代码以及视频讲解
本文所涉及所有资源均在传知代码平台可获取
引言
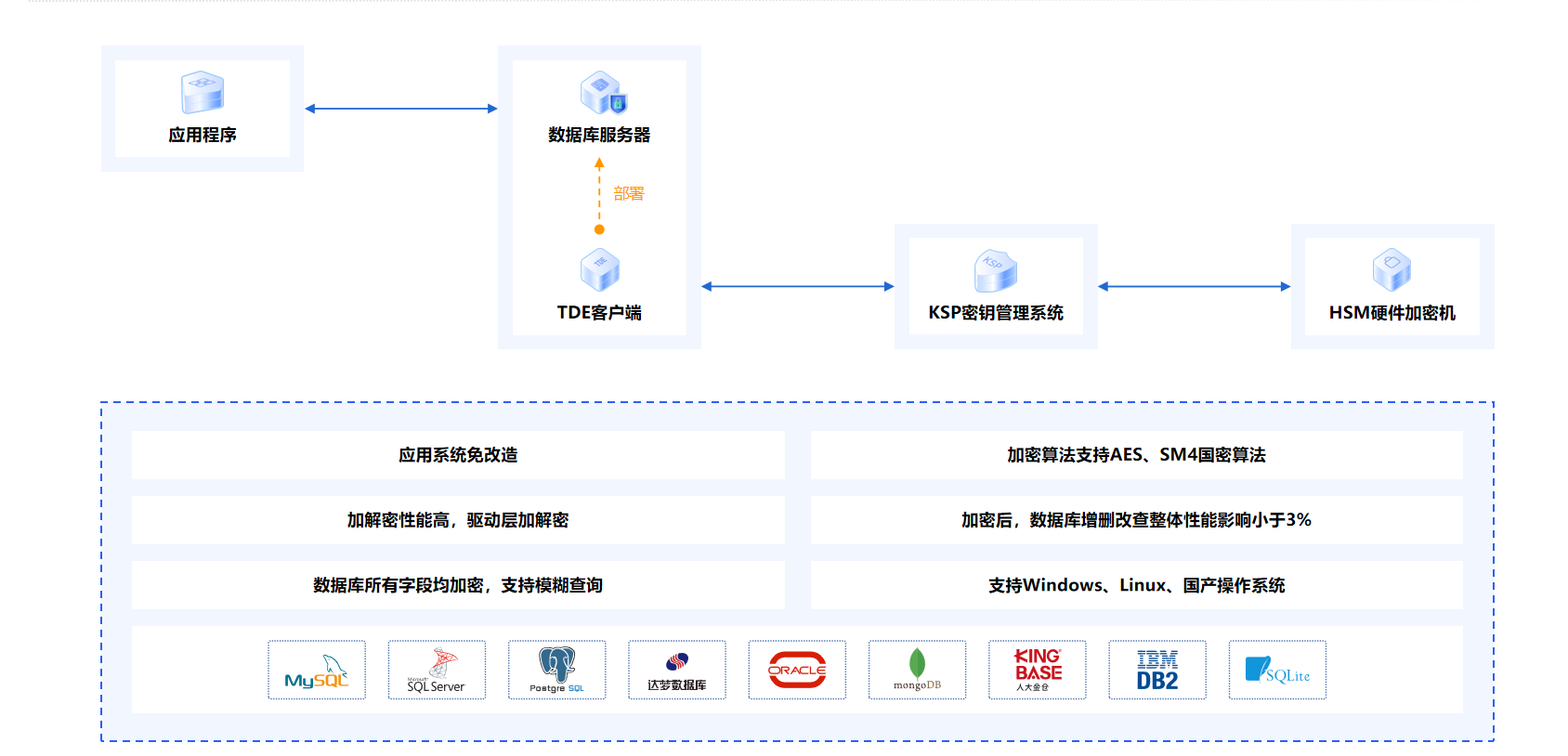
该系统基于EfficientNet与多头自注意力机制,构建了一个高效、精准的苹果叶片识别模型,能够对不同种类的苹果叶片进行准确分类。通过结合EfficientNet的强大特征提取能力和多头注意力机制的全局信息捕捉能力,系统在处理复杂背景和不同光照条件下的叶片图像时表现出色。此外,系统还集成了一个可视化平台,用户可以直观地查看叶片分类结果,并通过简便的界面上传图像进行预测。这使得该系统在实际农业生产中具有重要的应用价值,如病害监测和农业自动化管理等。
效果展示


本文核心创新点
1. 高效网络与注意力机制的集成:
本系统创新性地将 EfficientNet 与 多头自注意力机制 融合,形成了一个集成化的模型结构。EfficientNet以其精细化的网络架构设计和卓越的参数效率著称,而多头自注意力机制则增强了模型在捕捉全局信息和复杂特征方面的表现。通过这种集成,系统显著提升了苹果叶片分类任务的精准度和稳健性,特别是在处理大规模、高维度数据时展现了卓越的性能。
2. 模块化与用户友好的界面设计:
可视化界面的设计体现了高度的用户友好性与灵活性。用户可以通过图形界面直观地选择 EfficientNet 的不同模型结构(如B0到B7),这不仅满足了不同计算资源环境下的需求,还使得复杂的模型选择过程变得简洁和易于操作。通过模块化的设计,界面能够适应多种使用场景,从研究人员到农业工作者均可受益。
3. 智能化的模型选择与调整:
本系统引入了智能化的模型选择机制,允许用户根据任务的复杂性和计算资源的可用性动态调整模型架构。这种创新性设计提升了系统的可扩展性,使得在不同的应用环境中均能达到优化的性能表现。同时,系统支持对注意力机制参数的自适应调整,进一步提高了模型的灵活性和适应性。
EfficientNet核心原理
1. 网络深度
网络深度指的是神经网络中层的数量。在EfficientNet中,网络深度是一个关键的维度,用于捕获图像中的复杂特征。通过增加网络深度,模型能够学习到更多层次的特征表示,从而提高模型的性能。然而,过深的网络也可能导致梯度消失或梯度爆炸的问题,使得模型难以训练。因此,EfficientNet在设计时通过引入残差连接(Residual Connection)等技术来缓解这些问题,同时利用复合缩放策略来平衡网络深度与其他维度的关系。如下图所示:


图中第一部分就是这个网络的baseline,layer_i就是有多少层,可以理解为深度;H*W就是网络输入图像的分辨率;#channels就是网络的宽度。那么图中第二部分就是增加了网络的深度,可以看到“蓝,绿,黄”三部分都增加了一个。单独对网络深度进行变换之后,作者经过消融实验得到最右边的图,这里的“d”表示网络加深的倍数,可以看到当d=6和d=8时结果已经几乎没有提升,这说明并非一直增加网络深度就可以是的网络效果变好。
2. 网络宽度
网络宽度指的是神经网络中每一层的通道数(或称为特征图的数量)。增加网络宽度可以提高模型的特征表示能力,使得模型能够捕捉到更细粒度的特征。然而,过宽的网络也会增加计算量和参数量,从而增加模型的复杂度和训练难度。EfficientNet通过引入宽度乘数(Width Multiplier)来控制每一层的通道数,从而实现网络宽度的灵活调整。较小的宽度乘数可以减少参数量和计算量,使模型更轻量;而较大的宽度乘数则可以增加模型的性能。如下图所示:


那么图中的第一部分同样也是模型的baseline,由图中的第二部分可知,这是在网络的宽度上进行改进,可以看到“蓝,绿,黄”三部分都在横向增加。网络宽度的增加也不是越大越好的,因为上面最右图可知,当宽度增大到w=2.6时几乎是最佳的结果了,因为当再继续增大,计算量会增加很多且准确率增加的并不明显。
3. 图像分辨率
图像分辨率是指输入图像的大小或尺寸。在EfficientNet中,图像分辨率也是一个重要的维度,用于影响模型对图像细节的捕捉能力。使用更高分辨率的输入图像可以使模型捕捉到更细粒度的特征,但也会增加计算量和参数量。因此,EfficientNet通过引入分辨率乘数(Resolution Multiplier)来控制输入图像的分辨率,以实现不同计算资源条件下的灵活调整。较小的分辨率乘数可以降低输入图像的分辨率,从而减少计算复杂度;而较大的分辨率乘数则可以增加模型的视觉表征能力。如下图:


该图是从图像分辨率的角度去进行改进,如右图所示,当图像分辨率增大到一定程度时,带来的效果并不明显了。这是因为随着图像分辨率的增加,模型能够捕捉到更多的细节信息。然而,这种提升并不是线性的。当分辨率增加到一定程度后,模型从中获取的新增信息量逐渐减少,导致模型性能的提升也变得不那么显著。这是因为图像中的很多细节信息在达到一定分辨率后已经足够清晰,再提高分辨率对于模型来说可能只是冗余信息的增加。
4. 复合缩放
那么上述两个方面都不是一直呈现出线性关系,那么使用复合缩放的方法来找到三者的平衡以达到最优的结果。它通过对网络深度、宽度和分辨率三个维度进行统一的缩放,来实现模型性能的最优化。具体来说,EfficientNet使用了一个复合系数(Compound Scaling Factor)来同时调整这三个维度,以确保网络各个部分之间的平衡。复合缩放策略不仅考虑了每个维度对模型性能的独立影响,还考虑了它们之间的相互作用和权衡。通过系统地研究不同维度对模型性能的影响,EfficientNet找到了一个最优的缩放比例,使得模型在保持高效的同时达到了最优的性能。

由图中可以看出当同时增加深度和分辨率时效果增加的非常明显。图中红色线,这是卷积层数是36层,分辨率为299*299.
多头自注意力机制
多头自注意力机制(Multi-Head Self-Attention)是Transformer模型中的一个核心组件,其原理主要通过并行地使用多个自注意力头来捕捉输入序列中的不同上下文信息。它的原理可以概括为:

- 分割输入
输入序列的每个词向量(或更一般地,输入序列的嵌入向量)首先被分割成多个较小的部分,每个部分对应一个“头”(Head)。例如,如果输入词向量的维度是512,可以选择创建8个头,那么在本文中使用了4个头,可以根据自己的需要更改头的数量。每个头的维度就是64(512/8)。 - 计算注意力
对于每个头,分别执行自注意力计算。这通常涉及三个步骤:
线性变换:首先,通过三个不同的线性变换(或全连接层)分别生成查询(Query, Q)、键(Key, K)和值(Value, V)向量。这些变换允许模型学习输入数据的不同方面。
点积注意力:然后,计算每个查询向量与所有键向量的点积,得到一个分数矩阵,表示查询与键之间的相关性。为了防止梯度消失或爆炸,通常会对点积结果进行缩放(Scaled Dot-Product Attention)。
Softmax归一化:接着,使用Softmax函数对分数矩阵进行归一化,得到注意力权重分布。这些权重表示序列中每个位置对当前位置的重要性。 - 加权求和
使用注意力权重对值向量进行加权求和,得到每个头的输出。这一步骤聚合了序列中所有位置的信息,并根据权重赋予不同的重要性。 - 拼接输出
最后,通过一个输出权重矩阵对拼接后的表示进行线性变换,得到最终的输出矩阵。这一步骤可能用于进一步整合信息,并准备输出用于后续的网络层。在本文中这里后续的网络层主要为全连接层。
本文模型结构

本文的模型结构结合了EfficientNet和多头注意力网络共同搭建了这样一个模型,该模型在EfficientNet的最后一个卷积层后接多头自注意力网络。这样做的好处是:EfficientNet的卷积层已经对图像进行了有效的多尺度特征提取,但卷积操作本质上具有局部性,即每个卷积核只能看到一部分图像。因此,在卷积层后引入多头自注意力机制,能够捕获图像特征中的长距离依赖关系。这意味着模型不仅能关注局部的细节特征,还能够有效地整合来自图像不同区域的全局信息,进一步提升了特征表示的丰富性和表达能力。
EfficientNet b0–b7结构差异
EfficientNet-B0: 基准模型,使用了基于MobileNetV2架构的基础网络,并在此基础上进行优化。

EfficientNet-B1在宽度和深度上有所不同,具体不同的差异如下图:

EfficientNet-B2它的结构与EfficientNet-B1相同,它们之间唯一的区别是feature maps(通道)的数量不同,从而增加了参数的数量。
EfficientNet-B3到EfficientNet-B7分别在宽度和深度上均有差异,如下图:





主要区别在于网络的深度、宽度和输入分辨率的不同,这些差异使得每个模型在计算能力和精度上有所不同,从而适应不同的应用场景和资源限制。
不同的模型呈现出来的效果和精度差异如下:

实现过程
1. 数据集获取
本文使用的数据集是从飞浆平台下载的:AppleLeaf9数据集包括健康的苹果叶子和8类苹果叶部病害。当然也可以从我的附件中的readme给出的百度网盘链接下载,这里下载后是划分好训练验证集的。图片如图所示:

2. 数据集划分
本文按照8:2的比例划分了训练和验证集
# 遍历每个类别文件夹并进行划分
for class_folder in os.listdir(data_dir):
class_path = os.path.join(data_dir, class_folder)
if os.path.isdir(class_path):
images = os.listdir(class_path)
random.shuffle(images)
train_size = int(len(images) * split_ratio)
train_images = images[:train_size]
test_images = images[train_size:]
# 创建类别目录
train_class_dir = os.path.join(train_dir, class_folder)
test_class_dir = os.path.join(test_dir, class_folder)
os.makedirs(train_class_dir, exist_ok=True)
os.makedirs(test_class_dir, exist_ok=True)
......
3. 模型训练
数据集划分好后需要在训练脚本中读取划分好的数据集。在训练时可以选择EfficientNet的类型b0–b7,会产生不同的七个模型,用于后续的预测时选择相对应的最佳模型。也可以选择多头注意力中头的数量。
# 定义苹果叶片分类模型
class AppleLeafClassifier(nn.Module):
def __init__(self, model_name='efficientnet-b3', num_classes=9, attention_heads=4):
super(AppleLeafClassifier, self).__init__()
self.backbone = EfficientNet.from_pretrained(model_name)
.......
def forward(self, x):
x = self.backbone.extract_features(x)
b, c, h, w = x.size()
embed_dim = c
if self.multihead_attn is None or self.multihead_attn.multihead_attn.embed_dim != embed_dim:
self.multihead_attn = MultiHeadSelfAttention(embed_dim=embed_dim, num_heads=4).to(device)
开始模型训练
for epoch in range(num_epochs):
model.train()
running_loss = 0.0
for inputs, labels in train_loader:
inputs, labels = inputs.to(device), labels.to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item() * inputs.size(0)
epoch_loss = running_loss / train_size
model.eval()
correct = 0
total = 0
保存最佳模型
# 保存最好的模型
if epoch_acc > best_acc:
best_acc = epoch_acc
torch.save(model.state_dict(), 'best_model3.pth')
print('训练完成,最佳验证准确率: {:.4f}'.format(best_acc))
模型预测与可视化平台
def predict_image(self, file_path):
image = Image.open(file_path)
self.display_image(image)
transform = transforms.Compose([
transforms.Resize((256, 256)),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
image = transform(image).unsqueeze(0).to(device)
model_name = self.model_selector.currentText()
........
model.load_state_dict(torch.load(model_path, map_location=device)) # 使用 map_location 来匹配设备
model.eval()
def initUI(self):
self.setWindowTitle(self.title)
layout = QVBoxLayout()
self.model_selector = QComboBox(self)
for model_name in ['efficientnet-b0', 'efficientnet-b1', 'efficientnet-b2', 'efficientnet-b3', 'efficientnet-b4', 'efficientnet-b5', 'efficientnet-b6', 'efficientnet-b7']:
self.model_selector.addItem(model_name)
layout.addWidget(self.model_selector)
self.button = QPushButton('选择图像', self)
self.button.clicked.connect(self.open_file_dialog)
layout.addWidget(self.button)
self.label = QLabel(self)
layout.addWidget(self.label)
self.result_label = QLabel('分类结果: ', self)
self.result_label.setStyleSheet("font-size: 18px;")
layout.addWidget(self.result_label)
self.setLayout(layout)
self.setGeometry(300, 300, 400, 300)
训练过程:

实验结果展示:
1.基线模型结果:

2.加多头注意力结果:

可以看到在添加多头注意力后,我们的模型结果是要优于基线模型的。
参考文献
1.Mingxing Tan and Quoc V. Le. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. ICML 2019. Arxiv link: https://arxiv.org/abs/1905.11946.
2.Vaswani A. Attention is all you need[J]. arxiv preprint arxiv:1706.03762, 2017.
源码下载