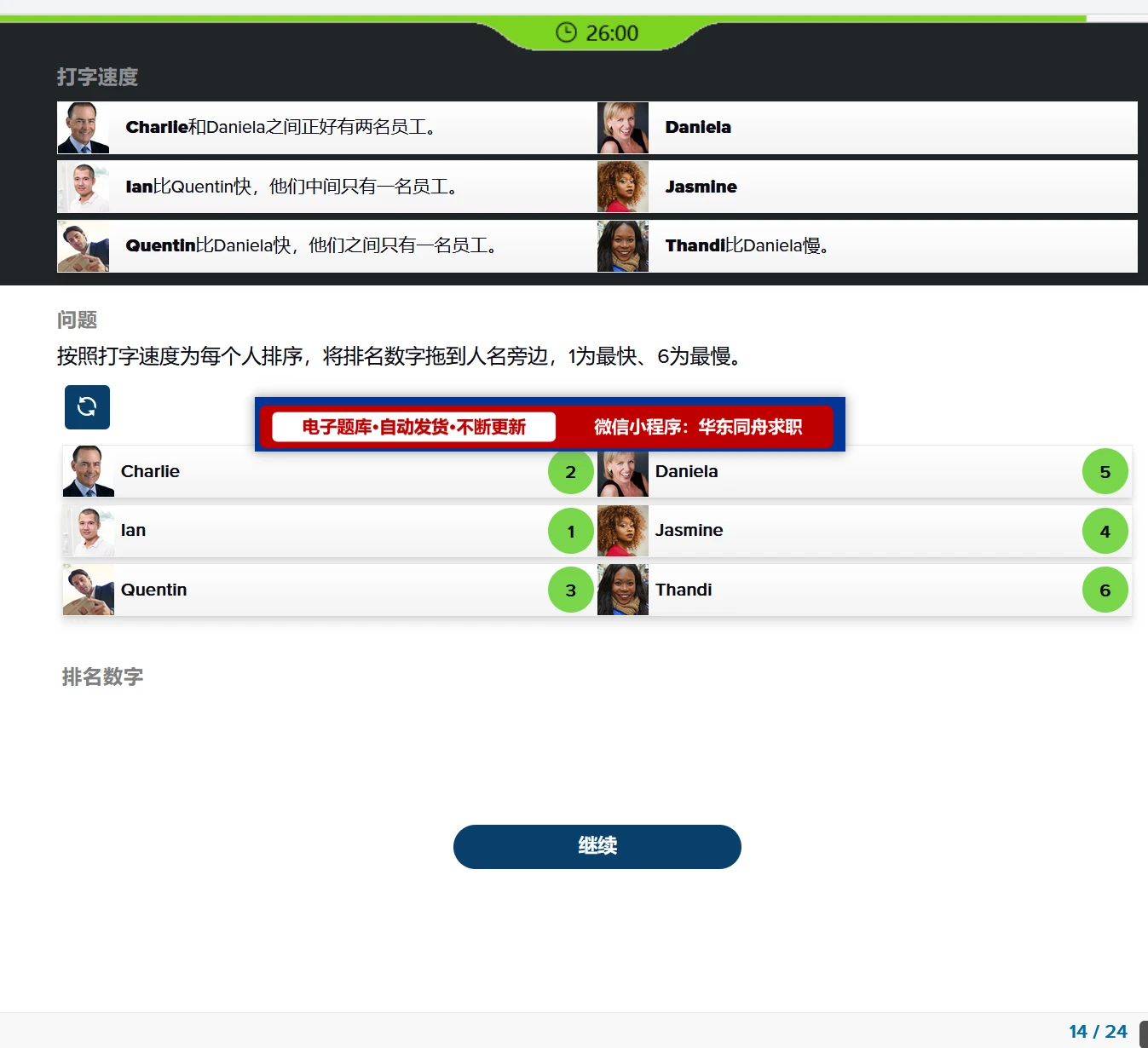
一、问题场景:
实际生产环境总存在很多kafka集群跨网段的问题。kafka集群可能存在多个网卡,对应多个网段。不同网段之间需要同时与集群通信,即跨网段生产消费问题。
单机
# broker 的唯一标识符,在 Kafka 集群中必须唯一
broker.id=0
# Kafka 服务监听的地址和端口,这里使用明文协议监听在 10.168.200.250 的 9092 端口
listeners=PLAINTEXT://10.168.200.250:9092
# 用于处理网络请求的线程数
num.network.threads=5
# 用于执行磁盘 I/O 操作的线程数
num.io.threads=8
# 套接字发送缓冲区大小,单位为字节
socket.send.buffer.bytes=102400
# 套接字接收缓冲区大小,单位为字节
socket.receive.buffer.bytes=102400
# 单个请求的最大字节数
socket.request.max.bytes=104857600
# Kafka 日志文件的存储目录
log.dirs=/home/logs/kafka
# 每个主题的默认分区数量
num.partitions=1
# 每个数据目录用于恢复的线程数
num.recovery.threads.per.data.dir=1
# 偏移量主题的副本因子,决定了数据的冗余度
offsets.topic.replication.factor=1
# 事务状态日志的副本因子
transaction.state.log.replication.factor=1
# 事务状态日志的最小同步副本数量
transaction.state.log.min.isr=1
# 日志保留的小时数,超过这个时间的日志将被清理
log.retention.hours=24
# 日志清理策略,这里设置为删除旧日志
log.cleanup.policy=delete
# 日志段的大小,单位为字节,当一个日志段达到这个大小后会创建新的日志段
log.segment.bytes=1073741824
# 检查日志保留策略的时间间隔,单位为毫秒
log.retention.check.interval.ms=300000
# 连接 Zookeeper 的地址,这里是连接本地的 2181 端口
zookeeper.connect=localhost:2181
# 连接 Zookeeper 的超时时间,单位为毫秒
zookeeper.connection.timeout.ms=18000
# 消费者组初始平衡的延迟时间,单位为毫秒,设置为 0 表示不延迟
group.initial.rebalance.delay.ms=0
多网段第一版 不行 你们可以试试
# broker 的唯一标识符,在 Kafka 集群中必须唯一
broker.id=0
# Kafka 服务监听的地址和端口,这里使用明文协议监听在 10.168.200.250 的 9092 端口
listeners=PLAINTEXT://10.168.200.250:9092,PLAINTEXT://10.168.201.250:9092
# Listener name, hostname and port the broker will advertise to clients.
# If not set, it uses the value for "listeners".
#remote visit
advertised.listeners=PLAINTEXT://10.168.200.250:9092,PLAINTEXT://10.168.201.250:9092
# 用于处理网络请求的线程数
num.network.threads=5
# 用于执行磁盘 I/O 操作的线程数
num.io.threads=8
# 套接字发送缓冲区大小,单位为字节
socket.send.buffer.bytes=102400
# 套接字接收缓冲区大小,单位为字节
socket.receive.buffer.bytes=102400
# 单个请求的最大字节数
socket.request.max.bytes=104857600
# Kafka 日志文件的存储目录
log.dirs=/home/logs/kafka
# 每个主题的默认分区数量
num.partitions=1
# 每个数据目录用于恢复的线程数
num.recovery.threads.per.data.dir=1
# 偏移量主题的副本因子,决定了数据的冗余度
offsets.topic.replication.factor=1
# 事务状态日志的副本因子
transaction.state.log.replication.factor=1
# 事务状态日志的最小同步副本数量
transaction.state.log.min.isr=1
# 日志保留的小时数,超过这个时间的日志将被清理
log.retention.hours=24
# 日志清理策略,这里设置为删除旧日志
log.cleanup.policy=delete
# 日志段的大小,单位为字节,当一个日志段达到这个大小后会创建新的日志段
log.segment.bytes=1073741824
# 检查日志保留策略的时间间隔,单位为毫秒
log.retention.check.interval.ms=300000
# 连接 Zookeeper 的地址,这里是连接本地的 2181 端口
zookeeper.connect=localhost:2181
# 连接 Zookeeper 的超时时间,单位为毫秒
zookeeper.connection.timeout.ms=18000
# 消费者组初始平衡的延迟时间,单位为毫秒,设置为 0 表示不延迟
group.initial.rebalance.delay.ms=0
多网段第二版 失败 你们可以试试
broker 的唯一标识符,在 Kafka 集群中必须唯一
broker.id=0
# Kafka 服务监听的地址和端口,这里使用明文协议监听在 10.168.200.250 的 9092 端口
listeners=PLAINTEXT://0.0.0.0:9092
# 配置 Kafka 广播给客户端的地址和端口
advertised.listeners=PLAINTEXT://10.168.200.250:9092,PLAINTEXT://10.168.201.250:9092
# 用于处理网络请求的线程数
num.network.threads=5
# 用于执行磁盘 I/O 操作的线程数
num.io.threads=8
# 套接字发送缓冲区大小,单位为字节
socket.send.buffer.bytes=102400
# 套接字接收缓冲区大小,单位为字节
socket.receive.buffer.bytes=102400
# 单个请求的最大字节数
socket.request.max.bytes=104857600
# Kafka 日志文件的存储目录
log.dirs=/home/logs/kafka
# 每个主题的默认分区数量
num.partitions=1
# 每个数据目录用于恢复的线程数
num.recovery.threads.per.data.dir=1
# 偏移量主题的副本因子,决定了数据的冗余度
offsets.topic.replication.factor=1
# 事务状态日志的副本因子
transaction.state.log.replication.factor=1
# 事务状态日志的最小同步副本数量
transaction.state.log.min.isr=1
# 日志保留的小时数,超过这个时间的日志将被清理
log.retention.hours=24
# 日志清理策略,这里设置为删除旧日志
log.cleanup.policy=delete
# 日志段的大小,单位为字节,当一个日志段达到这个大小后会创建新的日志段
log.segment.bytes=1073741824
# 检查日志保留策略的时间间隔,单位为毫秒
log.retention.check.interval.ms=300000
# 连接 Zookeeper 的地址,这里是连接本地的 2181 端口
zookeeper.connect=localhost:2181
# 连接 Zookeeper 的超时时间,单位为毫秒
zookeeper.connection.timeout.ms=18000
# 消费者组初始平衡的延迟时间,单位为毫秒,设置为 0 表示不延迟
group.initial.rebalance.delay.ms=0
解释
listeners=PLAINTEXT://0.0.0.0:9092:配置 Kafka 监听所有网络接口上的 9092 端口。
advertised.listeners=PLAINTEXT://10.60.200.250:9092,PLAINTEXT://10.60.201.250:9092:配置 Kafka 广播给客户端的地址和端口。客户端连接时会使用这些地址。
第三版 亲测OK
# broker 的唯一标识符,在 Kafka 集群中必须唯一
broker.id=0
# 配置 Kafka 监听的地址和端口
listeners=INTERNAL://10.168.200.250:9093,EXTERNAL://10.168.201.250:9092
# 配置 Kafka 广播给客户端的地址和端口
advertised.listeners=INTERNAL://10.168.200.250:9093,EXTERNAL://10.168.201.250:9092
# 指定 Kafka broker 之间的通信监听器
inter.broker.listener.name=INTERNAL
# Maps listener names to security protocols, the default is for them to be the same. See the config documentation for more details
listener.security.protocol.map=INTERNAL:PLAINTEXT,EXTERNAL:PLAINTEXT
# 用于处理网络请求的线程数
num.network.threads=5
# 用于执行磁盘 I/O 操作的线程数
num.io.threads=8
# 套接字发送缓冲区大小,单位为字节
socket.send.buffer.bytes=102400
# 套接字接收缓冲区大小,单位为字节
socket.receive.buffer.bytes=102400
# 单个请求的最大字节数
socket.request.max.bytes=104857600
# Kafka 日志文件的存储目录
log.dirs=/home/logs/kafka
# 每个主题的默认分区数量
num.partitions=1
# 每个数据目录用于恢复的线程数
num.recovery.threads.per.data.dir=1
# 偏移量主题的副本因子,决定了数据的冗余度
offsets.topic.replication.factor=1
# 事务状态日志的副本因子
transaction.state.log.replication.factor=1
# 事务状态日志的最小同步副本数量
transaction.state.log.min.isr=1
# 日志保留的小时数,超过这个时间的日志将被清理
log.retention.hours=24
# 日志清理策略,这里设置为删除旧日志
log.cleanup.policy=delete
# 日志段的大小,单位为字节,当一个日志段达到这个大小后会创建新的日志段
log.segment.bytes=1073741824
# 检查日志保留策略的时间间隔,单位为毫秒
log.retention.check.interval.ms=300000
# 连接 Zookeeper 的地址,这里是连接本地的 2181 端口
zookeeper.connect=localhost:2181
# 连接 Zookeeper 的超时时间,单位为毫秒
zookeeper.connection.timeout.ms=18000
# 消费者组初始平衡的延迟时间,单位为毫秒,设置为 0 表示不延迟
group.initial.rebalance.delay.ms=0