在当今数据驱动的世界中,机器学习(Machine Learning, ML)正逐渐成为解决问题的重要工具。在众多机器学习任务中,目标分类(Classification)算法尤其受到关注。本文将深入探讨目标分类算法的基本概念、常见类型、应用场景以及实际案例,帮助读者全面理解这一重要主题。
一、什么是目标分类?
目标分类是机器学习中的一种监督学习任务,其目标是根据输入数据的特征将数据点分配到预定义的类别中。与回归任务不同,分类任务的输出是离散的标签。例如,在垃圾邮件检测中,电子邮件被分为“垃圾邮件”或“非垃圾邮件”。

二、常见目标分类算法
1. 逻辑回归(Logistic Regression)

逻辑回归是一种广泛使用的线性分类算法,虽然名字中有“回归”二字,但它主要用于分类任务。逻辑回归的核心思想是利用逻辑函数(Sigmoid函数)将线性组合的输入特征映射到0到1之间的概率值。通过设定一个阈值(通常为0.5),可以将概率值转化为类别标签。
数学原理: 逻辑回归的目标是找到一个最佳的线性模型,形式为: [ P(Y=1|X) = \frac{1}{1 + e^{-(\beta_0 + \beta_1X_1 + \beta_2X_2 + ... + \beta_nX_n)}} ] 其中,(Y)是目标变量,(X)是特征,(\beta)是模型参数。
优缺点:
- 优点:易于实现和解释,适合处理线性可分的数据,计算效率高。
- 缺点:对特征的线性假设较强,处理非线性数据时效果较差,容易受到异常值的影响。
应用案例:在客户流失预测中,可以使用逻辑回归分析客户的使用时长、购买频率等特征,预测客户是否会流失。
2. 支持向量机(Support Vector Machine, SVM)

支持向量机是一种强大的分类算法,尤其在处理高维数据时表现优异。SVM试图在不同类别之间找到一个最优的超平面,使得各类别之间的间隔最大化。支持向量机不仅可以处理线性可分的问题,还可以通过引入核函数(Kernel Trick)处理非线性问题。
核心概念:
- 超平面:在特征空间中划分不同类别的边界。
- 支持向量:离超平面最近的样本点,它们对超平面的构建起到关键作用。
优缺点:
- 优点:在高维空间中表现良好,能够有效处理非线性数据,且不容易过拟合。
- 缺点:对参数选择和核函数的选择敏感,计算复杂度较高,训练时间较长。
应用案例:在文本分类中,SVM可以有效区分垃圾邮件和正常邮件。通过将文本数据转换为特征向量,SVM能够找到最佳的分类边界。
3. 决策树(Decision Tree)

决策树是一种基于树形结构的分类算法,通过对特征进行条件判断来进行分类。每个内部节点代表一个特征,每个分支代表特征的一个取值,而每个叶子节点代表最终的分类结果。决策树的构建通常采用贪心算法,选择最能区分数据的特征进行分裂。
关键指标:
- 信息增益:用于衡量特征对分类的贡献。
- 基尼指数:衡量样本的纯度,值越小表示样本越纯。
优缺点:
- 优点:易于理解和可视化,能够处理非线性关系,适用于类别型和数值型特征。
- 缺点:容易过拟合,尤其是在树深度较大时,且对噪声敏感。
应用案例:在客户信用评分中,决策树可以通过客户的收入、信用历史、贷款情况等特征,逐步分裂出客户的信用等级。
4. 随机森林(Random Forest)

随机森林是集成学习的一种方法,通过构建多个决策树并结合它们的预测结果来提高分类性能。每棵树都是在随机选择的特征子集上训练的,最终通过投票机制决定输出类别。这种方法有效降低了过拟合的风险,提高了模型的鲁棒性。
优缺点:
- 优点:抗过拟合能力强,能够处理高维特征,适应性强。
- 缺点:模型较大,不易于解释,训练和预测时间较长。
应用案例:在医疗领域,随机森林可以用于疾病预测,通过综合患者的多项健康指标(如血压、胆固醇水平等)来判断其患病风险。
5. 神经网络(Neural Networks)
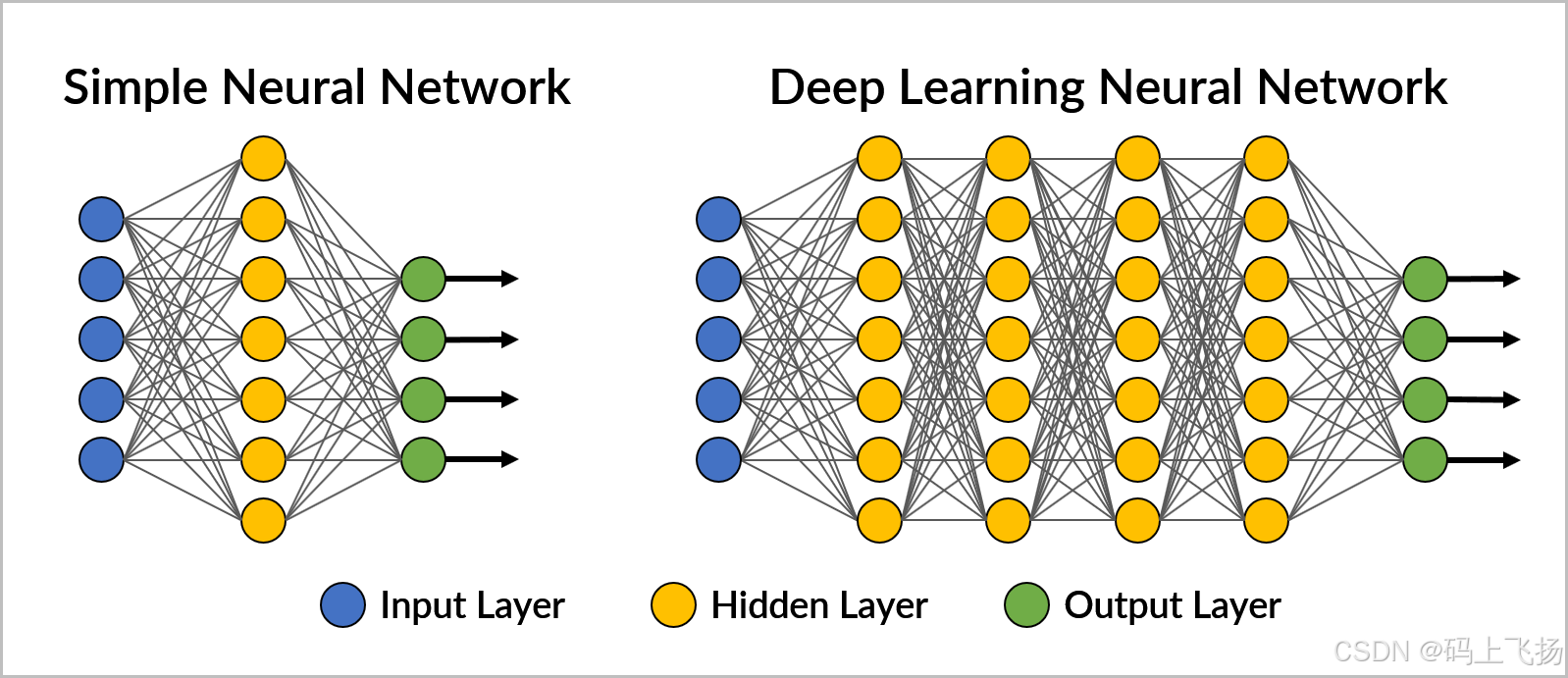
神经网络是一种模拟人脑神经元连接的分类算法,能够通过多层次的非线性变换来学习复杂的模式。常见的神经网络结构包括全连接网络、卷积神经网络(CNN)和循环神经网络(RNN)。其中,CNN在图像分类任务中表现尤为突出,RNN则在序列数据处理(如文本和时间序列)中应用广泛。
工作原理:
- 前向传播:输入数据经过每一层的加权和激活函数处理,最终输出结果。
- 反向传播:通过计算损失函数的梯度,更新网络参数,以最小化预测误差。
优缺点:
- 优点:能够自动提取特征,适合处理复杂的非线性关系,具有较强的泛化能力。
- 缺点:训练时间较长,参数调整复杂,对数据量和计算资源要求高。
应用案例:在自动驾驶中,卷积神经网络被广泛应用于识别道路标志和行人,从而实现安全的自动驾驶决策。
三、如何选择合适的分类算法?
选择合适的分类算法通常取决于以下几个因素:
- 数据规模:小数据集适合逻辑回归和决策树,大数据集可以考虑随机森林和神经网络。
- 特征类型:数值型特征适合逻辑回归和SVM,类别型特征则更适合决策树。
- 模型解释性:如果需要可解释性,决策树和逻辑回归是较好的选择;若不需要,则可以使用随机森林和神经网络。
- 计算资源:神经网络通常需要更多的计算资源,而逻辑回归和决策树相对较轻。
四、算法性能比较
在选择目标分类算法时,了解不同算法的性能是至关重要的。以下是从多个角度对常见分类算法进行比较,包括准确率、训练时间、可解释性、抗过拟合能力和适用场景。我们通过表格的方式来清晰地展示这些特征。
性能比较维度
- 准确率(Accuracy):指模型在测试集上正确分类的比例。
- 训练时间(Training Time):算法在训练模型上所需的时间。
- 可解释性(Interpretability):模型的决策过程是否容易理解。
- 抗过拟合能力(Overfitting Resistance):模型在新数据上的泛化能力。
- 适用场景(Use Cases):算法适合解决的问题类型。
算法性能比较表
| 分类算法 | 准确率 | 训练时间 | 可解释性 | 抗过拟合能力 | 适用场景 |
|---|---|---|---|---|---|
| 逻辑回归 | 中等 | 快速 | 高 | 较低 | 二分类问题,线性可分数据 |
| 支持向量机 | 高 | 中等 | 中 | 中等 | 文本分类,图像识别 |
| 决策树 | 中等 | 快速 | 高 | 较低 | 分类问题,医疗诊断 |
| 随机森林 | 高 | 中等 | 中 | 高 | 特征较多的复杂数据 |
| 神经网络 | 最高 | 较长 | 低 | 高 | 图像处理,语音识别,复杂模式 |
详细分析
-
准确率:
- 逻辑回归和决策树在简单线性可分数据上表现良好,但在复杂数据上可能不如支持向量机和随机森林。神经网络在处理大量数据时能达到最高的准确率,但需要适当的调参。
-
训练时间:
- 逻辑回归和决策树训练时间较短,适合快速实验。神经网络的训练时间较长,尤其是在大数据集上。
-
可解释性:
- 逻辑回归和决策树具有较高的可解释性,决策过程清晰。而神经网络由于其复杂的结构,通常被认为是“黑箱”模型,较难解释其决策过程。
-
抗过拟合能力:
- 随机森林和神经网络在抗过拟合能力上表现优异,尤其在处理高维数据时。相对而言,逻辑回归和决策树容易过拟合。
-
适用场景:
- 各算法适用的场景有所不同,逻辑回归适合线性可分问题,支持向量机在文本和图像分类中表现突出,随机森林适用于特征较多的复杂数据,而神经网络则在处理图像、语音等复杂模式时表现最佳。
通过上述比较,您可以根据具体的需求和数据特征,选择最适合的分类算法。希望这一章节能够为您在算法选择上提供有价值的参考!如果您有进一步的问题或想法,欢迎在评论区讨论。
五、结论
目标分类算法在机器学习中扮演着至关重要的角色。通过理解不同算法的特点、应用场景及其优势,您可以更好地选择适合您需求的算法。随着数据量的不断增加和计算能力的提升,目标分类算法的应用将更加广泛,为各行各业带来更多的创新和变革。