背景介绍
最近抽空参加了一个讯飞的 RAG 比赛,耗时两周终于在最后一天冲上了榜首。

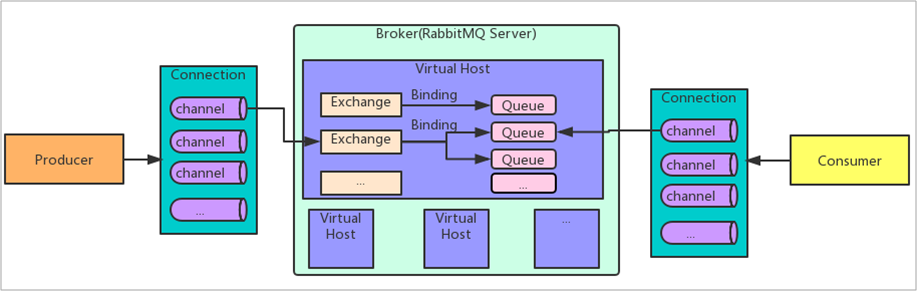
整体的框架是基于 RAG 能力有点弱弱的 Dify 实现。在比赛调优的过程中,经常需要批量提交几百个问题至 Dify 获取回答,并需要跟踪多轮调优的效果差异。借助 Langfuse 可以通过网页跟踪结果,相对比较方便了很多。但是现有版本的 Langfuse 不支持提交文件构建数据集,私有化部署的版本也不支持自动化评估,多版本的比较很麻烦。
在比赛期间断断续续实现了一些自动化脚本进行辅助,比赛结束后感觉确实很实用,因此就有了这个项目 Dify-Eval, 一款补全 Dify + Langfuse 组合短板的自动化工具。目前具备如下所示的功能:
- 一键上传本地文件至 Langfuse 构建数据集;
- 基于 Langfuse 数据集批量至 Dify,并关联原始数据集;
- 全自动大模型评分,多维度,可拓展;
- 多版本评分比较,可视化查看效果提升;


从我自己的使用体验来看,整体还是比较丝滑的。当然开发周期比较短暂,总共耗时 3 天左右,可能还有一些 bug 未发现,欢迎大家作为小白鼠来试用下。
项目介绍
Dify-Eval 是为 Dify + Langfuse 组合设计,这个组合日常的应用监控够用了,而 Dify-Eval 主要解决这个组合缺失的自动化批量测试与评估能力。框架的自动化评估是基于 Ragas 实现。详细的上手流程可以直接查看 Dify-Eval Github
整体是按照开箱即用的方案设计,期望用户只需要根据自己的需求修改 .env 配置文件即可走通完整流程。实际使用基本只需要执行下面的命令:
# 本地文件提交至 Langfuse,并提交问题给 Dify 进行批量测试
python run.py
# 基于 Ragas 进行数据集自动化评估
python evaluate.py
Langfuse 事实上是支持实时评估的,为什么要设计为两个流程呢?原因如下:
- 评估流程比较慢,自动化测试过程则快很多。合并在一起就每次测试都需要等待很久,分开设计下可以根据需要自行确定是否进行自动化评估;
- Dify 同步记录至 Langfuse 是异步完成的,因此实时评估时可能会出现 Dify 提交完成,但是 Langfuse 上获取不到记录,从而导致评估失败的问题;
所以建议先进行批量自动化测试,有需要的情况下确认记录已经同步至 Langfuse ,接下来执行自动化评估。
上手介绍
考虑真正需要用户修改的就是配置文件,而 Dify-Eval 同时关联了 Dify, Langfuse 和 Ragas,因此配置可能会稍微多一些。因此下面大概介绍下其中的配置项,通过配置项基本就能大致了解项目的设计了:
Langfuse 配置
Langfuse 相关的配置如下所示
# Langfuse 的公钥私钥与地址
LANGFUSE_PUBLIC_KEY=pk-lf-
LANGFUSE_SECRET_KEY=sk-lf-
LANGFUSE_HOST=http://localhost:3000/
这部分就是连接 Langfuse 的凭证和地址,对应的获取路径可以参考下图:

DATASET_NAME="数据集"
RUN_NAME="版本v1"
DATASET_NAME 对应的是一个 Langfuse 测试数据集,一个测试数据集中包含多个测试项,每个测试项对应的就是一个测试问题。
RUN_NAME 对应的就是基于测试数据集的一次完整的自动化测试。因此可想而知,基于 DATASET_NAME 可以多次进行测试,一般情况下建议修改 RUN_NAME 进行区分,方便后续跟踪效果的比较。
比如下图中就是基于同样的数据集进行了两次测试,对应的 RUN_NAME 分别为 版本v1 和 版本v2。

Dify 配置
Dify 相关的配置如下所示:
DIFY_API_BASE=http://localhost:58882/v1
DIFY_API_KEY=app-
这部分就是连接 Dify 应用的凭证,对应的获取路径可以参考下图:

Ragas 评估
Ragas 评估相关的配置如下所示:
RAGAS_BASE_URL="http://localhost:9997/v1"
RAGAS_EVAL_LLM="qwen2-instruct"
RAGAS_EMBEDDING="bge-m3"
RAGAS_API_KEY="cannot be empty"
Ragas 评估时需要使用大模型和嵌入模型,因此需要配置对应的地址和模型名称,理论上 OpenAI 格式的大模型和嵌入服务都是支持的。
实际测试时是基于私有化部署的 Xinference 服务完成的,实际也是可以支持的。我实际运行的效果如下所示:

输入输出文件
输入输出文件相关的配置如下所示:
LOCAL_FILE_PATH="example.csv"
OUTPUT_FILE_PATH=""
输入文件的格式为 .csv,其中 question 对应的是测试问题,answer 对应的是测试答案。
考虑到部分情况下可能没有正确答案,项目支持只包含 question 列,同样可以完成批量测试。
但是熟悉 Ragas 评估的研发同学应该知道,没有正确答案时,Ragas 的部分评估指标是无法支持的,因此在执行前可能会需要将 evaluate.py 中的 DEFAULT_METRICS 中不支持的指标去掉,就可以愉快地进行测试了。具体哪些指标不支持,可以参考下 Ragas Metrics 文档
输出文件的格式为 .csv ,默认为空情况下会输出至 results/ 目录下。
总结
整体而言,Dify-Eval 是一个比较趁手的小工具,补全 Dify + Langfuse 组合的一些明显短板,从目前的使用来看还不错,欢迎有需要的试用下。暂时没用上的可以 star 关注下,说不定明天就用上了。
当然目前项目还处于早期阶段,可能会存在一些 bug,欢迎大家反馈和提供 Pull Request。