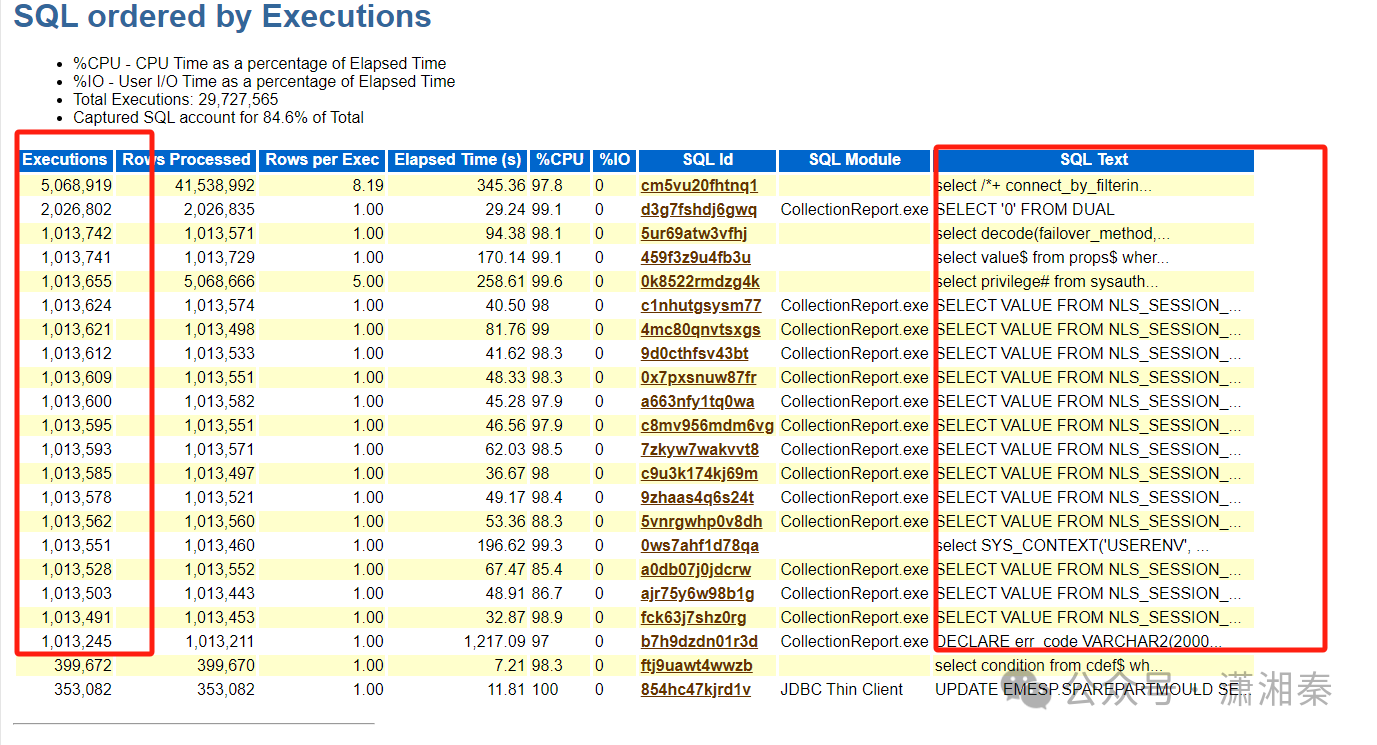
前言:
一、财会与人工智能之间的联系
人工智能是计算机科学的一个分支,旨在模拟人类智能。自20世纪50年代起,AI经历了多个发展阶段,从规则基础系统到现在的深度学习技术,已经在医疗、制造、金融等多个行业得到广泛应用。大语言模型是一种基于深度学习的AI工具,能够理解和生成自然语言文本。它们通过大规模数据集进行训练,能够执行多种任务,如文本生成、翻译和问答。GPT和BERT是当前最流行的模型。AI技术可以显著提高财务管理的效率。通过自动化数据处理和分析,财务人员可以节省时间并减少错误。此外,AI可以在财务报告生成中提供实时更新,提高决策的准确性。大语言模型通过对财务文本(如报告、新闻、社交媒体等)的分析,能够提取有价值的信息,支持财务决策。它们在预测分析中能够处理大量数据,从而为投资决策提供更好的支持。
1.2 代码运行环境的一件安装
二、使用pandas实现对excel表格数据的读取写入操作
在现代数据分析中,Excel表格因其易用性和广泛的应用而成为数据存储和处理的重要工具。无论是财务报告、销售数据还是市场调研,Excel都是分析师和决策者常用的数据格式。为了有效地处理和分析这些数据,Python的pandas库提供了强大的功能,使得读取和写入Excel文件变得简单而高效。
pandas库简介:
pandas是Python中用于数据处理和分析的强大库,特别适合处理表格数据。它提供了DataFrame和Series等数据结构,能够方便地进行数据操作、清洗和分析。
Excel文件格式:
Excel支持多种文件格式,其中最常见的是.xlsx和.xls。了解这些格式有助于选择合适的工具进行数据操作。
读取Excel数据:
使用pandas的read_excel()函数,可以轻松读取Excel文件中的数据,并将其加载到DataFrame中。可以选择读取特定的工作表、指定列、处理缺失值等。
写入Excel数据:
pandas的to_excel()函数允许将DataFrame写入Excel文件。可以设置文件名、工作表名和其他格式选项,使数据输出符合需求。
数据处理操作:
在加载数据后,可以使用pandas的多种功能进行数据处理,例如过滤、分组、聚合、合并等。这些操作能够帮助用户从数据中提取有价值的信息。
实践应用:
通过实际案例,例如财务数据分析、销售趋势报告等,可以展示如何利用pandas进行数据的读取、处理和输出,增强对数据的理解和分析能力。
2.1制造假数据
-
数据生成:利用
Faker库生成随机的中文姓名,结合random库随机生成学生的班级号和各科目成绩(语文、数学、英语、科学)。通过定义generate_data函数,可以灵活生成任意数量的学生数据。 -
数据存储:将生成的假数据存储在列表中,随后使用
pandas库将其转换为DataFrame格式。这种结构化的数据格式便于后续处理和分析。 -
Excel输出:通过
pandas的to_excel方法,将DataFrame中的数据写入Excel文件,方便用户进行查看和进一步的操作。 -
实用性:生成的模拟数据可用于测试数据分析工具、展示数据处理流程,或在教育和研究中作为样本数据进行教学和实验
import random
import pandas as pd
from faker import Faker
# 初始化 Faker
fake = Faker('zh_CN') # 使用中文
# 定义班级范围
classes = [1, 2, 3, 4, 5]
# 生成成绩的函数
def generate_score(min_score=50, max_score=100):
return random.randint(min_score, max_score)
# 生成假数据
def generate_data(num_records):
data = []
for _ in range(num_records):
student_name = fake.name() # 生成中文姓名
student_class = random.choice(classes)
chinese_score = generate_score()
math_score = generate_score()
english_score = generate_score()
science_score = generate_score()
data.append({
'姓名': student_name,
'班级号': student_class,
'语文成绩': chinese_score,
'数学成绩': math_score,
'英语成绩': english_score,
'科学成绩': science_score
})
return data
# 生成 1 万条数据
num_records = 10000
data = generate_data(num_records)
# 转换为 DataFrame
df = pd.DataFrame(data)
# 写入 Excel
df.to_excel('一万条学生成绩数据.xlsx', index=False)
print(f"已成功生成 {num_records} 条学生成绩数据,并写入到 Excel 文件中。")
2.2 pandas基础知识点说明
-
导入pandas库:
import pandas as pd:导入pandas库,使用简写pd来调用其功能,便于后续的数据操作。
-
读取Excel文件:
pd.read_excel('一万条学生成绩数据.xlsx'):读取指定的Excel文件并将其内容加载到DataFrame中,方便进行数据分析和处理。
-
查看数据的前几行:
df.head(1):默认显示前五行(可以指定参数显示任意数量的行),帮助用户快速了解数据的结构和内容。
-
获取数据的基本信息:
df.info():输出DataFrame的基本信息,包括行数、列数、每列的数据类型以及非空值的数量,帮助理解数据的整体情况。
-
统计描述性统计信息:
df.describe():计算数值型数据的描述性统计信息,包括均值、标准差、最小值、最大值和分位数等,便于分析数据分布情况。
-
班级分布统计:
df['班级号'].value_counts():统计每个班级的学生数量,返回一个Series,其中索引为班级号,值为对应的学生数量。
-
找出成绩最高的学生:
df.nlargest(5, '数学成绩'):使用nlargest方法找出“数学成绩”最高的5名学生,返回对应的DataFrame。
-
计算总成绩:
df['总成绩'] = ...:新增一列“总成绩”,通过将所有科目的成绩相加来计算,方便后续的分析和比较。
-
显示添加新列后的数据:
df.head():显示添加新列后DataFrame的前五行,帮助确认新增列的正确性。
-
保存修改后的数据到新的Excel文件:
df.to_excel('一万条学生成绩数据_修改后.xlsx', index=False):将修改后的DataFrame保存到新的Excel文件中,不保存行索引,以便于后续使用。
-
按总成绩排序找出最高的学生:
df.nlargest(10, '总成绩'):使用nlargest方法找出“总成绩”最高的前10名学生,返回对应的DataFrame
import pandas as pd
# 1. 读取 Excel 文件
df = pd.read_excel('一万条学生成绩数据.xlsx')
# 2. 查看数据的前几行,了解数据的结构
print("数据的前五行:")
print(df.head(1)) # 默认显示前五行
# 3. 获取数据的基本信息,包括行数、列数、每列的数据类型
print("\n数据的基本信息:")
print(df.info())
# 4. 统计每列的描述性统计信息(包括均值、最小值、最大值等)
print("\n数据的描述性统计信息:")
print(df.describe())# 查这个里面到底包含了那些信息
# 5. 统计班级的分布情况(每个班级有多少学生)
print("\n每个班级的学生数量:")
print(df['班级号'].value_counts())
# 6. 找出某一列中成绩最高的几名学生,比如数学成绩最高的 5 名学生
top_math_students = df.nlargest(5, '数学成绩')
print("\n数学成绩最高的5名学生:")
print(top_math_students)
# 7. 增加一列 "总成绩",将所有科目的成绩相加
df['总成绩'] = df['语文成绩'] + df['数学成绩'] + df['英语成绩'] + df['科学成绩']
print("\n增加 '总成绩' 后的数据前五行:")
print(df.head())
# 8. 保存修改后的数据到新的 Excel 文件
# df.to_excel('一万条学生成绩数据_修改后.xlsx', index=False)
# 8. 按照总成绩进行排序,找出成绩最高的前 10 名学生
top_students = df.nlargest(10, '总成绩')
print("\n总成绩最高的10名学生:")
print(top_students)
2.3按照班级进行分组、计算每个班级的平均成绩
import pandas as pd
# 1. 读取 Excel 文件
df = pd.read_excel('一万条学生成绩数据.xlsx')
# 9. 按班级进行分组,计算每个班级的平均成绩
# 我们只对与成绩相关的列进行平均计算
class_avg_scores = df.groupby('班级号')[['语文成绩', '数学成绩', '英语成绩', '科学成绩']].mean()
print("\n每个班级的平均成绩:")
print(class_avg_scores)三、使用matplotlib实现对报表信息的可视化操作
3.1 绘制班级的各科平均成绩柱状图
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib
matplotlib.use('TkAgg') # 设置后端为交互式的 TkAgg
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 解决负号 '-' 显示为方块的问题
#import seaborn as sns
# 1. 读取 Excel 文件
df = pd.read_excel('一万条学生成绩数据.xlsx')
# 2. 设置 seaborn 风格
# sns.set(style="whitegrid")
# 3. 统计每个班级的平均成绩
class_avg_scores = df.groupby('班级号')[['语文成绩', '数学成绩', '英语成绩', '科学成绩']].mean()
print(class_avg_scores)
# 4. 绘制班级的各科平均成绩柱状图
class_avg_scores.plot(kind='bar', figsize=(10, 6))
plt.title('班级平均成绩', fontsize=16)
plt.xlabel('班级号', fontsize=12)
plt.ylabel('平均成绩', fontsize=12)
plt.xticks(rotation=0)
plt.show()3.2 绘制数学成绩的分布直方图
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib
matplotlib.use('TkAgg') # 设置后端为交互式的 TkAgg
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 解决负号 '-' 显示为方块的问题
# 1. 读取 Excel 文件
df = pd.read_excel('一万条学生成绩数据.xlsx')
# 4. 绘制数学成绩的分布直方图
plt.figure(figsize=(10, 6))
plt.hist(df['数学成绩'], bins=10, color='skyblue', edgecolor='black')
plt.title('数学成绩分布', fontsize=16)
plt.xlabel('数学成绩', fontsize=12)
plt.ylabel('学生数量', fontsize=12)
plt.grid(True) # 显示网格线
plt.tight_layout()
plt.show()3.3绘制成绩的合图
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib
matplotlib.use('TkAgg') # 设置后端为交互式的 TkAgg
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 解决负号 '-' 显示为方块的问题
# 1. 读取 Excel 文件
df = pd.read_excel('一万条学生成绩数据.xlsx')
# 5. 绘制语文、数学、英语、科学成绩的盒图(boxplot)
plt.figure(figsize=(10, 6))
plt.boxplot([df['语文成绩'], df['数学成绩'], df['英语成绩'], df['科学成绩']], labels=['语文', '数学', '英语', '科学'])
plt.title('各科成绩的分布情况', fontsize=16)
plt.xlabel('科目', fontsize=12)
plt.ylabel('成绩', fontsize=12)
plt.grid(True)
plt.tight_layout()
plt.show()3.4绘制每个班级总成绩的均值折线图
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib
matplotlib.use('TkAgg') # 设置后端为交互式的 TkAgg
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 解决负号 '-' 显示为方块的问题
# 1. 读取 Excel 文件
df = pd.read_excel('一万条学生成绩数据.xlsx')
df['总成绩'] = df[['语文成绩', '数学成绩', '英语成绩', '科学成绩']].sum(axis=1)
class_total_avg = df.groupby('班级号')['总成绩'].mean()
plt.figure(figsize=(10, 6))
plt.plot(class_total_avg.index, class_total_avg.values, marker='o', linestyle='-', color='b')
plt.title('每个班级的总成绩均值', fontsize=16)
plt.xlabel('班级号', fontsize=12)
plt.ylabel('总成绩均值', fontsize=12)
plt.grid(True)
plt.tight_layout()
plt.show()4预测
线性回归是一种统计学方法,用于建模自变量与因变量之间的线性关系。在本例中,年份作为自变量,收入作为因变量。线性回归的核心假设是:因变量可以通过自变量的线性组合来预测。模型的目标是找到最佳拟合线,使得所有预测值与实际值之间的平方误差最小。

import numpy as np
from sklearn.linear_model import LinearRegression
# 示例历史收入数据
years = np.array([[1], [2], [3], [4], [5]]) # 年份
revenues = np.array([100, 150, 200, 250, 300]) # 收入
# 创建线性回归模型
model = LinearRegression()
model.fit(years, revenues)
# 预测第六年的收入
predicted_revenue = model.predict(np.array([[6]]))
print(f"预测第六年的收入: {predicted_revenue[0]}")
预测未来五年加绘图
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
import matplotlib
matplotlib.use('TkAgg')
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 解决负号 '-' 显示为方块的问题
# 示例历史收入数据
years = np.array([[1], [2], [3], [4], [5]]) # 年份
revenues = np.array([100, 150, 200, 250, 300]) # 收入
# 创建线性回归模型
model = LinearRegression()
model.fit(years, revenues)
# 预测第六年的收入
predicted_revenue = model.predict(np.array([[6]]))
# 预测未来五年的收入
future_years = np.array([[7], [8], [9], [10], [11]])
future_revenues = model.predict(future_years)
# 合并历史和未来数据用于绘图
all_years = np.vstack((years, future_years))
all_revenues = np.hstack((revenues, future_revenues))
# 绘制折线图
plt.figure(figsize=(10, 6))
plt.plot(all_years, all_revenues, marker='o', label='预测收入', color='blue')
plt.axvline(x=6, linestyle='--', color='red', label='第六年预测')
plt.title('收入预测')
plt.xlabel('年份')
plt.ylabel('收入')
plt.xticks(np.arange(1, 12, 1)) # 设置x轴刻度
plt.yticks(np.arange(100, 351, 50)) # 设置y轴刻度
plt.legend()
plt.grid()
plt.show()
# 输出预测结果
print(f"预测第六年的收入: {predicted_revenue[0]}")
print("未来五年的收入预测:", future_revenues.flatten())
自动化报表生成
import pandas as pd
# 示例数据
data = {
'日期': ['2024-01-01', '2024-01-02', '2024-01-03'],
'收入': [1000, 1500, 2000],
'支出': [400, 600, 800]
}
# 创建DataFrame
df = pd.DataFrame(data)
# 计算利润
df['利润'] = df['收入'] - df['支出']
# 打印财务报表
print("财务报表:")
print(df)
风险评估
import pandas as pd
# 示例交易数据
transactions = {
'交易ID': [1, 2, 3, 4],
'金额': [500, 15000, 300, 7000]
}
# 创建DataFrame
df_transactions = pd.DataFrame(transactions)
# 设置风险阈值
threshold = 1000
# 风险评估
df_transactions['风险'] = df_transactions['金额'] > threshold
# 打印风险评估结果
print("交易风险评估:")
print(df_transactions)
参考文献