文章目录
- 【JUC并发编程系列】深入理解Java并发机制:高效并发背后的守护者(八、线程池的秘密)
- 1. 线程池基础知识
- 1.1 什么是线程池
- 1.2 为什么要使用线程池
- 1.3 线程池使用场景
- 1.4 线程池有哪些作用
- 2. 线程池基本用法
- 2.1 线程池的创建方式
- 2.2 线程池底层是如何实现复用的
- 2.3 简单模拟手写 Java 线程池
- 3. 线程池的原理
- 3.1 核心线程数一直在运行状态如何避免cpu飙高问题
- 3.2 ThreadPoolExecutor 构造函数的核心参数
- 3.3 阿里巴巴java开发手册中不推荐使用jdk自带线程池
- 3.4 线程池拒绝策略
- 3.5 自定义线程池名称
- 3.6 线程池五种状态
- 3.7 线程池参数如何配置
- 3.8 SpringBoot项目中如何整合线程池
【JUC并发编程系列】深入理解Java并发机制:高效并发背后的守护者(八、线程池的秘密)
1. 线程池基础知识
1.1 什么是线程池
线程池是一种管理线程的机制,它能够有效地控制运行中的线程数量,复用已创建的线程,减少创建和销毁线程的开销,并且能够快速响应并发任务。线程池维护了一组可重用的线程,这些线程处于等待状态,一旦有新的任务提交给线程池,线程池就会选择一个空闲的线程来执行这个任务。
Java 提供了 java.util.concurrent.ExecutorService 接口和它的实现类 ThreadPoolExecutor 作为创建线程池的标准方式。此外,Executors 工厂类提供了创建线程池的简便方法。
1.2 为什么要使用线程池
-
因为频繁的开启线程或者停止线程,线程需要重新被 cpu 从就绪到运行状态调度,需要发生 cpu 的上下文切换,效率非常低。
-
线程池是一种重要的并发工具,它可以帮助开发者更好地管理和控制多线程程序中的线程,提高系统的稳定性和效率。在设计高并发系统时,合理使用线程池是非常关键的。
-
阿里巴巴Java开发手册中强制规定:线程资源必须通过线程池提供,不允许在应用中自行显式创建线程。
- 说明:线程池的好处是减少在创建和销毁线程上所消耗的时间以及系统资源的开销,解决资源不足的问题。如果不使用线程池,有可能造成系统创建大量同类线程而导致消耗完内存或者“过度切换“的问题。
1.3 线程池使用场景
-
Web服务器处理HTTP请求:Web服务器接收到大量的HTTP请求时,可以使用线程池来处理这些请求。每个请求被分配给线程池中的一个线程来处理,这样可以有效地利用服务器资源,避免因为创建和销毁线程带来的开销。
-
数据库查询处理:当数据库服务器接收到多个查询请求时,可以使用线程池来管理查询处理任务。这样可以避免每个查询都创建一个新的数据库连接和线程,从而提高数据库服务器的性能。
-
异步发送邮件或短信:应用程序需要发送大量的邮件或短信通知时,可以使用线程池来异步处理这些任务。这样可以确保即使在短时间内有大量的发送请求,也不会阻塞应用程序的主线程。
-
批量文件处理:当需要处理大量文件时,例如压缩、解压、格式转换等,可以使用线程池来并发处理这些文件,从而加快处理速度。
-
定时任务执行:应用程序中可能会有一些需要定期执行的任务,如备份数据库、清理日志文件等。可以使用线程池来管理这些定时任务,确保它们按照预定的时间间隔执行。
-
异步I/O操作:对于需要频繁进行I/O操作的应用,例如读写文件或进行网络通信,可以使用线程池来处理这些操作,以提高程序的响应速度和效率。
1.4 线程池有哪些作用
- 资源复用:线程池可以重复使用预先创建好的线程,避免了频繁创建和销毁线程所带来的时间和资源开销。
- 控制并发线程数量:线程池可以限制同时运行的线程数量,避免因为线程过多而导致系统资源耗尽,从而保护系统免受过载的影响。
- 快速响应新任务:线程池中的线程通常处于等待状态,一旦有新的任务提交给线程池,就可以立即执行这些任务,无需等待线程的创建过程。
- 管理线程生命周期:线程池负责管理线程的创建、启动、执行、终止等生命周期事件,简化了线程管理的复杂性。
- 提高系统吞吐量:通过有效管理线程的生命周期和并发度,线程池可以提高系统的整体吞吐量,特别是在处理大量短期任务时表现明显。
- 简化并发编程:线程池提供了一种简单的方式来处理并发任务,开发者只需要关注任务的逻辑,而不需要关心底层线程的管理细节。
- 提供拒绝策略:当线程池无法接受更多任务时,可以采用不同的拒绝策略来处理这些情况,例如丢弃任务、等待队列空间释放或由调用者线程执行任务。
- 方便的扩展性:开发者可以根据需要调整线程池的配置,例如增加或减少线程数量,以适应不断变化的应用需求。
- 降低上下文切换成本:减少了频繁创建和销毁线程所带来的上下文切换次数,从而降低了系统的总体开销。
- 提高线程利用率:通过将空闲线程用于执行新任务,线程池提高了线程的整体利用率。
示例
假设你正在构建一个Web服务器,每当客户端发起一个HTTP请求时,服务器都需要创建一个线程来处理该请求。如果没有使用线程池,服务器可能会遇到以下问题:
- 创建和销毁线程的开销很高。
- 如果并发请求太多,可能会耗尽系统资源,导致服务器崩溃。
通过使用线程池,你可以:
- 限制并发线程的数量,保护服务器不受过载影响。
- 快速响应新请求,因为线程已经在等待状态,可以立即执行任务。
- 提高服务器的整体吞吐量,因为线程可以被复用。
总之,线程池提供了一种高效管理并发任务的方法,它有助于提高系统的性能和稳定性,同时也简化了并发编程的复杂性。
2. 线程池基本用法
2.1 线程池的创建方式
-
可缓存线程池:
Executors.newCachedThreadPool(); -
可定长度 限制最大线程数:
Executors.newFixedThreadPool(); -
可定时:
Executors.newScheduledThreadPool(); -
单例:
Executors.newSingleThreadExecutor();
真实底层都是基于 ThreadPoolExecutor 构造函数封装的线程池
2.2 线程池底层是如何实现复用的
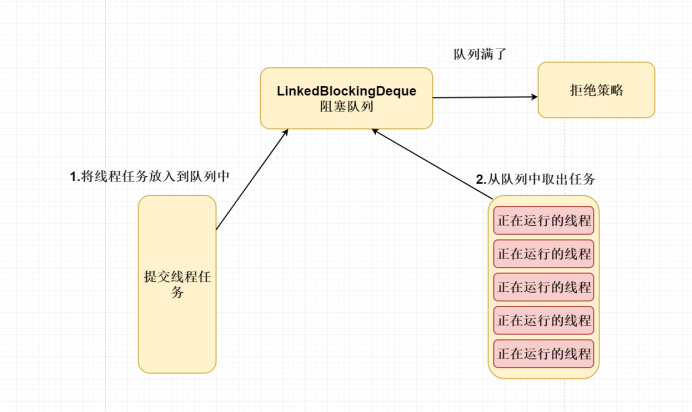
核心复用机制,最多只会创建2个线程,提交10个线程任务到缓存
- 定义一个容器(
LinkedBlockingQueue)缓存提交的线程任务 - 提前创建好固定数量的线程一直在运行状态(2个线程)
- 无界(无限存储元素) 有界(有限制容量存储元素)
- 提交线程任务会存放在
LinkedBlockingQueue中缓存起来 - 一直在运行的线程就会从
LinkedBlockingQueue取出线程任务执行。 - 如果提交线程任务到
LinkedBlockingQueue中存放,如果阻塞队列满了走拒绝策略
线程池缺陷:线程一直在运行状态,可能会消耗到cpu的资源。
本质思想:创建一个线程,不会立马停止或者销毁而是一直实现复用。
- 提前创建固定大小的线程一直保持在正在运行状态;(可能会非常消耗 cpu 的资源)
- 当需要线程执行任务,将该任务提交缓存在并发队列中;如果缓存队列满了,则会执行拒绝策略;
- 正在运行的线程从并发队列中获取任务执行从而实现多线程复用问题;
2.3 简单模拟手写 Java 线程池
import java.util.concurrent.LinkedBlockingQueue;
import java.util.concurrent.TimeUnit;
/**
* @author 赵立
*/
public class TestExecutors {
/**
* 定义一个容器 缓存提交的线程任务
*/
private LinkedBlockingQueue<Runnable> runnables;
/**
* 标记线程运行状态
*/
private volatile boolean isRun = true;
/**
* @param queueSize 队列缓存任务容量的大小
* @param runThreadCount 一直在运行线程的个数
*/
public TestExecutors(int queueSize, int runThreadCount) {
runnables = new LinkedBlockingQueue<>(queueSize);
for (int i = 0; i < runThreadCount; i++) {
new TaskThread().start();
}
}
class TaskThread extends Thread {
@Override
public void run() {
//线程一直在运行状态
while (isRun || runnables.size() > 0) {
Runnable task = null;
try {
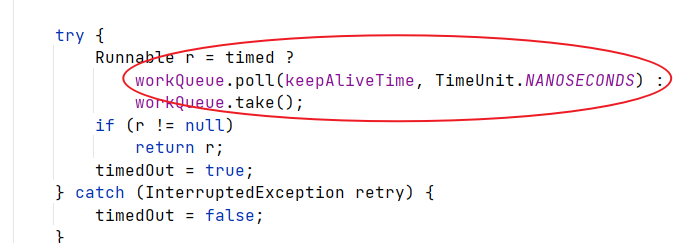
//如果没有任务,则阻塞 3s 后再继续运行,避免了 cpu 飙高的问题
task = runnables.poll(3, TimeUnit.SECONDS);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
if (task != null) {
task.run();
}
}
}
}
/**
* 提交线程任务
*/
void execute(Runnable runnable) {
runnables.offer(runnable);
}
/**
* 停止当前的线程池
*/
public void shutdown() {
this.isRun = false;
}
public static void main(String[] args) {
TestExecutors testExecutors = new TestExecutors(4, 2);
for (int i = 0; i < 10; i++) {
int finalI = i;
testExecutors.execute(() -> {
System.out.println(Thread.currentThread().getName() + " 执行任务" + finalI);
});
}
testExecutors.shutdown();
}
}
3. 线程池的原理
3.1 核心线程数一直在运行状态如何避免cpu飙高问题
-
线程池中核心线程在运行中从队列中取出任务,如果队列中是为空的话,则当前线程会阻塞,主动的释放cpu执行权。
-
如果有另外的线程提交向线程池中提交新的任务,则当前核心线程会被主动唤醒起来 ,从队列中取出该任务执行。
3.2 ThreadPoolExecutor 构造函数的核心参数
核心参数介绍:
-
corePoolSize:核心线程数量,一直正在保持运行的线程 -
maximumPoolSize:最大线程数,线程池允许创建的最大线程数。必须满足最大线程数>=核心线程数
比如说核心线程数量是为 2 ,它一直在运行状态,最大线程数是 4 是指当我们队列容量满了就触发创建线程,最多可以创建多少个线程帮忙执行任务:最大线程数(4)- 核心线程数量(2), 额外在创建2个线程来帮忙
-
keepAliveTime:超出corePoolSize后创建的线程的存活时间,即没有任务执行的情况下经过keepAliveTime后停止执行 -
unit:keepAliveTime的时间单位。 -
workQueue:任务队列,用于保存待执行的任务。即存放缓存提交的任务 -
threadFactory:线程池内部创建线程所用的工厂。即线程池内部工厂 自定义线程池 -
handler:任务无法执行时的处理器。即当我们队列满了,走其他处理策略
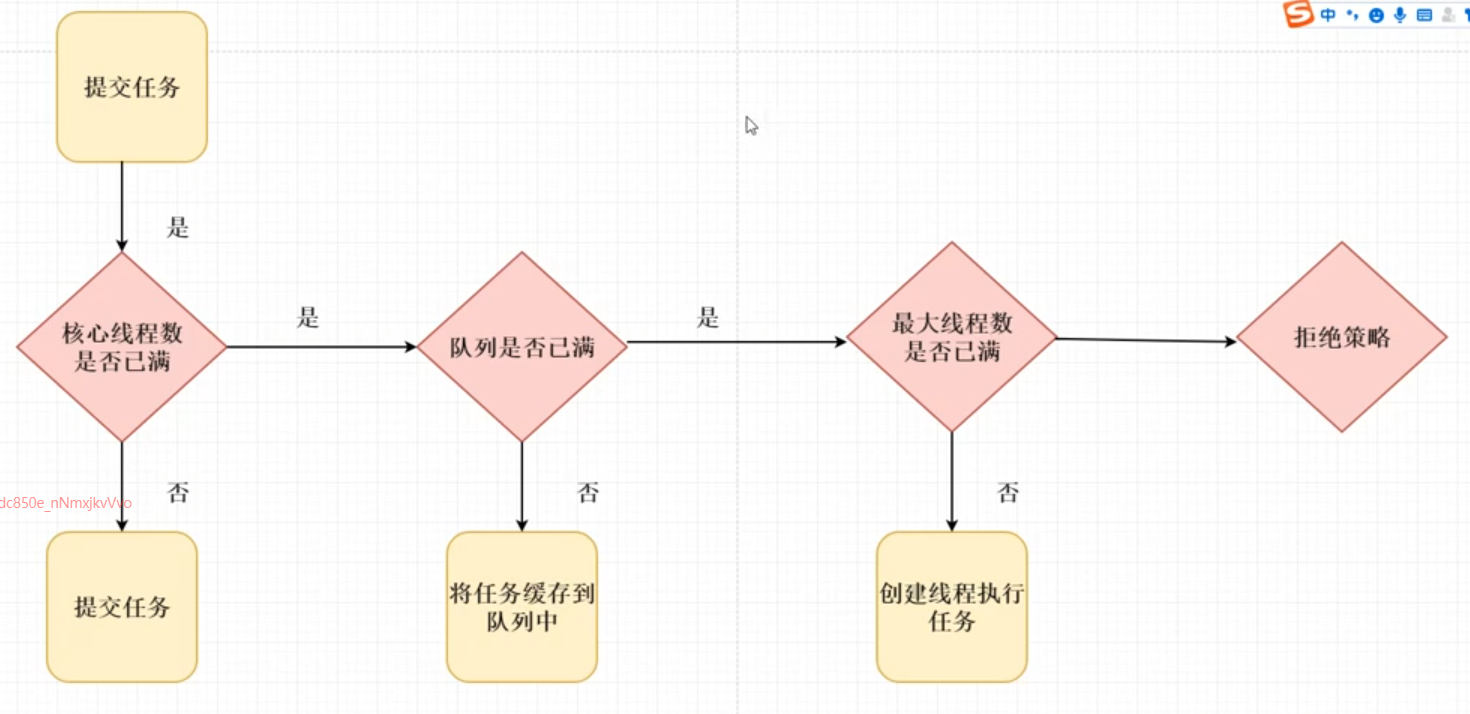
核心原理:
-
提交任务的时候比较核心线程数,如果当前任务数量小于核心线程数的情况下,则直接复用线程执行。
-
如果任务量大于核心线程数,则缓存到队列中。
-
如果缓存队列满了,且任务数小于最大线程数的情况下,则创建额外线程执行。
-
如果队列和最大线程数都满的情况下,则走拒绝策略。
注意:最大线程数,在一定时间没有执行任务则会被销毁,避免浪费cpu内存。
jdk官方的专业术语:
-
当线程数小于核心线程数时,创建线程。
-
当线程数大于等于核心线程数,且任务队列未满时,将任务放入任务队列。
-
当线程数大于等于核心线程数,且任务队列已满
-
若线程数小于最大线程数,创建线程
-
若线程数等于最大线程数,抛出异常,拒绝任务
-
3.3 阿里巴巴java开发手册中不推荐使用jdk自带线程池
因为默认的 Executors 线程池底层是基于 ThreadPoolExecutor 构造函数封装的,采用无界队列存放缓存任务,会无限缓存任务容易发生 内存溢出,会导致我们最大线程数会失效。

3.4 线程池拒绝策略
如果队列满了,且任务总数>最大线程数则当前线程走拒绝策略。可以自定义异拒绝异常
rejectedExecutionHandler:任务拒绝处理器
两种情况会拒绝处理任务:
-
当线程数已经达到
maxPoolSize,切队列已满,会拒绝新任务 -
当线程池被调用
shutdown()后,会等待线程池里的任务执行完毕,再shutdown()。如果在调用shutdown()和线程池执行shutdown()之间提交任务,会拒绝新任务。
线程池会调用rejectedExecutionHandler来处理这个任务。如果没有设置,默认是AbortPolicy,会抛出异常。
ThreadPoolExecutor类有几个内部实现类来处理拒绝任务:
-
AbortPolicy丢弃任务,抛运行时异常 -
CallerRunsPolicy执行任务,主线程执行此任务** -
DiscardPolicy忽视,什么都不会发生 -
DiscardOldestPolicy从队列中踢出最先进入队列(最后一个执行)的任务 -
实现
RejectedExecutionHandler接口,可自定义处理器 (推荐使用)- 队列满的话可以将任务记录到本地磁盘或者网络中保存,后期可以直接使用人工补偿的形式。
public class TestThreadPoolExecutor {
public static ExecutorService newFixedThreadPool() {
return new ThreadPoolExecutor(2,
4,
0L,
TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<>(2),
new TestRejectedExecutionHandler());
}
public static void main(String[] args) {
ExecutorService executorService = TestThreadPoolExecutor.newFixedThreadPool();
for (int i = 0; i < 10; i++) {
int finalI = i;
executorService.execute(() -> System.out.println(Thread.currentThread().getName() + "," + finalI));
}
}
}
public class TestRejectedExecutionHandler implements RejectedExecutionHandler {
@Override
public void rejectedExecution(Runnable r, ThreadPoolExecutor executor) {
System.out.println("任务被拒绝!");
r.run();
}
}
3.5 自定义线程池名称
目的:有时候为了快速定位出现错误的位置,在采用线程池时我们需要自定义线程池的名称。
创建ThreadFactory(ThreadPoolExecutor默认采用的是DefaultThreadFactory,可以参照代码)
public class TestThreadPoolExecutor {
public static ExecutorService newFixedThreadPool() {
return new ThreadPoolExecutor(2,
4,
0L,
TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<>(2),
new TestNamedThreadFactory(),
new TestRejectedExecutionHandler());
}
public static void main(String[] args) {
ExecutorService executorService = TestThreadPoolExecutor.newFixedThreadPool();
for (int i = 0; i < 10; i++) {
int finalI = i;
executorService.execute(() -> System.out.println(Thread.currentThread().getName() + "," + finalI));
}
}
}
import java.util.concurrent.ThreadFactory;
import java.util.concurrent.atomic.AtomicInteger;
public class TestNamedThreadFactory implements ThreadFactory {
private static final AtomicInteger poolNumber = new AtomicInteger(1);
private final ThreadGroup group;
private final AtomicInteger threadNumber = new AtomicInteger(1);
private final String namePrefix;
TestNamedThreadFactory() {
SecurityManager s = System.getSecurityManager();
group = (s != null) ? s.getThreadGroup() :
Thread.currentThread().getThreadGroup();
namePrefix = "test" +
poolNumber.getAndIncrement() +
"-thread-";
}
public Thread newThread(Runnable r) {
Thread t = new Thread(group, r,
namePrefix + threadNumber.getAndIncrement(),
0);
if (t.isDaemon())
t.setDaemon(false);
if (t.getPriority() != Thread.NORM_PRIORITY)
t.setPriority(Thread.NORM_PRIORITY);
return t;
}
}
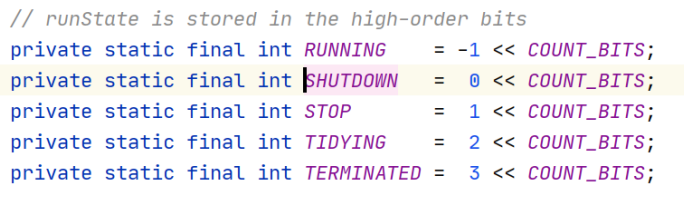
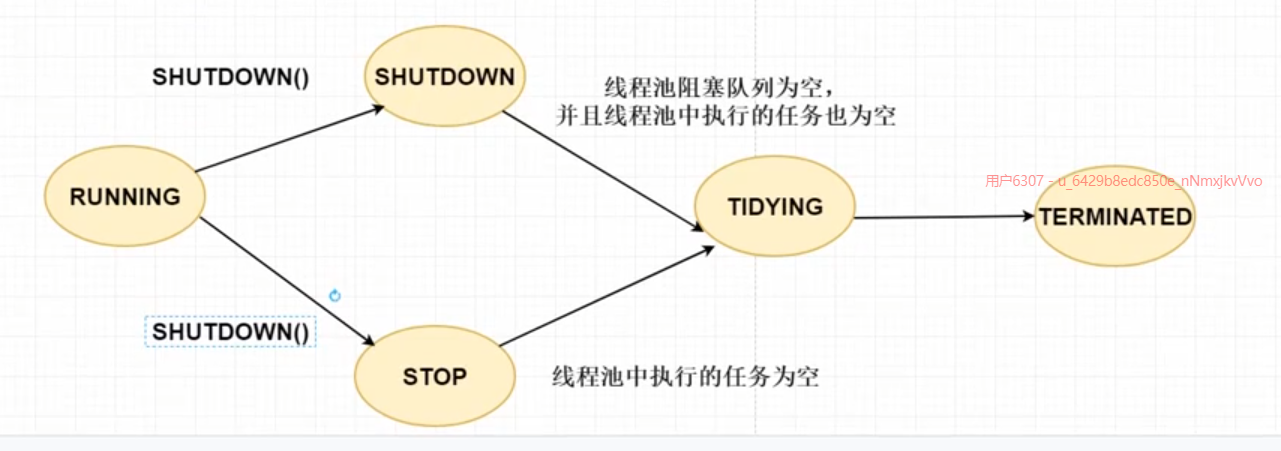
3.6 线程池五种状态
线程池的5种状态:Running、ShutDown、Stop、Tidying、Terminated
线程池内部的5种状态
-
RUNNING:线程池能够接受新任务,以及对新添加的任务进行处理。- 状态说明:线程池处在
RUNNING状态时,能够接收新任务,以及对已添加的任务进行处理。 - 状态切换:线程池的初始化状态是
RUNNING。换句话说,线程池被一旦被创建,就处于RUNNING状态,并且线程池中的任务数为0!
- 状态说明:线程池处在
-
SHUTDOWN:线程池不可以接受新任务,但是可以对已添加的任务进行处理。-
状态说明:线程池处在
SHUTDOWN状态时,不接收新任务,但能处理已添加的任务。 -
状态切换:调用线程池的
shutdown()接口时,线程池由RUNNING=>SHUTDOWN。
-
-
stop:线程池不接收新任务,不处理已添加的任务,并且会中断正在处理的任务。工作线程停止-
状态说明:线程池处在
STOP状态时,不接收新任务,不处理已添加的任务,并且会中断正在处理的任务。 -
状态切换:调用线程池的
shutdownNow()接口时,线程池由(RUNNINGorSHUTDOWN) =>STOP。
-
-
TIDYING-
状态说明:当所有的任务已终止,
ctl记录的”任务数量”为0,线程池会变为TIDYING状态。当线程池变为TIDYING状态时,会执行钩子函数terminated()。terminated()在ThreadPoolExecutor类中是空的,若用户想在线程池变为TIDYING时,进行相应的处理;可以通过重载terminated()函数来实现。 -
状态切换:当线程池在
SHUTDOWN状态下,阻塞队列为空并且线程池中执行的任务也为空时,就会由SHUTDOWN=>TIDYING。当线程池在STOP状态下,线程池中执行的任务为空时,就会由STOP=>TIDYING。
-
-
TERMINATED:线程池彻底终止的状态。-
状态说明:线程池彻底终止,就变成
TERMINATED状态。 -
状态切换:线程池处在
TIDYING状态时,执行完terminated()之后,就会由TIDYING=>TERMINATED。
-
3.7 线程池参数如何配置
CPU密集型与IO密集型区别
Cpu密集型:当前线程做大量的程序计算;
-
CPU密集型也叫计算密集型,指的是系统的硬盘、内存性能相对CPU要好很多,此时,系统运作大部分的状况是CPU Loading 100%,CPU要读/写I/O(硬盘/内存),I/O在很短的时间就可以完成,而CPU还有许多运算要处理,CPU Loading很高。
-
在多重程序系统中,大部份时间用来做计算、逻辑判断等CPU动作的程序称之CPU bound。例如一个计算圆周率至小数点一千位以下的程序,在执行的过程当中绝大部份时间用在三角函数和开根号的计算,便是属于CPU bound的程序。
-
CPU bound的程序一般而言CPU占用率相当高。这可能是因为任务本身不太需要访问I/O设备,也可能是因为程序是多线程实现因此屏蔽掉了等待I/O的时间。
-
cpu 密集型(CPU-bound)线程池设计: 最佳线程数=cpu核数或者cpu核数±1
IO密集型:linux内核会发生用户态到内核态切换过程;
-
IO密集型:比如当前线程读文件、写文件、传输文件、网络请求属于密集型;
-
IO密集型指的是系统的CPU性能相对硬盘、内存要好很多,此时,系统运作,大部分的状况是CPU在等I/O (硬盘/内存) 的读/写操作,此时CPU Loading并不高。
-
I/O bound的程序一般在达到性能极限时,CPU占用率仍然较低。这可能是因为任务本身需要大量I/O操作,而pipeline做得不是很好,没有充分利用处理器能力。比如接收一个前端请求=>解析参数=>查询数据库=>返回给前端这样的,那么就是IO密集型的,例如web应用。
-
I/O密集型(I/O-bound)线程池设计:最佳线程数目 = ((线程等待时间+线程CPU时间)/线程CPU时间 ) CPU数目*
线程等待时间所占比例越高,需要越多线程。线程CPU时间所占比例越高,需要越少线程。
假如一个程序平均每个线程CPU运行时间为0.5s,而线程等待时间(非CPU运行时间,比如IO)为1.5s,CPU核心数为16,那么最佳的线程数应该是? 核心线程数==64
根据上面这个公式估算得到最佳的线程数:((0.5+1.5)/0.5)*16=64。
3.8 SpringBoot项目中如何整合线程池
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.core.task.TaskExecutor;
import org.springframework.scheduling.concurrent.ThreadPoolTaskExecutor;
import java.util.concurrent.ThreadPoolExecutor;
@Configuration
public class ZhaoliThreadPoolConfig {
/**
* 线程核心数
*/
@Value("${zhaoli.thread.corePoolSize}")
private int corePoolSize;
/**
* 线程最大数
*/
@Value("${zhaoli.thread.maxPoolSize}")
private int maxPoolSize;
/**
* 任务容量
*/
@Value("${zhaoli.thread.queueCapacity}")
private int queueCapacity;
/**
* 允许空闲时间,默认60
*/
@Value("${zhaoli.thread.keepAlive}")
private int keepAlive;
@Bean
public TaskExecutor zhaoliTaskExecutor() {
ThreadPoolTaskExecutor threadPoolTaskExecutor = new ThreadPoolTaskExecutor();
threadPoolTaskExecutor.setCorePoolSize(corePoolSize);
threadPoolTaskExecutor.setMaxPoolSize(maxPoolSize);
threadPoolTaskExecutor.setQueueCapacity(queueCapacity);
threadPoolTaskExecutor.setKeepAliveSeconds(keepAlive);
threadPoolTaskExecutor.setThreadNamePrefix("zhaoliThread-");
//设置拒绝策略 当线程数达到最大时,如何处理新任务
//CallerRunsPolicy 不由线程池中线程执行,由调用者所在线程执行
threadPoolTaskExecutor.setRejectedExecutionHandler(new ThreadPoolExecutor.CallerRunsPolicy());
threadPoolTaskExecutor.setWaitForTasksToCompleteOnShutdown(true);
return threadPoolTaskExecutor;
}
}
在需要异步执行的方法上加上@Async("zhaoliTaskExecutor")注解,该注解中指定的线程池名称就是我们自定义线程池中的zhaoliTaskExecutor()方法对应的Bean的名称。











![[机器学习]04-逻辑回归(python)-03-API与癌症分类案例讲解](https://i-blog.csdnimg.cn/direct/65afbb877d674c2daab91f18d7b6352c.png)