Abstract
本文提出了一种名为DENSER的高效方法,该方法利用三维高斯点云(3DGS)技术来重建动态城市环境。尽管通过神经辐射场(NeRF)隐式方法和3DGS显式方法的若干场景重建技术在较复杂的动态场景中展示了出色的效果,但在建模前景物体的动态外观时仍存在挑战,特别是在处理远距离动态物体时。为此,我们提出了DENSER框架,该框架显著增强了动态物体的表现能力,能够精准建模驾驶场景中的动态物体外观。与直接使用球谐函数(SH)建模动态物体外观的方法不同,我们提出了一种基于小波动态估计SH基函数的新方法,从而在时空上实现了更优的动态物体外观表现。除了物体外观的建模,DENSER通过多个场景帧对点云进行稠密化处理,提升了物体形状的表现能力,并加速了模型训练的收敛。我们在KITTI数据集上的广泛评估表明,该方法在性能上远超现有最先进的技术。
代码地址:https://github.com/sntubix/denser
欢迎加入自动驾驶实战群
Introduction
从图像中建模动态3D城市环境具有广泛的应用,包括构建城市级别的数字孪生体和模拟环境,这些应用可以显著降低自动驾驶系统的训练和测试成本。这些应用要求高效且高保真的3D环境表示以及能够实时渲染高质量新视角的能力。模拟在开发和优化自动驾驶功能中至关重要,因为它提供了一个可控、安全且具有成本效益的测试环境。尽管传统模拟工具如CARLA、LGSVL和DeepDrive加速了自动驾驶的发展,它们都存在一个共同的限制,即与现实的差距大(sim-to-reality gap)。这种差距源于资产建模和渲染的局限性,限制了基于模型的模拟工具完全复制现实世界复杂性的能力。
为了缩小这一差距,基于NeRF和3DGS的数据驱动和逼真的技术在3D场景重建中展示了显著的能力,实现了视觉和几何上的高度真实的保真度。虽然NeRF和3DGS在静态和小规模场景的重建中表现优异,但对高度动态和复杂的大规模城市场景的重建仍是一个重大挑战。
本文提出的DENSER是一个基于场景图的框架,显著增强了动态物体的表现能力,并能够准确建模驾驶场景中动态物体的外观。与直接使用球谐函数(SH)建模动态物体外观不同,我们引入了一种基于小波动态估计SH基函数的新方法,从而在时空上实现了更优的动态物体外观表现。实验结果表明,DENSER在KITTI数据集上实现了出色的场景分解效果。
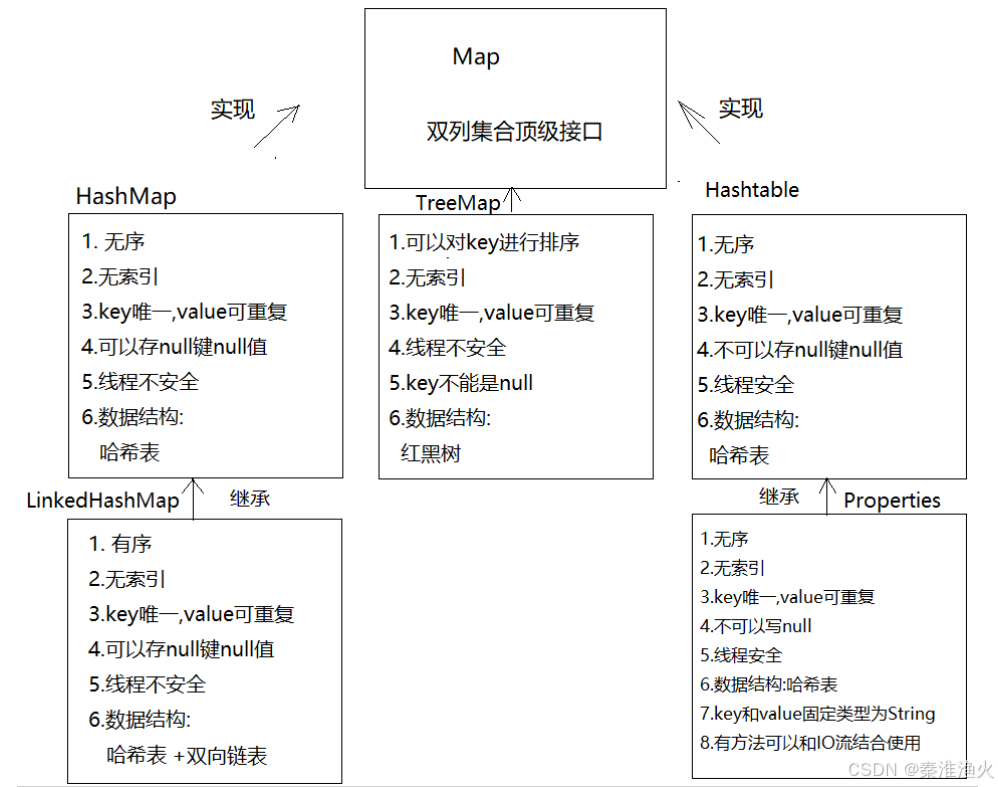
3.框架与方法
A. 预备知识
3DGS通过有限数量的3D各向异性高斯分布
![]()
明确地表示场景,每个由5元组
![]()
定义,
![]()
表示其质心,
![]()
是尺度向量,
![]()
是旋转矩阵,
![]()
是透明度,
![]()
是与视图相关的颜色,通常用一组球谐函数(SH)系数表示。高斯占据的3D体积可以表示为
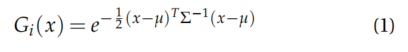
高斯
![]()
的协方差矩阵Σ可以通过旋转矩阵𝑅和尺度向量𝑆分解为
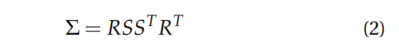
为了渲染,这些3D高斯分布被投影到2D,它们的协方差矩阵也随之转化。这包括使用仿射近似的投影变换的雅可比矩阵和视图变换𝑊计算出一个新的相机坐标系中的协方差矩阵。
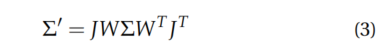
像素颜色𝑐通过使用𝑁阶2D斑点及透明度混合计算
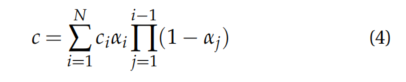
尽管3DGS在静态和以物体为中心的小场景中表现良好,但在处理包含瞬时对象和不断变化外观的场景时存在挑战。本文提出了一种通过动态估计SH系数来建模动态对象外观的框架,该方法使用小波函数从而在空间和时间上更好地表示动态对象外观。
B. 场景图表示
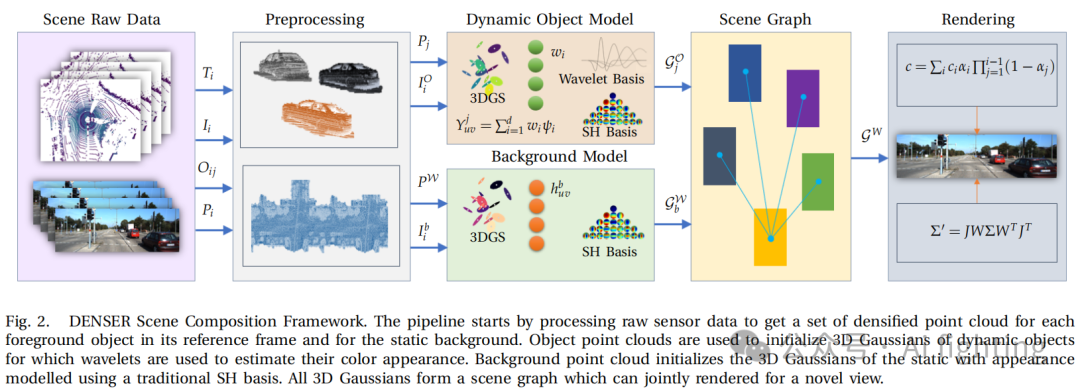
如图2所示,提出的框架基于场景图表示,它同时包含静态背景和动态对象。在DENSER中,场景分解为代表环境中静态实体(如道路和建筑物)的背景节点和代表场景中动态对象(例如车辆)的对象节点。每个节点都由一组3D高斯分布表示,如第III-A节所述,每个节点分别进行优化。背景节点直接在世界参考系𝑊中优化,而对象节点则在它们的对象参考系中优化,可以转换到世界参考系。所有背景节点和动态对象节点的高斯分布进行合并渲染。
设
![]()
为表示背景节点的3D高斯分布集,
![]()
为表示对象𝑖在其参考系中的3D高斯分布集。给定对象𝑖的轨迹
![]()
,可以提取表示对象𝑖在时间𝑡处位置和方向的姿态变换矩阵
![]()
。假设对象的几何形状在不同姿态下没有变化,可以通过使用齐次变换矩阵
![]()
将
![]()
转换到世界参考系。
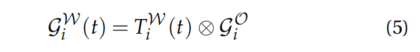
用于渲染的所有高斯分布集可以通过将静态背景节点的高斯分布集和经过转换的动态对象节点的高斯分布集进行拼接得到,
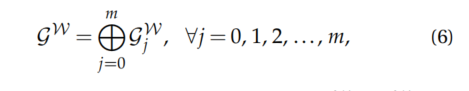
其中𝑗=0表示背景,即
![]()
,其余高斯分布集为动态对象节点的高斯分布集。
C. 场景分解
本文通过增强瞬时对象外观建模来改进现有的3DGS复合场景重建,生成更真实和一致的场景表示。DENSER的输入为𝑛帧序列。帧由𝑚个跟踪对象集、传感器姿态,LiDAR点云,相机图像集,以及可选的深度图组成,i∈{1,2,…,n}。每一帧中的对象,
![]()
,通常由边界框、跟踪标识符和对象类别定义,j∈{1,2,…,m}。基于这些输入,DENSER首先在世界参考系𝑊中累积所有帧的点云,并使用对象边界框过滤前景对象的点。生成的点云
![]()
,用于初始化背景
![]()
的3D高斯分布,包括位置,透明度,协方差矩阵,以及对应的旋转矩阵
![]()
和尺度。
此外,背景中的每个高斯分布分配了一组SH系数
![]()
![]()
,其中𝑈和𝑉由定义视图相关颜色的SH基阶数决定,
![]()
,θ和𝜙定义了视图方向。对于静态场景,原始3DGS已经能够高效地表示场景,但在包含动态实体和变化外观的场景中,它表现不佳。仅使用SH系数表示瞬时对象的外观往往是不足的。主要原因是SH对场景中对象位置变化的敏感性,以及这些运动引起的阴影和光照变化。为了保持一致的视觉外观,DENSER通过(i)在不同帧之间的对象点云密集化来解决这一问题,这不仅确保了3D高斯分布初始化的强先验,还减轻了姿态校准误差和数据集中的噪声测量。使用传感器姿态变换矩阵和LiDAR点云,可以通过对象的边界框定义的ROI过滤器获取对象𝑗在帧𝑖的点云
![]()
。跨所有帧拼接后得到的密集点云
![]()
用于初始化。(ii) 我们使用SH基的时间依赖近似,通过带有可优化的尺度和平移参数的正交小波基捕捉动态对象的变化外观。在DENSER中,使用Ricker小波。
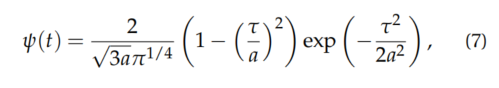
where a 是尺度参数,τ = t − b,b 是平移参数。物体 j 的 SH基函数
![]()
,使用子小波的线性组合来近似,公式如下
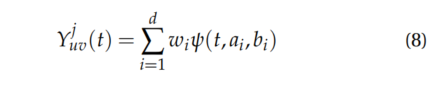
其中,d 是小波基的维度,也是一个可优化的参数。小波即使在有限维度的小波基下,也能捕捉到高频内容,因此在捕捉动态物体细节以及变化的外观上表现显著。本文的创新贡献主要体现在 (i) 和 (ii) 两个方面。
D. 优化
为了优化我们的场景,我们采用了一个复合损失函数 L,定义如下
![]()
其中,
![]()
代表重建损失,确保预测图像 Ipred 与真实图像密切匹配。通过 L1 损失和结构相似性指数(SSIM)损失的组合来实现这一点。L1 损失为
![]()
,而 SSIM 损失
![]()
为
![]()
,其中 SSIM 衡量两张图像之间的相似性,考虑到亮度、对比度和结构的变化。SSIM 评估图像质量,并对结构信息更为敏感。总的颜色损失 Lcolor 通过 L1 和 LSSIM 定义为
![]()
。其中是一个参数,用于鼓励 和
![]()
之间的结构对齐。
![]()
是单目深度损失,确保预测的深度图与观察到的深度信息一致。该项有助于保持场景的几何一致性。深度损失
![]()
计算为预测深度
![]()
与真实深度
![]()
图之间的 L1 损失,即
![]()
。Laccum 是累积损失,用于惩罚累积的物体占用概率偏离期望分布的情况。具体而言,它包括一个基于熵的损失,以确保每个物体的占用概率均衡分布,公式为
![]()
,其中 β 代表物体占用概率。这个复合损失函数促进了外观、几何形状和占用概率的同时优化,确保场景的连贯和逼真的重建。
Experiment
1 结果与评估
我们对比了我们的方法与其他最先进方法的定性和定量结果。这些方法包括:
(1)NSG ,它使用多平面图像表示背景,并利用每个物体学习的潜在编码与共享解码器来建模移动物体。
(2)MARS ,它基于 Nerfstudio [31] 构建场景图。
(3)3D Gaussians ,用一组各向异性高斯来建模场景。
(4)StreetGaussian ,它将前景和背景表示为复合3D高斯。
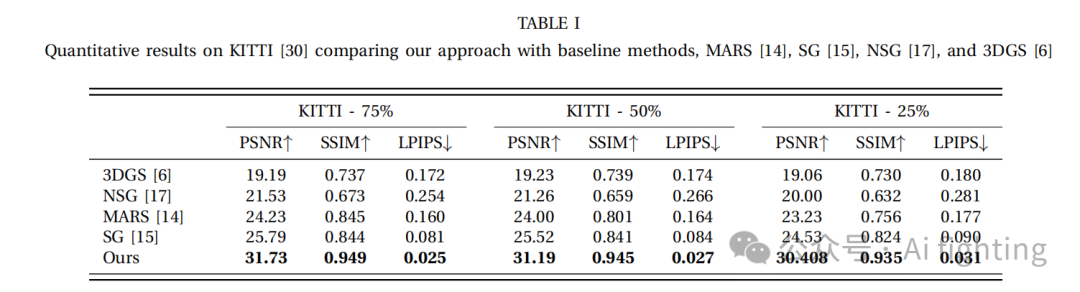
表 1 展示了我们的方法与基线方法的定量对比结果。由于我们严格遵循 MARS 和 StreetGaussians(SG)中的相同程序和设置,因此我们可以合法地引用它们的结果进行比较。渲染图像分辨率为 1242×375。我们的方法显著优于之前的方法。图像重建设置中的训练集和测试集是相同的,而在新视角合成中,我们渲染不包含在训练数据中的帧。具体来说,在 75% 切分中,我们保留每四帧中的一帧,在 50% 切分中,我们保留每两帧中的一帧,而在 25% 切分中,只有每四帧用于训练,这样训练集分别占据 25%、50% 和 75% 的数据。我们采用了 PSNR、SSIM 和 LPIPS 作为度量指标来评估渲染质量。我们的模型在所有指标上都取得了最好的表现。实验结果表明,DENSER 在重建动态场景方面表现优异,显著优于基线方法。结果显示,在峰值信噪比(PSNR)、结构相似性指数(SSIM)和学习感知图像块相似性(LPIPS)指标上有显著提升,详细见表 1。PSNR 和 SSIM 的改进强调了我们基于小波的方法在复杂环境中保持高保真度和结构完整性的有效性。此外,DENSER 在重建细节方面表现出色,例如在场景 0006 中卡车后方的阴影(如图 3 所示),而其他基线方法无法做到这一点。

2. 场景编辑应用
DENSER 实现了逼真的场景编辑,例如交换、平移和旋转车辆,以创建多样且逼真的场景。这种多功能性使得自动系统能够提升其性能,并增强其在处理复杂现实世界条件时的能力,从日常交通到紧急情况。
物体移除:要移除一个物体,我们只需构建一个删除掩码,有效过滤掉与待移除物体相关的高斯参数。删除掩码随后应用于训练模型的高斯参数,移除与不需要物体相关的属性,如图 5 所示。

物体交换:在我们的表示框架中交换车辆是一个简单的过程,只需交换与两个目标车辆关联的唯一轨迹 ID。这种操作会动态改变场景,其中一个车辆将假定与其交换车辆的空间属性,特别是位置和方向,如图 6 所示。

物体旋转和平移:我们通过动态调整物体在 3D 环境中的位置和朝向来实现旋转和平移修改。给定某一时间步 i 下的物体位置旋转矩阵,我们可以修改平移和旋转,以实现所需的运动操作。为了说明这一点,可以在运动平面内移动平移分量以实现平移,而对于旋转,我们可以围绕运动平面的法线改变旋转角度,并计算相应的新旋转矩阵,替换物体,如图 7 所示。

轨迹改变:轨迹定义为一系列姿态。编辑场景以使物体沿着轨迹运动时,不仅可以在两个配置之间概括旋转和平移的变化,还可以将这种变化应用于时间段内,从而获得平滑的平移和旋转变化,正如图 8 所示。

结论
1.本文提出了DENSER框架,使用小波动态估计SH基数,而不是直接使用球谐函数来建模动态对象的外观。这种方法更好地捕捉了动态对象在空间和时间上的外观变化,从而增强了对动态物体的表示能力。
2.DENSER通过跨多个场景帧的点云致密化来增强物体形状的表示,这有助于在模型训练过程中实现更快的收敛,从而提高了场景重建的效率。
3.DENSER在KITTI数据集上进行了广泛的评估,结果表明该方法在动态场景重建方面大幅超越了现有的最先进技术,证明了其有效性。
文章引用:DENSER: 3D Gaussians Splatting for Scene Reconstruction of Dynamic Urban Environments
最后别忘了,帮忙点“在看”。
您的点赞,在看,是我创作的动力。
AiFighing是全网第一且唯一以代码、项目的形式讲解自动驾驶感知方向的关键技术。
扫码加入自动驾驶实战知识星球,即可跟学习自动驾驶感知项目:环境配置,算法原理,算法训练,代码理解等。
关注我的公众号auto_driver_ai(Ai fighting), 第一时间获取更新内容。