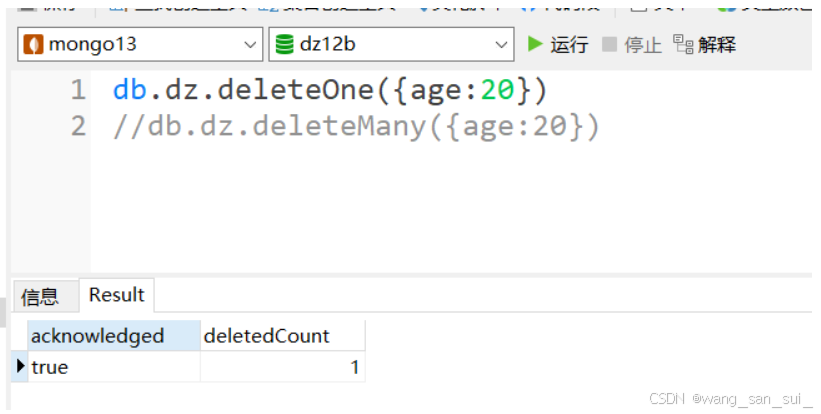
任务描述
需要在一个图中绘制多个wav文件的基频图,具体一点,绘制三种不正常的基频曲线,和一种正常的基频曲线进行对比,并且将正常的基频曲线的范围画出。
代码
import pyworld as pw
import librosa
import numpy as np
def extract_f0(wav_file):
# 读取 WAV 文件
y, sr = librosa.load(wav_file, sr=16000)
# 将音频数据类型转换为 double
y = y.astype(np.float64)
# 提取基频(F0)值
# f0, timeaxis = pw.harvest(y, sr)
pitch, t = pw.dio(
y.astype(np.float64),
sr,
frame_period= 200 / sr * 1000,
)
f0 = pw.stonemask(y.astype(np.float64), pitch, t, sr)
new_f0 = [i for i in f0 if i>0]
return new_f0
wav = ''
data_dir = ''
# 提取三种不同程度的基频(F0)值
pitch_values_file1 = extract_f0(f'{data_dir}/*/*_{wav}.wav')
pitch_values_file2 = extract_f0(f'{data_dir}/*/*_{wav}.wav')
pitch_values_file3 = extract_f0(f'{data_dir}/*/*_{wav}.wav')
# 提取所有正常的基频值
pitch_values_normal_file1 = extract_f0(f'{data_dir}/*/*/*_{wav}.wav')
pitch_values_normal_file2 = extract_f0(f'{data_dir}/*/*/*_{wav}.wav')
pitch_values_normal_file3 = extract_f0(f'{data_dir}/*/*/*_{wav}.wav')
pitch_values_normal_file4 = extract_f0(f'{data_dir}/*/*/*_{wav}.wav')
# 找到最长的正常序列长度
max_length = max(len(pitch_values_normal_file1), len(pitch_values_normal_file2), len(pitch_values_normal_file3), len(pitch_values_normal_file4))
# 使用线性插值将所有正常序列调整为相同长度
sequence1_interp = np.interp(np.linspace(0, 1, max_length), np.linspace(0, 1, len(pitch_values_normal_file1)), pitch_values_normal_file1)
sequence2_interp = np.interp(np.linspace(0, 1, max_length), np.linspace(0, 1, len(pitch_values_normal_file2)), pitch_values_normal_file2)
sequence3_interp = np.interp(np.linspace(0, 1, max_length), np.linspace(0, 1, len(pitch_values_normal_file3)), pitch_values_normal_file3)
sequence4_interp = np.interp(np.linspace(0, 1, max_length), np.linspace(0, 1, len(pitch_values_normal_file4)), pitch_values_normal_file4)
# 计算平均值序列
average_sequence = np.mean([sequence1_interp, sequence2_interp, sequence3_interp, sequence4_interp], axis=0)
# 计算最大值序列
max_sequence = np.maximum.reduce([sequence1_interp, sequence2_interp, sequence3_interp, sequence4_interp])
# 计算最小值序列
min_sequence = np.minimum.reduce([sequence1_interp, sequence2_interp, sequence3_interp, sequence4_interp])
import matplotlib.pyplot as plt
from scipy.interpolate import interp1d
# 生成时间序列作为横轴
time = np.linspace(0, 1, max(len(pitch_values_file1), len(pitch_values_file2), len(pitch_values_file3), max_length))
# 使用线性插值将基频值列表插值为与时间序列相匹配的长度
f1 = interp1d(np.linspace(0, 1, len(pitch_values_file1)), pitch_values_file1, kind='linear')
f2 = interp1d(np.linspace(0, 1, len(pitch_values_file2)), pitch_values_file2, kind='linear')
f3 = interp1d(np.linspace(0, 1, len(pitch_values_file3)), pitch_values_file3, kind='linear')
# 画出正常的基频
ave = interp1d(np.linspace(0, 1, len(average_sequence)), average_sequence, kind='linear')
max = interp1d(np.linspace(0, 1, len(max_sequence)), max_sequence, kind='linear')
min = interp1d(np.linspace(0, 1, len(min_sequence)), min_sequence, kind='linear')
# 创建图表
plt.figure(figsize=(10, 6)) # 设置图表大小
# 绘制四个wav文件的基频值变化图
plt.plot(time, f1(time), marker='', color='blue', label='Low Intelligibility',markersize=1)
plt.plot(time, f2(time), marker='', color='purple', label='Middle Intelligibility',markersize=1)
plt.plot(time, f3(time), marker='', color='green', label='High Intelligibility',markersize=1)
plt.plot(time, ave(time), marker='', color='red', label='Normal Average',markersize=1, linewidth=3.5)
# 绘制最大值序列和最小值序列之间的区域
plt.fill_between(time, min(time), max(time), color='lightpink', label='Normal Range')
plt.xlabel('Time') # 设置横轴标签
plt.ylabel('Pitch Value (Hz)') # 设置纵轴标签
plt.title('Pitch Value Changes over Time') # 设置图表标题
plt.grid(True) # 显示网格线
plt.legend() # 显示图例
# 保存图表为一个图像文件
plt.savefig(f'pitch_value_plot-v2-{wav}.png')
# 显示图表
plt.show()结果