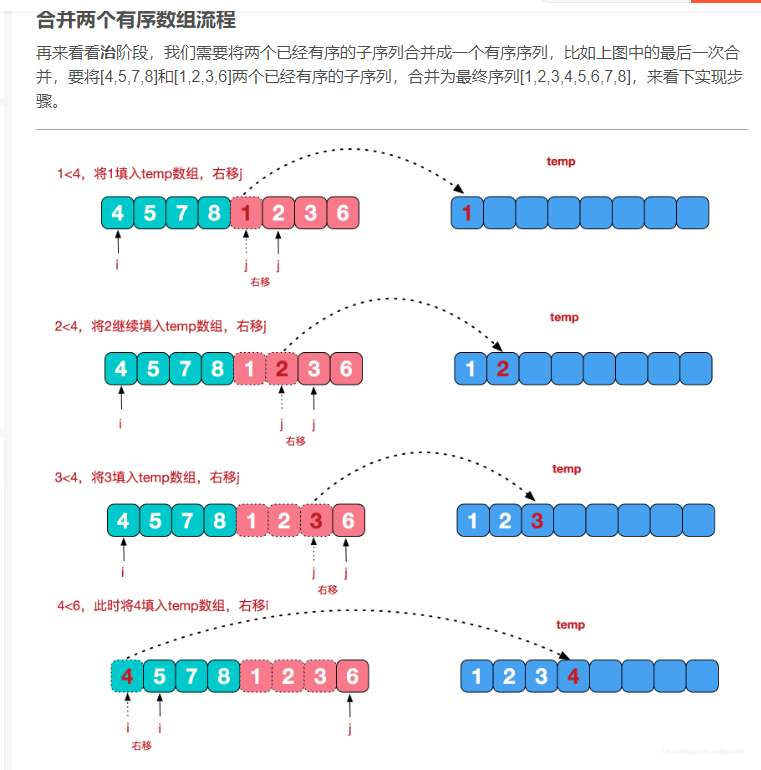
索引数据结构
索引(index)是帮助MySQL高效获取数据的一种有序数据结构。索引是存储到表空间中,当我们的 sql 中的where条件用到索引的时候,会在存储层就过滤出数据来,如果不走索引,则需要在server层过滤。 存储层过滤的性能比在server层更好。
常用的索引结构有:Hash表,二叉树,平衡二叉查找树(红黑树是一个近似平衡二叉树),B树,B+树。
数据结构在线演示网站:Data Structure Visualization
Mysql5.7之后选用B+树作为默认的索引结构,接下来,介绍各种数据结构存在的优缺点。
Hash表
我们使用Hash表存储表数据Key可以存储索引列,Value可以存储行记录或者行磁盘地址。Hash表在等 值查询时效率很高,时间复杂度为O(1);
原理
A. 事先将索引通过 hash算法后得到的hash值(即磁盘文件指针)存到hash表中。
B. 在进行查询时,将索引通过hash算法,得到hash值,与hash表中的hash值比对。通过磁盘文件指针,只要一次磁盘IO就能找到要的值。
优点:
- 对索引的key进行一次 hash 计算就可以定位出数据存储的位置。
- 很多时候 hash 索引要比 B+ 树索引更高效
缺点:
- 仅能满足 ''='',''IN'',不支持范围查询(
因为Hash冲突问题,且hash表无序) - 不适合模糊查询(like)的场景

二叉树
特点:父节点左子树所有结点的值小于父节点的值,右子树所有结点的值大于父节点的值。二叉树的检索复杂度和树高相关:理想状态下效率可以达到O(logn)
缺点:在某些特定的情况下,二叉树有可能退化成单链表的,此时会进行全表扫描,并且元素的查找效率也会明显的下降。

红黑树
红黑树是一个近似平衡的二叉树。
平衡二叉树是采用二分法思维,平衡二叉查找树除了具备二叉树的特点,最主要的特征是树的左右两个 子树的层级最多相差1。在插入删除数据时通过左旋/右旋操作保持二叉树的平衡,不会出现左子树很 高、右子树很矮的情况。
使用平衡二叉查找树查询的性能接近于二分查找法,时间复杂度是 O(log2n)。
缺点:
- 时间复杂度和树高相关:树有多高就需要检索多少次,每个节点的读取,都对应一次磁盘 IO 操作 【瓶颈】。
- 磁盘每次寻道时间为10ms,在表数据量大时,对响应时间要求高的场景下,查询性能就会出 现瓶颈。 举例:1百万的数据量,log2n约等于20次磁盘IO,时间20*10=0.2s
- 平衡二叉树不支持范围查询快速查找,范围查询时需要从根节点多次遍历,查询效率极差。
- 数据量大的情况下,索引存储空间占用巨大

B树
减少耗时的IO操作,就要尽量降低树的高度, 把二叉树,变为多叉树。每个节点存储多个元素,在每个节点尽可能多的存储 数据。
特点:
- B树的节点中存储着多个元素,每个节点内有多个分叉。
- 节点中的元素包含键值和数据,节点中的键值从大到小排列。也就是说,在所有的节点都储存数 据。
- 父节点当中的元素不会出现在子节点中。
- 所有的叶子结点都位于同一层,叶节点具有相同的深度,叶节点之间没有指针连接
优点:
- 磁盘IO次数会大大减少。
- 比较是在内存中进行的,比较的耗时可以忽略不计。
- B树的高度相比于平衡二叉树会大幅缩小,所以使用B树构建索引可以很好的提升查询的效率。
缺点:
- B树不支持范围查询的快速查找:如果我们想要查找15和26之间的数据,查找到15之后,需要回到 根节点重新遍历查找,需要从根节点进行多次遍历,查询效率有待提高。
- 空间占用较大:如果data存储的是行记录,行的大小随着列数的增多,所占空间会变大。一个页中 可存储的数据量就会变少,树相应就会变高,磁盘IO次数就会变大。

B+树
在B树基础上,MySQL在B树的基础上继续改造,使用B+树构建索引。B+树和B树最主要的区别在于非 叶子节点是否存储数据的问题
B树:非叶子节点和叶子节点都会存储数据。
B+树:只有叶子节点才会存储数据,非叶子节点只存储键值。叶子节点之间使用双向指针连接,最 底层的叶子节点形成了一个双向有序链表。
优点:
- 继承了B树的优点【多叉树的优点】
- 支持范围查询,保证等值和范围查询的快速查找
- MySQL的索引就采用了B+树的数据结构。









![[Linux] Linux 的进程如何调度——Linux的 O(1)进程调度算法](https://i-blog.csdnimg.cn/direct/2e68aaca6a914648bc6e3b0528c6667f.png)