文章目录
- 前言
- 1. Java 集合框架概述
- 1.1 Java 集合框架的定义和意义
- 1.2 Java 集合框架的历史演进
- 1.3 集合框架的基本组成部分
- 1.4 Java 集合的优势
- 1.5 Java 集合与数组的区别与关系
- 2. Java 集合框架的核心接口
- 2.1 Collection 接口
- 2.2 List 接口
- 2.3 Set 接口
- 2.4 Queue 接口
- 2.5 Map 接口
- 3. List 接口与实现类详解
- 3.1 List 接口的特点与应用场景
- 3.2 ArrayList:动态数组的实现
- 3.3 LinkedList:基于链表的双向链表实现
- 3.4 Vector 和 Stack:线程安全的 List 实现
- 3.5 List 常用操作和方法
- 3.6 ArrayList vs. LinkedList
- 4. Set 接口与实现类详解
- 4.1 Set 接口的特点与应用场景
- 4.2 HashSet:基于哈希表的实现
- 4.3 LinkedHashSet:有序哈希表实现
- 4.4 TreeSet:基于红黑树的实现,支持排序
- 4.5 EnumSet:专门处理枚举类型的 Set 实现
- 4.6 Set 常用操作和方法
- 4.7 HashSet vs. TreeSet vs. LinkedHashSet
- 5. Queue 和 Deque 接口与实现类详解
- 5.1 Queue 接口的特点与应用场景
- 5.2 PriorityQueue:基于堆实现的优先队列
- 5.3 LinkedList 作为 Queue 的实现
- 5.4 ArrayDeque:基于数组的双端队列实现
- 5.5 Deque 接口详解
- 5.6 BlockingQueue 和其实现类
- 5.7 Queue 和 Deque 常用操作与方法
- 6. Map 接口与实现类详解
- 6.1 Map 接口的特点与应用场景
- 6.2 HashMap:基于哈希表的实现
- 6.3 LinkedHashMap:有序哈希表实现
- 6.4 TreeMap:基于红黑树的实现,支持排序
- 6.5 WeakHashMap 和 IdentityHashMap:特殊场景下的 Map 实现
- 6.6 ConcurrentHashMap:线程安全的 Map 实现
- 6.7 Map 常用操作与方法
- 6.8 HashMap vs. TreeMap vs. LinkedHashMap
- 7. Collections 工具类
- 7.1 Collections 类的作用与概述
- 7.2 常见方法:排序、查找、填充、逆序、同步化
- 排序 (sort)
- 查找 (search)
- 填充 (fill)
- 逆序 (reverse)
- 同步化 (synchronizedXxx)
- 7.3 Collections.synchronizedXxx:线程安全的集合
- 7.4 Collections.unmodifiableXxx:不可变集合的创建
- 7.5 Collections.emptyXxx:空集合的创建
- 7.6 自定义比较器:Comparator 接口与 Lambda 表达式的结合
- Comparator 接口
- Lambda 表达式与 Comparator 结合
- 8. Java 8 Stream API 与集合框架的结合
- 8.1 Stream API 简介
- 8.2 Stream 与集合的关系
- 8.3 Stream 的操作类型:中间操作和终端操作
- 中间操作
- 终端操作
- 8.4 常见 Stream 操作
- 过滤(Filter)
- 映射(Map)
- 归约(Reduce)
- 收集(Collect)
- 8.5 并行 Stream
- 8.6 Stream API 在集合框架中的应用示例
- 对 `List` 进行过滤、映射和排序
- 使用 `Map` 和 `Collectors.groupingBy` 进行数据分组
- 9. 泛型与 Java 集合框架
- 9.1 什么是泛型
- 9.2 为什么集合需要泛型
- 9.3 集合框架中的泛型应用
- 10. 集合的性能与优化
- 10.1 各种集合的性能对比
- 10.2 选择合适的集合:时间复杂度与空间复杂度的权衡
- 常见场景选择
- 内存占用差异
- 10.3 集合大小的初始设置与调整
- ArrayList 容量调整
- HashMap 的容量与负载因子
- 10.4 使用 Iterator 和增强 for 循环遍历集合的性能差异
- Iterator 遍历
- 增强 for 循环
- 10.5 避免不必要的集合复制与转换
- 不必要的复制操作
- 避免重复的类型转换
- 10.6 使用并发集合提高性能
- ConcurrentHashMap
- CopyOnWriteArrayList
- BlockingQueue
- 11. 线程安全与并发集合
- 11.1 线程安全集合概述
- 11.2 同步集合
- Vector
- Hashtable
- Collections.synchronizedXxx()
- 11.3 并发集合
- ConcurrentHashMap
- CopyOnWriteArrayList
- ConcurrentLinkedQueue
- 11.4 StampedLock 与 ReadWriteLock 在集合中的应用
- ReadWriteLock
- StampedLock
- 11.5 如何选择并发集合
- 12. 不可变集合与空集合
- 12.1 不可变集合的意义
- 12.2 使用 Collections.unmodifiableXxx 创建不可变集合
- 12.3 Java 9+ 提供的 List.of(), Set.of(), Map.of() 方法
- 12.4 空集合的特殊处理
- 12.5 常见的不可变集合应用场景
- 13. Java 集合框架中的设计模式
- 13.1 迭代器模式(Iterator Pattern)
- 13.2 工厂模式(Factory Pattern)在集合框架中的应用
- 13.3 策略模式(Strategy Pattern):Comparator 与排序算法
- 13.4 观察者模式(Observer Pattern)与事件通知机制
- 14. Java 集合框架中的常见错误
- 14.1 ConcurrentModificationException
- 14.2 NullPointerException
- 14.3 ClassCastException
- 本期小知识
前言
这里是分享 Java 相关内容的专刊,每日一更。
本期将为大家带来以下内容:
- Java 集合框架概述
- Java 集合框架的核心接口
- List 接口与实现类详解
- Set 接口与实现类详解
- Queue 和 Deque 接口与实现类详解
- Map 接口与实现类详解
- Collections 工具类
- Java 8 Stream API 与集合框架的结合
- 泛型与 Java 集合框架
- 集合的性能与优化
- 线程安全与并发集合
- 不可变集合与空集合
- Java 集合框架中的设计模式
- Java 集合框架中的常见错误
1. Java 集合框架概述
1.1 Java 集合框架的定义和意义
在日常编程中,我们经常需要处理 一组数据,比如要保存一系列的数字、字符、对象等。为了高效地管理和操作这些数据,Java 提供了一套强大且灵活的工具,称为 集合框架(Collections Framework)。简单来说,集合框架就是 一组类和接口,用来存储、操作和处理多个数据。
举个简单的例子,当你需要存储多个名字、数字或对象时,Java 集合框架可以让你轻松完成这些任务,而不必自己编写复杂的代码来手动处理这些数据。通过使用集合框架,我们可以轻松地 添加、删除、查找、排序 数据,极大地简化了编程工作。
1.2 Java 集合框架的历史演进
Java 集合框架并不是从一开始就存在的,它在 Java 2(JDK 1.2) 版本中引入。最初,Java 语言有一些基本的数据结构,比如 数组(Array),但是这些结构在处理动态数据(比如元素数量不固定时)时并不灵活。
为了提供一种统一的方式来管理和操作数据,Java 在 JDK 1.2 中引入了集合框架,并且随着 Java 的发展,集合框架也得到了不断扩展和优化。例如,在 Java 5 中引入了 泛型(Generics),使集合框架更安全、更方便。在 Java 8 中,又加入了 Stream API,让我们可以更高效地操作集合中的数据。
现在,Java 集合框架已经成为 Java 编程语言中不可或缺的部分,几乎所有 Java 程序都依赖于它来管理和操作数据。
1.3 集合框架的基本组成部分
Java 集合框架的核心结构可以分为三个部分:接口(Interfaces)、实现类(Classes)和算法(Algorithms)。
- 接口:接口定义了集合的行为和操作。例如,
List接口表示一个有序的集合,Set接口表示一个不能包含重复元素的集合。这些接口是集合框架的蓝图,规定了每种集合类型可以做什么。 - 实现类:实现类是接口的具体实现。比如,
ArrayList是List接口的实现,HashSet是Set接口的实现。这些类提供了不同的存储和操作方式,让我们可以根据不同需求选择合适的实现类。 - 算法:集合框架中还包含一些用于操作集合的通用算法,像排序、查找、填充等。这些算法大多由工具类
Collections提供。通过这些算法,我们可以在不修改集合结构的前提下,对集合中的数据进行各种操作。
总结来说,集合框架的接口是规则,具体的实现类是我们可以直接使用的工具,而算法则是我们可以用来操作这些工具的“招式”。
1.4 Java 集合的优势
Java 集合框架之所以受到广泛欢迎,主要因为它具有以下几个显著优势:
- 可重用性:集合框架提供了许多已经设计好、测试过的类和接口,我们可以直接使用这些组件,而不必重新设计数据结构。这提高了代码的可重用性,也减少了开发和测试的时间。
- 灵活性:集合框架有多种不同类型的集合结构,比如列表(
List)、集合(Set)、映射(Map)等。我们可以根据需要选择最合适的集合来处理数据,这让代码更加灵活。 - 易维护性:使用集合框架后,我们的代码变得更加简洁和结构化。此外,由于 Java 集合框架已经经过大量优化和测试,它能确保数据操作的效率和稳定性,从而减少了维护的成本和难度。
1.5 Java 集合与数组的区别与关系
虽然 数组(Array)和 集合(Collections) 都可以存储多个元素,但它们有很大的区别:
| 比较维度 | 数组 | 集合(如 ArrayList) |
|---|---|---|
| 大小是否固定 | 大小是固定的,创建后无法改变 | 大小是动态的,可以根据需要自动增长或缩小 |
| 数据类型是否统一 | 存储相同类型的数据(如 int[]、String[]) | 存储对象类型的数据,可通过泛型指定存储类型 |
| 功能和灵活性 | 只能进行简单的存储和读取 | 提供丰富的操作方法(如添加、删除、排序、去重等) |
| 使用场景 | 适用于需要高效访问特定元素的场景 | 适合处理数量未知、动态变化的数据,执行复杂操作时适用 |
2. Java 集合框架的核心接口
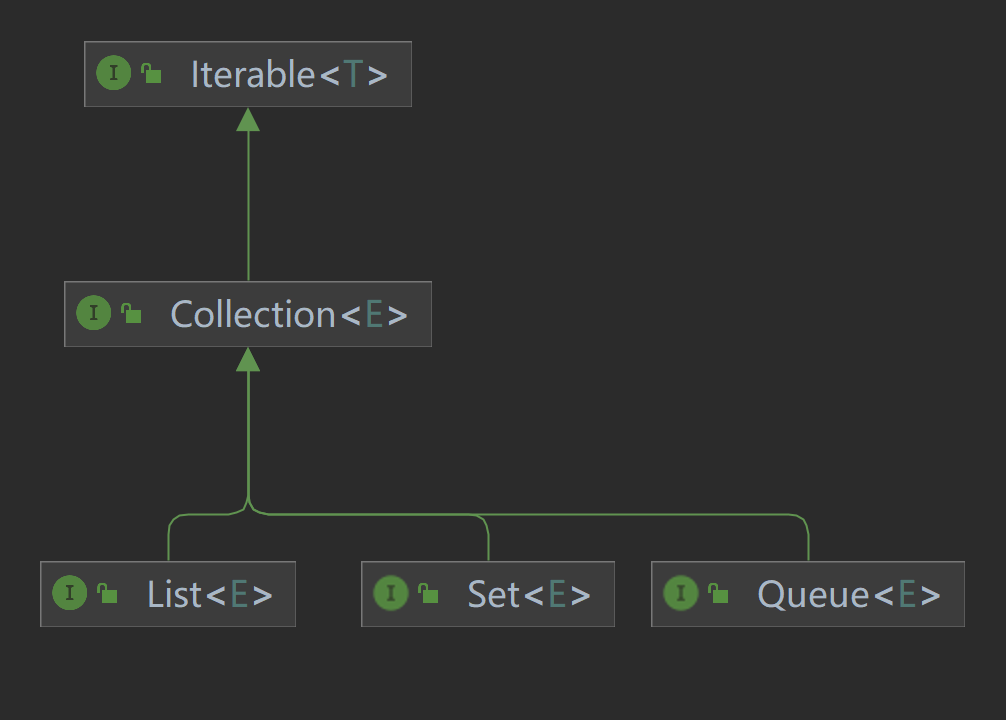
2.1 Collection 接口
Collection 是所有集合接口的基类,它定义了一些集合操作的基本方法。虽然 Collection 本身不能直接实例化,但它为 List、Set 和 Queue 等子接口提供了规范。
Collection 的常用方法:
| 方法名称 | 功能描述 |
|---|---|
add(E e) | 将元素加入集合。 |
remove(Object o) | 移除集合中的指定元素。 |
size() | 返回集合中的元素数量。 |
isEmpty() | 判断集合是否为空。 |
contains(Object o) | 检查集合中是否包含指定元素。 |
这里要注意的是,Collection 并没有规定元素的顺序、可重复性或者具体的存储机制,这些特点由它的子接口如 List、Set 和 Queue 来进一步细化。
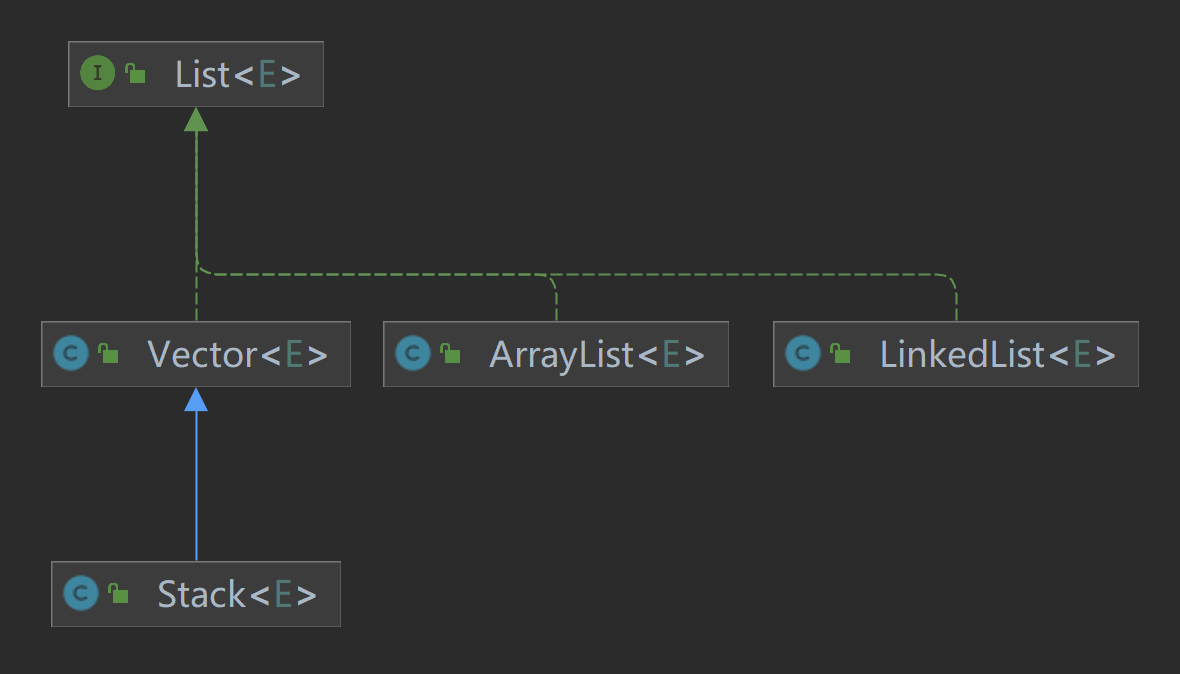
2.2 List 接口
List 是 Collection 的子接口,它的特点是 有序 且 允许重复。这意味着在 List 中,元素的插入顺序会被记录,并且可以包含多个相同的元素。
List 的核心特性:
- 元素有序:插入顺序得到保证,意味着你可以通过索引访问元素。
- 允许重复:与
Set不同,List允许多个相同的元素存在。
List 接口的常用实现类:
| 实现类 | 底层数据结构 | 随机访问性能 | 插入/删除性能 | 线程安全性 | 适用场景 |
|---|---|---|---|---|---|
ArrayList | 动态数组 | O ( 1 ) O(1) O(1) | O ( n ) O(n) O(n) | 否 | 频繁读取 |
LinkedList | 双向链表 | O ( n ) O(n) O(n) | O ( 1 ) O(1) O(1) | 否 | 频繁插入、删除 |
Vector | 动态数组 | O ( 1 ) O(1) O(1) | O ( n ) O(n) O(n) | 是 | 已过时,但在某些情况下需要线程安全的场景 |
Stack | 基于 Vector | O ( 1 ) O(1) O(1) | O ( n ) O(n) O(n) | 是 | 后进先出的栈操作 |
性能比较:
- ArrayList 适合读多写少的场景,因为它的随机访问性能非常高。
- LinkedList 适合频繁插入和删除元素的场景,特别是在中间位置操作时表现出色。
- Vector 虽然是线程安全的,但由于其所有操作都经过同步,性能较
ArrayList和LinkedList差。
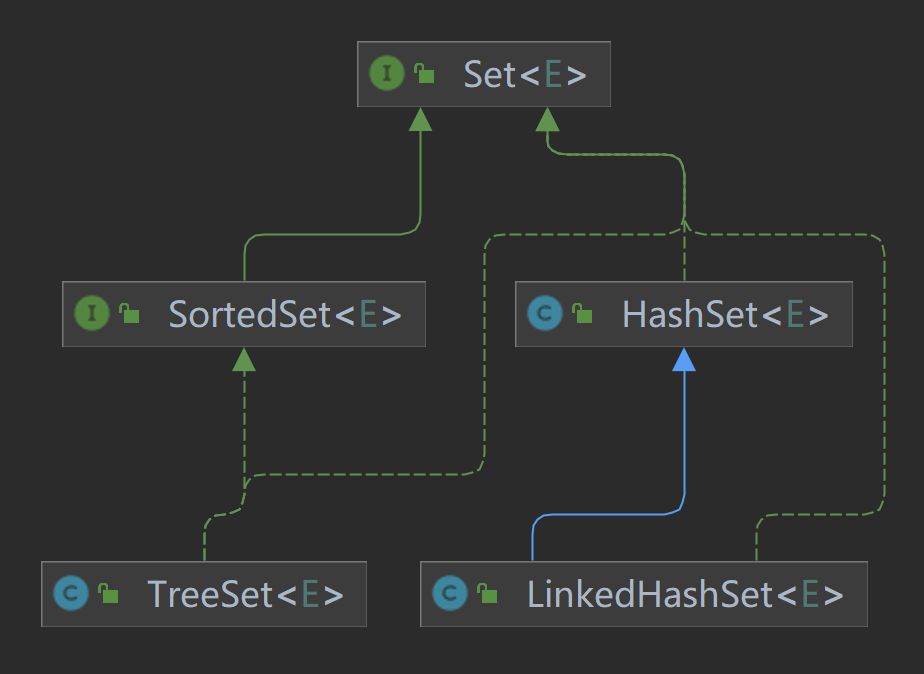
2.3 Set 接口
Set 是 Collection 的子接口,它的最大特点是 不允许重复元素。Set 主要用于需要确保集合中元素唯一的场景。
Set 的核心特性:
- 无重复性:任何元素在集合中只会出现一次。
- 有序性(取决于实现类):例如
HashSet无序,而TreeSet有序。
Set 接口的常用实现类:
| 实现类 | 底层数据结构 | 查找性能 | 插入/删除性能 | 有序性 | 适用场景 |
|---|---|---|---|---|---|
HashSet | 哈希表 | O ( 1 ) O(1) O(1) | O ( 1 ) O(1) O(1) | 无序 | 需要快速去重的场景 |
LinkedHashSet | 哈希表 + 链表 | O ( 1 ) O(1) O(1) | O ( 1 ) O(1) O(1) | 插入顺序 | 保持插入顺序的去重 |
TreeSet | 红黑树 | O ( l o g n ) O(logn) O(logn) | O ( l o g n ) O(logn) O(logn) | 有序 | 需要排序的集合场景 |
性能分析:
- HashSet 是去重集合中最快的选择,但如果你对顺序有要求,
LinkedHashSet更合适。 - 如果需要按顺序(例如数字大小或字母顺序)存储元素,
TreeSet是最好的选择。
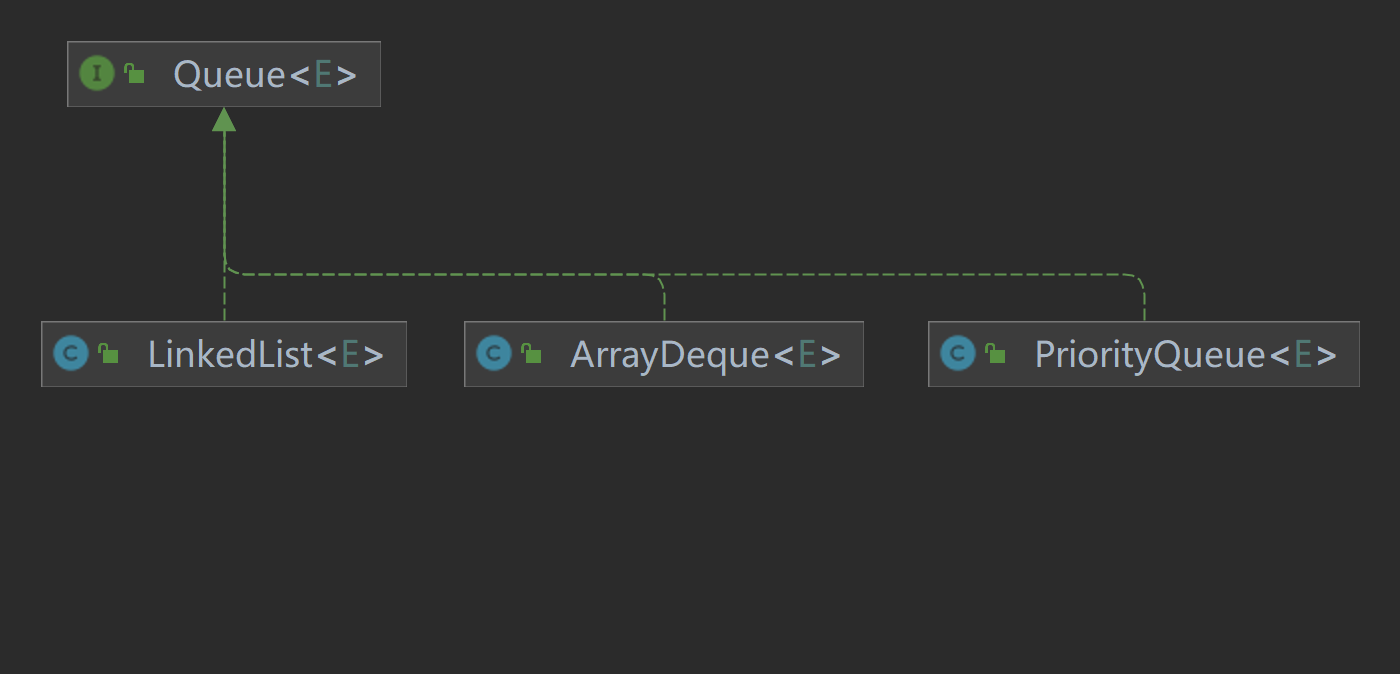
2.4 Queue 接口
Queue 是一个 先进先出(FIFO)的数据结构,通常用于任务调度、消息处理等需要按顺序处理元素的场景。
Queue 的核心特性:
- 先进先出(FIFO):最先加入队列的元素最先被处理。
- 特定场景:可以使用优先级队列(
PriorityQueue)来处理带有优先级的任务。
Queue 接口的常用实现类:
| 实现类 | 底层数据结构 | 查找性能 | 插入/删除性能 | 特点 | 适用场景 |
|---|---|---|---|---|---|
LinkedList | 双向链表 | O ( n ) O(n) O(n) | O ( 1 ) O(1) O(1) | 可以作为队列或双端队列 | 一般队列操作,灵活性强 |
PriorityQueue | 堆 | O ( l o g n ) O(logn) O(logn) | O ( l o g n ) O(logn) O(logn) | 元素按优先级排序,非 FIFO | 任务调度,优先处理任务 |
ArrayDeque | 动态数组 | O ( n ) O(n) O(n) | O ( 1 ) O(1) O(1) | 高效的双端队列,性能优于 LinkedList | 双端队列,LIFO/FIFO 场景 |
2.5 Map 接口
Map 接口用于存储 键值对(key-value pairs)。每个键是唯一的,通过键可以快速找到对应的值。Map 是 Java 集合框架中非常重要的一部分,虽然它不直接继承 Collection 接口,但它是 Java 集合框架的重要组成部分。
Map 的核心特性:
- 键值对结构:每个键只能映射到一个值。
- 快速查找:通过键可以快速定位对应的值。
Map 接口的常用实现类:
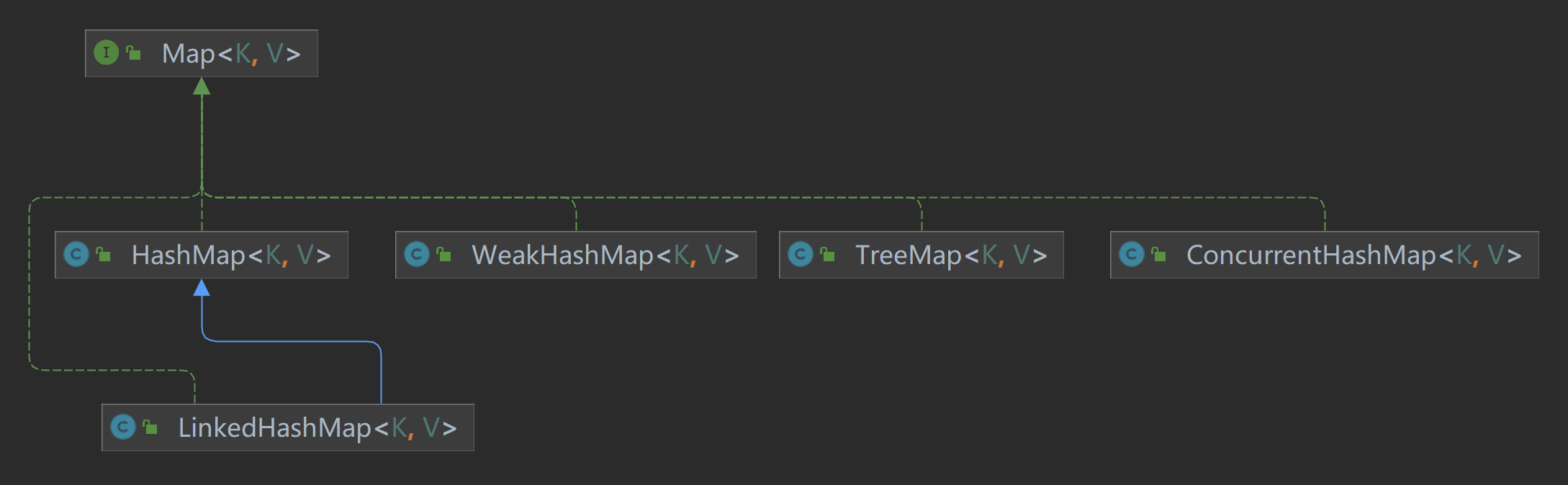
| 实现类 | 底层数据结构 | 查找性能 | 插入/删除性能 | 有序性 | 线程安全性 | 适用场景 |
|---|---|---|---|---|---|---|
HashMap | 哈希表 | O ( 1 ) O(1) O(1) | O ( 1 ) O(1) O(1) | 无序 | 否 | 需要快速查找键值对的场景 |
LinkedHashMap | 哈希表 + 链表 | O ( 1 ) O(1) O(1) | O ( 1 ) O(1) O(1) | 插入顺序 | 否 | 需要保持插入顺序的场景 |
TreeMap | 红黑树 | O ( l o g n ) O(logn) O(logn) | O ( l o g n ) O(logn) O(logn) | 键有序 | 否 | 需要对键进行排序的场景 |
WeakHashMap | 哈希表 + 弱引用 | O ( 1 ) O(1) O(1) | O ( 1 ) O(1) O(1) | 无序 | 否 | 自动回收无用键,适用于缓存实现 |
ConcurrentHashMap | 哈希表 | O ( 1 ) O(1) O(1) | O ( 1 ) O(1) O(1) | 无序 | 是 | 多线程环境下的键值对存储 |
3. List 接口与实现类详解
3.1 List 接口的特点与应用场景
List 接口是一个 有序 且 允许重复 的集合,它继承了 Collection 接口,并添加了按索引访问元素的能力。具体来说,List 适用于如下场景:
- 按顺序存储元素:保持插入顺序,即使有重复元素时,也能按照插入的顺序访问。
- 频繁的读取操作:在需要根据索引快速访问元素时,
List提供了快速访问的能力。 - 允许重复值:如果场景需要存储相同的元素,例如一份购物清单中可能会多次出现同一个商品,
List允许这种情况。
3.2 ArrayList:动态数组的实现
ArrayList 是 List 接口的一个典型实现,底层使用的是 动态数组。它的容量可以在需要时自动增加,因此不必预先确定大小。ArrayList 的优势在于它能快速地随机访问元素,但在中间插入或删除元素时性能较差,因为需要移动其他元素。
| 特点 | 说明 |
|---|---|
| 底层实现 | 动态数组 |
| 访问速度 | 随机访问 O ( 1 ) O(1) O(1),插入删除 O ( n ) O(n) O(n) |
| 线程安全性 | 非线程安全 |
| 默认初始容量 | 10 10 10 |
| 扩容机制 | 容量不足时自动扩展 1.5 1.5 1.5 倍 |
| 适用场景 | 数据 查询 频繁,插入删除相对较少的场景 |
3.3 LinkedList:基于链表的双向链表实现
LinkedList 是另一种 List 的实现,它使用的是 双向链表 结构。链表中的每个元素都包含一个指向前一个元素和下一个元素的引用。与 ArrayList 相比,LinkedList 的插入和删除操作非常高效,尤其是在中间位置插入或删除元素时,无需像 ArrayList 那样移动其他元素。
| 特点 | 说明 |
|---|---|
| 底层实现 | 双向链表 |
| 访问速度 | 随机访问 O ( n ) O(n) O(n),插入删除 O ( 1 ) O(1) O(1) |
| 线程安全性 | 非线程安全 |
| 适用场景 | 频繁 插入、删除 操作,队列或栈操作场景 |
3.4 Vector 和 Stack:线程安全的 List 实现
Vector 和 Stack 都是早期的 Java 集合类,虽然现在不如 ArrayList 和 LinkedList 常用,但它们依然有其特殊的用途。两者都是线程安全的集合类。
| 特点 | Vector | Stack |
|---|---|---|
| 底层实现 | 动态数组 | 基于 Vector 的动态数组 |
| 线程安全性 | 线程安全 | 线程安全 |
| 适用场景 | 多线程环境下的 ArrayList 替代品 | 后进先出的栈操作 |
3.5 List 常用操作和方法
List 提供了许多常用的方法,可以对集合进行增删改查等基本操作:
| 操作 | 方法 | 说明 |
|---|---|---|
| 添加 | add(E element) | 在末尾添加元素 |
| 删除 | remove(int index) | 删除指定索引的元素 |
| 修改 | set(int index, E element) | 替换指定位置的元素 |
| 查询 | get(int index) | 获取指定位置的元素 |
| 排序 | Collections.sort(List) | 对列表进行自然排序 |
3.6 ArrayList vs. LinkedList
ArrayList 和 LinkedList 都是 List 接口的常用实现,它们的性能差异主要体现在访问、插入和删除操作上。选择哪种实现类,取决于具体的使用场景。
性能对比:
| 操作 | ArrayList | LinkedList |
|---|---|---|
| 随机访问 | O ( 1 ) O(1) O(1) | O ( n ) O(n) O(n) |
| 插入删除 | O ( n ) O(n) O(n)(需要移动元素) | O ( 1 ) O(1) O(1)(在两端或中间位置插入时) |
| 内存消耗 | 较少(数组结构,紧凑存储) | 较多(需要额外的指针存储前后引用) |
| 扩容 | 需要重新分配更大的数组并复制元素 | 不需要 |
选择建议:
- 如果主要操作是 读取 数据,
ArrayList是更好的选择,因为它的随机访问性能更好。 - 如果需要频繁地 插入 或 删除 数据,尤其是在列表的中间位置,
LinkedList更为高效。 - 如果列表中的元素数量较大并且大部分操作是 增、删、改,
LinkedList的表现会优于ArrayList。
4. Set 接口与实现类详解
4.1 Set 接口的特点与应用场景
Set 是 Java 集合框架中的一个接口,它与 List 最大的不同在于:Set 不允许存储重复的元素,即在同一个 Set 中,一个元素只能出现一次。此外,Set 通常不保证元素的顺序(有例外,如 LinkedHashSet 和 TreeSet)。
| 特点 | 说明 |
|---|---|
| 无重复元素 | 每个元素只能出现一次 |
| 顺序不固定 | 一般不保证存储顺序(LinkedHashSet 例外) |
| 适用场景 | 去重、集合运算、独特元素的存储 |
4.2 HashSet:基于哈希表的实现
HashSet 是 Set 接口的实现之一,底层使用的是哈希表(HashMap)存储元素。由于哈希表的特性,HashSet 提供了极高的查找、插入和删除效率,但不保证元素的顺序。
| 特点 | 说明 |
|---|---|
| 无序存储 | HashSet 不保证元素的存储顺序,顺序可能与插入顺序不同 |
| 高效操作 | 基于哈希表实现,插入、删除和查找操作的时间复杂度通常为 O ( 1 ) O(1) O(1) |
允许 null 元素 | HashSet 允许存储一个 null 元素 |
| 适用场景 | 当不关心存储顺序,只需要快速访问和去重时,HashSet 是最佳选择 |
4.3 LinkedHashSet:有序哈希表实现
LinkedHashSet 继承自 HashSet,它在保持 HashSet 高效性的同时,维护了元素的插入顺序。底层使用哈希表和双向链表来存储元素。
| 特点 | 说明 |
|---|---|
| 有序存储 | LinkedHashSet 保证元素的存储顺序与插入顺序一致 |
| 性能稍差于 HashSet | 由于维护了链表结构,性能略低于 HashSet,但仍然高效,时间复杂度为
O
(
1
)
O(1)
O(1) |
允许 null 元素 | 允许存储一个 null 元素 |
| 适用场景 | 适合需要高效操作且保持元素插入顺序的场景,比如缓存系统中保留访问顺序 |
4.4 TreeSet:基于红黑树的实现,支持排序
TreeSet 是 Set 接口的另一个实现类,基于红黑树数据结构。与 HashSet 不同的是,TreeSet 保证元素的排序,即可以按自然顺序(或自定义顺序)排序存储元素。
| 特点 | 说明 |
|---|---|
| 排序存储 | 默认按元素的自然顺序排序(如数字从小到大),也可通过自定义比较器排序 |
| 性能较低 | 基于红黑树实现,插入、删除和查找的时间复杂度为 O ( l o g n ) O(logn) O(logn) |
不允许 null 元素 | TreeSet 不允许存储 null 元素 |
| 适用场景 | 适合需要按顺序存储并频繁排序操作的场景,如处理有序数据或范围查询 |
4.5 EnumSet:专门处理枚举类型的 Set 实现
EnumSet 是专为枚举类型设计的 Set 实现类,效率非常高,且只能存储枚举类型的元素。它是所有 Set 实现中最轻量级的实现,内部通常通过位向量来存储元素。
| 特点 | 说明 |
|---|---|
| 只能用于枚举类型 | EnumSet 只能存储枚举类型的元素,不能存储其他类型的数据 |
| 所有元素必须属于同一枚举类 | EnumSet 中的所有元素必须来自同一个枚举类,不能跨枚举类混合使用 |
| 高效 | EnumSet 内部实现非常高效,通常比其他 Set 实现类更高效 |
| 适用场景 | 当需要操作枚举类型集合时,EnumSet 是最佳选择 |
4.6 Set 常用操作和方法
Set 提供了常用的集合操作,例如:
| 操作 | 方法 | 说明 |
|---|---|---|
| 添加 | add(E e) | 添加元素到集合中 |
| 删除 | remove(Object o) | 删除指定元素 |
| 交集 | retainAll(Collection<?> c) | 保留集合的交集部分 |
| 并集 | addAll(Collection<? extends E> c) | 合并多个集合 |
| 差集 | removeAll(Collection<?> c) | 删除集合中存在于另一集合的元素 |
4.7 HashSet vs. TreeSet vs. LinkedHashSet
不同的 Set 实现类在性能和特性上有较大的差异,下面的表格总结了它们的主要区别。
| 特性 | HashSet | LinkedHashSet | TreeSet |
|---|---|---|---|
| 底层结构 | 哈希表 | 哈希表 + 链表 | 红黑树 |
| 元素顺序 | 无序 | 按插入顺序 | 排序(自然顺序或自定义顺序) |
| 操作性能 | O ( 1 ) O(1) O(1) |
O
(
1
)
O(1)
O(1)(比 HashSet 略低) | O ( l o g n ) O(logn) O(logn) |
| 是否允许 null | 允许 | 允许 | 不允许 |
| 适用场景 | 需要高效去重,不关心顺序的场景 | 需要按插入顺序遍历元素的场景 | 需要排序的场景 |
选择建议:
- 如果不关心元素顺序且性能是首要考虑,
HashSet是最优选择。 - 如果需要保持插入顺序,选择
LinkedHashSet。 - 如果需要有序存储且常常需要进行排序操作,
TreeSet是合适的选择,但其性能不如前两者高效。
5. Queue 和 Deque 接口与实现类详解
Queue 和 Deque 是 Java 集合框架中的重要接口,专门用于处理队列和双端队列结构。它们在各种应用场景中广泛使用,特别是 任务调度、缓冲区管理、并发控制 等。本节将深入探讨它们的核心特点及常用实现类,并结合表格分析它们的性能和使用场景。
5.1 Queue 接口的特点与应用场景
Queue 是继承自 Collection 的接口,表示 先进先出(FIFO) 的队列数据结构。元素按插入顺序存储,优先处理先插入的元素。
| 特点 | 说明 |
|---|---|
| 顺序性 | 按插入顺序处理元素(FIFO)。 |
| 线程安全 | 标准队列不提供线程安全,需使用并发队列如 BlockingQueue |
| 操作效率 | 队头插入、删除操作高效。 |
| 应用场景 | 任务调度、缓冲区、生产者-消费者模式。 |
常见应用场景:
- 任务调度:使用队列存储任务,按照先来先处理的原则逐个执行。
- 缓冲区管理:在网络或文件读写中,队列用于缓存数据,确保顺序消费。
5.2 PriorityQueue:基于堆实现的优先队列
PriorityQueue 是 Java 提供的一个基于堆的队列实现,能够根据元素的优先级来决定元素的处理顺序,而不是简单的 FIFO 顺序。
| 特点 | 说明 |
|---|---|
| 堆结构 | 内部使用 最小堆 实现,保证每次出队的是优先级最高的元素(默认按自然顺序) |
| 非线程安全 | PriorityQueue 不适用于多线程并发环境 |
| 不保证遍历顺序 | 遍历时元素顺序不保证是优先级顺序 |
| 排序方式 | 按优先级处理(最小堆) |
| 性能 | 插入和删除的时间复杂度均为 O ( l o g n ) O(logn) O(logn) |
| null 支持 | 不允许存储 null 元素 |
| 应用场景 | 任务调度系统、事件驱动系统 |
5.3 LinkedList 作为 Queue 的实现
LinkedList 是 Java 中双向链表的实现类,可以作为 List 也可以作为 Queue 使用。它在作为队列时,提供了无界队列的功能。
| 特点 | 说明 |
|---|---|
| 数据结构 | 基于双向链表,插入和删除效率高 |
| 无界性 | 队列大小没有限制 |
| null 支持 | 可以存储 null |
| 应用场景 | 简单任务队列、无固定容量限制的缓存 |
5.4 ArrayDeque:基于数组的双端队列实现
ArrayDeque 是 Deque 接口的一个实现,使用动态数组作为底层存储结构,提供了双端操作的高效实现。与 LinkedList 相比,ArrayDeque 的操作更高效。
| 特点 | 说明 |
|---|---|
| 双端操作 | 支持在队头和队尾进行插入和删除操作,时间复杂度为 O ( 1 ) O(1) O(1) |
| 性能 | 由于基于数组,整体性能优于 LinkedList |
| 容量管理 | 动态扩展数组,无需手动调整容量 |
| null 支持 | 不允许存储 null 元素 |
| 应用场景 | 双端队列操作,缓存机制,堆栈替代品 |
5.5 Deque 接口详解
Deque(Double Ended Queue)是一种双端队列,允许在队列的两端插入和移除元素,既可以作为 FIFO 队列,也可以作为 LIFO 堆栈使用。因此,Deque 是队列和堆栈的灵活结合。
| 特点 | 说明 |
|---|---|
| 双端操作 | 支持在两端插入和删除,灵活性高 |
| FIFO 和 LIFO | 可以同时支持队列和堆栈功能 |
| 应用场景 | 需要灵活队列操作,如任务调度、双向缓存、回溯算法 |
5.6 BlockingQueue 和其实现类
BlockingQueue 是一个线程安全的队列,它支持在队列为空时阻塞获取操作,以及在队列已满时阻塞插入操作。这使得 BlockingQueue 在并发编程中非常适用,特别是在生产者-消费者模型中。
常见的 BlockingQueue 实现类:
| 实现类 | 特点 | 场景 |
|---|---|---|
| ArrayBlockingQueue | 有界阻塞队列,基于数组实现,容量固定 | 生产者-消费者模型,控制任务数目 |
| LinkedBlockingQueue | 基于链表实现的阻塞队列,可以是无界的或有界的 | 用于高吞吐量场景,允许队列大小动态变化 |
| PriorityBlockingQueue | 基于优先级的阻塞队列,插入元素按优先级排序 | 用于处理优先级任务调度,按优先级执行任务 |
5.7 Queue 和 Deque 常用操作与方法
| 操作类型 | 操作名称 | 描述 | 返回值 | 空队列时返回 |
|---|---|---|---|---|
| FIFO | offer(E e) | 将元素插入队尾 | 成功返回 true,失败返回 false | - |
| FIFO | poll() | 从队头移除并返回元素 | 队头元素 | null |
| FIFO | peek() | 查看队头元素但不移除 | 队头元素 | null |
| LIFO | push(E e) | 将元素推入栈顶(Deque 的头部) | - | - |
| LIFO | pop() | 从栈顶弹出元素,移除并返回栈顶元素 | 栈顶元素 | - |
6. Map 接口与实现类详解
Map 接口在 Java 集合框架中用于存储键值对(key-value pairs),它的特点是每个键必须唯一,且通过键可以快速查找对应的值。常见的 Map 实现类包括 HashMap、LinkedHashMap、TreeMap 等。
6.1 Map 接口的特点与应用场景
| 特点 | 说明 |
|---|---|
| 键值对存储 | 每个键唯一,键和值组成键值对存储。 |
| 查找效率高 | 查找操作通常是 O ( 1 ) O(1) O(1) 或 O ( l o g n ) O(logn) O(logn)。 |
| null 键和值支持 | HashMap 支持 null 键和 null 值,但 TreeMap 不允许。 |
| 顺序性 | 部分实现如 LinkedHashMap 可以维护插入顺序。 |
常见应用场景:
- 数据字典:将标识符映射到数据对象,如用户 ID 和用户数据的关联。
- 缓存:通过键快速查找缓存内容。
- 计数器:统计事件频率,如词频统计,键为词,值为词出现的次数。
6.2 HashMap:基于哈希表的实现
HashMap 是最常用的 Map 实现类,基于 哈希表(Hash Table) 来存储键值对。它允许一个 null 键和多个 null 值,操作的时间复杂度通常为
O
(
1
)
O(1)
O(1)。
| 特点 | 说明 |
|---|---|
| 哈希结构 | 通过哈希函数快速查找键值对,时间复杂度 O ( 1 ) O(1) O(1) |
| 无序 | HashMap 不保证键值对的插入顺序 |
| 允许 null 键和值 | 可以存储一个 null 键和多个 null 值 |
| 非线程安全 | 在多线程环境下需用 ConcurrentHashMap 替代 |
| 自动扩容 | 当哈希表过满时,自动扩展容量 |
| 默认初始容量 | 16 16 16 |
| 扩容机制 | 当容量超过加载因子(load factor)默认值 0.75 0.75 0.75 时,容量自动扩展 2 2 2 倍 |
适用场景:
- 缓存系统:用于存储和快速查找缓存数据。
- 索引结构:如用户 ID 和用户数据的映射,快速定位数据。
6.3 LinkedHashMap:有序哈希表实现
LinkedHashMap 是 HashMap 的子类,除了哈希表结构外,它通过双向链表维护键值对的插入顺序或访问顺序。
| 特点 | 说明 |
|---|---|
| 插入/访问顺序有序 | 默认按照插入顺序,支持按访问顺序排序 |
| 哈希表结构 | 与 HashMap 类似,通过哈希函数实现快速查找 |
| 内存开销较高 | 由于维护双向链表,内存消耗比 HashMap 稍高 |
适用场景:
- LRU 缓存机制:可通过访问顺序的
LinkedHashMap实现最近最少使用(Least Recently Used,LRU)缓存。 - 顺序敏感场景:需要遍历时保持插入顺序的场景。
6.4 TreeMap:基于红黑树的实现,支持排序
TreeMap 是 Map 接口的另一种实现,基于红黑树(Red-Black Tree),能够根据键的自然顺序(或指定的比较器顺序)进行排序。
| 特点 | 说明 |
|---|---|
| 基于红黑树 | 使用平衡二叉搜索树实现,时间复杂度为 O ( l o g n ) O(logn) O(logn) |
| 有序 | 按键的自然顺序或指定顺序排序 |
| 不支持 null 键 | 不允许 null 键,但支持 null 值 |
适用场景:
- 需要排序的场景:如按字母顺序排序的电话簿,或按日期排序的事件日志。
- 范围查询:快速查找某个范围内的键值对,如获取某个范围内的时间戳数据。
6.5 WeakHashMap 和 IdentityHashMap:特殊场景下的 Map 实现
WeakHashMap:存储的键是 “弱引用”,当键不再被引用时,GC(垃圾回收器)可以自动回收这些键及其对应的值。
适用于缓存场景,当键对象不再被使用时,自动移除对应的缓存条目。
IdentityHashMap:使用引用相等性(==)来比较键,而不是 equals() 方法。即,只有当两个键对象在内存中的地址相同时,才被视为相同。
适用于需要区分不同对象实例的场景,即使它们逻辑上是相等的。
6.6 ConcurrentHashMap:线程安全的 Map 实现
ConcurrentHashMap 是 HashMap 的线程安全版本,它通过分段锁(或无锁操作)来支持并发访问,同时提供高效的性能。
| 特点 | 说明 |
|---|---|
| 线程安全 | 多线程并发环境下使用,避免数据不一致问题 |
| 分段锁机制 | 锁分段,支持更高的并发访问 |
| 不允许 null 键值 | null 键和值不允许出现 |
适用场景:高并发访问的环境:如共享资源的缓存系统,或者多线程更新计数器。
6.7 Map 常用操作与方法
| 操作类型 | 常用方法 | 说明 |
|---|---|---|
| 添加键值对 | put(K key, V value) | 插入一个键值对,若键已存在,则覆盖旧值 |
| 获取值 | get(Object key) | 根据键获取对应的值 |
| 删除键值对 | remove(Object key) | 删除指定键的键值对 |
| 遍历键值对 | entrySet()、keySet()、values() | 分别获取所有键值对、键集合、值集合进行遍历 |
| 排序 | TreeMap 或通过 Comparator 实现自定义顺序。 | TreeMap 天然支持排序,其他 Map 可以通过 Comparator自定义排序 |
| 批量操作 | putAll(Map<? extends K,? extends V> m) | 将另一个 Map 中的所有键值对添加到当前 Map 中 |
6.8 HashMap vs. TreeMap vs. LinkedHashMap
| 特性 | HashMap | TreeMap | LinkedHashMap |
|---|---|---|---|
| 实现结构 | 哈希表 | 红黑树 | 哈希表 + 双向链表 |
| 时间复杂度 | O ( 1 ) O(1) O(1) | O ( l o g n ) O(logn) O(logn) | O ( 1 ) O(1) O(1) |
| 是否有序 | 否 | 是(按键的自然顺序或自定义顺序) | 是(按插入顺序或访问顺序) |
| 是否支持 null 键/值 | 支持 | 不支持 null 键,支持 null 值 | 支持 |
| 线程安全性 | 非线程安全 | 非线程安全 | 非线程安全 |
| 适用场景 | 快速查找,无需排序的场景 | 需要按键排序的场景 | 需要维护插入顺序的场景 |
7. Collections 工具类
Collections 是一个 Java 工具类,位于 java.util 包中,它提供了许多静态方法来操作或返回集合。它的作用在于简化集合的操作,如排序、搜索、线程安全处理等,让开发者能够方便地处理各种集合操作。
7.1 Collections 类的作用与概述
Collections 类主要用于对集合(如 List、Set、Map)进行批量操作,例如排序、查找、线程安全包装等。它还可以创建特殊集合,例如空集合和不可变集合。Collections 提供的工具方法能极大简化集合操作的实现,提高代码的可读性和维护性。
| 功能 | 说明 |
|---|---|
| 排序 | 对 List 进行升序、降序排序。 |
| 查找 | 查找特定元素在集合中的位置或最大最小元素。 |
| 填充 | 将集合中的所有元素替换为指定的单一值。 |
| 逆序 | 反转 List 中元素的顺序。 |
| 线程安全 | 将非线程安全的集合包装为线程安全的集合。 |
| 不可变集合 | 创建不可修改的集合,避免集合被修改。 |
7.2 常见方法:排序、查找、填充、逆序、同步化
Collections 类提供了多种常用方法,下面详细介绍一些关键操作。
排序 (sort)
Collections.sort() 是最常用的方法之一,用于对 List 进行升序或降序排序。它支持自然排序(基于元素的 compareTo 方法)或自定义排序(通过 Comparator)。
List<Integer> numbers = Arrays.asList(5, 2, 9, 1);
Collections.sort(numbers); // 升序排序
| 方法 | 说明 |
|---|---|
Collections.sort(List<T>) | 对 List 元素进行自然排序 |
Collections.sort(List<T>, Comparator<T>) | 使用自定义 Comparator 进行排序 |
查找 (search)
Collections 提供方法用于查找元素的位置或最大、最小值。binarySearch 要求集合必须是排序的。
int index = Collections.binarySearch(numbers, 5); // 二分查找
int max = Collections.max(numbers); // 查找最大值
| 方法 | 说明 |
|---|---|
Collections.binarySearch(List<T>, T key) | 使用二分查找在排序列表中查找指定元素的位置 |
Collections.max(Collection<T>) | 查找集合中的最大元素 |
Collections.min(Collection<T>) | 查找集合中的最小元素 |
填充 (fill)
fill() 方法用于将 List 中的所有元素替换为相同的值。
Collections.fill(numbers, 0); // 将所有元素替换为 0
| 方法 | 说明 |
|---|---|
Collections.fill(List<T>, T obj) | 用指定的对象替换 List 中的所有元素 |
逆序 (reverse)
reverse() 用于将 List 中元素的顺序反转。
Collections.reverse(numbers); // 反转 List 中的元素顺序
| 方法 | 说明 |
|---|---|
Collections.reverse(List<T>) | 反转 List 中的元素顺序 |
同步化 (synchronizedXxx)
Collections.synchronizedXxx() 用于将非线程安全的集合包装为线程安全的集合。
List<String> syncList = Collections.synchronizedList(new ArrayList<>());
| 方法 | 说明 |
|---|---|
Collections.synchronizedList(List<T>) | 将 List 包装为线程安全的 |
Collections.synchronizedSet(Set<T>) | 将 Set 包装为线程安全的 |
Collections.synchronizedMap(Map<K,V>) | 将 Map 包装为线程安全的 |
7.3 Collections.synchronizedXxx:线程安全的集合
在多线程环境中,集合如 ArrayList、HashMap 并不是线程安全的。在多个线程同时访问集合时,可能会产生竞争条件。为了防止这种情况,Collections 提供了一系列 synchronizedXxx() 方法来创建线程安全的集合。
| 方法 | 说明 |
|---|---|
synchronizedList(List<T> list) | 返回一个线程安全的 List |
synchronizedSet(Set<T> set) | 返回一个线程安全的 Set |
synchronizedMap(Map<K,V> map) | 返回一个线程安全的 Map |
synchronizedCollection(Collection<T> c) | 返回一个线程安全的通用 Collection |
应用场景:
- 在多线程环境中,需要多个线程同时访问共享的集合。
- 避免数据竞争和不一致性问题。
示例:
List<String> syncList = Collections.synchronizedList(new ArrayList<>());
synchronized (syncList) {
// 在同步块中进行遍历,避免并发修改异常
for (String s : syncList) {
System.out.println(s);
}
}
7.4 Collections.unmodifiableXxx:不可变集合的创建
不可变集合是指一旦创建就不能修改的集合,这在某些场景下非常有用,例如在需要共享给多个模块或方法,但不希望被修改时。Collections.unmodifiableXxx() 方法提供了创建不可变集合的能力。
| 方法 | 说明 |
|---|---|
unmodifiableList(List<T> list) | 返回一个不可修改的 List |
unmodifiableSet(Set<T> set) | 返回一个不可修改的 Set |
unmodifiableMap(Map<K,V> map) | 返回一个不可修改的 Map |
应用场景:
- 创建只读配置集合,防止配置数据被意外修改。
- 创建只读视图,避免集合被错误操作修改。
示例:
List<String> list = new ArrayList<>(Arrays.asList("a", "b", "c"));
List<String> unmodifiableList = Collections.unmodifiableList(list);
unmodifiableList.add("d"); // 抛出 UnsupportedOperationException
7.5 Collections.emptyXxx:空集合的创建
Collections 提供了一系列方法用于创建空集合。这些空集合通常用于返回时避免 null,并且它们是不可修改的,防止操作引发错误。
| 方法 | 说明 |
|---|---|
emptyList() | 返回一个空的不可修改 List |
emptySet() | 返回一个空的不可修改 Set |
emptyMap() | 返回一个空的不可修改 Map |
应用场景:
- 当需要返回空集合时,使用
emptyXxx()代替null,避免引发NullPointerException。 - 不需要占用额外的内存。
示例:
List<String> emptyList = Collections.emptyList();
Set<String> emptySet = Collections.emptySet();
Map<String, String> emptyMap = Collections.emptyMap();
7.6 自定义比较器:Comparator 接口与 Lambda 表达式的结合
Comparator 是一个用于比较两个对象的接口,通常用于自定义排序规则。Java 8 引入了 Lambda 表达式,使得自定义比较器更加简洁和灵活。
Comparator 接口
Comparator 接口通过 compare(T o1, T o2) 方法来比较两个对象,并返回一个整数值,表示它们的相对顺序。
Lambda 表达式与 Comparator 结合
在 Java 8 之前,必须显式地创建一个匿名内部类来实现 Comparator 接口;而在 Java 8 之后,使用 Lambda 表达式可以大幅简化代码。
示例:对字符串按照长度排序
List<String> strings = Arrays.asList("apple", "banana", "pear");
// 使用 Lambda 表达式创建 Comparator
Collections.sort(strings, (s1, s2) -> s1.length() - s2.length());
| 功能 | 示例 |
|---|---|
| 自然排序 | Collections.sort(list) |
| 自定义排序 | Collections.sort(list, Comparator) |
| Lambda 表达式 | (s1, s2) -> s1.length() - s2.length() |
应用场景:需要按照自定义规则对集合进行排序时,例如按照字符串长度、某个属性值等。
8. Java 8 Stream API 与集合框架的结合
Java 8 引入的 Stream API 大大简化了对集合的操作,使得开发者可以以声明式的方式处理数据,而不必编写繁琐的循环代码。Stream API 提供了一种高效且具有高度可读性的方式来操作集合数据,可以完成过滤、转换、排序、聚合等操作,特别是在大规模数据处理和并行处理上表现出色。
8.1 Stream API 简介
Stream 是 Java 8 提供的新特性,允许我们以函数式编程风格操作数据集合。Stream API 可以用来处理 List、Set、Map 等集合中的数据,通过简洁的链式调用,开发者能够使用过滤、映射、归约等操作来处理数据。
Stream 的特点:
- 无存储:Stream 不是数据结构,不存储数据,而是从数据源(集合、数组等)中获取数据。
- 不可修改:Stream 的操作不会修改原集合,它是对数据的映射与转换。
- 延迟执行:Stream 的操作是延迟执行的,只有在终端操作执行时才真正处理数据。
流式处理 可以简化代码,提升可读性,特别适合数据密集型应用程序。
8.2 Stream 与集合的关系
Stream API 与传统的 Java 集合密切相关。虽然集合本身存储数据,但 Stream 更像是一种对集合数据进行操作的视图,它通过各种中间操作与终端操作来处理数据流,生成新的结果。
关系:
- 集合是数据的容器,而 Stream 是对集合中数据的操作。
- 集合中的数据可以通过
stream()方法转为 Stream,从而使用 Stream API 进行操作。 - Stream 提供了一种函数式编程方式,简化了对集合数据的处理。
List<String> list = Arrays.asList("apple", "banana", "orange");
Stream<String> stream = list.stream(); // 将集合转换为 Stream
| 集合方法 | Stream 对应方法 |
|---|---|
list.forEach() | stream.forEach() |
list.removeIf() | stream.filter() |
list.sort() | stream.sorted() |
list.addAll() | stream.collect() |
8.3 Stream 的操作类型:中间操作和终端操作
Stream API 操作分为 中间操作(Intermediate Operations)和 终端操作(Terminal Operations)。
中间操作
中间操作会返回一个新的 Stream 对象,它们是惰性执行的,也就是说中间操作不会立即执行,只有在执行终端操作时,中间操作才会真正处理数据。
常见的中间操作:
| 操作名称 | 描述 | 功能说明 |
|---|---|---|
filter(Predicate) | 根据给定条件过滤数据 | 返回满足条件的元素集合 |
map(Function) | 将元素转换为其他形式 | 将元素映射为新形式或类型 |
sorted() | 对元素进行排序 | 按照默认或自定义顺序排序元素 |
limit(long n) | 限制返回的元素个数 | 返回前 n 个元素 |
distinct() | 去除集合中的重复元素 | 返回去重后的元素集合 |
stream.filter(s -> s.length() > 5) // 过滤长度大于 5 的元素
.map(String::toUpperCase) // 转换为大写
.sorted(); // 排序
终端操作
终端操作是 Stream 的最后一步操作,它触发所有中间操作并生成结果,执行终端操作后,Stream 不再可用。
常见的终端操作:
| 操作名称 | 描述 | 功能说明 |
|---|---|---|
forEach(Consumer) | 对每个元素执行给定的操作 | 对每个元素进行处理(例如打印、修改等) |
collect(Collector) | 将流中的元素收集到指定的集合或其他容器中 | 将流转换为集合、列表、映射等 |
reduce(BinaryOperator) | 通过合并操作将流中的元素聚合为单个结果 | 根据自定义逻辑聚合元素,返回单个值 |
count() | 返回流中元素的个数 | 计算并返回流中元素的总数量 |
long count = stream.filter(s -> s.length() > 5).count(); // 统计长度大于 5 的元素个数
| 操作类型 | 操作方式 | 是否立即执行 |
|---|---|---|
| 中间操作 | 生成新的 Stream,惰性执行 | 否 |
| 终端操作 | 生成最终结果,触发流处理 | 是 |
8.4 常见 Stream 操作
Stream API 提供了多种常见的操作,下面列出了一些典型操作。
过滤(Filter)
filter() 方法根据条件过滤掉不符合条件的元素,返回一个包含满足条件元素的新 Stream。
List<String> filtered = list.stream()
.filter(s -> s.length() > 5) // 过滤长度大于5的字符串
.collect(Collectors.toList());
映射(Map)
map() 方法用于将 Stream 中的每个元素按照某个函数进行转换,生成一个新的 Stream。
List<Integer> lengths = list.stream()
.map(String::length) // 将每个字符串转换为其长度
.collect(Collectors.toList());
归约(Reduce)
reduce() 用于将 Stream 中的元素组合成一个单一的结果,比如累加、求和等。
int totalLength = list.stream()
.map(String::length)
.reduce(0, Integer::sum); // 计算所有字符串长度的总和
收集(Collect)
collect() 是将 Stream 结果收集到一个容器中(如 List、Set、Map)。常用 Collectors 工具类进行收集操作。
List<String> upperCaseList = list.stream()
.map(String::toUpperCase)
.collect(Collectors.toList()); // 收集到 List
| 操作 | 方法 | 作用 |
|---|---|---|
| 过滤 | filter(Predicate) | 根据条件过滤元素 |
| 映射 | map(Function) | 将每个元素映射为新形式 |
| 归约 | reduce(BinaryOperator) | 将流中的元素合并为单个结果 |
| 收集 | collect(Collector) | 将流中的元素收集到一个集合 |
8.5 并行 Stream
Stream API 支持并行流(Parallel Stream),它可以利用多核处理器的优势并行处理数据,以提升性能。并行流通过 parallelStream() 方法创建,内部通过 ForkJoinPool 来分治处理数据,适合在大数据量或计算密集型任务中使用。
并行流的创建:
- 使用
parallelStream():直接从集合创建并行流。 - 将普通流转换为并行流:
stream().parallel()。
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);
int sum = numbers.parallelStream()
.mapToInt(i -> i * 2)
.sum(); // 并行计算和
| 流类型 | 说明 | 适用场景 |
|---|---|---|
| 顺序流 | 默认流操作是顺序执行的,按次序处理数据 | 数据量较小,或不需要并行处理的任务 |
| 并行流 | 数据分片后并行处理,充分利用多核 CPU | 大数据量,计算密集型任务 |
注意事项:
- 并行流可能在某些场景下引入额外的性能开销,比如过度分解任务或在较小数据集上使用。
- 对于顺序相关的数据操作(如操作有序集合),并行流可能会导致顺序不一致。
8.6 Stream API 在集合框架中的应用示例
通过 Stream API,常见的集合操作变得更加简洁。以下是一些 Stream API 在实际应用中的示例。
对 List 进行过滤、映射和排序
List<String> fruits = Arrays.asList("apple", "banana", "pear", "orange");
List<String> result = fruits.stream()
.filter(s -> s.length() > 5) // 过滤长度大于 5 的元素
.map(String::toUpperCase) // 转换为大写
.sorted() // 按字母顺序排序
.collect(Collectors.toList()); // 收集到 List
使用 Map 和 Collectors.groupingBy 进行数据分组
List<String> words = Arrays.asList("apple", "banana", "pear", "apple", "pear");
Map<String, Long> wordCount = words.stream()
.collect(Collectors.groupingBy(word -> word, Collectors.counting())); // 按单词分组并计数
9. 泛型与 Java 集合框架
泛型是 Java 语言中的一个强大机制,它使得代码具有更好的可读性、类型安全性和可重用性。通过使用泛型,开发者可以在编写集合时指定集合中允许存储的对象类型,从而在编译时捕获类型错误,避免类型转换时出现的运行时错误。
9.1 什么是泛型
泛型(Generics) 是 Java 5 引入的一种机制,它允许在类、接口和方法中使用类型参数,从而使代码能够处理各种类型的数据,而无需显式地指定具体的类型。简单来说,泛型让代码能够在保持类型安全的同时具有更高的灵活性和重用性。
示例:
在不使用泛型时,集合通常存储 Object 类型的数据,导致取出数据时需要进行显式的类型转换,并且容易出现 ClassCastException 错误。
List list = new ArrayList(); // 非泛型集合
list.add("Hello");
String s = (String) list.get(0); // 强制类型转换
使用泛型后,可以指定集合中存储的类型,编译器会进行类型检查,避免类型转换问题:
List<String> list = new ArrayList<>(); // 使用泛型
list.add("Hello");
String s = list.get(0); // 不需要类型转换
9.2 为什么集合需要泛型
在 Java 集合框架中,泛型的主要作用是提升类型安全性和代码可读性。如果没有泛型,集合会接受任何类型的对象(因为它们存储的是 Object 类型),这意味着在运行时可能会遇到类型转换错误。而泛型允许在编译时就确定集合存储的类型,从而避免了此类错误。
泛型带来的优势:
- 类型安全:泛型可以确保集合中的元素类型一致,防止类型转换异常。
- 代码可读性提升:开发者不需要频繁地进行类型转换,代码变得更加简洁。
- 重用性:泛型可以让类、接口、方法处理多种数据类型,而不必为每个类型编写新的实现。
例如,使用泛型的 List 可以限制只存储某种特定类型的数据:
List<Integer> intList = new ArrayList<>(); // 只能存储 Integer 类型
intList.add(1); // 正确
// intList.add("String"); // 编译时错误,不允许添加 String 类型
9.3 集合框架中的泛型应用
在实际开发中,泛型在 Java 集合框架中得到了广泛应用,提升了代码的安全性和可维护性。以下是泛型的常见应用场景。
Java 的集合类,如 List、Set、Map 等都使用了泛型,使得这些类在存储对象时可以保证类型安全。
List<String> list = new ArrayList<>(); // 限定 List 中只能存储 String 类型
Map<Integer, String> map = new HashMap<>(); // Map 中键为 Integer,值为 String
10. 集合的性能与优化
在 Java 开发中,选择合适的集合类型以及对集合进行优化是提升性能的关键。不同的集合有各自的特点和适用场景,合理选择和优化集合操作可以减少资源消耗,提升程序的效率。
10.1 各种集合的性能对比
不同的集合实现类在性能上各有差异,主要体现在增删改查的效率上。常见集合类的性能可以通过时间复杂度来衡量:
| 集合类 | 插入(add) | 删除(remove) | 查找(get) | 遍历 |
|---|---|---|---|---|
| ArrayList | O ( 1 ) O(1) O(1) (尾部) | O ( n ) O(n) O(n)(非尾部) | O ( 1 ) O(1) O(1) | O ( n ) O(n) O(n) |
| LinkedList | O ( 1 ) O(1) O(1)(头/尾) | O ( 1 ) O(1) O(1)(头/尾) | O ( n ) O(n) O(n) | O ( n ) O(n) O(n) |
| HashSet | O ( 1 ) O(1) O(1) | O ( 1 ) O(1) O(1) | O ( 1 ) O(1) O(1) | O ( n ) O(n) O(n) |
| LinkedHashSet | O ( 1 ) O(1) O(1) | O ( 1 ) O(1) O(1) | O ( 1 ) O(1) O(1) | O ( n ) O(n) O(n) |
| TreeSet | O ( l o g n ) O(logn) O(logn) | O ( l o g n ) O(logn) O(logn) | O ( l o g n ) O(logn) O(logn) | O ( n ) O(n) O(n) |
| HashMap | O ( 1 ) O(1) O(1) | O ( 1 ) O(1) O(1) | O ( 1 ) O(1) O(1) | O ( n ) O(n) O(n) |
| LinkedHashMap | O ( 1 ) O(1) O(1) | O ( 1 ) O(1) O(1) | O ( 1 ) O(1) O(1) | O ( n ) O(n) O(n) |
| TreeMap | O ( l o g n ) O(logn) O(logn) | O ( l o g n ) O(logn) O(logn) | O ( l o g n ) O(logn) O(logn) | O ( n ) O(n) O(n) |
性能要点:
- ArrayList:随机访问性能好,但插入和删除非尾部元素时性能较差。
- LinkedList:插入和删除操作高效,适合频繁插入/删除操作的场景,但随机访问性能差。
- HashSet 和 HashMap:基于哈希表,查找和插入性能高效,但元素无序。
- TreeSet 和 TreeMap:基于红黑树,支持排序操作,但插入和查找的效率略低于哈希表。
10.2 选择合适的集合:时间复杂度与空间复杂度的权衡
选择合适的集合要考虑两方面因素:
- 时间复杂度:集合在增删改查操作上的效率。
- 空间复杂度:集合占用的内存空间。
常见场景选择
- 快速查找:选择
HashSet或HashMap,它们提供 O ( 1 ) O(1) O(1) 的查找时间复杂度。 - 需要有序性:如果需要保持元素插入顺序,选择
LinkedHashSet或LinkedHashMap。如果需要排序,使用TreeSet或TreeMap,它们提供 O ( l o g n ) O(logn) O(logn) 的查找、插入和删除操作。 - 频繁插入删除:如果插入和删除操作比查找操作频繁,可以选择
LinkedList,其插入删除操作是 O ( 1 ) O(1) O(1)。 - 空间优化:
ArrayList在处理小数据量时效率较高,而HashMap和TreeMap会有更大的空间开销,因为它们使用哈希表或树结构来存储数据。
内存占用差异
ArrayList在初始容量未满时占用较少内存,但在扩展容量时有额外的内存和性能开销。HashSet和HashMap使用哈希表存储,会有更多的内存消耗。TreeSet和TreeMap使用树结构,空间复杂度较高,特别是在数据量较大时。
10.3 集合大小的初始设置与调整
集合的容量在大数据量场景中对性能有重要影响。对于集合如 ArrayList、HashMap 等,合理地设置初始大小可以避免动态扩容带来的性能开销。
ArrayList 容量调整
ArrayList 在存储空间不足时会自动扩容,但这需要进行数组复制,性能较低。因此,在预计要存储大量元素时,应该设置一个合理的初始容量:
List<Integer> list = new ArrayList<>(1000); // 设置初始容量为 1000
HashMap 的容量与负载因子
HashMap 在容量达到一定百分比(即负载因子,默认 0.75)时会自动扩容,扩容过程会重新计算哈希值并将元素重新分配,耗费资源。在初始化时设置适当的容量可以减少扩容次数:
Map<String, Integer> map = new HashMap<>(1000); // 预估放入 1000 个元素
优化建议:如果知道要存储的元素个数,提前设置集合的初始容量可以有效减少性能开销。
10.4 使用 Iterator 和增强 for 循环遍历集合的性能差异
在 Java 中,遍历集合的方式主要有两种:使用 Iterator 或增强 for 循环。两者性能差异并不明显,但在某些特定场景下有区别。
Iterator 遍历
Iterator 提供了遍历集合的标准方式,尤其在需要在遍历过程中安全地删除元素时,Iterator 是首选方式:
Iterator<String> iterator = list.iterator();
while (iterator.hasNext()) {
String item = iterator.next();
// iterator.remove(); // 安全地删除元素
}
优势:可以安全地进行删除操作,不会导致 ConcurrentModificationException。
劣势:相对于增强 for 循环,代码稍微繁琐。
增强 for 循环
增强 for 循环语法简洁,适合不涉及删除元素的遍历:
for (String item : list) {
System.out.println(item);
}
优势:代码简洁,适合读操作。
劣势:不支持删除操作,若同时对集合进行修改,可能会引发 ConcurrentModificationException。
10.5 避免不必要的集合复制与转换
在编写程序时,避免对集合进行不必要的复制或转换操作是提升性能的关键。以下是几种常见的低效操作:
不必要的复制操作
避免在每次操作时都创建新的集合实例,尤其是在处理大量数据时,频繁的集合复制会带来显著的性能开销。
List<Integer> newList = new ArrayList<>(existingList); // 不必要的复制操作
解决方案:直接操作原集合,除非明确需要副本。
避免重复的类型转换
有时集合中的对象需要类型转换,如果这种转换频繁且可以预先确定类型,应该避免在每次迭代时进行转换。
for (Object obj : list) {
String str = (String) obj; // 每次迭代都进行类型转换
}
解决方案:使用泛型定义集合类型,避免类型转换。
10.6 使用并发集合提高性能
在多线程环境下,传统的集合类如 ArrayList、HashMap 是非线程安全的,如果多个线程同时访问它们,可能会引发数据不一致问题。为了确保线程安全,Java 提供了并发集合,如 ConcurrentHashMap、CopyOnWriteArrayList 等。
ConcurrentHashMap
相比于 HashMap,ConcurrentHashMap 使用了更细粒度的锁机制,允许多个线程并发地进行读写操作,而不会像 HashMap 那样引发线程安全问题。
ConcurrentHashMap<String, Integer> map = new ConcurrentHashMap<>();
map.put("key1", 1);
map.get("key1");
CopyOnWriteArrayList
适合读操作远多于写操作的场景。在写操作时,CopyOnWriteArrayList 会创建一份新的底层数组,确保读操作的线程安全性。
CopyOnWriteArrayList<String> list = new CopyOnWriteArrayList<>();
list.add("Hello");
String value = list.get(0);
BlockingQueue
适用于生产者-消费者模式,BlockingQueue 在队列为空或已满时会阻塞线程,确保多线程环境下的数据同步。
BlockingQueue<Integer> queue = new ArrayBlockingQueue<>(10);
queue.put(1); // 当队列满时,阻塞线程
queue.take(); // 当队列为空时,阻塞线程
11. 线程安全与并发集合
在多线程环境下使用集合时,如果没有妥善的同步机制,会导致数据的不一致甚至程序崩溃。因此,Java 提供了多种线程安全的集合类和同步机制来解决这个问题。
11.1 线程安全集合概述
线程安全集合指的是在多个线程同时访问时,能够确保数据一致性且不发生并发问题的集合。Java 中的早期解决方案如 Vector 和 Hashtable 是通过内部锁机制(synchronized)来实现线程安全的,但这些类在高并发环境下可能存在性能瓶颈。为了更高效地处理多线程访问,Java 在后续版本中引入了多种并发集合,如 ConcurrentHashMap、CopyOnWriteArrayList 等。
| 概念 | 描述 | 功能说明 |
|---|---|---|
| 原子性操作 | 所有操作(如插入、删除、更新等)都是不可分割的,保证操作的完整性,避免竞态条件 | 确保操作在并发环境中不会被中途打断,要么全部成功,要么全部失败 |
| 同步机制 | 通过锁机制或无锁技术确保多个线程安全地访问共享资源或集合 | 使用互斥锁、读写锁或无锁算法(如 CAS)来保证多线程情况下的访问安全 |
11.2 同步集合
早期 Java 中通过对集合的操作方法进行同步,来确保线程安全。最常见的同步集合有。
Vector
Vector 是 ArrayList 的线程安全版本,内部方法都被 synchronized 关键字修饰,保证每次操作都只允许一个线程执行。
Vector<Integer> vector = new Vector<>();
vector.add(1);
vector.get(0);
优点:实现了线程安全,适合简单的多线程环境。
缺点:由于每次访问都需要加锁,性能较差,特别是在高并发场景下,频繁的锁操作导致效率下降。
Hashtable
Hashtable 类似于 HashMap,但它在所有方法上都加了同步锁。
Hashtable<String, String> hashtable = new Hashtable<>();
hashtable.put("key", "value");
优点:线程安全。
缺点:与 Vector 相同,由于所有操作都加了锁,性能受到严重限制。
Collections.synchronizedXxx()
Java 提供了 Collections 工具类中的 synchronizedXxx() 方法,可以将非线程安全的集合包装成线程安全的版本。
List<String> synchronizedList = Collections.synchronizedList(new ArrayList<>());
Map<String, String> synchronizedMap = Collections.synchronizedMap(new HashMap<>());
优点:灵活性高,可以将任何类型的集合转换为线程安全集合。
缺点:底层依然依赖 synchronized,性能在高并发下可能不理想。
11.3 并发集合
随着并发编程需求的增加,Java 提供了更高效的并发集合,它们通过更细粒度的锁或者无锁机制来提高并发性能。
ConcurrentHashMap
ConcurrentHashMap 是 HashMap 的线程安全版本,使用分段锁机制(Segmented Locking)来提高并发性能。相比 Hashtable,它不需要对整个表加锁,而是对部分段进行锁定,大大提升了并发访问的性能。
ConcurrentHashMap<String, Integer> map = new ConcurrentHashMap<>();
map.put("key1", 1);
map.get("key1");
优点:高并发性能,读操作几乎不会被锁限制。
缺点:比 HashMap 稍微复杂,在小规模数据操作时,性能优势不明显。
CopyOnWriteArrayList
CopyOnWriteArrayList 是线程安全的 List 实现,采用写时复制的策略。每次修改操作都会创建一个新的底层数组,并在写操作结束后替换旧的数组。
CopyOnWriteArrayList<String> list = new CopyOnWriteArrayList<>();
list.add("Hello");
list.get(0);
优点:读操作不需要加锁,适合读操作频繁、写操作较少的场景。
缺点:写操作较慢,因为每次写操作都会复制整个数组,导致性能开销较大。
ConcurrentLinkedQueue
ConcurrentLinkedQueue 是线程安全的无界队列,实现了非阻塞算法,适合高并发的队列操作。
ConcurrentLinkedQueue<String> queue = new ConcurrentLinkedQueue<>();
queue.offer("task1");
queue.poll();
优点:无锁的并发队列,性能优越,适合任务队列等高并发场景。
缺点:在少量数据或低并发场景中,无特别性能优势。
11.4 StampedLock 与 ReadWriteLock 在集合中的应用
在某些高读操作频率的场景下,传统的锁机制显得低效。Java 引入了 ReadWriteLock 和 StampedLock 来优化读写性能。
ReadWriteLock
ReadWriteLock 允许多个线程同时读取,但在写入时只允许一个线程写操作。这种机制大大提升了读多写少场景下的性能。
ReadWriteLock lock = new ReentrantReadWriteLock();
Lock readLock = lock.readLock();
Lock writeLock = lock.writeLock();
readLock.lock();
try {
// 读操作
} finally {
readLock.unlock();
}
writeLock.lock();
try {
// 写操作
} finally {
writeLock.unlock();
}
优点:大大提高读多写少场景的性能。
缺点:写操作仍需要锁定整个数据结构,写操作性能不佳。
StampedLock
StampedLock 是 ReadWriteLock 的增强版,提供了乐观读锁机制,在读操作过程中不阻塞写操作,从而进一步提高了性能。
StampedLock lock = new StampedLock();
long stamp = lock.tryOptimisticRead();
try {
// 乐观读取
if (!lock.validate(stamp)) {
// 如果在读取期间有写操作,升级为悲观读锁
stamp = lock.readLock();
}
} finally {
lock.unlockRead(stamp);
}
优点:支持乐观锁,读写性能优异,适合高并发环境。
缺点:使用相对复杂,开发者需要手动验证读写状态。
11.5 如何选择并发集合
在选择并发集合时,主要考虑以下几个因素:
- 读写操作的频率:如果读操作远多于写操作,可以选择
ConcurrentHashMap或CopyOnWriteArrayList,它们能有效提高读操作性能。 - 是否需要有序性:如果需要保持插入顺序或排序,可以选择
ConcurrentSkipListMap或ConcurrentSkipListSet。 - 是否需要阻塞行为:如果需要阻塞队列(如生产者-消费者模式),可以选择
BlockingQueue系列,如LinkedBlockingQueue或ArrayBlockingQueue。 - 集合的大小和访问模式:在高并发下,
ConcurrentHashMap适合大数据量、频繁读写的场景;CopyOnWriteArrayList适合读操作非常多而写操作很少的场景。
| 场景 | 推荐集合 | 理由 |
|---|---|---|
| 高并发的键值对存储 | ConcurrentHashMap | 支持高并发的快速读写操作 |
| 读操作多于写操作的列表 | CopyOnWriteArrayList | 写操作较少,读操作频繁,不需要加锁 |
| 需要无界队列的任务处理 | ConcurrentLinkedQueue | 高效的非阻塞并发队列 |
| 需要阻塞队列(生产者-消费者模式) | LinkedBlockingQueue / ArrayBlockingQueue | 支持线程间的阻塞操作 |
| 有序键值对存储,需支持并发操作 | ConcurrentSkipListMap | 支持并发访问的有序 Map,基于跳表实现,支持排序 |
| 读写比例不均衡,读多写少的场景 | ReadWriteLock / StampedLock | 提升读操作的性能,允许多个读操作并发进行 |
12. 不可变集合与空集合
在日常开发中,有些场景下我们希望某个集合在创建后不可修改,即变为不可变集合。这种集合的内容无法被更改,既不能新增元素,也不能删除或修改现有元素。Java 提供了多种方法来创建不可变集合和处理空集合,这些操作可以帮助我们编写更加安全和健壮的代码。
12.1 不可变集合的意义
不可变集合是指一旦创建后,就无法再修改其内容的集合。这种集合有几个重要的优点:
- 线程安全:不可变集合天然是线程安全的,因为没有修改操作,所以不存在并发修改的风险。
- 防止意外修改:当你不希望某个集合被误改时,不可变集合可以确保数据的稳定性。
- 提高性能:某些场景下,不可变集合可以减少内存和CPU的消耗,因为不需要支持修改操作。
例如,假设你有一个用于配置的集合,配置是全局共享的,且在程序运行期间不会修改。将这个集合设为不可变,可以防止由于代码中的某些意外行为而导致配置数据被修改。
12.2 使用 Collections.unmodifiableXxx 创建不可变集合
在 Java 中,Collections 工具类提供了一些方法来将现有的集合包装成不可变集合,最常见的是 Collections.unmodifiableXxx 方法。通过这些方法,你可以创建不可修改的 List、Set 和 Map 等集合。
List<String> list = new ArrayList<>();
list.add("A");
list.add("B");
// 使用 unmodifiableList 创建不可变的 List
List<String> unmodifiableList = Collections.unmodifiableList(list);
unmodifiableList.add("C"); // 会抛出 UnsupportedOperationException 异常
unmodifiableXxx 方法并不会创建一个全新的集合,而是返回一个包装后的集合,这个集合只能执行读取操作,任何修改操作都会抛出 UnsupportedOperationException 异常。因此,开发者需要确保在使用该方法前,所有需要的修改操作都已完成。
12.3 Java 9+ 提供的 List.of(), Set.of(), Map.of() 方法
从 Java 9 开始,Java 引入了一些新的工厂方法,能够快速创建不可变集合。这些方法包括 List.of()、Set.of() 和 Map.of(),它们直接返回不可变集合,简化了代码编写,同时避免了使用 Collections.unmodifiableXxx 时的包装开销。
List.of():创建一个不可变的 List
List<String> immutableList = List.of("A", "B", "C");
Set.of():创建一个不可变的 Set
Set<String> immutableSet = Set.of("A", "B", "C");
Map.of():创建一个不可变的 Map
Map<String, String> immutableMap = Map.of("key1", "value1", "key2", "value2");
这些方法返回的集合都是不可变的,且更加简洁、方便。此外,Java 9 的这些方法还有一个重要特性:它们不允许出现 null 值,如果尝试传递 null,会抛出 NullPointerException 异常。
12.4 空集合的特殊处理
在某些情况下,我们需要返回一个空集合。例如,当数据库查询返回空结果时,返回一个空的 List 或 Set 是一种常见的做法。Java 提供了一些方法来方便地创建空集合:
- Collections.emptyList():返回一个不可变的空
List。 - Collections.emptySet():返回一个不可变的空
Set。 - Collections.emptyMap():返回一个不可变的空
Map。
这些方法不仅简化了代码,还避免了不必要的 null 检查操作,减少了可能的 NullPointerException 风险。
List<String> emptyList = Collections.emptyList(); // 返回空的 List
Set<String> emptySet = Collections.emptySet(); // 返回空的 Set
Map<String, String> emptyMap = Collections.emptyMap(); // 返回空的 Map
返回一个空集合通常比返回 null 更好,因为调用代码不需要额外进行 null 检查,能更简洁、更安全地处理结果。
12.5 常见的不可变集合应用场景
不可变集合在以下场景中非常有用:
-
全局常量集合:例如,某个集合用于存储一组固定的配置或状态,程序中任何地方都可以使用,但不应该被修改。
public static final List<String> COLORS = List.of("RED", "GREEN", "BLUE"); -
防止修改共享集合:在多线程环境中共享集合时,不可变集合可以避免并发修改导致的数据一致性问题。
-
只读集合:当你希望提供某个集合的只读版本时(如 API 返回结果),不可变集合可以确保外部代码无法对集合进行修改。
-
防止误操作:如果某个集合在逻辑上不应该被修改,将它设为不可变集合可以避免不小心的误修改。例如,服务层传递的某些集合数据不希望被业务层修改。
13. Java 集合框架中的设计模式
在 Java 集合框架中,许多经典的设计模式被广泛应用。这些设计模式为集合的设计和使用提供了灵活的解决方案,帮助开发者以简洁、高效的方式操作集合。接下来,我们将逐一介绍集合框架中常见的设计模式及其应用。
13.1 迭代器模式(Iterator Pattern)
迭代器模式 是一种用于顺序访问集合元素的设计模式,而无需了解集合的底层实现。在 Java 集合框架中,几乎所有集合类都实现了 Iterator 接口,通过该接口可以方便地遍历集合中的每一个元素。
List<String> list = new ArrayList<>();
list.add("A");
list.add("B");
list.add("C");
// 使用迭代器遍历集合
Iterator<String> iterator = list.iterator();
while (iterator.hasNext()) {
System.out.println(iterator.next());
}
核心概念:Iterator 提供了 hasNext()、next() 等方法,可以让开发者逐个访问集合中的元素,而不用关心集合的具体实现方式(如数组、链表等)。
优点:它将遍历操作从集合对象中解耦出来,集合类只需要提供一个迭代器,遍历的细节交由 Iterator 来处理。
13.2 工厂模式(Factory Pattern)在集合框架中的应用
工厂模式是一种用于创建对象的设计模式,它通过隐藏具体的实例化过程,提供了一种创建对象的通用方法。在 Java 集合框架中,我们经常通过静态工厂方法来创建集合对象。例如,Collections 类中的一些静态方法和 Java 9+ 的 List.of()、Set.of() 都是工厂模式的典型应用。
Collections 工具类的工厂方法:
List<String> list = Collections.unmodifiableList(new ArrayList<>()); // 创建不可变集合
Set<String> set = Collections.emptySet(); // 创建一个空集合
Java 9+ 提供的工厂方法:
List<String> list = List.of("A", "B", "C"); // 通过工厂方法创建不可变 List
Set<String> set = Set.of("X", "Y", "Z"); // 通过工厂方法创建不可变 Set
这些工厂方法隐藏了集合的具体实现,使用者只需要调用这些方法即可获得所需的集合,而不关心具体的构造过程。
13.3 策略模式(Strategy Pattern):Comparator 与排序算法
策略模式允许一个算法的行为在运行时动态变化,而不需要修改使用它的代码。在 Java 集合框架中,Comparator 接口就是策略模式的一个典型应用。通过为集合提供不同的 Comparator,我们可以灵活地控制集合的排序方式。
Comparator 使用示例:
List<Integer> numbers = Arrays.asList(3, 1, 4, 1, 5, 9);
// 使用自然排序
Collections.sort(numbers);
// 使用自定义 Comparator 进行降序排序
Collections.sort(numbers, (a, b) -> b - a);
策略模式的核心思想:我们将具体的排序算法作为参数传递给 Collections.sort(),这样可以根据需求选择不同的排序策略,而不必修改集合类的代码。
通过使用不同的 Comparator 实现,集合的排序规则可以灵活变化。例如,你可以按数字大小排序,也可以按字符串的字母顺序、长度等进行排序。
13.4 观察者模式(Observer Pattern)与事件通知机制
观察者模式是一种行为型设计模式,它定义了一种一对多的依赖关系,当一个对象的状态发生变化时,它的所有依赖者(观察者)都会收到通知并自动更新。虽然 Java 集合框架本身并没有直接实现观察者模式,但在 Java 的事件处理机制中,观察者模式被广泛应用。
例如,在图形界面编程中,按钮点击事件的处理就是观察者模式的应用。当用户点击按钮时,按钮会通知所有的监听器(观察者),从而触发相应的动作。
观察者模式的关键组件:
- 主题(Subject):维护一组观察者,当状态改变时通知它们。
- 观察者(Observer):对主题感兴趣的对象,主题的变化会影响观察者的行为。
简单的观察者模式示例(Java 内置的 Observer 接口):
class NewsAgency extends Observable {
private String news;
public void setNews(String news) {
this.news = news;
setChanged();
notifyObservers(news);
}
}
class NewsChannel implements Observer {
private String news;
@Override
public void update(Observable o, Object arg) {
this.news = (String) arg;
System.out.println("News updated: " + news);
}
}
public class Main {
public static void main(String[] args) {
NewsAgency agency = new NewsAgency();
NewsChannel channel = new NewsChannel();
agency.addObserver(channel);
agency.setNews("Breaking news: Java is awesome!");
}
}
在这个例子中,NewsAgency 是被观察的对象,NewsChannel 是观察者。每当 NewsAgency 的新闻更新时,它会通知所有的 NewsChannel,从而触发相应的操作。
14. Java 集合框架中的常见错误
在使用 Java 集合框架时,开发者经常会遇到一些常见的错误和问题。这些错误不仅会导致程序崩溃,还可能引发难以调试的逻辑错误。下面我们将介绍几种常见错误的产生原因、如何避免它们,以及一些调试集合问题的技巧。
14.1 ConcurrentModificationException
ConcurrentModificationException 是开发者在操作集合时经常遇到的异常。它通常在遍历集合的过程中发生,特别是在使用 Iterator 遍历集合时,如果你同时修改了集合的结构(如增删元素),就会抛出这个异常。
异常场景:
List<String> list = new ArrayList<>();
list.add("A");
list.add("B");
list.add("C");
for (String item : list) {
if (item.equals("B")) {
list.remove(item); // 这里会抛出 ConcurrentModificationException
}
}
原因:在遍历集合时修改集合,会导致集合的内部结构不一致,进而触发异常。
解决办法:
-
使用
Iterator的remove()方法:避免直接调用remove(),而是通过Iterator提供的安全删除机制。Iterator<String> iterator = list.iterator(); while (iterator.hasNext()) { String item = iterator.next(); if (item.equals("B")) { iterator.remove(); // 正确的删除方式 } } -
使用并发集合(如
CopyOnWriteArrayList):在并发场景下修改集合时,可以使用线程安全的集合类,如CopyOnWriteArrayList,它允许在遍历时进行修改。
14.2 NullPointerException
NullPointerException 是 Java 中最常见的异常之一。它通常在集合中插入或访问 null 元素时产生,特别是当集合不允许 null 时,可能导致程序崩溃。
异常场景:
List<String> list = null;
list.add("A"); // 会抛出 NullPointerException,因为 list 是 null
原因:试图在 null 集合上进行操作,或者某些集合不允许插入 null 值(如 TreeSet 和 TreeMap)。
解决办法:
-
初始化集合:确保在使用集合之前先进行初始化。
List<String> list = new ArrayList<>(); // 先初始化,再操作 -
使用空集合而非
null:避免返回null,使用Collections.emptyList()或Collections.emptySet()返回一个空集合。 -
添加
null检查:在对集合进行操作时,添加null检查来防止空指针异常。
14.3 ClassCastException
ClassCastException 发生在试图将一个对象转换为与其类型不兼容的类时。在集合中,特别是在不使用泛型时,容易发生这种异常。例如,试图将一个 String 对象强制转换为 Integer。
异常场景:
List list = new ArrayList(); // 没有使用泛型
list.add("A");
Integer number = (Integer) list.get(0); // 会抛出 ClassCastException
原因:没有使用泛型,导致集合中的对象类型不明确,从而发生类型转换错误。
解决办法:使用泛型可以在编译时检查类型,从而避免类型转换错误。
List<String> list = new ArrayList<>();
list.add("A");
// 编译时检查,防止类型转换错误
本期小知识
Deque 是双端队列(Double Ended Queue),既可以从队首插入和移除元素,也可以从队尾插入和移除元素。它比 Queue 更灵活。
LinkedList 是 Deque 的一个常见实现,它可以同时用作栈(Stack)和队列(Queue)。所以,LinkedList 是一个同时支持 LIFO 和 FIFO 结构的集合类。