每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领域的领跑者。点击订阅,与未来同行! 订阅:https://rengongzhineng.io/

谷歌今天发布了两款升级版Gemini模型:Gemini-1.5-Pro-002和Gemini-1.5-Flash-002,同时推出了以下更新:
- 1.5 Pro模型的价格降低了50%(适用于输入和输出token少于128K的提示)
- 1.5 Flash的速率上限提高了2倍,1.5 Pro的速率上限提高了约3倍
- 输出速度提高了2倍,延迟减少了3倍
- 默认过滤设置进行了更新
这些新模型是在今年5月Google I/O大会上发布的Gemini 1.5模型的基础上进行了重大改进。开发者可以通过Google AI Studio和Gemini API免费访问这些最新模型,谷歌云的客户和大企业用户也可以在Vertex AI上使用。
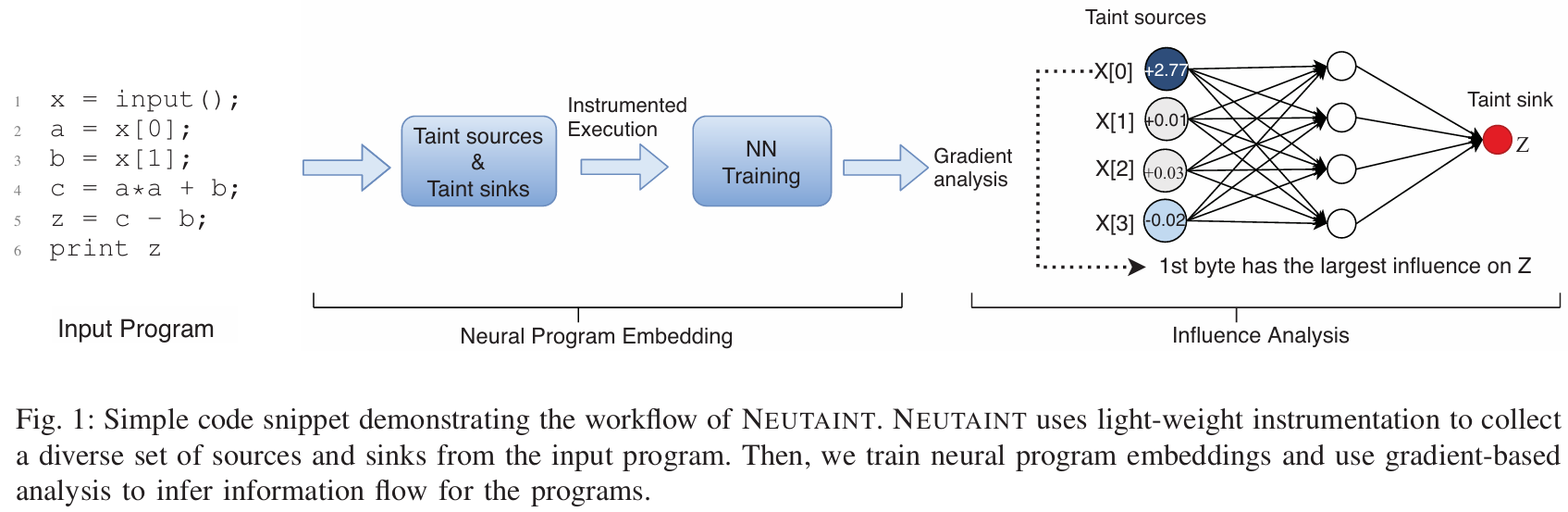
总体性能提升,尤其是在数学、长文本处理和视觉任务方面
Gemini 1.5系列模型专为广泛的文本、代码和多模态任务而设计。例如,Gemini模型可以处理1000页的PDF文件、回答包含超过1万行代码的仓库问题、解析时长一小时的视频,并从中生成有用的内容。
这次更新让1.5 Pro和Flash模型在生产环境中的性能更好、速度更快、成本更低。据测试数据显示,1.5 Pro在MMLU-Pro基准测试中的表现提升了约7%,在MATH和HiddenMath竞赛数学题的测试中,两个模型都提升了约20%。在视觉理解和Python代码生成方面,模型的性能也有所提升,幅度在2-7%之间。
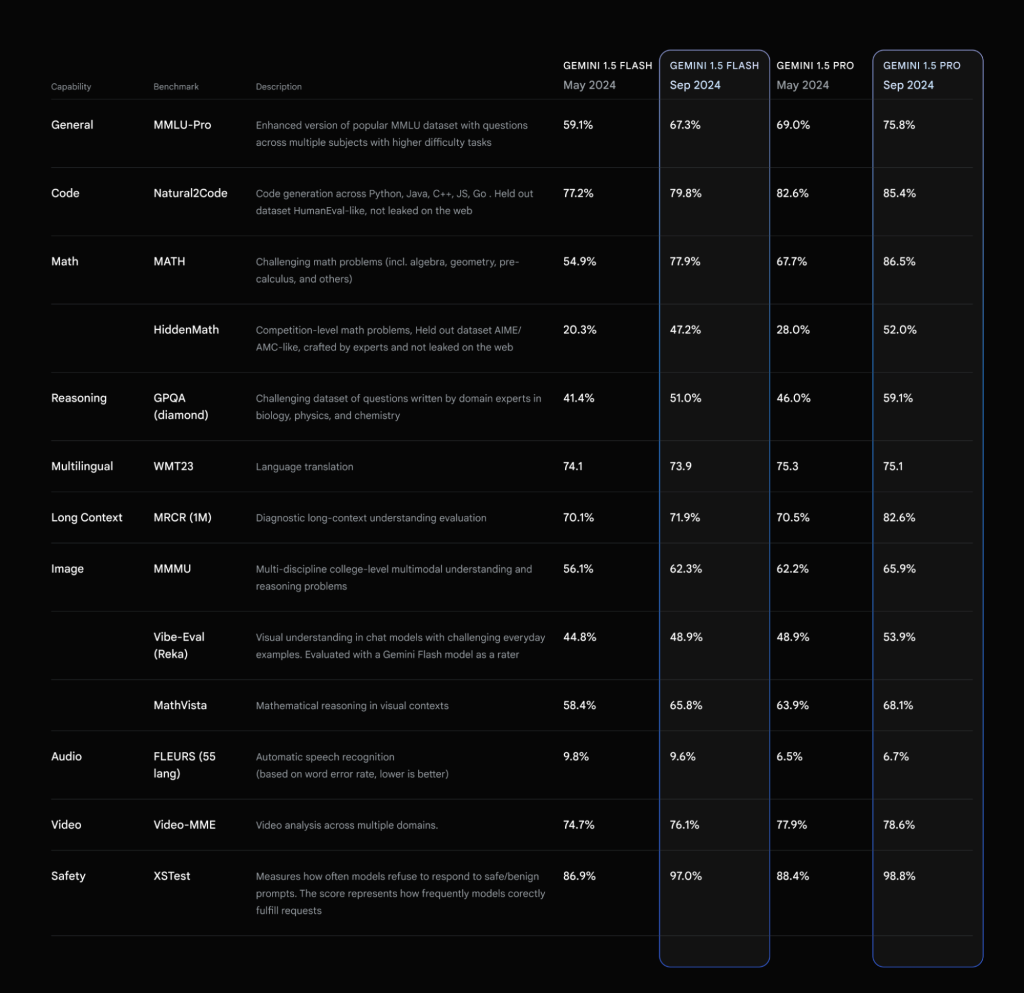
模型的响应风格也变得更加简洁,开发者反馈的这一改进意在降低使用成本。例如,在总结、问答和信息提取任务中,输出长度相比之前的模型缩短了5-20%。对于需要长文本输出的聊天类产品,谷歌提供了提示策略指南,帮助用户获得更详细的回应。
Gemini 1.5 Pro模型
Gemini 1.5 Pro的2百万token长上下文窗口和多模态功能让人眼前一亮,从视频理解到处理1000页PDF,仍有许多未被发掘的新用例。今天,谷歌宣布1.5 Pro的输入token价格降低64%,输出token价格降低52%,缓存token价格降低64%,这些调整将于2024年10月1日生效,适用于少于128K token的提示。结合上下文缓存,这大大降低了使用Gemini的成本。

速率限制增加
为了让开发者更轻松地使用Gemini,谷歌将1.5 Flash的付费级速率上限提高到2000 RPM,而1.5 Pro提高到1000 RPM,相比之前分别是1000和360。在接下来的几周内,谷歌还将继续提升Gemini API的速率限制。
更快的输出和更低的延迟
在核心模型改进的同时,谷歌也在过去几周内降低了1.5 Flash的延迟,大幅提升了每秒输出的token数量,解锁了更多的应用场景。
更新的过滤设置
自2023年12月首次发布以来,Gemini系列一直致力于构建一个安全可靠的模型。在今天发布的-002版本中,模型在遵循用户指令的同时进一步平衡了安全性。开发者可以根据自己的需求配置这些安全过滤器,默认情况下,新版本模型将不会自动应用过滤器。
Gemini 1.5 Flash-8B实验性更新
谷歌还发布了“Gemini-1.5-Flash-8B-Exp-0924”实验版本,该版本在文本和多模态任务中的表现有显著提升,现已通过Google AI Studio和Gemini API开放使用。
开发者对1.5 Flash-8B模型的反馈十分积极,谷歌将继续根据这些反馈改进从实验到生产的发布流程。
谷歌对这些更新充满期待,迫不及待想看看大家用新版Gemini模型会开发出什么样的应用!对于Gemini Advanced用户,未来将能访问优化聊天功能的Gemini 1.5 Pro-002版本。