索引
1.索引
在数据中索引最核心的作用就是:加速查找
1.1 索引原理
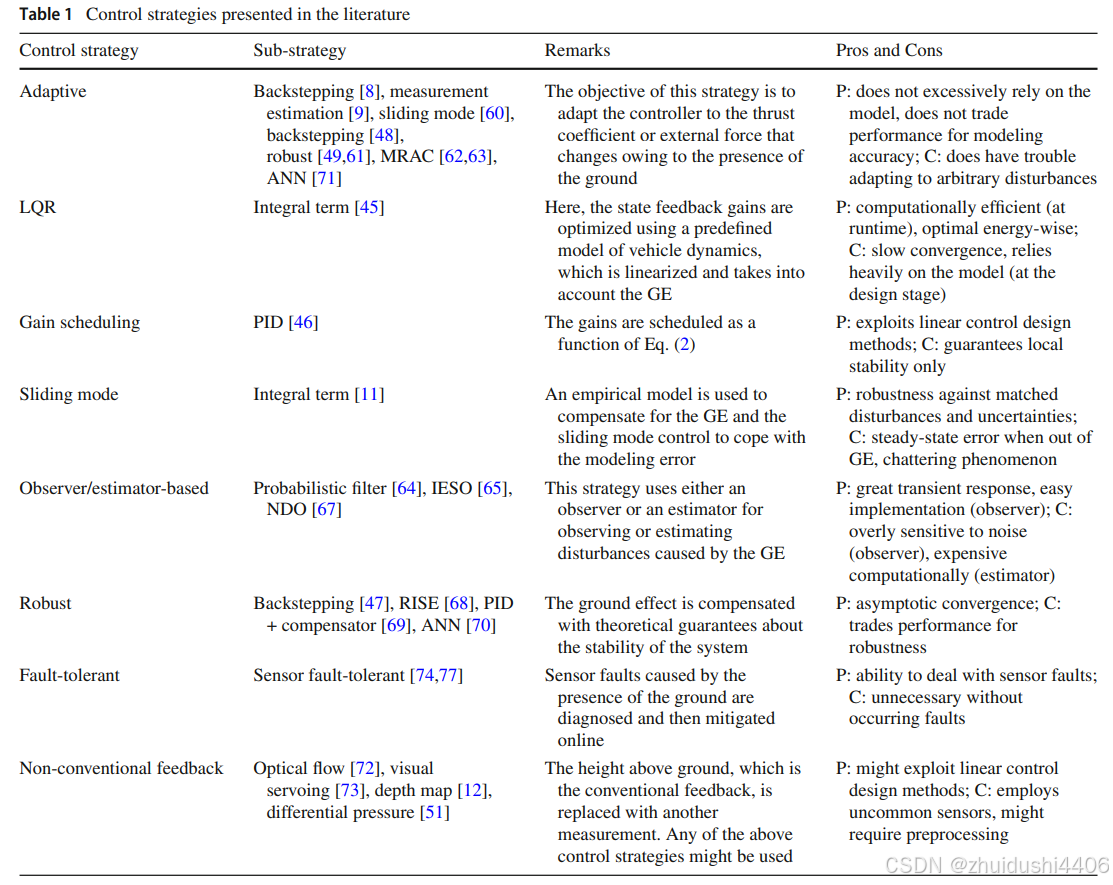
索引的底层是基于B+Tree的数据存储结构
如图所示:

很明显,如果有了索引结构的查询效率比表中逐行查询的速度要快很多且数据越大越明显。
数据库的索引是基于上述B+Tree的数据结构实现,但在创建数据库表时,如果指定不同的引擎,底层使用的B+Tree结构的原理有些不同:
- myisam 引擎,非聚簇索引(数据和索引结构分开索引)
- innodb引擎,聚簇索引(数据和主见索引存储在一起)
myisam引擎(非聚簇索引)
create table 表名(
id int(11) not null auto_increment primary key,
name varchar(32) not null,
age int
)engine=myisam default charset=utf8

innodb引擎(聚簇索引)
create table 表名(
id int(11) not null auto_increment primary key,
name varchar(32) not null,
age int
)engine=innodb default charset=utf8

- 常见的索引
在开发过程中常见的索引类型:
- 主键索引:加速查找、不能为空,不能重复。+联合主键索引
- 唯一索引:加速查找、不能重复。+联合唯一索引
- 普通所以那就:加速查找。+联合索引
创建主键和联合主键索引
create table t1(
id int not null auto_increment primary key,
name varchar(32) not null
)default charset=utf8;
create table t2 (
id int not null auto_increment primary key,
name varchar(32) not null
)default charset=utf8;
create table t3(
id int not null auto_increment,
name varchar(32) not null,
primary key (id,name)) --如果是多列,称为联合主键(不常用myisam引擎支持)
alter table 表名 add primary key (列名);
- 删除索引时可能会报错,自增列必须定义为键。
alter table 表名 drop primary key;
[42000][1075] Incorrect table definition; there can be only one auto column and it must be defined as a key
唯一和联合唯一索引
#在创建表之前创建唯一索引
create table unique_t1
(
id int not null auto_increment primary key,
name varchar(32) not null,
email varchar(64) not null,
unique unique_name (name),
unique unique_email (email)
) default charset = utf8;
create table unique_t2
(
id int not null auto_increment primary key,
name varchar(32) not null,
email varchar(64) not null,
unique unique_name_email (name, email) -- 如果多列,联合唯一索引,也就是如果允许有一项是重复的,联合索引的列不全都重复即可
) default charset = utf8;
# 在创建表后创建唯一索引
create unique index unique_age on unique_t2 (age);
# 删除索引
drop index unique_age on unique_t2;
索引和联合索引
create table index_t1
(
id int not null auto_increment primary key,
name varchar(32) not null,
email varchar(64) not null,
index index_name (name)
) default charset = utf8;
create table index_t2
(
id int not null primary key,
name varchar(16) not null,
email varchar(32) not null,
age int(11) not null,
index index_name_email (name, email)
) default charset = utf8;
create index index_t1_age on index_t2(age);
drop index index_t1_age on index_t2;
命中索引
- 类型不一致
select * from resume_library where 姓名=123; --没有命中索引
select * from resume_library where 位置=123; --没有命中索引
select * from resume_library where r_id = '3000000'; -- 命中索引
- 使用不等于
select * from resume_library 姓名!=于金龙;-- 未命中
select * from resume_library email !=yujinlong2002@outlook.com;-- 未命中
# 主键有特殊情况(resume_library的id列是表的主键)
select * from resume_library where id = 10; -- 命中索引🎯
- or,当or条件中有未建立索引的列才有效(id:主键,name 有索引 ,email 没有索引)
select * from tb where id = 213 or email='xxxxxx@xxxx.com'
-- 未命中
select * from tb where email='xxxxxx@xxxx.com' or name='阿龙的代码在报错'; 未命中
特殊情况
select * from tb where id = 213 or email='xxxxxx@xxxx.com' and name='阿龙的代码在报错' -- 命中 🎯
- 排序,当根据索引进行排序的时候,选择的映射如果不是索引,那么就不走索引
select * from tb order by name asc -- 未命中
select * from tb order by name desc -- 未命中
select name from tb order by name desc -- 命中🎯
特殊情况:(id 是主键)
select * from tb where order by id desc -- 命中🎯
- like,模糊匹配时
select * from tb where name like "%代码在报错"; -- 未命中
select * from tb where name like "阿龙%在报错"; -- 未命中
select * from tb where name like "_龙在报错"; -- 未命中
特别的(通配符在最后面可以命中)
select * from tb where name like "阿龙的代码%" -- 命中🎯
select * from tb where name like "于%"
- 使用函数
select * from tb where reverse(name)="阿龙的代码在报错"; -- 未命中
特殊的情况:
select * from tb where name=reverse("阿龙的代码在报错") -- 命中🎯
- 最左前缀原则,如果是联合索引,要遵循最左前缀原则
如果是联合索引未(id,name,age)
id and name -- 命中🎯
id -- 命中🎯
name -- 未命中
id or name --未命中
name and age --未命中
以上是数据库索引中比较常见的无法命中索引的情况,如果有错误或者不规范的地方希望各位大佬指正
- 最左前缀原则,如果是联合索引,要遵循最左前缀原则
如果是联合索引未(id,name,age)
id and name -- 命中🎯
id -- 命中🎯
name -- 未命中
id or name --未命中
name and age --未命中
以上是数据库索引中比较常见的无法命中索引的情况,如果有错误或者不规范的地方希望各位大佬指正














![[教程]如何在iPhone上启用中国移动/联通/电信RCS消息](https://i-blog.csdnimg.cn/direct/bc0b3971d5744219a134528a3df0db89.png)