大家好,今天咱们来聊聊XGBoost ~
XGBoost(Extreme Gradient Boosting)是一种集成学习算法,是梯度提升树的一种改进。它通过结合多个弱学习器(通常是决策树)来构建一个强大的集成模型。
XGBoost 的核心原理涉及到损失函数的优化和树模型的构建。
核心原理
1. 损失函数(Loss Function):
假设我们有一个由 个样本组成的训练数据集,,其中 是特征向量, 是对应的标签。
XGBoost 使用泰勒展开式对损失函数进行近似。对于一般的损失函数 ,泰勒展开式可以写作:
其中, 是当前模型的预测值, 和 分别是损失函数关于预测值的一阶导数(梯度)和二阶导数(海森矩阵)。这里的 表示第 个样本。
2. 正则化项(Regularization Term):
为了防止过拟合,XGBoost 引入了正则化项。正则化项包含了树模型的复杂度,可以写作:
其中, 是叶子节点的数量, 是叶子节点的分数, 和 是正则化参数。
3. 目标函数(Objective Function):
XGBoost 的目标函数是损失函数和正则化项的加权和。假设我们有 个树模型,每个树模型表示为 ,目标函数可以写作:
4. 模型更新(Model Update):
XGBoost 采用贪婪算法逐步构建树模型。每一步迭代,都会学习一个新的树模型,以减小目标函数。模型更新分为两个步骤:叶子节点分裂(Leaf Split)和叶子节点权重(Leaf Weight)的更新。
对于叶子节点 ,其分数 可以通过以下公式计算:
其中, 是叶子节点 上所有样本的一阶梯度之和, 是叶子节点 上所有样本的二阶梯度之和。而且,当叶子节点的分数确定后,可以使用优化算法(如近似贪婪算法)来选择最佳的分裂点。
5. 预测(Prediction):
最终模型的预测结果可以通过将所有树的输出值相加来获得:
这里的 表示第 个树对样本 的预测输出。
综上所述,XGBoost 通过优化目标函数,迭代地构建树模型,并通过贪婪算法对树的结构进行优化,从而得到强大的集成模型。
特点和适用场景
XGBoost作为一种高效的集成学习算法,这里给大家总结7个显著的特点:
1. 高效的并行化处理:
-
XGBoost 能够有效地利用多核处理器进行并行计算,加速模型训练过程。
-
它采用了一种分布式计算框架,使得在大规模数据集上的训练也能够快速完成。
2. 高度优化的损失函数:
-
XGBoost 使用了泰勒展开式对损失函数进行近似,这样做能够更好地理解数据,从而更快地收敛到最优解。
-
通过一阶和二阶导数信息,XGBoost 能够更加精确地估计每个样本的损失。
3. 正则化和剪枝:
-
XGBoost 通过正则化项来控制模型的复杂度,防止过拟合。
-
它采用了剪枝技术来减小树的规模,降低模型的复杂度,提高泛化能力。
4. 可扩展性和灵活性:
-
XGBoost 可以与多种编程语言和数据处理框架(如Python、R、Spark)无缝集成。
-
它支持自定义损失函数和评估指标,可以适应各种不同的任务和需求。
5. 特征重要性评估:
-
XGBoost 提供了一种直观的方法来评估特征的重要性,可以帮助用户进行特征选择和模型解释。
6. 处理缺失值:
-
XGBoost 能够自动处理缺失值,不需要对缺失值进行额外的处理或填充。
7. 支持多种目标函数:
-
XGBoost 支持分类、回归、排序等多种类型的任务,可以灵活应对不同的问题。
XGBoost 最能解决的问题包括但不限于:
-
分类问题:XGBoost 在处理分类问题时表现优异,能够有效地处理高维度特征和大规模数据集。
-
回归问题:对于回归问题,XGBoost 能够提供精确的预测和较小的泛化误差。
-
排序问题:在搜索引擎、推荐系统等需要排序的场景中,XGBoost 能够学习到有效的排序模型。
-
异常检测:XGBoost 可以通过学习异常模式来进行异常检测,适用于金融欺诈检测、工业生产中的异常监测等场景。
-
特征工程:XGBoost 能够自动处理缺失值和异常值,减少了特征工程的工作量。
-
模型解释:XGBoost 提供了直观的特征重要性评估,可以帮助解释模型的预测结果。
完整案例
下面,是一个使用XGBoost算法进行二分类的完整案例,包括数据集、Python代码和结果可视化。我们使用鸢尾花数据集作为示例数据集,该数据集包含四个特征和三个类别。
案例流程
-
数据加载与预处理。
-
特征工程与数据分割。
-
使用XGBoost进行模型训练。
-
模型评估与可视化。
数据集
我们将使用鸢尾花数据集,该数据集包含150个样本,每个样本有四个特征:花萼长度、花萼宽度、花瓣长度和花瓣宽度,以及一个目标变量,代表鸢尾花的类别(Setosa、Versicolor和Virginica)。
代码
import numpy as np
import pandas as pd
import xgboost as xgb
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, confusion_matrix
import matplotlib
matplotlib.use('TkAgg')
import matplotlib.pyplot as plt
import seaborn as sns
from mpl_toolkits.mplot3d import Axes3D
if __name__ == '__main__':
# 加载鸢尾花数据集
iris = load_iris()
X = iris.data
y = iris.target
# 数据分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 设置XGBoost参数
param = {'max_depth': 3, 'eta': 0.3, 'objective': 'multi:softmax', 'num_class': 3}
num_round = 20
# 训练模型
dtrain = xgb.core.DMatrix(X_train, label=y_train)
dtest = xgb.core.DMatrix(X_test, label=y_test)
bst = xgb.train(param, dtrain, num_round)
# 在测试集上进行预测
y_pred = bst.predict(dtest)
# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print("Accuracy:", accuracy)
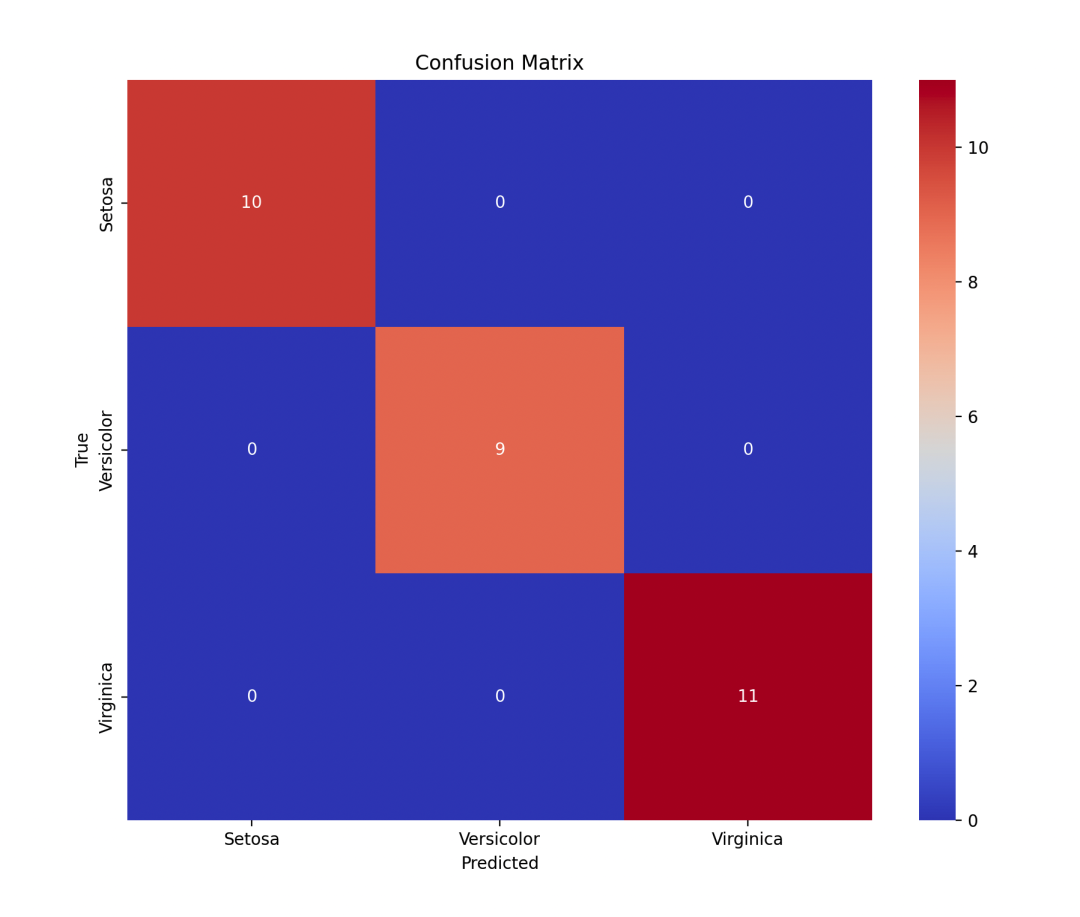
# 绘制混淆矩阵
labels = ['Setosa', 'Versicolor', 'Virginica']
cm = confusion_matrix(y_test, y_pred)
plt.figure(figsize=(10, 8))
sns.heatmap(cm, annot=True, fmt='d', cmap='coolwarm', xticklabels=labels, yticklabels=labels)
plt.xlabel('Predicted')
plt.ylabel('True')
plt.title('Confusion Matrix')
plt.show()
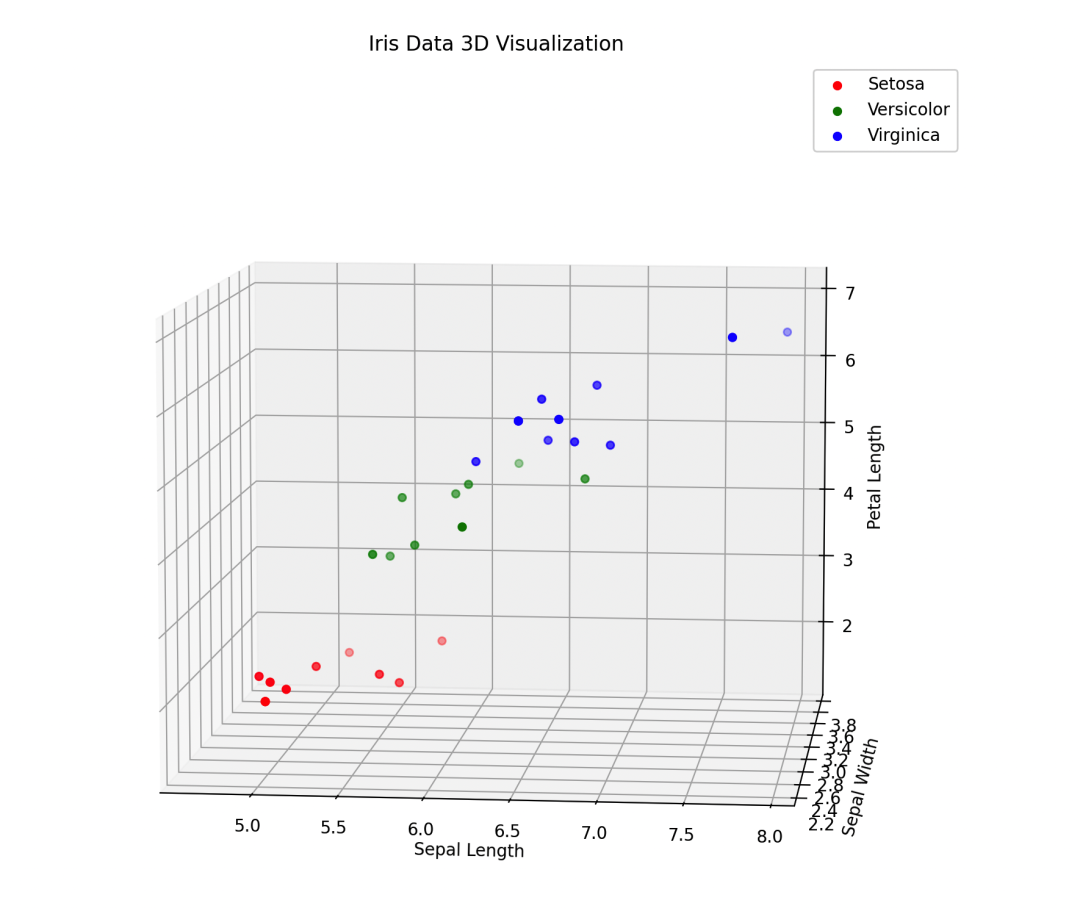
# 3D 可视化
fig = plt.figure(figsize=(12, 10))
ax = fig.add_subplot(111, projection='3d')
colors = ['r', 'g', 'b']
for i in range(3):
ax.scatter(X_test[y_test == i, 0], X_test[y_test == i, 1], X_test[y_test == i, 2], c=colors[i], label=labels[i])
ax.set_xlabel('Sepal Length')
ax.set_ylabel('Sepal Width')
ax.set_zlabel('Petal Length')
ax.set_title('Iris Data 3D Visualization')
plt.legend()
plt.show()在实际应用中,可以调整XGBoost的参数以获得更好的性能,例如使用交叉验证来选择最佳的参数组合。
其中,
scikit-learn==1.5.2
matplotlib==3.9.0
seaborn==0.13.2
xgboost==2.1.1绘制混淆矩阵
可视化
最后
XGBoost是一种集成学习算法,基于决策树构建强大的预测模型。它通过迭代训练多个决策树模型,利用梯度提升技术不断优化模型性能。XGBoost在各种数据集上都表现出色,并且被广泛应用于分类和回归问题。