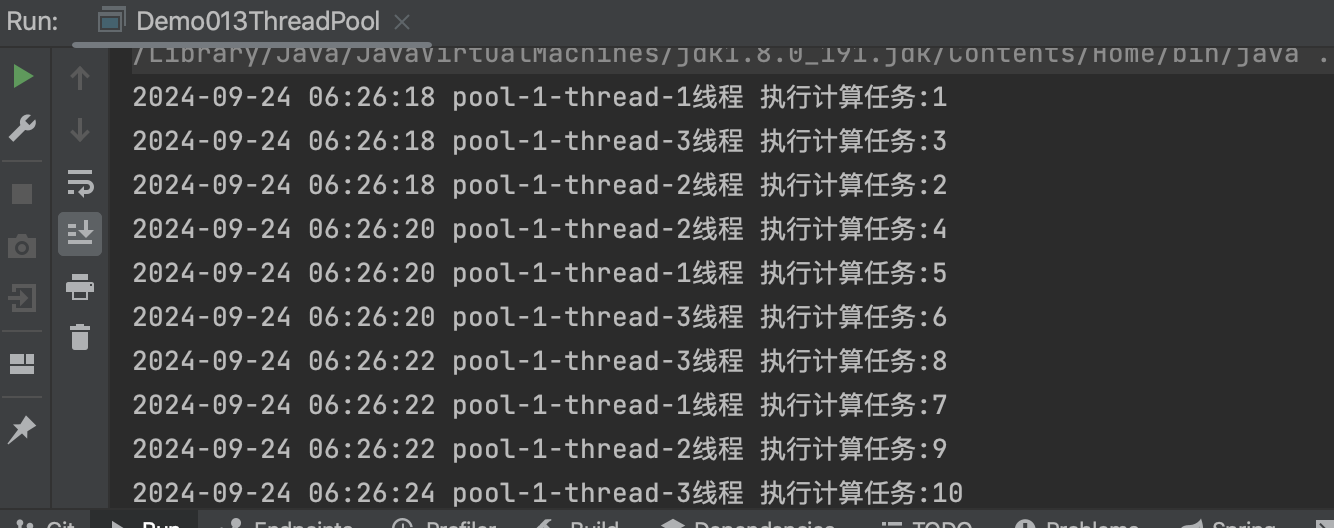
进入Scala模式
终端里输入Scala
创建一个新的Scala文件
vim 文件名.scala
复制粘贴代码
ctrl+shift c/v
使用vim
先进入插入模式,可以通过按i键来实现,然后粘贴代码,完成后按Esc键退出插入模式,保存并退出可以通过输入:wq然后按Enter键。
编译运行程序
scalac 文件名.scala
scala 文件名终端退出scala模式
:quit / :exit删除在vim里写好的代码
-
删除字符或单词:
- 在普通模式(Normal mode)下,你可以使用
x命令来删除光标所在位置的单个字符。 - 要删除一个单词,首先使用
w命令将光标移动到单词的末尾,然后使用x来删除整个单词。
- 在普通模式(Normal mode)下,你可以使用
-
删除一行:
- 在普通模式下,使用
dd命令删除光标所在的整行。
- 在普通模式下,使用
-
删除多行:
- 在普通模式下,使用数字加
dd来删除光标所在位置向下的多行。例如,5dd会删除光标所在行和接下来的四行。
- 在普通模式下,使用数字加
-
删除到行尾:
- 在普通模式下,使用
D命令删除从光标位置到行尾的所有内容。
- 在普通模式下,使用
-
删除到文件末尾:
- 在普通模式下,使用
:%d命令删除整个文件的内容。
- 在普通模式下,使用
-
撤销删除:
- 如果你不小心删除了内容,可以使用
u命令来撤销删除操作。
- 如果你不小心删除了内容,可以使用
-
退出 Vim:
- 如果你想要退出 Vim 而不保存任何更改,可以在普通模式下使用
:q!命令。
- 如果你想要退出 Vim 而不保存任何更改,可以在普通模式下使用
请注意,Vim 的模式非常重要。确保你在执行删除操作之前处于普通模式。如果你不确定自己处于哪个模式,可以按下 Esc 键返回普通模式。
如果你刚刚在 Vim 中写好了代码并想要全部删除,可以使用以下命令:
:%d这将在普通模式下删除整个文件的内容。如果你只想删除文件的一部分,确保使用正确的命令和范围。如果你只是想退出而不保存更改,可以使用:
:q!这将放弃所有更改并退出 Vim。
创建.txt文件并在里面写入内容
import java.io.FileWriter
// 指定文件名
val filename = "filename.txt"
// 使用try-with-resources语句确保文件最终被关闭
val file = new FileWriter(filename)
try {
// 写入内容到文件
file.write("学号 性别 数学 英语 物理\n")
file.write("301610 男 80 64 78\n")
file.write("301611 女 65 87 58\n")
} catch {
case e: Exception => e.printStackTrace() // 处理可能的异常
} finally {
// 关闭文件
file.close()
}实验成功代码
计算级数
object Exercise2_1 {
def main(args: Array[String]): Unit = {
// 读取用户输入的q值
val q = scala.io.StdIn.readDouble() // 读取输入的q值
// 初始化级数和n
var Sn = 0.0
var n = 1.0
// 循环计算级数的和,直到Sn大于或等于q
while (Sn < q) {
Sn += 1.0 / n
n += 1.0
}
// 输出Sn的值
println(s"Sn=${Sn}")
}
}分别取出下面三个班级Top3的分数 ruc01
object ClassScores {
def main(args: Array[String]): Unit = {
// 初始化Map来存储每个班级的分数列表,明确指定列表类型为Int
var scores = Map(
"class1" -> List[Int](),
"class2" -> List[Int](),
"class3" -> List[Int]()
)
// 读取数据并填充分数列表
val data = List(
("class1", 90), ("class2", 91), ("class1", 88),
("class2", 99), ("class1", 100), ("class2", 77),
("class1", 77), ("class2", 57), ("class3", 77),
("class3", 88), ("class3", 99), ("class3", 100),
("class3", 22), ("class3", 77)
)
// 将分数添加到对应的班级列表中
data.foreach {
case (className, score) =>
scores = scores.updated(className, scores(className) :+ score)
}
// 导入隐式转换,以便能够对Int进行排序
import scala.math.Ordered
// 打印每个班级的Top 3分数
scores.foreach { case (className, scoreList) =>
// 显式指定排序顺序
val topScores = scoreList.sorted(Ordering[Int].reverse).take(3)
println(s"Top 3 scores for $className: ${topScores.mkString(", ")}")
}
}
}统计学生成绩一 ruc02 仅成功编译,无法运行
import scala.io.Source
import scala.collection.mutable.ListBuffer
object ruc02 {
def main(args: Array[String]): Unit = {
// 读取文件内容
val lines = Source.fromFile("filename.txt").getLines().toList
// 跳过表头
val headers = lines.head.split("\\s+").tail
val students = lines.tail.map(_.split("\\s+").map(_.toInt))
// 定义统计函数
def statistics(scores: List[Int]): (Double, Int, Int) = {
val total = scores.sum
val average = total.toDouble / scores.length
val min = scores.min
val max = scores.max
(average, min, max)
}
// 计算总体统计数据
val overallStats = headers.zipWithIndex.map { case (header, index) =>
val scores = students.map(_(index))
val (average, min, max) = statistics(scores)
(header, (average, min, max))
}.toMap
// 计算男女分别的统计数据
val genderStats = Map(
"male" -> headers.tail.map(_ => ListBuffer[Int]()),
"female" -> headers.tail.map(_ => ListBuffer[Int]())
)
students.foreach { student =>
val gender = student(1) // 性别字段的索引是1
headers.tail.indices.foreach { index =>
val headerIndex = index + 1 // 跳过性别字段
val score = student(headerIndex)
genderStats(gender.toString)(headerIndex - 1) += score
}
}
val statsForGender = (gender: String) => {
headers.tail.map { header =>
val scores = genderStats(gender)(headers.indexOf(header) - 1).toList
val (average, min, max) = statistics(scores)
((gender, header), (average, min, max))
}.toMap
}
val maleStats = statsForGender("male")
val femaleStats = statsForGender("female")
// 打印统计结果
println("Overall statistics:")
overallStats.foreach { case (course, stats) =>
println(s"$course: avg=${stats._1}, min=${stats._2}, max=${stats._3}")
}
println("\nMale statistics:")
maleStats.foreach { case ((gender, course), stats) =>
println(s"$course: avg=${stats._1}, min=${stats._2}, max=${stats._3}")
}
println("\nFemale statistics:")
femaleStats.foreach { case ((gender, course), stats) =>
println(s"$course: avg=${stats._1}, min=${stats._2}, max=${stats._3}")
}
}
}统计学生成绩二 仅成功编译,无法运行
import scala.collection.mutable.ArrayBuffer
import scala.io.Source
object ruc02 {
def get_alldata(allStudents: List[Array[String]], courseNames: Array[String], array1: ArrayBuffer[Int], array2: ArrayBuffer[Int], array3: ArrayBuffer[Int]): Unit = {
for (i <- 2 until courseNames.length + 2) {
for (j <- allStudents.indices) {
val score = allStudents(j)(i).toInt
array1.append(score)
if (allStudents(j)(1) == "male") {
array2.append(score)
} else if (allStudents(j)(1) == "female") {
array3.append(score)
}
}
}
}
def get_data(array: ArrayBuffer[Int], data2: ArrayBuffer[Double], Nn: Int): Unit = {
var index = 0
while (index < array.length) {
val scores = array.slice(index, index + Nn)
val average = scores.sum.toDouble / scores.length
val min = scores.min
val max = scores.max
data2.append(average)
data2.append(min)
data2.append(max)
index += Nn
}
}
def print_data(data2: ArrayBuffer[Double], courseNames: Array[String]): Unit = {
for (i <- courseNames.indices) {
println(s"${courseNames(i)}: average=${data2(i * 3).formatted("%.2f")}, min=${data2(i * 3 + 1)}, max=${data2(i * 3 + 2)}")
}
}
def main(args: Array[String]): Unit = {
val File = Source.fromFile("d:/2.txt")
val all_Data = File.getLines().map {_.split(" ")}.toList
val courseNames = all_Data.head.drop(1).toArray // Convert to Array for mutability
val allStudents = all_Data.tail.map(_.map(_.trim)) // Remove leading and trailing spaces
val array1 = ArrayBuffer[Int]()
val array2 = ArrayBuffer[Int]()
val array3 = ArrayBuffer[Int]()
get_alldata(allStudents, courseNames, array1, array2, array3)
val data2 = ArrayBuffer[Double]()
val Nn = courseNames.length
get_data(array1, data2, Nn)
get_data(array2, data2, Nn)
get_data(array3, data2, Nn)
println("course average min max")
print_data(data2.take(Nn * 3), courseNames)
println("course average min max(male)")
print_data(data2.slice(Nn * 3, Nn * 6), courseNames)
println("course average min max(female)")
print_data(data2.slice(Nn * 6, Nn * 9), courseNames)
}
}实验截图