一、说明
二、懒惰学习与急切学习
预先学习的工作原理是使用训练数据构建模型,然后使用此模型评估测试数据。如果评估结果合适,则使用获得的模型预测新数据。因此,预先学习在模型上执行大部分必要的工作,这些方法称为预先学习,因为它们在遇到新示例之前执行泛化。另一方面,惰性学习在从输入中接收新数据之前不会构建任何模型,并等待未分类的数据,然后开始构建预测模型,因此称为惰性学习,因为它推迟了模型的构建。
惰性学习算法的训练时间更短,预测时间更长。预先学习算法在训练阶段处理数据,并且比惰性学习算法更快地预测数据观察。
三、批量学习(离线)与在线学习
批量学习是指批量训练机器学习模型。换句话说,批量学习是指定期训练模型,例如每周、每两周、每月、每季度等。在批量学习中,系统不具备增量学习的能力,每次都必须使用所有可用数据对模型进行训练。在这种方法中,数据是在一段时间内收集和积累的,然后以定期的时间间隔尽可能多地使用积累的数据来训练模型。这种训练需要大量的时间和计算资源,因此,通常是离线完成的,因此,这种方法也被称为离线学习。使用批量学习训练的模型在面对新数据时,仅根据模型的性能以一定的时间间隔进行重新训练。
图 1.显示了批量训练方法的概述。

图 1.批量或离线训练概述
构建离线模型或批量训练模型需要使用整个训练数据集训练模型,而提高这些模型的性能需要使用整个训练数据集进行重新训练。这些模型的性质是静态的,这意味着一旦经过训练,它们的性能不会提高,直到重新训练新模型。模型的性能会随着时间的推移而缓慢下降,因为模型遇到的环境或数据每天都在变得更加复杂;而模型保持不变。这种现象通常称为模型旋转或数据漂移,一种可能的解决方案是定期使用新数据训练模型。
使用这些方法的原因有几个,可以提到如下:
1. 业务需求不需要重复学习模型。
2. 数据分布预计不会频繁更改。
3. 没有用于定期训练模型的软件系统和计算资源。
4. 没有创建渐进式学习系统所需的专业知识。
但在在线学习中,训练是逐步完成的,当新数据以小组或小批量的形式到达时。在这种方法中,每个学习步骤都很快,计算复杂度低,因此系统可以在新信息到达后立即学习。对于连续接收数据(例如股票价格)并需要适应快速或独立变化以及计算资源有限时的系统,在线学习是一个不错的选择。图 2 显示了在线学习方法的概述。
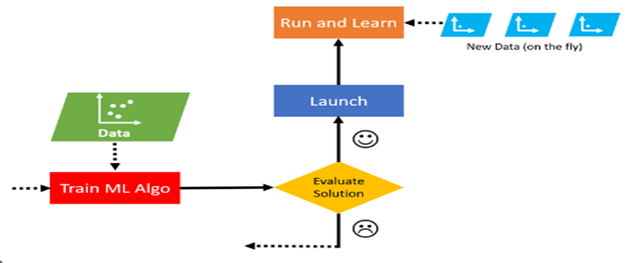
图 2.小组或离线培训概述
在线学习算法还用于在无法放入机器主内存的大量数据上训练系统,这也称为核外学习。它的工作方式是,算法加载一部分数据并对该数据运行训练步骤,然后重复此过程,直到它对所有数据运行。在线训练方法的缺点之一是,如果使用不适当的数据进行训练,系统性能会很差,最终用户很容易看到它的效果,总的来说,训练数据的质量在这种方法中非常重要。这种方法的具体应用之一是 Google 电子邮件系统,它有时会询问用户收到的电子邮件是垃圾邮件还是非垃圾邮件,并使用用户反馈来训练其算法。
四、惩罚 vs. 生成
机器学习模型可分为两种类型:判别模型和生成模型。
判别模型根据条件概率对看不见的数据进行预测,可用于分类或回归。相反,生成模型侧重于数据集的分布,以返回给定实例的概率。判别模型是指用于统计分类的一类模型,主要用于监督机器学习。这些类型的模型也称为条件模型,因为它们学习数据集中类或标签之间的边界。在两类分类问题中,判别模型的目标是学习将输入映射到二进制输出的函数。
判别模型无法生成新数据,可以说判别模型的最终目标是将一个类与另一个类分开。如果我们在数据集中有异常值,则与生成模型相比,判别模型的性能更好。在图 3 中,我们看到了区分模型的视图。
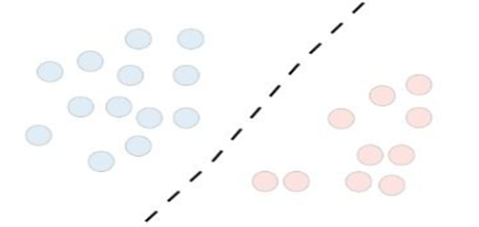
图 3.鉴别模型概述
换句话说,判别模型的目的是训练数据之间的分离线或超平面,使用判别模型的算法可以是 logistic 回归、支持向量机、神经网络类型、最近邻、决策树和随机森林指出。
生成模型是一类可以生成新数据的统计模型。这些模型在无监督机器学习中用作执行任务的方法,例如估计数据之间的概率和相似性、对数据点进行建模以及描述数据中的现象。因为这些模型经常使用贝叶斯定理(我将在未来几天讨论这个算法)来寻找联合概率,所以它们可以处理比判别模型更复杂的任务。因此,生成方法侧重于数据集中类的分布,并对数据点的基础模式或分布(例如高斯分布)进行建模。图 4 显示了生成器模型的视图。

图 4.发电机模型概述
与试图在数据之间绘制分隔线或超平面的判别模型不同,生成模型尝试学习数据的概率分布。使用生成模型的算法包括 Naïve Bayes、Bayes 网络、马尔可夫随机场、隐马尔可夫模型 (HMM)、生成对抗网络 (GAN) 和自回归模型。
注: 自回归模型是一类机器学习 (ML) 模型,它通过对序列中先前的输入进行测量来自动预测序列中的下一个分量。
为了更好地理解这两种方法,这两种方法之间的区别可以总结如下。
·判别模型的主要思想是找到判别边界并在数据空间中绘制它,而生成模型则试图对数据的位置进行建模。
·生成模型可以生成数据,而判别模型侧重于预测数据标签。
·假设我们有输入数据 x,并且我们想使用 y 标签对数据进行分类。生成模型学习联合概率分布 p(x, y),判别模型学习条件概率分布 p(y|x) 或以 x 为条件的 y 的概率。条件概率意味着我们有两个事件,如果事件 x 已经发生,我们想计算事件 y 的概率。换句话说,假设事件 x 已经发生,事件 y 发生的可能性有多大,我们将在未来详细讨论。
·判别模型识别现有数据,即可用于对数据进行分类,而生成模型可以生成数据。
·生成模型通常用于无监督学习任务,判别模型通常用于监督学习任务。
·生成模型比判别模型更容易受异常值数据的影响。
·与生成模型相比,差异化模型的计算成本较低。
“GAN” 网络可以看作是生成网络模型和判别网络模型之间的竞争,如图 5 所示,作为这些算法产生的图像的一个例子,所有的图像都是由该算法产生的。

图 5 是 “GAN” 网络生成的图像示例。
五、基于实例的学习与基于模型的学习
基于实例的学习(也称为基于内存的学习或惰性学习)涉及记住训练数据,以预测模型未见过的新数据。这种方法不需要任何关于数据的先验知识或假设,这使得它易于实施和理解。但是,计算成本可能很高,因为在进行预测之前,所有训练数据都必须存储在内存中。
在基于实例的学习中,该算法会记住训练数据,并在进行预测时使用相似性度量并将新项目与存储的数据进行比较。图 5 显示了如何根据其相邻样本预测新样本。
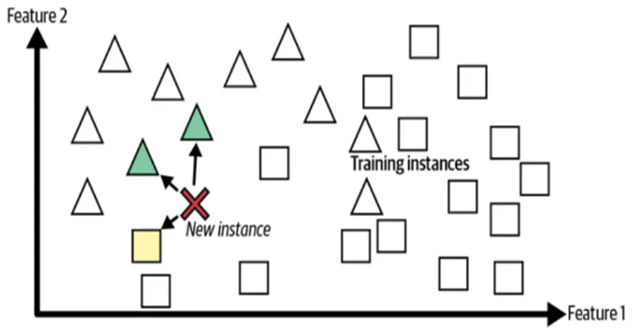
图 5.基于实例的学习算法的一般形式
基于模型的学习方法(也称为基于结构的学习或预先学习)通过从训练数据构建模型,可以比基于实例的方法更好地泛化。这涉及使用线性回归、逻辑回归、随机森林树等算法来创建可用于预测新数据点的模型。
图 6 显示了如何根据从训练数据中学到的边界来执行类预测,而不是与基于相似性度量的存储数据集进行比较。
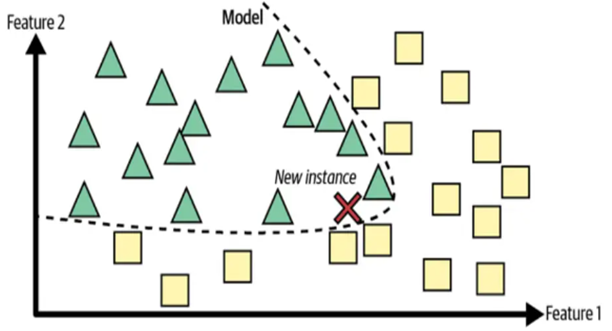
图 6.基于模型的学习算法的一般形式
基于实例的学习和基于模型的学习有几个关键区别,可以提到如下:
泛化性:在基于模型的学习中,目标是学习一个可用于预测新数据的可泛化模型,这意味着该模型在一个数据集上训练,然后在另一个数据集上训练,该模型以前从未见过它们,模型的评估和性能受到测试。相比之下,基于实例的学习算法只记住训练示例并使用它们来预测新数据。这意味着基于实例的学习算法不会尝试学习可泛化的模型,并且它们在新数据上的性能不如基于模型的算法可靠。
可扩展性: 由于基于实例的学习算法只记住训练样本,因此在处理大型数据集时,它们可能会非常缓慢,并且在某些情况下无法使用,因为模型必须将所有训练样本存储在 store the memory 中,并将新数据与每个存储的样本进行比较。相比之下,基于模型的学习算法可以更具可扩展性,因为它们不必存储所有训练示例。相反,他们学习了一个模型,该模型可用于在不存储训练数据的情况下进行预测。
可解释性: 基于模型的学习算法通常生成的模型比基于示例的学习算法更容易解释,因为基于模型的算法学习一组可用于了解模型如何预测的规则或参数。相比之下,基于示例的学习算法只是存储训练示例并将其用作预测的基础,这可能会使预测难以解释。
六、参数模型与非参数模型
在机器学习中,参数模型对数据的概率分布做出假设,并且具有固定数量的参数,这些参数不依赖于训练数据的数量。从数据中学习参数后,该模型可用于预测新数据。另一方面,非参数模型对数据的概率分布没有假设,并且不能用一组参数指定模型,并且参数的数量会随着训练数据的数量而变化。非参数模型通常需要更多的数据来估计其参数,并且其计算速度可能比参数模型慢。参数模型的示例包括线性回归、逻辑回归和简单贝叶斯。非参数模型的示例包括 k 最近邻、决策树和随机森林。
通常,当数据相对简单并遵循已知的概率分布时,参数模型非常有用,而非参数模型更适合于复杂和异构数据。
七、结论
在第 10 部分中,我们讨论了 ML 中的不同类型的学习。在接下来的机器学习之旅中,我们将讨论 AI 中不同类型的算法,尤其是在第 11 部分:下一节中,我们将研究逻辑回归,这是一种用于二元分类任务的流行统计模型,通过根据输入变量估计事件发生的概率。