序言
第一次论文出现在 《Leveraging Large Language Models for Concept Graph Recovery and Question Answering in NLP Education》
论文地址:https://arxiv.org/abs/2402.14293
七月份的时候应该是又改进了一次。但是又发了一篇新的地址:《Graphusion: Leveraging Large Language Models for Scientific Knowledge Graph Fusion and Construction in NLP Education》
(论文重生之我有名字啦)
论文地址:https://arxiv.org/abs/2407.10794
代码仓库:https://github.com/IreneZihuiLi/CGPrompt
我们先讲前面的。
文章目录
- 序言
- 202402 Leveraging Large Language Models for Concept Graph Recovery and Question Answering in NLP Education
- 摘要
- 思维导图
- 论文方法
- 方法描述
- 方法改进
- 解决的问题
- 论文实验
- 论文总结
- 文章优点
- 方法创新点
- 未来展望
- 202407 Graphusion: Leveraging Large Language Models for Scientific Knowledge Graph Fusion and Construction in NLP Education
- 摘要
- 思维导图
- 论文方法
- 方法描述
- 1. 种子概念生成(Seed Concept Generation)
- 2. 候选三元组提取(Candidate Triplet Extraction)
- 3. 知识图谱融合(KG Fusion)
- 解决的问题
- 论文实验
- 链接预测
- 知识图谱补全
- 论文总结
- 文章优点
- 方法创新点
- 未来展望
202402 Leveraging Large Language Models for Concept Graph Recovery and Question Answering in NLP Education
摘要
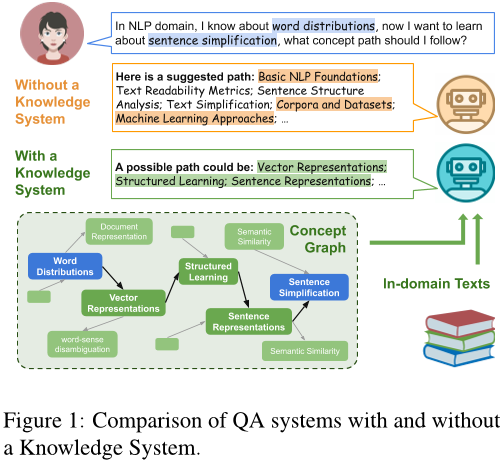
本研究探讨了大型语言模型(LLM)在自然语言处理教育领域的应用潜力,着重于概念图谱恢复和问答任务。研究人员评估了LLM在零样本情况下的概念图谱恢复能力,并引入了一个由专家验证的NLP专注于科学图论推理和问答的新基准TutorQA。CGLLM是一个将概念图谱与LLM集成以回答各种问题的工作流。实验结果表明,LLM在零样本情况下具有与监督方法相当的概念图谱恢复能力,并且在TutorQA任务中实现了高达26%的F1得分提升。此外,人类评价和分析显示,CGLLM可以生成更细粒度的概念答案。
思维导图

论文方法

方法描述
本文提出了构建概念图谱的方法,包括零样本学习和有监督学习两种方式。在零样本学习中,使用了多种提示策略,如零样本、Chain-of-Thought(CoT)和Retriever Augmented Generation(RAG),并探索了是否加入额外信息的效果。而在有监督学习中,则是基于二元分类模型或图形卷积网络(GCN)来预测未见的概念关系。
具体来说,在零样本学习中,通过提供领域名称、依赖关系定义及描述以及查询概念,构建出一个知识图谱,并将答案限制为“是”或“否”。同时,还考虑到了添加额外信息的情况,例如从维基百科获取概念定义和从训练数据中获取相邻概念的信息等。此外,也尝试了CoT提示策略,详细例子请参见附录A。
在有监督学习中,首先利用给定的概念嵌入来进行二元分类,然后结合GCN模型来预测未知的关系。对于GCN模型,通过连接已知的先决条件关系矩阵和可学习权重矩阵,实现了特征矩阵到隐藏状态矩阵的转换。最后,通过可训练矩阵X和隐层表示X^的点乘,得到了剩余的关系矩阵。
方法改进
本文提出的方法具有一定的创新性和实用性。在零样本学习中,通过多种提示策略和额外信息的引入,提高了预测准确率;在有监督学习中,结合了GCN模型,使得预测结果更加准确。同时,本文提出的构建概念图谱的方法也为相关领域的研究提供了参考。
解决的问题
本文解决了如何构建概念图谱的问题,为自然语言处理等领域提供了重要的基础支持。同时,该方法也可应用于其他需要构建关系图谱的场景,具有一定的普适性。
论文实验
本文主要介绍了三个对比实验:
第一个实验是使用LectureBankCD数据集对概念图谱的恢复进行了比较。该实验包括四个任务:先决条件预测、路径搜索、最短路径搜索和概念建议。其中,任务1使用准确率和F1分数作为评估指标,任务2到4使用相似度基于F1分数(S-F1)作为评估指标。实验结果表明,与传统的预训练模型相比,使用概念图谱增强的知识增强系统在所有任务中都表现出了更好的性能。
第二个实验是在TutorQA基准上进行的问答任务。该实验包括五个任务:先决条件预测、路径搜索、最短路径搜索、概念建议和Idea Hamster。其中,任务1到4使用准确率和F1分数作为评估指标,任务5使用专家评价来评估生成的项目提案的质量。实验结果表明,与传统的预训练模型相比,使用概念图谱增强的知识增强系统在所有任务中都表现出了更好的性能。
第三个实验是对概念图谱恢复的启发式策略的研究。该实验探索了不同的提示策略和外部数据的影响。实验结果表明,在NLP领域中,将邻居概念添加为额外信息可以显著提高基线模型的性能,而使用LectureBankCD文档会降低性能。此外,通过微调外部数据也可以获得更好的性能。
综上所述,本文展示了使用概念图谱增强的知识增强系统的优越性,并探讨了不同提示策略和外部数据的影响。这些发现对于开发更有效的知识增强系统具有重要的指导意义。

论文总结
文章优点
- 本文探索了大语言模型(LLMs)在教育场景中的概念图谱恢复和问答任务中的应用,填补了LLMs在教育领域整合方面的文献空白。
- 作者开发了一个名为CGLLM的管道,用于改善LLMs与TutorQA(一个专为科学图谱推理和问答设计的基准测试)中概念图的交互。结果表明,CGLLM显著提升了性能,F1分数提升了高达26%。
- 作者在研究中考虑了伦理问题,确保他们的数据集TutorQA不包含任何有害或涉及个人隐私的信息,并遵守了AI研究中既定的伦理规范。
方法创新点
- 作者提出了利用LLMs生成的概念图来回答更加复杂和具有挑战性的问题的应用方法。
- 他们开发了CGPrompt,这是一种使LLMs能够从给定的一组概念中执行零样本概念图谱恢复的方法,并设计了TutorQA,这是一个经过专家验证、以NLP为中心的基准,用于基于概念图的问答。
- 作者设计了CGLLM管道,旨在通过利用LLMs来增强问答性能。
未来展望
- 作者承认他们的方法存在一些局限性,特别是在从零构建概念图时,以及在提供的答案路径中忽略了概念顺序。解决这些问题将是他们未来工作的重点。
- 作者建议将知识图谱与LLMs整合,进一步提高文本生成中的真实性和可解释性,这将有助于教育场景中的应用。
202407 Graphusion: Leveraging Large Language Models for Scientific Knowledge Graph Fusion and Construction in NLP Education
个人观点:
新增了名字- 扩充了更完善的数据集规模以及评价指标
- 更新了论文定位(感觉从(KGC + QA)的说明强化了图谱构建的部分)
- 增加了链接预测的实验。
摘要
这篇论文介绍了一种名为Graphusion的知识图谱融合框架,该框架利用大型语言模型(LLMs)从自由文本中零样本构建知识图谱。传统的KG构建需要专家付出大量努力,而Graphusion提供了一个全局视角,包括实体合并、冲突解决和新颖的三元组发现等模块。作者展示了如何将Graphusion应用于自然语言处理领域,并在教育场景下验证了其有效性。他们还提出了一个新的经过专家验证的基准测试TutorQA,包含六个任务和总共1200个问答对。实验结果表明,Graphusion在链接预测方面的准确率比监督基线高出高达10%,并且在概念实体提取和关系识别的人类评估中分别达到了2.92和2.37分的成绩。
思维导图


论文方法
方法描述
本文提出了一种名为Graphusion的框架,用于科学领域的知识图谱构建。该框架包括三个关键步骤:种子概念生成、候选三元组提取和知识图谱融合。在种子概念生成阶段,使用BERTopic进行主题建模以识别每个话题的代表性概念,并将其作为种子概念。在候选三元组提取阶段,利用链式思维提示从自由文本中提取候选三元组。最后,在知识图谱融合阶段,通过实体合并、冲突解决和新颖三元组推断等操作将不同来源的知识图谱融合成一个全局视角下的知识图谱。

1. 种子概念生成(Seed Concept Generation)
在第一步,Graphusion框架从科学领域的自由文本数据中提取种子概念。通过主题建模(Topic Modeling),例如BERTopic,识别文本中的代表性概念,将其作为种子概念。这些种子概念为后续的三元组提取提供了基础,并保证了与领域相关的高质量概念提取。
2. 候选三元组提取(Candidate Triplet Extraction)
第二步基于种子概念,开始从自由文本中提取候选三元组。通过链式思维(Chain-of-Thought, CoT)提示策略,模型能够识别这些概念之间的关系,并提取三元组,如 “概念A - 关系 - 概念B”。此步骤不仅限于种子概念,模型还能发现包括新概念的三元组,从而扩展知识图谱的覆盖范围。
3. 知识图谱融合(KG Fusion)
第三步是知识图谱融合,解决前两步中生成的局部视角问题,并处理概念和关系之间的冲突。在此阶段,Graphusion框架执行以下操作:
- 实体合并:合并语义相似的实体,例如 “NMT” 和 “Neural Machine Translation”。
- 冲突解决:如果两个概念之间存在不同的关系(如“前提条件”与“下位关系”冲突),框架将根据背景信息选择最合适的关系。
- 新颖三元组推断:框架还会从背景文本中推断出新的三元组关系,以进一步丰富知识图谱。
解决的问题
Graphusion旨在解决零样本科学知识图谱构建中的问题,即如何从自由文本中自动提取出与领域相关的概念和关系,并将其整合为一个高质量的知识图谱。同时,该框架也适用于需要快速构建科学知识图谱的场景,例如科研人员需要了解某个研究方向的相关概念和关系时。
论文实验
本文主要介绍了针对知识图谱(Knowledge Graph)的研究工作,涵盖了两个任务:链接预测(Link Prediction)和知识图谱补全(Knowledge Graph Completion)。通过实验评估了Graphusion框架在这些任务中的表现,并与传统的监督学习方法进行了比较,证明了该框架在零样本学习场景中的有效性。
链接预测
在链接预测任务中,作者使用了LectureBankCD数据集进行实验,包含自然语言处理(NLP)领域中的322个预定义概念及其先决条件关系标签。作者对比了四种传统的监督学习基线模型,包括DeepWalk、Node2Vec、P2V和BERT,这些模型基于概念嵌入并进行二元分类,以确定给定概念对之间是否存在关系。此外,作者还进行了两种基于大语言模型(LLMs)的实验:零样本学习和**检索增强生成(RAG)**策略。
实验结果表明,基于LLMs的零样本学习模型(特别是GPT-4和GPT-4o)在恢复领域特定概念图谱方面优于传统的监督学习基线模型。加入RAG方法后,GPT-4o在精度和F1分数上进一步提高,验证了该方法在特定领域数据集上的显著效果。
例如,表1展示了LectureBankCD-NLP测试集上的评估结果,GPT-4o的表现超越了传统的基线模型,特别是在结合RAG后的任务中达到了最佳表现 。

知识图谱补全
在知识图谱补全任务中,作者收集了ACL会议的论文集(2017-2023年),生成了688个种子概念,作为知识图谱补全的基础。在该任务中,Graphusion框架通过从自由文本中提取候选三元组,并将这些三元组与现有的知识图谱进行融合。
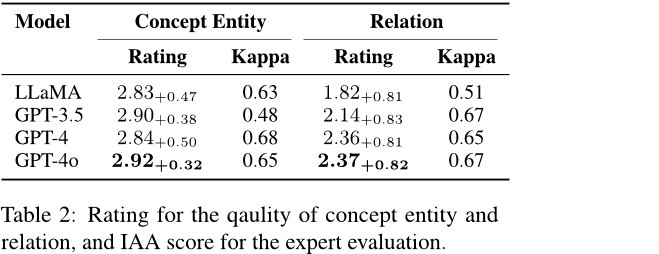
实验中,作者评估了Graphusion在四种语言模型(LLaMa、GPT-3.5、GPT-4和GPT-4o)上的表现,尤其关注概念实体质量和关系提取的质量。实验结果表明,GPT-4o在概念和关系提取上均表现最佳,并且专家的一致性评分(Inter-Annotator Agreement,IAA)较高,表明其在人类专家评估中的可靠性。
表2显示了各模型在概念实体和关系提取任务上的得分,GPT-4o在两个指标上均表现优越,并且IAA评分显示专家评估结果的一致性较高 。
通过这些实验,本文展示了Graphusion框架在知识图谱任务中的有效性,尤其是在零样本学习和知识图谱融合方面的优越性。
论文总结
文章优点
该论文提出了一种基于大型语言模型(LLM)的知识图谱融合与构建的方法,能够实现零样本知识图谱提取,并将其应用于教育问答场景中。具体来说,该研究提出了Graphusion框架,通过实体合并、冲突解决和新颖三元组发现等模块实现了自动化的科学知识图谱构建;同时,设计了TutorQA基准测试集,用于评估基于知识图谱增强的问答系统性能。这些方法在实验中取得了显著的效果,为基于自然语言处理领域的知识图谱建设和应用提供了新的思路和技术支持。
方法创新点
该论文的主要贡献在于提出了利用大型语言模型进行知识图谱融合的新方法,克服了传统知识图谱构建方法存在的局限性和不足之处。此外,该研究还针对教育问答场景的特点,设计了一个专门的基准测试集,用于评估基于知识图谱增强的问答系统的性能表现。这些创新性的方法对于提高自然语言处理领域中的知识图谱建设和应用具有重要意义。
未来展望
虽然该论文提出的Graphusion框架和TutorQA基准测试集已经取得了一些有意义的结果,但仍然存在一些限制和挑战需要进一步探索和改进。例如,在知识图谱构建过程中如何考虑不同来源文本之间的关系和一致性问题,以及如何更好地利用人类专家的知识来指导和优化自动化的知识图谱构建过程等。因此,未来的研究方向可以围绕这些问题展开,以进一步推动基于自然语言处理领域的知识图谱建设和应用的发展。







![[Linux]进程管理指令](https://img-blog.csdnimg.cn/img_convert/7a5af5d7733b89852b2999b70d8a2462.png)










