的时间->231 毫秒
可以看到,在并行的情况下,只需要一半的时间。
注意: 以上值不是恒定的。在不同的系统中可能会产生不同的结果。
并行性的线程转储分析
当我们在代码中启用并行性时,JVM 使用 ForkJoinPool 框架来启用并行处理。该框架根据当前处理中的需求创建一些工作线程。让我们使用 fastthread.io 工具对上述代码进行启用并行性的线程转储分析。
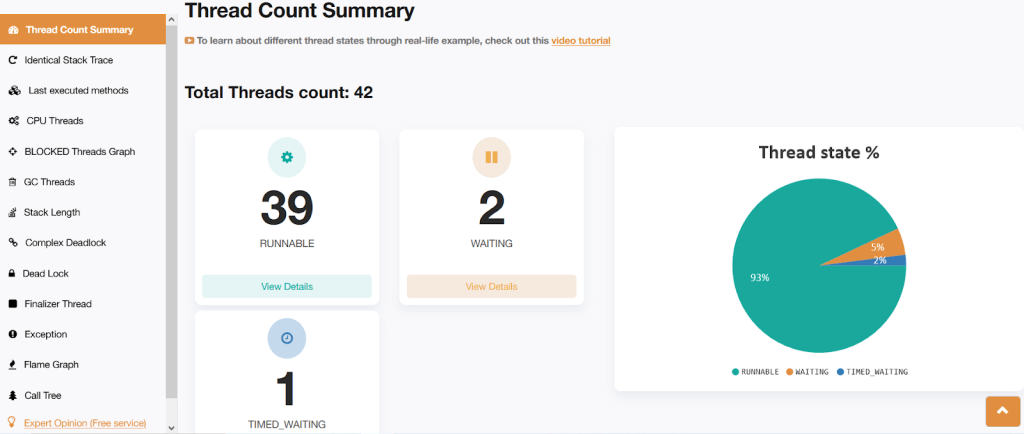
图:fastThread 报告显示启用并行后的线程数

图:fastThread 报告通过启用并行性显示相同的堆栈跟踪
在这种情况下,上述代码总共使用了 42 个线程。其中有 2 个处于等待状态,39 个正在运行,1 个处于定时等待状态。我们可以使用该工具分析更多行为。有关详细分析,您可以使用 fastthread.io 工具进行检查。
从上图你可以了解到它正在使用更多的线程。
运行线程过多的原因是它使用了 ForkJoinPool API。这是负责在后台实现“并行性”的 API。当您查看下一节时,您将了解这种差异。您可以在此处找到报告。
无并行性的线程转储分析
让我们了解在不启用并行的情况下的线程转储分析。

图:fastThread 报告显示未启用并行性的线程数

图:fastThread 报告显示未启用并行性的相同堆栈跟踪
如果仔细观察上图,你就会发现只使用了几个线程。与上图相比,本例中只有 35 个线程。本例中有 32 个可运行线程。但是,等待线程和 timed_waiting 线程分别为 2 个和 1 个。本例中可运行线程数量减少的原因是它没有调用 ForkJoinPool API。查看此报告了解更多详细信息。
这样,fastthread.io工具就可以以非常智能的方式深入了解线程转储内部情况。
总结
我们重点介绍了 ConcurrentHashMap 中的并行性以及如何在应用程序中使用此功能。此外,我们还了解了启用此功能时 JVM 会发生什么情况。并行性是一项很酷的功能,可以在现代并发应用程序中很好地使用。