机器学习的研究和学习必须使用Python开发库,面对很多个机器学习的Python库或者框架,我们是不是傻傻的分不清,这个那个到底是做什么,什么时候用这个,什么时候用那个,他们各自的优势劣势都有哪些,这篇文章就给大家逐一剖析,让小伙伴们在见到他们的时候能够如数家珍般的讲出来。

机器学习的核心思想是通过数据训练模型,然后使用这个模型进行预测或分类。常见的机器学习算法包括线性回归、决策树、支持向量机和聚类算法等。
深度学习是机器学习的一个子领域,它主要利用神经网络,尤其是深层神经网络来进行数据分析和模式识别。深度学习的灵感来源于人脑的结构,通过多层神经元的连接和激活函数,深度学习能够自动学习和提取数据中的特征,从而在图像识别、自然语言处理等任务上表现出色。
使用这些库不仅简化了模型的开发过程,还为大家提供了强大的工具和资源。
下面,我通过具体的代码示例,深入了解这些库的使用方法和应用场景,帮助对于某一个库的初学者更好地掌握机器学习和深度学习的相关库的使用
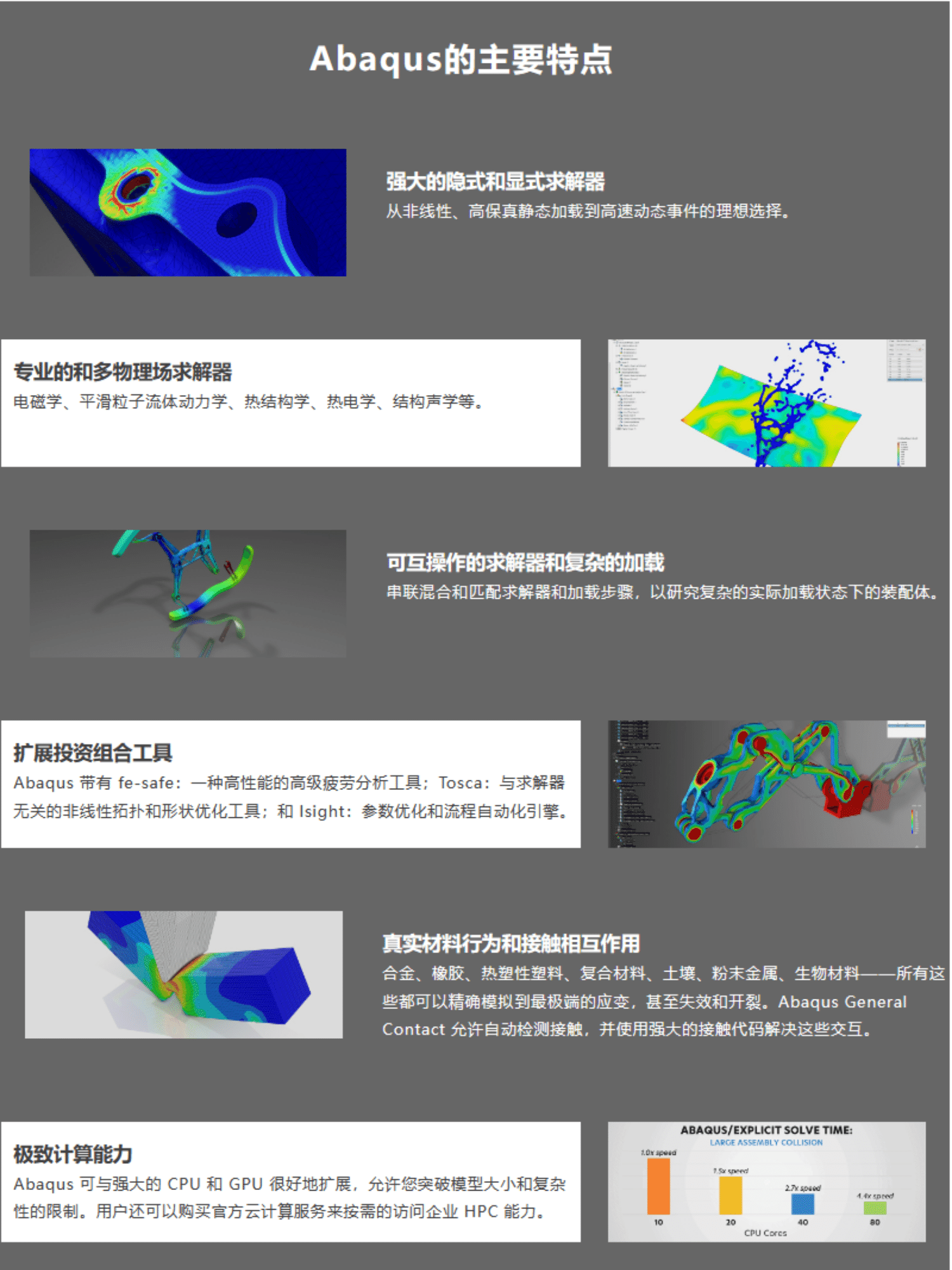
1. TensorFlow
TensorFlow是一个开源的机器学习框架,由Google Brain团队开发并在2015年发布。它提供了灵活的计算模型,支持大规模分布式训练和跨平台部署,适用于从研究到生产的各种场景。
特点:
- 支持分布式计算,能在多GPU和TPU上高效运行。
- 拥有丰富的预训练模型和工具,如TensorFlow Hub和TensorFlow Model Garden。
- 强大的社区支持和广泛的文档资源。
- 兼容Keras,提供高层API简化深度学习模型的构建和训练。
适用场景:
- 大规模深度学习模型训练和部署。
- 需要跨平台支持的机器学习应用,如移动设备和Web应用。
- 工业级应用和生产环境中的AI解决方案。
经典案例: 使用TensorFlow构建并训练一个简单的神经网络进行手写数字识别(MNIST数据集)。
import tensorflow as tf
from tensorflow.keras.datasets import mnist
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Flatten
import matplotlib.pyplot as plt
# 加载数据
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
# 构建模型
model = Sequential([
Flatten(input_shape=(28, 28)),
Dense(128, activation='relu'),
Dense(10, activation='softmax')
])
# 编译模型
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
# 训练模型
history = model.fit(x_train, y_train, epochs=5, validation_data=(x_test, y_test))
# 绘制训练结果
plt.plot(history.history['accuracy'], label='accuracy')
plt.plot(history.history['val_accuracy'], label = 'val_accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.ylim([0.5, 1])
plt.legend(loc='lower right')
plt.show()
# 评估模型
test_loss, test_acc = model.evaluate(x_test, y_test, verbose=2)
print('\nTest accuracy:', test_acc)
# Test accuracy: 0.9751999974250793训练结果展示:

2. PyTorch
开发者: Facebook's AI Research lab (FAIR)
详细介绍: PyTorch是一个开源深度学习框架,由Facebook的人工智能研究实验室开发。它于2016年发布,以其动态计算图和易用性而广受欢迎,尤其在研究社区中。
特点:
- 动态计算图(Define-by-Run),调试方便,灵活性高。
- 广泛的社区支持和丰富的资源,如PyTorch Hub。
- 强大的支持库,如TorchVision(计算机视觉)和TorchText(自然语言处理)。
- 与ONNX(Open Neural Network Exchange)兼容,便于模型导出和跨平台部署。
适用场景:
- 学术研究和快速原型开发。
- 需要动态计算图和灵活调试的深度学习项目。
- 计算机视觉和自然语言处理任务。
经典案例: 使用PyTorch构建并训练一个简单的神经网络进行手写数字识别(MNIST数据集)。
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
import matplotlib.pyplot as plt
# 数据加载和预处理
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5,), (0.5,))])
trainset = datasets.MNIST(root='./data', train=True, download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=64, shuffle=True)
testset = datasets.MNIST(root='./data', train=False, download=True, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=64, shuffle=False)
# 定义模型
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.fc1 = nn.Linear(28 * 28, 128)
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
x = x.view(-1, 28 * 28)
x = torch.relu(self.fc1(x))
x = self.fc2(x)
return x
model = Net()
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 训练模型
epochs = 5
train_losses = []
for epoch in range(epochs):
running_loss = 0.0
for images, labels in trainloader:
optimizer.zero_grad()
outputs = model(images)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
train_losses.append(running_loss / len(trainloader))
# 绘制训练损失
plt.plot(train_losses, label='Training loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend(loc='upper right')
plt.show()
# 评估模型
correct = 0
total = 0
with torch.no_grad():
for images, labels in testloader:
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy of the network on the 10000 test images: %d %%' % (100 * correct / total))训练结果展示:

3. Scikit-learn
详细介绍: Scikit-learn是一个基于Python的机器学习库,构建在NumPy、SciPy和matplotlib之上。它提供了简单且一致的API,适用于经典机器学习算法。
特点:
- 覆盖广泛的机器学习算法,如回归、分类、聚类、降维等。
- 简单易用的API设计,适合初学者和快速开发。
- 与Python生态系统中的其他库(如Pandas、NumPy)无缝集成。
- 丰富的文档和教程,社区活跃。
适用场景:
- 中小型数据集的机器学习任务。
- 快速原型和教学用途。
- 需要标准机器学习算法的各种应用。
经典案例: 使用Scikit-learn进行鸢尾花数据集的分类,并绘制决策边界。
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVC
from sklearn.decomposition import PCA
# 加载数据
iris = datasets.load_iris()
X = iris.data
y = iris.target
# 数据预处理
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
# PCA降维
pca = PCA(n_components=2)
X_train_pca = pca.fit_transform(X_train)
X_test_pca = pca.transform(X_test)
# 训练模型
svm = SVC(kernel='linear')
svm.fit(X_train_pca, y_train)
# 绘制决策边界
def plot_decision_boundary(model, X, y):
h = .02
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, h),
np.arange(y_min, y_max, h))
Z = model.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plt.contourf(xx, yy, Z, alpha=0.8)
plt.scatter(X[:, 0], X[:, 1], c=y, edgecolors='k', marker='o')
plt.xlabel('PCA Component 1')
plt.ylabel('PCA Component 2')
plt.title('Decision Boundary')
plt.show()
plot_decision_boundary(svm, X_test_pca, y_test)训练结果展示:

4. Keras
详细介绍: Keras是一个高层神经网络API,最初由François Chollet开发。它提供简洁易用的接口,能够以模块化和可扩展的方式构建和训练深度学习模型。
特点:
- 简单易用,极大简化了深度学习模型的构建过程。
- 支持多种后端(如TensorFlow、Theano、CNTK)。
- 丰富的预训练模型和工具。
- 强大的社区和文档支持。
适用场景:
- 快速原型开发和实验。
- 教学和初学者学习深度学习。
- 需要高效开发和部署的深度学习应用。
经典案例: 使用Keras构建并训练一个简单的卷积神经网络进行手写数字识别(MNIST数据集)。
from tensorflow.keras.datasets import mnist
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense
import matplotlib.pyplot as plt
# 加载数据
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
x_train = x_train.reshape(-1, 28, 28, 1)
x_test = x_test.reshape(-1, 28, 28, 1)
# 构建模型
model = Sequential([
Conv2D(32, kernel_size=(3, 3), activation='relu', input_shape=(28, 28, 1)),
MaxPooling2D(pool_size=(2, 2)),
Flatten(),
Dense(128, activation='relu'),
Dense(10, activation='softmax')
])
# 编译模型
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
# 训练模型
history = model.fit(x_train, y_train, epochs=5, validation_data=(x_test, y_test))
# 绘制训练结果
plt.plot(history.history['accuracy'], label='accuracy')
plt.plot(history.history['val_accuracy'], label = 'val_accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.ylim([0.5, 1])
plt.legend(loc='lower right')
plt.show()
# 评估模型
test_loss, test_acc = model.evaluate(x_test, y_test, verbose=2)
print('\nTest accuracy:', test_acc)训练结果展示:

6. LightGBM
Microsoft 出品
详细介绍: LightGBM(Light Gradient Boosting Machine)是一个基于梯度提升的高效框架,由Microsoft开发。它针对大规模数据和分布式训练进行了优化。
特点:
- 高效的梯度提升框架,速度快,内存使用少。
- 支持类别特征处理和分布式训练。
- 丰富的调参选项和模型解释工具。
- 社区支持和文档资源充足。
适用场景:
- 需要高性能和高效计算的机器学习任务。
- 大规模数据集的分类和回归任务。
- 需要快速迭代和调参的项目。
经典案例: 使用LightGBM进行分类任务,并绘制特征重要性图。
import lightgbm as lgb
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
import matplotlib.pyplot as plt
# 加载数据
data = load_breast_cancer()
X = data.data
y = data.target
# 数据拆分
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建数据集
train_data = lgb.Dataset(X_train, label=y_train)
test_data = lgb.Dataset(X_test, label=y_test)
# 参数设置
params = {
'objective': 'binary',
'metric': 'binary_error',
'boosting_type': 'gbdt',
'num_leaves': 31,
'learning_rate': 0.05,
'feature_fraction': 0.9
}
# 训练模型
bst = lgb.train(params, train_data, 100, valid_sets=[test_data])
# 预测
y_pred = bst.predict(X_test, num_iteration=bst.best_iteration)
y_pred = (y_pred > 0.5).astype(int)
accuracy = accuracy_score(y_test, y_pred)
print(f'Accuracy: {accuracy}')
# 绘制特征重要性
lgb.plot_importance(bst)
plt.show()训练结果展示:

7. NLTK(Natural Language Toolkit)
介绍:NLTK是一个强大的自然语言处理库,用于处理人类语言数据。
特点:
- 提供了丰富的文本处理工具和资源,包括词性标注、词干提取、命名实体识别等。
- 支持多种自然语言处理算法和技术,如分词、句法分析、语义分析等。
- 包含大量语料库和词汇资源,方便研究和实践。
适用场景:
- 文本分析和挖掘,如情感分析、主题提取等。
- 信息检索和检索系统的构建。
- 语言学研究和自然语言处理教学。
经典案例: 情感分析是自然语言处理中的一项重要任务,旨在确定一段文本的情感倾向,如积极、消极或中立。
import nltk
from nltk.tokenize import word_tokenize
from nltk.corpus import stopwords
from nltk.stem import WordNetLemmatizer
from nltk.sentiment.vader import SentimentIntensityAnalyzer
nltk.data.path.append('/Users/yaojianguo/nltk_data', '/Library/Frameworks/Python.framework/Versions/3.9/nltk_data', '/Library/Frameworks/Python.framework/Versions/3.9/share/nltk_data', '/Library/Frameworks/Python.framework/Versions/3.9/lib/nltk_data', '/usr/share/nltk_data', '/usr/local/share/nltk_data', '/usr/lib/nltk_data', '/usr/local/lib/nltk_data')
# 下载 NLTK 的数据
nltk.download('punkt')
nltk.download('stopwords')
nltk.download('wordnet')
nltk.download('vader_lexicon')
# 示例文本
text = "NLTK is a great library for natural language processing. I use it all the time in my projects."
# 分词
tokens = word_tokenize(text.lower())
# 去除停用词
stop_words = set(stopwords.words('english'))
filtered_tokens = [word for word in tokens if word.isalnum() and word not in stop_words]
# 词形还原
lemmatizer = WordNetLemmatizer()
lemmatized_tokens = [lemmatizer.lemmatize(word) for word in filtered_tokens]
# 构建文本
processed_text = ' '.join(lemmatized_tokens)
# 情感分析
sid = SentimentIntensityAnalyzer()
scores = sid.polarity_scores(processed_text)
# 输出结果
print("Text:", text)
print("Sentiment Scores:", scores)训练结果展示:

首先对文本进行了分词、去除停用词和词形还原等预处理步骤,然后利用 NLTK 自带的情感分析工具 SentimentIntensityAnalyzer 对文本进行情感分析。输出结果中的 compound 分数表示整体情感倾向,可以帮助了解文本的情感色彩。
通过上面七个常用机器学习Python库的学习和了解,同学们可以自己code下代码,运行下,之后深入理解下,代码的逻辑就更能掌握这些库的特点和用处,相信同学通过这篇文章对机器学习和人工智能有跟深入的掌握。
各种关系分支的图如下:

上面这个图没有显示大模型的,可以理解 Transformer位置就是大模型的位置。