传统上,预测这些趋势涉及针对每种情况的专门模型。最近的进展指向了可以处理广泛预测问题的"基础模型"。
这是9月份刚刚发布的论文TimeMOE。它是一种新型的时间序列预测基础模型,“专家混合”(Mixture of Experts, MOE)在大语言模型中已经有了很大的发展,现在它已经来到了时间序列。
想象一下有一个专家团队,每个专家都有自己的专长。TimeMOE的工作原理与此类似。它不是为每个预测使用整个模型,而是只激活最适合特定任务的一小部分"专家"。这使得TimeMOE可以扩展到数十亿个参数,同时保持效率。
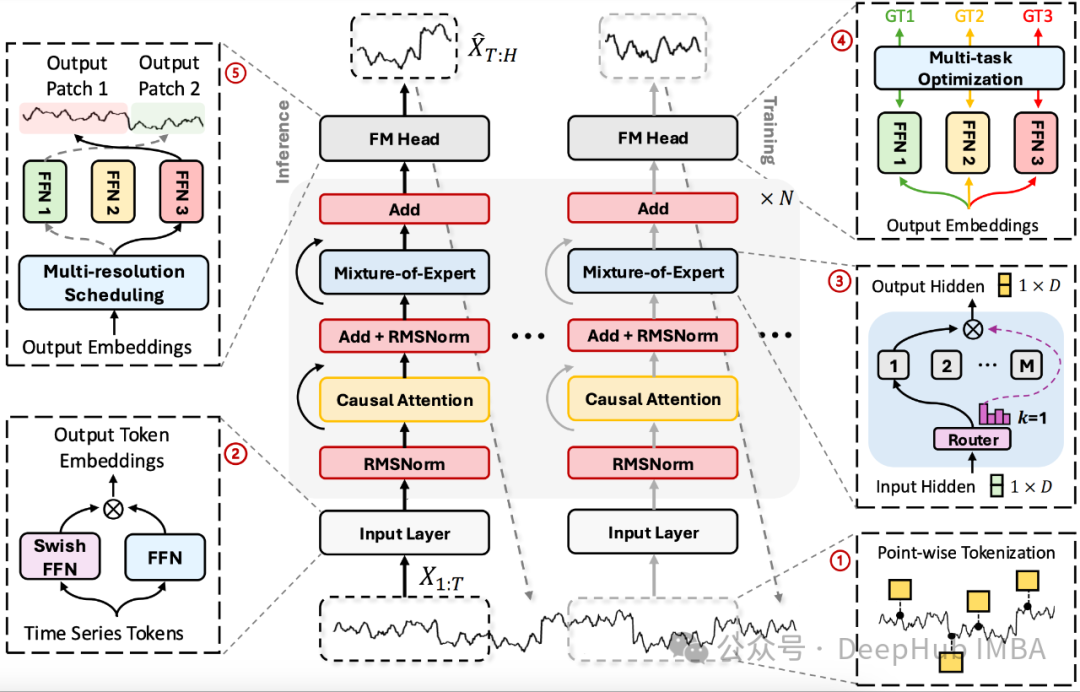
TimeMOE的研究目的主要包括:
- 开发一种可扩展的、统一的时间序列预测基础模型架构。
- 通过利用稀疏混合专家(MOE)设计,在提高模型能力的同时降低计算成本。
- 探索时间序列领域的缩放定律,验证增加模型规模和训练数据量是否能持续改善性能。
- 创建一个大规模、高质量的时间序列数据集(Time-300B),用于预训练更强大的预测模型。
- 在零样本和微调场景下评估模型的通用预测能力。
关键概念
- 逐点标记化(Point-wise tokenization): TimeMOE将时间序列数据分解为单个点,确保它可以处理任何长度的序列。
- 混合专家Transformer(Mixture-of-Experts Transformer): 这是TimeMOE的核心。它是一种专门为时间序列数据设计的人工神经网络。TimeMOE不是为每个预测使用整个网络,而是只激活网络内的一小部分"专家",从而提高效率。
- 多分辨率预测(Multi-resolution forecasting): TimeMOE可以在各种时间尺度上预测未来值(如预测明天或下周的天气)。这种灵活性使其适用于更广泛的预测任务。
TimeMOE的优势
- 可扩展性: TimeMOE可以扩展到数十亿个参数,而不会牺牲推理效率。
- 效率: MOE架构允许TimeMOE仅为每个预测激活网络的一个子集,从而减少计算负载。
- 灵活性: TimeMOE可以处理任何长度的序列,并在各种时间尺度上预测未来值。
- 准确性: 考虑到模型的效率,TimeMOE在预测准确性方面始终优于现有模型。
- 泛化能力: TimeMOE在Time-300B数据集上的训练使其能够在未见过的数据上表现良好(零样本学习)。
通过结合这些优势,TimeMOE为广泛的时间序列预测应用提供了一个有前景的解决方案。
详细改进描述
TimeMOE的主要改进集中在以下几个方面:
- 稀疏混合专家(MOE)架构:- TimeMOE采用了一种稀疏的MOE设计,每个输入时间序列标记只激活一小部分专家网络。- 这种设计显著提高了计算效率,同时保持了高模型容量。- MOE层取代了传统Transformer中的前馈网络(FFN),引入了动态路由机制。
- 多分辨率预测头:- TimeMOE引入了一种新颖的多分辨率预测头,能够同时在多个尺度上进行预测。- 这种设计增强了模型的灵活性,使其能够生成跨越各种时间范围的预测。- 通过多分辨率集成学习,提高了预测的鲁棒性。
- 大规模预训练:- 研究者构建了Time-300B数据集,包含超过3000亿个时间点,跨越9个领域。- TimeMOE在这个大规模数据集上进行预训练,显著提升了模型的泛化能力。
- 灵活的输入处理:- 采用逐点标记化,确保模型可以处理任意长度的输入序列。- 使用旋转位置编码(RoPE),提高了模型对序列长度的适应性和外推能力。
- 优化的损失函数:- 使用Huber损失函数,提高了模型对异常值的鲁棒性。- 引入辅助平衡损失,解决MOE架构中的负载不平衡问题。
- 可扩展性设计:- TimeMOE首次将时间序列基础模型扩展到24亿参数,其中11亿参数被激活。- 验证了时间序列领域的缩放定律,证明增加模型规模和训练数据量能持续改善性能。
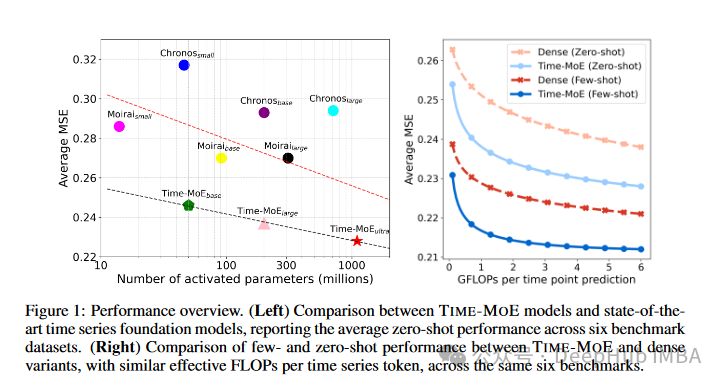
TimeMOE与其他基线模型的性能对比
性能指标介绍
研究者使用了多个指标来评估TimeMOE的性能:
- 平均平方误差(MSE)和平均绝对误差(MAE):- 这两个指标用于衡量预测值与实际值之间的差异。- 在零样本和微调场景下,TimeMOE在这些指标上都显著优于基线模型。
- 计算效率:- 与同等规模的密集模型相比,TimeMOE在训练成本上平均降低了78%,推理成本降低了39%。
- 零样本性能:- 在六个基准数据集上的零样本预测任务中,TimeMOE平均减少了23%的预测误差。
- 微调性能:- 在下游任务的微调场景中,TimeMOE平均减少了25%的预测误差。
- 模型规模缩放:- 研究者展示了随着模型规模从5000万参数扩展到24亿参数,性能持续提升。
- 多分辨率预测:- TimeMOE能够在{96, 192, 336, 720}等多个预测范围内保持优秀性能。
- 跨领域泛化能力:- 在能源、天气、交通等多个领域的数据集上,TimeMOE都展现出强大的泛化能力。
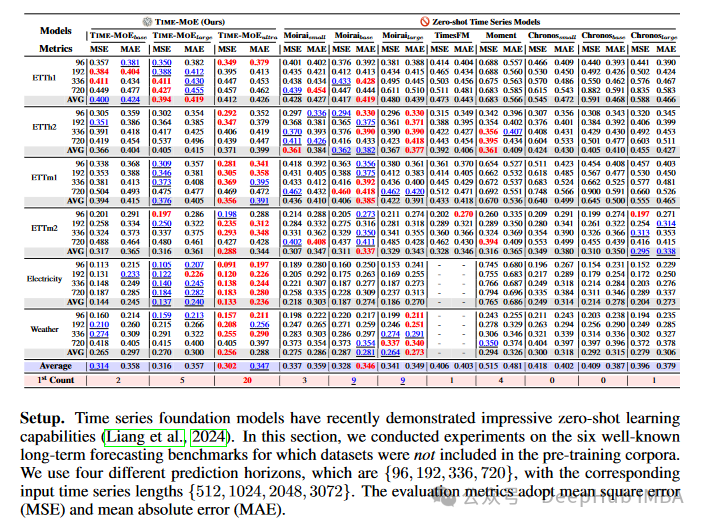
这些性能指标全面展示了TimeMOE在准确性、效率和泛化能力方面的优势,证明了它作为一个通用时间序列预测基础模型的潜力。
代码实现
以下是使用TimeMOE进行预测的基本代码示例:
importtorch
fromtransformersimportAutoModelForCausalLM
context_length=12
seqs=torch.randn(2, context_length) # tensor shape is [batch_size, context_length]
model=AutoModelForCausalLM.from_pretrained(
'Maple728/TimeMoE-50M',
device_map="cpu", # use "cpu" for CPU inference, and "cuda" for GPU inference.
trust_remote_code=True,
)
# normalize seqs
mean, std=seqs.mean(dim=-1, keepdim=True), seqs.std(dim=-1, keepdim=True)
normed_seqs= (seqs-mean) /std
# forecast
prediction_length=6
output=model.generate(normed_seqs, max_new_tokens=prediction_length) # shape is [batch_size, 12 + 6]
normed_predictions=output[:, -prediction_length:] # shape is [batch_size, 6]
# inverse normalize
predictions=normed_predictions*std+mean
这段代码展示了如何加载预训练的TimeMOE模型,对输入序列进行标准化,生成预测,然后将预测结果反标准化。
总结
TimeMOE把MOE扩展到了时间序列预测的领域
通过引入稀疏混合专家设计,TimeMOE成功平衡了模型规模和计算效率。利用Time-300B数据集,TimeMOE验证了大规模预训练在时间序列领域的有效性。多分辨率预测能力使TimeMOE适用于各种预测任务和时间尺度。在多个基准测试中,TimeMOE显著超越了现有模型,尤其是在零样本学习场景下。
TimeMOE研究论文
https://avoid.overfit.cn/post/6edf19076ad7460291afb38be5dd687d






![[leetcode刷题]面试经典150题之9python哈希表详解(知识点+题合集)](https://i-blog.csdnimg.cn/direct/037be17e1bdd49fe911a51840406c312.png)












![[Redis][集群][上]详细讲解](https://i-blog.csdnimg.cn/direct/596a5e439a544bab81d2161f7010cc69.png)