什么是token?为什么要限制token的输入?平时说的消耗token数指的是什么?
token是用于自然语言处理的词的片段。
在自然语言处理模型中,限制token数量主要是出于计算效率和资源限制的考虑。每一个token都对应一个向量,当输入模型的token数量增加时,模型需要处理的数据量也会相应增加,这对计算资源(如内存和计算能力)的需求也会增大。因此,在现实应用中,为了保证模型能在可接受的时间内完成任务,通常会对输入的token数量设置一个上限。
当我们说模型消耗的token数时,通常是指在一次计算(比如一次训练步骤中或是一次推理过程中)模型处理的token总量(包括input和output)。不同模型的tokenizer不同,所以不同模型计算同一个句子的token数不同。
token的组成可以参考下图,不同模型可能定义了不同字部分的独立限制:
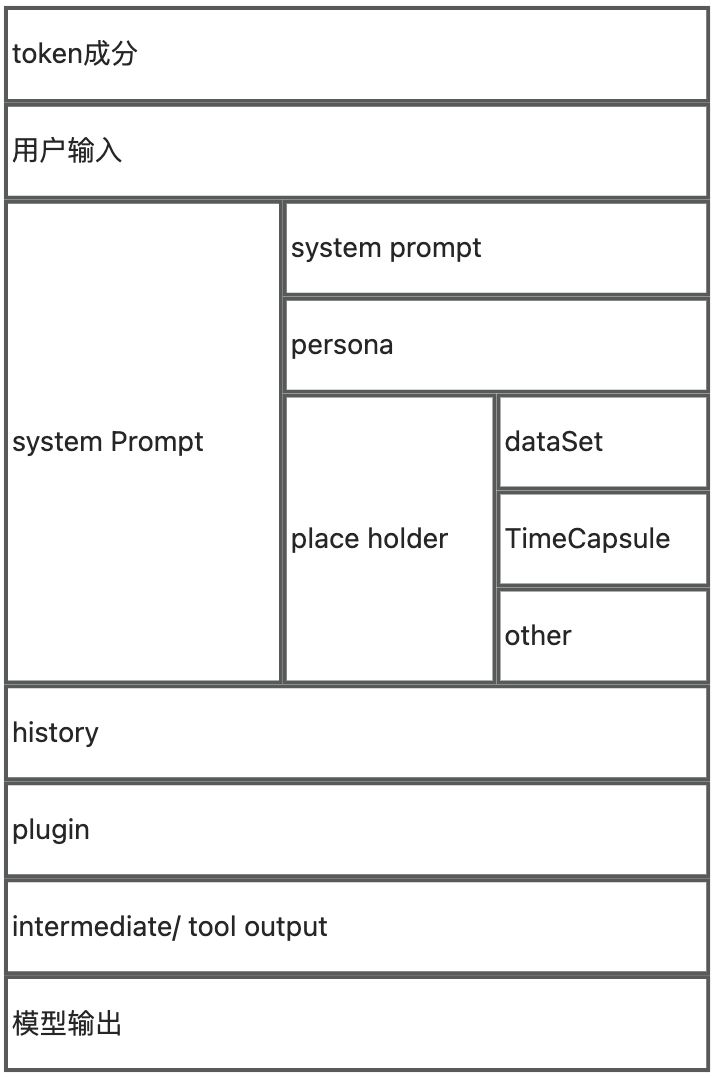
为什么训练成本的消耗要用token消耗来衡量?
- 直观:模型训练时的基本单位就是token,每个token都需要模型进行处理和计算。因此,token数可以直接反映训练过程中的计数量。这使得token消耗成为一种直观易懂的衡量标准。
- 通用性:不同的模型、不同的任务,其训练过程中的具体操作可能会不同,但token作为基本处理单元,其存在是共通的。因此,使用token消耗作为衡量标准,具有良好的通用性和一致性。
- 与模型复杂性关联:模型处理的token数和模型的复杂性直接相关,处理的token越多,模型的复杂性通常越高,进而对计算资源的需求也越大。因此,使用token消耗可以有效的反映模型训练的复杂度和成本。
备注:
tokenizer(token计数器):词元分析器是一种计算机处理文本的技术。它将文本分解成一个个单独的词元,也就是文本中的单词、数字、符号等基本单位。词元分析器常用于自然语言处理、搜索引擎、文本挖掘等应用中,能够帮助进行文本的预处理和数据的清洗。在机器学习和深度学习领域中,词元分析器也是必不可少的一步,它能够将文本数据转化为数学模型所需要的向量或矩阵形式,更方便进行后续的算法和模型训练。https://platform.openai.com/tokenizer












![【Python报错已解决】[notice] A new release of pip available: 22.2 -> 22.2.2](https://i-blog.csdnimg.cn/direct/e5ca7849d0bd40b3ae7a083a00244132.png#pic_center)


