目录
前言
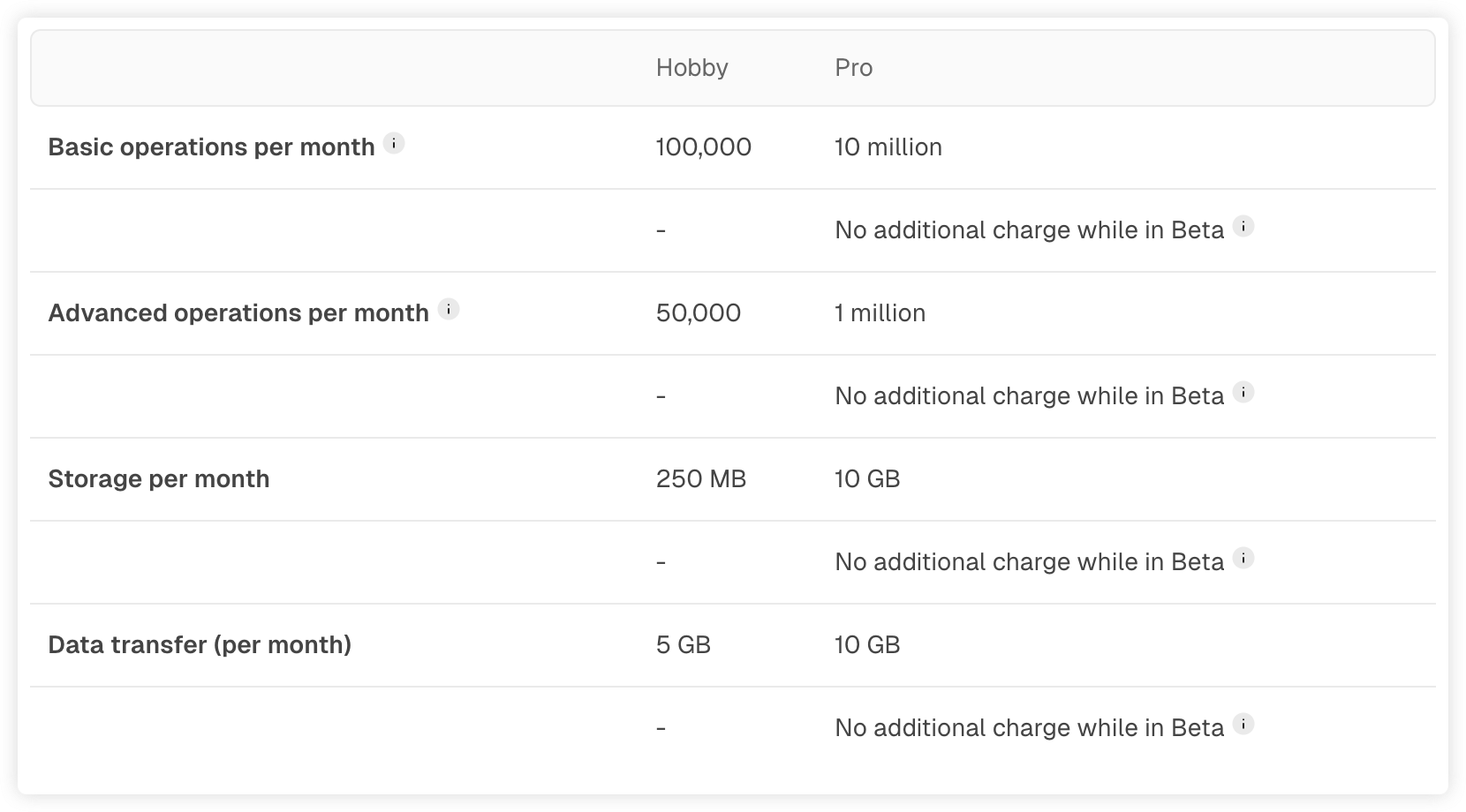
保持系统数据同步(双写问题)
消息队列消息丢失的问题
总结
前言
在当今互联网飞速发展的时代,随着业务复杂性的不断增加,消息队列作为一种重要的技术手段,越来越多地被应用于各种场景。它们不仅能有效解耦系统各部分之间的联系,还能够平衡流量峰值,提高系统的整体性能。
在本文中,我将重点分析一家医美公司的团队在使用消息队列时的奇葩做法。这家公司的技术团队选择了 Kafka 作为主要的消息队列,但在某些情况下却出现了数据未能成功消费的问题。为了应对这个挑战,他们又引入了 RocketMQ,并通过其延迟机制来弥补之前的不足。然而,这样的做法是否合理?这背后又隐藏着哪些技术思考与团队协作的缺陷?
接下来,我们将深入探讨这家公司的消息队列应用,以及其中的潜在问题与改进方案。
下面是我画的他们业务的一个架构图:

<图一>
在这个架构图中,数据首先从MySQL数据库流入“业务1”,并通过Kafka进行消息传递。然后,数据被传递到“业务2”进行处理。处理完成后,系统会判断是否成功。如果成功,则数据继续存储到MySQL中;如果未成功处理,则会将消息发送到RocketMQ进行重新处理。
这个架构是非常简单,加入了 RocketMQ 就一个诉求就是消息不丢失,真的能做到吗?其实有几个问题,第一个问题系统同步也就是双重写入问题 第二个问题就是加入RocketMQ 和不合理,下面我们逐一讲解。
保持系统数据同步(双写问题)
我们业务系统有两个双写:业务1的1和2。业务2的5和6。图中这样的设计看起来很简单但是有一些严重的问题。
先用一个流程图来说明双写严重的问题:

<图二>
在这个例子中,两个客户同时想要更新项X:
客户端l 想要将值设置为A,客户端2 想要设置为B 。两个客户端首先将新值写入数据库,然后将其写入消息队列中。由于实机不凑巧,这些请求交叉了:数据库首先看到来自客户端1 的写入,将值设置为A,然后看到来自客户端2 的写入,将值设置为B ,因此数据库中的最终值为B 。而消息队列首先看到来自客户端2 的写人,然后才是客户端1 的写人,所以消息队列中的最终值是A。这两个系统将永远不一致,即使目前还没有发生错误。
除非有一些额外的并发监测机制,或者加入版本向量或者加入分布式锁。否则甚至不会注意到并发写入,一个值悄悄覆盖另一个值。
我们可以总结到双重写入的一个问题就是值会可能被覆盖。
还有一个很难发现的问题就是客户端1或者客户端2写入数据库成功了但是写入消息队列失败了,这不是一个并发问题,这是一个容错问题,也会造成两个系统相互不一致的结果,这是致命的。确保数据库和消息队列都成功或者失败是个原子提交问题,需要用到2pc 等分布式事务相关的技术。
这两个问题都是致命的,必须解决,数据库的主从复制给我了启发,不管如何并发,从库总是订阅主库的binglog,保证了数据的一致性。我们发现我们这个例子其实可以看成两个主库的双写问题,有没有一种技术把两个主库的双写问题转成主从机制呢?那么问题不就解决了吗?还真的是有这种方案,就是CDC 技术。于是我的架构就发生了一种变化。

<图三>
CDC 技术是对系统同步的里程碑,他借助了主从的思想,软件开发工程师开始认识到日志的重要性,再也不认为,数据库复制日志的问题被认为是数据库内部实现细节,他们开始尝试解析日志,捕获数据的变化,写入时立即将更改作为一种流来发布,那么业务只需要消费这些数据就可以了。现在很多数据库都提供了CDC解决方法。mysql 在国内用的最多的是canal。前面讲过就是canal作为一个从库似的获取主库的数据,并且她集成了快照技术也就是说会记录位置的偏移量,以便在快照处理完成后,知道哪一点开始应用修改。canal 具体问题,可以参考相关的文档。
消息队列消息丢失的问题
图一我们发现了该团队用了RocketMQ和kafka 就是解决业务2消息丢失的问题,RocketMQ在哪种情况下会用到,我们将详细分析下:
只有一种情况下,就是消费者出现error 或者异常,代码能捕获到这些问题,调用RocketMQ,用它的延迟队列。其实又有集中假设:
-
如果消费者出现了代码本身的bug ,应该在测试阶段就应该发现的,或者经过压测,这是代码问题,应该避免的
-
第二种情况就是业务二入库失败了,会把消息投递到RocketMQ,用它的延迟队列过段时间数据库可能就好了,就一定能捕获吗,成功写入到RocketMQ吗?
-
如果消费者在处理一半业务就突然挂掉了还能写入到RocketMQ吗,消息还是丢失了
经过分析发现只有第二种情况可能,为了一种可能的情况,引入RocketMQ当然是不合适的,是弊端大于利,而且系统更为复杂,不仅要监控kafka 而且也要监控RocketMQ。
那么我们就想kafka 能不能让消息不丢失呢。当然是可以的呀
在消息队列的处理中,常见的情况有以下几种:
• 零次处理(At-most-once):消息可能丢失,但不会被重复处理。
• 一次处理(At-least-once):消息一定会被处理,但可能会被处理多次。
• 精确一次(Exactly-once):确保每条消息只被处理一次。
消息不丢失我们可以用 At-least-once 消息设计模式
kafka 应该从生产者,消费者,还有服务端 去讨论消息不丢失:
生产者来说:
-
使用带回调方法的API。我们就知道消息有没有成功
-
设置参数 acks=1 (-1,0,1)。-1生产者在发送消息后不等待任何确认,1 领导者(leader)在成功写入消息后发送确认。 -1 所有的副本(包括领导者和跟随者)都必须确认消息已被成功写入。
-
设置参数 retries=3。重试次数,如果次数到了还是失败,我们可以写入日志中
-
设置参数 retry.backoff.ms=300。每次重试间隔时间
服务端:
replication.factor>1。 (分区副本的个数),至少一个主分区,多个副本节点
Min.insync.replicas>1。 (isr 最少的副本数量)。
Unclean.leader.election.enable = false。 (是否能把非ISR集合中的副本选举为leader 副本)
定义:ISR 是指与当前主分区(Leader)保持同步的所有副本(Replica)。这些副本在数据写入主分区时,能够及时接收到并确认写入的数据。这是重要的,如果选择了非ISR 节点作为leader ,那么就会造成数据丢失。
消费者:
消费者是根据offset 来确定消息的消费位置,可以手动提交offset,就是业务结束的时候
Enable.auto.commit = false (手动提交偏移量)
具体的代码可以参考相关的文档。
得出了最终的架构是这样的。

总结
这篇文章我们详细介绍了cdc 技术,kafka 如何消息不丢失,同时也详细阐述了结构的不合理性以及合理性的架构是如何演变的