目录
⚛️1. 会议详情
☪️2. 会议回顾
♋2.1 多模态时代,存内计算架构的应用与发展
♏2.2 分布式环境下深度学习任务的高效可靠执行研究
♐2.3 IGZO在后道单片三维集成中的机遇与挑战
♑2.4 witin-nn:神经网络算法模型在存内开发板上的应用开发
♉2.5 茶歇交流 ~ ~ ~
♈2.6 AGI开源圆桌分享
🔯神秘彩蛋
⚛️1. 会议详情
会议主题:高能效存内计算 · AGI 创新工坊
会议流程:

主办方:存内计算开发者社区
☪️2. 会议回顾
议程亮点:
- 存内计算技术架构及最新趋势
- AGI开源项目交流
- 存内计算实操体验
- 存内计算:突破物理极限的下一代算力技术
存内计算技术通过直接消除“存储”和“计算”之间的界限,避免数据频繁搬运,显著提升芯片性能,降低功耗,并保持成本可控,真正实现了存算一体化。
AGI圆桌交流:AIGC开源互动分享
随着AI技术的迅猛发展,我们正站在通用人工智能(AGI)的前沿。与行业先行者共同探讨AGI的最新研究进展,及其对未来社会的深远影响。

♋2.1 多模态时代,存内计算架构的应用与发展

分享嘉宾: 李阳 — 知存科技存算生态负责人
分享内容:在多模态时代,计算需求的激增不仅是技术发展的必然,也是社会变革的体现。云端大模型的应用正渗透到我们生活的方方面面,包括:
- 视频生成与精准搜索广告
- 办公自动化提升效率
- 元宇宙游戏的沉浸式体验
- 移动终端的智能化应用
- 智能助手与具身智能的交互
- 自动驾驶技术的可靠性
同时,我们也迎来了前所未有的计算需求。这不仅是技术进步的必然结果,更是对未来生活方式的深刻反思。云端大模型的应用已无处不在,涵盖了从视频生成、搜索广告,到办公自动化、元宇宙游戏,再到智能助手和自动驾驶。这些技术正在重新定义我们的互动方式和工作效率。
然而,数万亿参数的云端大模型并非无懈可击。当前,AI发展面临四大瓶颈:功耗、成本、带宽与容量。这让我思考,尽管技术日新月异,但我们必须正视其可持续性和社会责任。在追求效率和创新的同时,如何确保技术的环境友好性和经济可承受性,是我们每一个从业者需深思的问题。
解决方案:存内计算技术的崛起为我们提供了新的视角。相较于传统的CPU/GPU,它带来的更高并行度和能效意味着我们可以在有限资源下,推动更大规模的计算。这种技术不仅是一种选择,更是一种对未来计算架构的重新思考。

技术亮点:通过将不同的die集成在硅基基座上,混合集成逻辑、模拟与内存芯片,并基于UCIE协议实现高速互联,接口带宽可达1Kbit。尽管集成成本高,但这种设计的灵活性使我们能够更快地响应市场需求,促进技术的快速迭代。这不仅是技术上的突破,更是推动社会进步的力量。我坚信,只有将技术发展与社会价值紧密结合,才能真正实现可持续的未来。

♏2.2 分布式环境下深度学习任务的高效可靠执行研究

分享嘉宾: 黄彬彬 — 杭州电子科技大学
分享内容:随着深度学习模型规模的迅猛扩展,单机训练逐渐无法满足日益增长的计算需求。在这一背景下,分布式训练成为必然趋势。通过多机协同,我们能够将训练过程分解为多个任务,调度到多个计算节点上并行执行,从而显著加快训练速度。

然而,分布式深度学习面临着调度和故障两大挑战。训练速度的提升与分布式调度策略密切相关,特别是流水线并行训练中的调度问题,成为加速训练的关键所在。此外,计算节点的故障也可能导致任务延迟甚至中断。因此,提前预测计算节点故障并采取相应措施,能够有效降低故障对训练过程的影响。
解决方案:为此,提出了基于强化学习的流水线分布式训练调度方案(PG-MPSS)。该方案的工作流程如下:
- 特征提取:通过对每个阶段的所有层特征进行逻辑“或”操作,提取阶段特征。
- 特征编码:将每个阶段的特征依次输入到映射网络中。
- 节点映射:映射网络输出每个阶段对应的计算节点编号。
- 流水线训练:基于模型划分及阶段映射结果,实施流水线并行训练。
同时,还提出了基于连续时间动态图预测的节点故障预测方案(CTDG-NFP)。该方案采取邻居采样策略,在时间游走中,从某点出发,走到其邻居节点中的一个。设计采样邻居的策略至关重要。

在时间游走过程中,引入了长短路径学习,以确认游走路径的长度。这一过程经过匿名化处理后,可以揭示多样化长度的路径规律。时间编码器结合了多层感知器(MLP)和Informer编码器,以提升故障预测的准确性。

技术亮点:
- 强化学习调度:通过引入强化学习机制,使调度更加智能化,能够根据实时反馈优化训练过程。
- 流水线并行:流水线分布式训练提高了资源利用率,缩短了训练时间,实现了更高的计算效率。
- 故障预测:基于图结构的连续时间动态预测方法,可以提前识别潜在故障,增强系统的可靠性。
- 长短路径学习:通过灵活的路径学习策略,提高了邻居采样的准确性,为节点故障预测提供了更全面的视角。
思考与展望:在深度学习的未来,如何高效、可靠地执行分布式任务,将是技术进步的关键。通过结合强化学习与图结构预测,我们不仅提升了训练效率,也为系统的稳定性提供了保障。这一研究不仅推动了学术界的探索,也为工业界的应用开辟了新的方向。我们必须继续关注这些前沿技术,推动其在实际场景中的应用,助力深度学习的更广泛发展。
♐2.3 IGZO在后道单片三维集成中的机遇与挑战

分享嘉宾: 李骏康 — 浙江大学集成电路学院
分享内容:集成电路性能的提升与MOSFET器件的微缩化密不可分。进入后摩尔时代,三维集成成为应对器件微缩化挑战的重要发展方向。当前,芯片级三维集成被广泛视为提升集成电路密度和性能的主要手段,它能够快速响应市场对更高集成度的需求。这一趋势不仅是技术进步的体现,也在重新定义芯片设计和制造的思考。
未来,基于后道工艺的单片三维集成将是发展的关键。然而,这一方法的实现依赖于兼容低温工艺的成熟半导体材料,这不仅是材料科学的挑战,也是制造工艺的突破。

解决方案:氧化物半导体的一个显著优势是其迁移率与结晶状态无关,这使其在非晶态下也能保持较高的电子迁移率。IGZO(铟镓锌氧化物)作为显示面板领域成熟的半导体材料,展示了这种优势。其组成元素铟、镓和锌的相互作用,直接影响材料的性能。
- 铟 (In) 提供电子,但由于键结弱,易形成氧空位缺陷,可能影响器件的稳定性。
- 镓 (Ga) 则通过其强键结来增强稳定性,有效减少氧空位,从而提高IGZO的整体性能。
- 锌 (Zn) 确保材料在特定条件下不晶化,其化学配比与Ga₂O₃、In₂O₃的不同,使其在维持性能的同时,降低材料的复杂性。
氧化物半导体通过原子层沉积(ALD)方式实现低温生长(< 400℃),这为实现垂直的三维结构创造了条件。然而,IGZO的工艺中常见的C污染会导致缺陷,进而影响性能。特别是在Al₂O₃/IGZO界面质量不佳的情况下,顶栅器件的亚阈值特性将遭受严重退化。此外,后段的绝缘层沉积(ILD)及薄膜晶化退火等工艺,会使器件长时间处于高温环境,从而导致薄膜性能的退化。氟处理能增强IGZO中金属与氧的键结,提高薄膜的稳定性。
技术亮点:
- 高迁移率特性:氧化物半导体在非晶态下依然保持较高的电子迁移率,为高速器件的实现提供了可能。
- 灵活的阈值电压调节:通过调整元素组分,可以精准控制器件的阈值电压,提升设计的灵活性和适应性。
- 低温工艺的兼容性:氧化物半导体适合于低温工艺,促进三维集成的实现,尤其在当前追求高集成度的背景下显得尤为重要。
- 全n型IGZO器件的创新:基于全n型IGZO的单极性共轭10T SRAM电路结构,通过优化阈值电压和开态电流,成功实现SRAM的基本功能。

思考与展望:IGZO作为后道工艺实现单片三维集成的最佳候选沟道材料,凭借其高迁移率、低漏电和兼容低温工艺的特点,将在未来的集成电路中扮演重要角色。然而,IGZO目前仍面临高温稳定性、抗氢性和正偏压温度不稳定性等挑战。
利用IGZO实现存储阵列(如SRAM、DRAM等)不仅能有效提升芯片的集成度,也为计算效率的提升提供了坚实基础。未来,需要继续深入研究IGZO材料的特性,探索其在高性能计算芯片中的应用潜力。只有将技术创新与实际需求相结合,才能在集成电路的未来发展中把握机遇,迎接挑战。
♑2.4 witin-nn:神经网络算法模型在存内开发板上的应用开发

分享嘉宾: 张翼翔 — 知存科技存算工程师
分享内容:本次分享深入探讨了Witin_NN的构成及其在存算一体化中的应用,着重分析了当前面临的挑战以及存内计算的优势。
Witin_NN的构建流程分为三个阶段:
- 基础浮点模型训练:为模型建立初步性能基线,确保其在高精度下运行。
- 量化感知训练:通过量化处理降低模型复杂度,以减少存储需求和计算负担,同时尽量保留模型的准确性。
- 噪声感知训练:提高模型对噪声的鲁棒性,使其在现实环境中表现更稳定。
在未采用存内计算之前,深度学习模型的训练和推理通常依赖于频繁的数据传输,这导致了严重的带宽瓶颈和高能耗,进而影响整体性能和效率。此外,传统计算架构在处理复杂模型时,往往面临延迟和功耗问题,限制了实时应用的实现。
存内计算的优势在于其能将存储和计算整合,显著降低数据传输的需求。由于计算在数据存储层面完成,存内计算能够减少延迟并提高能效,特别适合边缘设备和资源受限的环境。其亮点包括:
- 高能效:减少了因数据传输引起的能耗。
- 低延迟:计算过程在存储中进行,避免了传统架构中的传输延迟。
- 提升计算密度:通过优化芯片设计,提高集成度和运算能力。
在此背景下,WitinMapper承担着模型的Map转换功能,确保训练好的模型能有效适应特定硬件。烧录工具则负责将模型烧录到目标芯片,实现实际应用。最后,推理引擎确保芯片端的高效推理功能,为存内计算提供强大的支持。

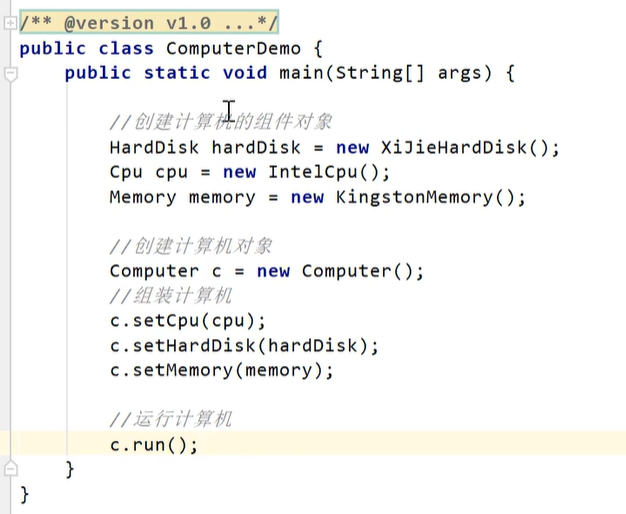
Witin_NN 用法
class DnnNet(nn.Module):
def __init__(self):
self.linear1 = torch.nn.Linear(128,128, bias = False)
def forward(self, _input):
out = self.linear1(_input)
return out
class DnnNet(nn.Module):
def __init__(self):
config_linear1 = LayerConfigFactory.get_default_config()
config_linear1.use_quantization = False
self.linear1 = WitinLinear(128,128, bias = False, layer_config=config_linear1)
def forward(self, _input):
out = self.linear1(_input)
return out
class DnnNet(nn.Module):
def __init__(self):
config_linear1 = LayerConfigFactory.get_default_config()
config_linear1.use_quantization = True
config_linear1.noise_level = 4
config_linear1.x_quant_bit = 8 #输入量化位宽
config_linear1.y_quant_bit = 8 #输出量化位宽
config_linear1.scale_x = 16 #输入缩放参数
config_linear1.scale_y = 16 #输出缩放参数
config_linear1.scale_weight = 16 #权重缩放参数
self.linear1 = WitinLinear(128,128, bias = False, layer_config=config_linear1)
def forward(self, _input):
out = self.linear1(_input)
return out
存内计算开发板上的开发实践 ~ ~ ~

传送门:Witin-NN-Tool
目录结构:
mnist_demo_ver3.0
|—— python # 模型训练、ONNX模型转换代码
|—— mapper # 工具链的输入及产物示例
|—— project # 板端工程示例
|—— tools # 串口工具,环境.whl 文件等
|—— doc # 一些工具或工程的说明文档

本Demo展示了一个卷积神经网络(CNN)的结构,以下是详细的训练步骤及问题记录与解决方案。
训练步骤
-
Python环境安装
本Demo推荐在Windows操作系统上进行运行。环境的正确设置是成功训练模型的基础,详细的安装指导请参考doc/python 环境安装.txt。建议使用虚拟环境(如Anaconda)来管理依赖,以避免不同项目之间的库版本冲突。这种做法不仅能保持环境的整洁,还能提供必要的灵活性。
安装Anaconda
启动Anaconda
-
进入代码目录
使用命令行进入代码目录:cd python这一阶段需要确保所有相关代码文件完好无损,且路径设置正确,以避免后续运行中的错误。
安装依赖


-
模型训练配置
在进入代码目录后,需检查并修改模型训练配置文件config.py。超参数的设置(如学习率、批次大小、训练轮数等)直接影响模型的性能。基于经验,初始学习率应保持在一个较小的范围内,以便模型能逐渐适应数据集,避免震荡或发散。 -
运行训练脚本
启动模型训练过程:python train.py训练完成后,生成的最佳模型权重会保存至
models/net_type/bestModel.pth。权重文件的质量直接关系到推理阶段的效果,因此建议在训练时记录每轮的损失和精度变化,以监控模型的收敛情况。
-
推理与ONNX模型构建
通过运行以下命令将训练得到的模型进行推理并构建ONNX模型:python infer_and_generate_onnx.py生成的ONNX模型将被保存在
models/net_type/bestModel_quant.onnx。将该模型复制到mapper/input目录中,确保其在后续步骤中的可访问性。这一环节不仅是对模型性能的再次验证,也是将训练好的模型转化为实际应用的关键步骤。 -
量化数据生成
运行以下脚本生成必要的测试数据:python create_quant_data.py此操作将在
mapper/input目录中生成test_data_cnn_0_100.npy和mnist_data_cnn.h。这两个文件是后续生成映射和验证时必不可少的输入文件。数据的准确性和完整性将直接影响模型在实际硬件上的表现。
-
根据下载的 pdf 教程,使用 NPU 烧写板(NPU 烧录器),进行模型烧录和开发。
问题记录及解决方案
环境安装问题
- 问题:在安装Python环境时,常常遇到依赖包缺失或版本不兼容的问题。
- 解决方案:在安装前,建议通过
pip list检查已安装的包,确保版本与项目要求一致。使用pip install -r requirements.txt来批量安装所有依赖,能够显著降低遗漏的风险。
模型训练未收敛
- 问题:训练过程中,损失函数未能有效下降,模型精度停滞不前。
- 解决方案:需仔细检查
config.py中的超参数设置,特别是学习率和批次大小。常见的做法是尝试不同的学习率衰减策略,例如学习率预热或动态调整。对数据集进行详细分析,以确保其多样性和代表性,也是提升模型性能的有效途径。
推理模型失败
- 问题:运行
infer_and_generate_onnx.py时,模型加载失败,提示找不到权重文件。 - 解决方案:检查权重文件的路径和名称是否正确,确保在运行推理前权重文件已经成功保存。可通过异常处理机制捕捉具体错误,帮助定位问题。
量化数据生成失败
- 问题:在执行
create_quant_data.py时,出现输入文件缺失的错误提示。 - 解决方案:核实
mapper/input目录中ONNX模型文件是否存在,并确保路径设置正确。建议在执行之前,手动检查输入文件的完整性和有效性,确保数据格式符合要求。

思考与展望
在存内计算开发板上的实践过程中,以下几点值得深入思考和总结:
1. 存内计算的优势与挑战
存内计算将计算过程直接集成于内存中,显著降低了数据传输延迟,提升了整体性能。这一优势特别适合实时性要求高的应用,如边缘计算。但挑战依然存在,主要包括硬件兼容性和算法适配性,需在实践中不断调整和优化。
2. 硬件与软件的协同设计
成功的存内计算依赖于硬件与软件的紧密配合。理解硬件特性有助于开发适应的算法。例如,在硬件资源受限的情况下,调整算法复杂度和资源占用,能有效提升性能。这种动态调整能力是实现高效存内计算的关键。
3. 数据处理与优化
高效的数据处理是提升计算性能的重要环节。通过数据预处理和压缩技术,可以减小存储需求并加快计算速度。此外,使用数据增强和优化数据集划分,能提升模型的泛化能力,进一步优化存内计算的效率。
4. 实践中的问题及解决方案
在实践中,常遇到如计算精度下降和能耗过高等问题。通过实验与调整,例如优化量化策略或引入残差连接,能够有效提升模型表现。这种持续反馈与优化的过程,强化了对模型和系统的理解。


最终输出内容:
开发板 reset 按键进行重启操作,正确输出见下图。

♉2.5 茶歇交流 ~ ~ ~



♈2.6 AGI开源圆桌分享

分享组织: 特工宇宙
分享内容:在特工宇宙的AGI(通用人工智能)开源圆桌分享会上,分享人与研究人员共同探讨了AGI的未来、开源技术的关键作用,以及实现AGI所面临的挑战与机遇。与会者认为,AGI的目标是构建自我学习和高度适应性的智能系统,能够理解自然语言并解决复杂任务,展现出人类水平的智能。
开源技术被视为推动AGI发展的重要动力,通过共享代码和数据,开源社区加速了研究进程,降低了技术门槛。与会者分享了成功的开源项目,如OpenAI的GPT系列和Google的TensorFlow,强调开源促进跨学科合作的重要性。
尽管前景广阔,实现AGI面临安全性、伦理性和计算资源需求等挑战。专家建议在开源项目中引入伦理审查与社区监督,以确保技术发展符合社会期待。同时,如何高效利用计算资源也是关键议题,许多参与者分享了在云计算和分布式计算方面的经验,与会者对AGI的发展充满信心,认为技术进步和开源社区的壮大将使AGI的实现变得可行。此次分享为AGI研究者提供了宝贵的平台,促进了思想碰撞与合作。期待在不久的将来,AGI能为社会带来更多创新与变革。
🔯神秘彩蛋
天才博士计划——知存科技


入选天才博士计划的你,将拥有
- 百万级行业顶级待遇
- 挑战世界领先技术的机会
- 核心研发岗位
- 广阔的职业发展空间
投递链接:天才博士计划