-
强大的自愈能力是Kubernetes这类容器编排引擎的一个重要特性,自愈的默认实现方式是自动重启发生故障的容器,除此之外,用户还可以利用Liveness和Readiness探测机制设置更精细的健康检查,进而实现如下需求:
- 零停机部署
- 避免部署无效的镜像
- 更加安全的滚动升级
-
默认的健康检查
-
kubernetes默认的健康检查机制:每个容器启动时都会执行一个进程,此进程由Dockerfile的CMD或者entrypoint指定,如果进程退出时返回码非零,则认为容器发生故障,kubernetes就会根据restartPolicy重启容器
-
模拟一个容器发生故障的场景

-
Pod的restartPolicy设置为OnFailure,默认是Always,sleep 10: exit 1,模拟容器启动10s后发生故障,执行kubectl apply创建pod,命名为healthcheck

-
过几分钟查看pod的状态

-
可以看到容器当前已经重启3次了,容器进程返回值非零,kubernetes则认为容器发生故障,需要重启
-
-
-
Liveness探测
-
Liveness探测让用户可以自定义判断容器是否健康的条件,如果探测失败,Kubernetes就会重启容器

-
启动进程首先创建文件/tmp/healthy,30s后删除,在此设定中,如果tmp/healthy文件存在,则认为容器处于正常状态,反之则发生故障
-
livenessProbe部分定义如何执行Liveness探测
-
探测的方法是:通过cat命令检查/tmp/healthy文件是否存在,如果命令执行成功,返回值为零,kubernetes则认为本次Liveness探测成功,如果命令返回值非零,本次Liveness探测失败
-
initialDelaySeconds:10指定容器启动10s之后开始执行Liveness探测,我们一般会根据应用启动的准备时间来设置,比如某个应用正常启动要花30s,那么initialDelaySeconds的值就应该大于30
-
periodSeconds:5指定每5s执行一次Liveness探测,Kubernetes如果连续执行3次Liveness探测均失败,则会杀掉并重启容器
-
创建Pod liveness

-
从配置文件可知,最开始的30s,/tmp/healthy存在,cat命令返回0,Liveness探测成功,这段时间kubectl describe pod liveness的Events部分会显示正常的日志,

-
35秒之后,日志会显示/tmp/healthy已经不存在,Liveness探测失败,再过几十秒,几次探测都失败之后,容器会被重启


-
-
-
Readiness探测
-
除了Liveness探测,Kubernetes Health Check机制还包括Readiness探测,用户通过Liveness探测可以告诉Kubernetes什么时候通过重启容器实现自愈,Readiness探测则是告诉Kubernetes什么时候可以将容器加入到Service负载均衡池中,对外提供服务
-
Readiness探测的配置语法与Liveness探测完全一样

-
创建Pod,查看pod状态

-
Pod readiness的ready状态经历了如下变化:
- 刚被创建时,ready状态为不可用
- 15s后(initialDelaySeconds+periodSeconds),第一次进行Readiness探测并成功返回,设置ready为可用
- 30s秒,/tmp/healthy被删除,连续3次Readiness探测均失败后,ready被设置为不可用
- 通过kubectl describe pod readiness也可以看到Readiness探测失败的日志

-
-
Liveness探测和Readiness探测比较:
- Liveness探测和Readiness探测是两种Health Check机制,如果不特意配置,Kubernetes将对两种探测采取相同的默认行为,即通过判断容器启动进程的返回值是否为零来判断探测是否成功
- 两种探测的配置方法完全一样,支持的配置参数也一样,不同之处在于探测失败后的行为:Liveness探测是重启容器,Readiness探测则是将容器设置为不可用,不接收Service转发的请求
- Liveness探测和Readiness探测是独立执行的,二者之间没有依赖,所以可以单独使用,也可以同时使用,用Liveness探测判断容器是否需要重启以实现自愈,用Readiness探测判断容器是否已经准备好对外提供服务
-
Health Check 在 Scale up中的应用
-
对于多副本应用,当执行Scale Up操作时,新副本会作为backend被添加到Service的负载均衡中,与已有副本一起处理客户的请求,考虑到应用启动通常都需要一个准备阶段,比如加载缓存数据,连接数据库等,从容器启动到真正能够提供服务是需要一段时间的,我们可以通过Readiness探测判断容器是否准备就绪,避免将请求发送到还没有准备好的backend
-

-
这次使用了不同于exec的另一种探测方法httpGet,kubernetes对于该方法探测成功的判断条件是http请求的返回代码在200-400之间
- schema指定协议,支持HTTP(默认)和HTTPS
- path指定访问路径
- port指定端口
-
配置解析:
- 容器启动10s之后开始探测
- 如果http://[container_ip]:8080/healthy返回代码不是200-400,表示容器没有就绪,不接收Service web-svc的请求
- 每隔5秒探测一次
- 直到返回代码为200-400,表明容器已经就绪,然后将其加入到web-svc的负载均衡中,开始处理客户请求
- 探测会继续以5秒的间隔执行,如果连续发生3次失败,容器又会从负载均衡中移除,直到下次探测成功重新加入
-
对于http://[container_ip]:8080/healthy,应用则可以实现自己的判断逻辑,比如检查所依赖的数据库是否就绪

- 定义/healthy的处理函数
- 连接数据库并执行测试SQL
- 测试成功,正常返回,代码200
- 测试失败,返回错误代码503
- 在8080端口监听
-
对于生产环境中重要的应用,都建议配置Health Check,保证处理客户请求的容器都是准备就绪的Service backend
-
-
Health Check在滚动更新中的应用
-
Health Check另一个重要作用的应用场景是Rolling Update,如果有一个正常运行的多副本应用,接下来对应用进行更新(比如使用更高版本的image),Kubernetes会启动新副本,会发生如下事件:
- 正常情况下新副本需要10秒钟完成准备工作,在此之前无法响应业务请求
- 由于人为配置错误,副本始终无法完成准备工作(比如无法连接后端数据库)
-
如果没有配置Health Check会出现怎么样的情况?
- 因为新副本本身没有异常退出,默认的Health Check机制会认为容器已经就绪,进而会逐步用新副本替换现有的副本,其结果就是:当所有旧副本都被替换后,整个应用将无法处理请求,无法对外提供服务,如果这是发生在重要的生产西永,后果会非常严重
- 如果正确配置了Health Check,新副本只有通过了Readiness探测才会被添加到Service,如果没有通过探测,现有副本不会被全部替换,业务仍然正常运行
-
使用如下配置文件app.v1.yml模拟一个10副本的应用

-
创建Pod,并且10秒后副本能够通过Readiness探测

-
然后滚动更新应用,配置文件app.v2.yml

-
由于新副本中不存在/tmp/healthy,因此无法通过Readiness探测

-
详细解析
- 从kubectl get pod输出看:
- 从Pod的AGE栏可判断,最后5个Pod是新的副本,目前正处于Not ready状态
- 旧副本从最初的10个副本减少到8个
- 从kubectl get deployment app的输出看:
- desired 10表明期望的状态是10个ready的副本
- current 13表示当前副本的总数,即8个旧副本+5个新副本
- up-to-date 5表示当前已经完成更新的副本数,即5个新副本
- available 8 表示当前处于ready状态的副本数,即8个旧副本
- 从kubectl get pod输出看:
-
在设定中,新副本始终无法通过Readiness探测,所以这个状态会一直保持下去,Health Check帮我们屏蔽了有缺陷的副本,同时保留了大部分旧副本,业务没有因为更新失败受到影响
-
为什么新创建的副本数是5个,同时只销毁了2个旧副本?
-
原因是滚动更新通过参数maxSurge和maxUnavailable来控制副本替换的数量
-
maxSurge:
- 此参数控制滚动更新过程中副本总数超过desired的上限,maxSurge可以是具体的整数,比如3,也可以是百分比,向上取整,maxSurge默认值为25%
- 在上面的例子中,desired为10,那么副本总数的最大值为rpundUp(10 + 10 * 25%) = 13,所以我们看到current就是13
-
maxUnavailable:
- 此参数控制滚动更新过程中,不可用的副本数占desired的最大比例,maxUnavailable可以是具体的整数,比如3,也可以是百分比,向下取整,maxUnavailable默认值为25%
- 上面的例子中,desired为10,那么可用的副本数至少为10 - roundDown(10*25%) = 8,所以我们看到的available是8
-
maxSurge值越大,初始创建的新副本数量就越多,maxUnavailable值越大,初始销毁的旧副本数量就越多
-
理想情况下,该案例是这样的:
- 创建3个新副本使副本总数达到13个,
- 销毁2个旧副本可用的副本数降到8个,
- 当2个旧副本成功销毁后,在创建2个新副本,使副本总数保持为13个
- 当新副本通过Readiness探测后,会使可用副本数增加,超过8个
- 进而可以继续销毁更多的旧副本,使可用副本数回到8个
- 旧副本的销毁使副本总数低于13,这样就允许创建更多的新副本
- 这个过程会持续进行,最终所有的旧副本都会被新副本替换,滚动更新完成
- 而我们的实际情况是在第4步卡住,新副本无法通过Readiness探测,这个过程在kubectl describe deployment app的日志部分查看

-
如果滚动更新失败,可以通过kubectl rollout undo回滚到上一个版本

-
如果要定制maxSurge和maxUnavailable,可以进行配置

-
-
Health Check
news2026/2/14 13:01:49
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.coloradmin.cn/o/2161723.html
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈,一经查实,立即删除!相关文章

c++优先队列priority_queue(自定义比较函数)
c优先队列priority_queue(自定义比较函数)_c优先队列自定义比较-CSDN博客
373. 查找和最小的 K 对数字 - 力扣(LeetCode) 官方题解:
class Solution {
public:vector<vector<int>> kSmallestPairs(vecto…

开源UNI-SOP云统一认证平台
今天给大家分享一款开源的商用级别认证平台UNI-SOP,这块软件分为开源版本和专业版本,由于专业版涉及到一些代码授权问题,暂时未开源,不过,一般应用开源版本足够了。 先来看看系统管理平台界面,然后我们再来…
![[OPEN SQL] SELECT语句](https://i-blog.csdnimg.cn/direct/65634126c0b14030934dfc72c4721dd1.png)
[OPEN SQL] SELECT语句
本次操作使用的数据库表为SCUSTOM,其字段内容如下所示 航班用户(SCUSTOM) 1.SELECT语句
SELECT语句从数据库表中读取必要的数据
1.1 读取一行数据
语法格式
SELECT SINGLE <cols>... WHERE cols:数据库表的字段 从数据库表中读取一条数据可使…
![[数据结构]动态顺序表的实现与应用](https://i-blog.csdnimg.cn/direct/f5c016efacaa400b8762ad82e844ebfc.png)
[数据结构]动态顺序表的实现与应用
文章目录 一、引言二、动态顺序表的基本概念三、动态顺序表的实现1、结构体定义2、初始化3、销毁4、扩容5、缩容5、打印6、增删查改 四、分析动态顺序表1、存储方式2、优点3、缺点 五、总结1、练习题2、源代码 一、引言
想象一下,你有一个箱子(静态顺序…

武汉大学首个人形机器人来了!
B站:啥都会一点的研究生公众号:啥都会一点的研究生
AI圈又发生了哪些新鲜事?
武汉大学展示首个人形机器人“天问”:1.7米高,65公斤重,36个自由度
武汉大学近日展示了其首个人形机器人“天问”࿰…
屏幕演示工具 | 水豚鼠标助手 v1.0.7
水豚鼠标助手是一款功能强大的屏幕演示工具,专为Windows 10及以上系统设计。这款软件提供了多种实用功能,旨在增强用户的屏幕演示体验,特别适合教师、讲师和需要进行屏幕演示的用户。鼠标换肤:软件提供多种鼠标光标样式࿰…

国庆出行新宠:南卡Pro5骨传导耳机,让旅途不再孤单
国庆长假即将来临,对于热爱旅行和户外运动的朋友们来说,一款适合旅行使用的耳机无疑是提升旅途体验的神器。今天,我要向大家推荐一款特别适合国庆出行的耳机——南卡Runner Pro5骨传导耳机。作为一名热爱旅游的体验者,我强烈推荐南…

2024年主流前端框架的比较和选择指南
在选择前端框架时,开发者通常会考虑多个因素,包括框架的功能、性能、易用性、社区支持和学习曲线等。以下是一些主流前端框架的比较和选择指南。
1. 主流前端框架简介
React 优点: 组件化开发,易于复用和维护。虚拟DOM提高了性能。强大的生…

Java 中创建线程几种方式
目录
概述
一. 继承Thread类
1. 特点
2. 注意事项
3. 代码示例
二. 实现Runnable接口
1. 特点
2. 注意事项
3. 代码示例
三. 实现Callable接口
1. 特点
2. 注意事项
3. 代码示例 概述
在Java中,线程(Thread)是程序执行的最小单…

Java面试篇基础部分-Synchronized关键字详解
Synchronized关键字用于对Java对象、方法、代码块等提供线程安全操作。Synchronized属于独占式的悲观锁机制,同时也是可重入锁。我们在使用Synchronized关键字的时候,可以保证同一时刻只有一个线程对该对象进行访问;也就是说它在同一个JVM中是线程安全的。 Java中的每个…
mask controlnet
diffusers/examples/controlnet/README.md at main huggingface/diffusers GitHub🤗 Diffusers: State-of-the-art diffusion models for image and audio generation in PyTorch and FLAX. - diffusers/examples/controlnet/README.md at main huggingface/diffusershttp…

怎么在Proteus中找到排阻
1、打开安装好的Proteus,点击上方菜单栏中的“库”,再选择“从库选取零件”,或者在左侧元件列表中单击鼠标右键,再点击右键菜单中的“从库中挑选”选项。 2、之后会打开元器件库,我们打开类别中的“Resistors”&#x…

《深度学习》CNN 数据增强、保存最优模型 实例详解
目录
一、数据增强
1、什么是数据增强
2、目的
3、常用的数据增强方法
4、数据预处理
用法:
5、使用数据增强增加训练数据
二、保存最优模型
1、什么是保存最优模型
2、定义CNN模型
运行结果:
3、设置训练模式
4、设置测试模式、保存最优模…

RHCS认证-Linux(RHel9)-Ansible
文章目录 一、ansible 简介二 、ansible部署三、ansible服务端测试四 、ansible 清单inventory五、Ad-hot 点对点模式六、YAML语言模式七、RHCS-Ansible附:安装CentOS-Stream 9系统7.1 ansible 执行过程7.2 安装ansible,ansible-navigator7.2 部署ansibl…

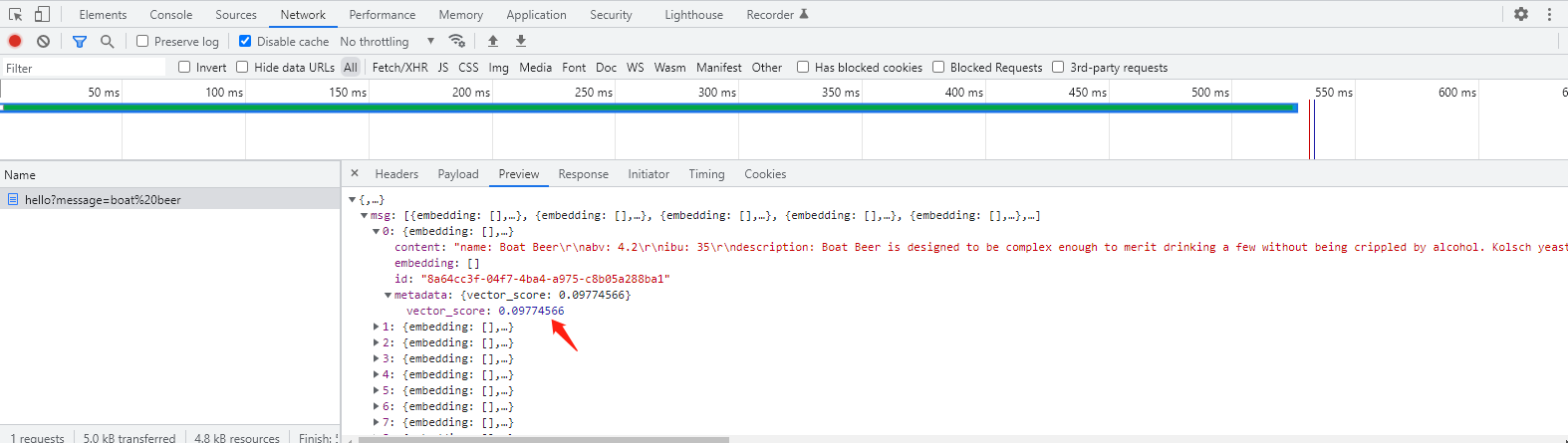
Spring Boot集成Redis向量数据库实现相似性搜索
1.什么是Redis向量数据库?
Redis 是一个开源(BSD 许可)的内存数据结构存储,用作数据库、缓存、消息代理和流式处理引擎。Redis 提供数据结构,例如字符串、哈希、列表、集合、带范围查询的有序集合、位图、超对数日志、…

Qt开发-comboBox 所有槽函数介绍(2024.09)
activated(int): 触发于ComboBox中某一项被激活时,参数为该项的索引。 currentIndexChanged(QString)/currentIndexChanged(int): 当前选中项变化时触发,前者传递文本,后者传递索引。 currentTextChanged(QString): 当前选中项的文字变更时触…

Ubuntu 与Uboot网络共享资源
1、NFS
1.1 Ubuntu 下 NFS 服务开启
sudo apt-get install nfs-kernel-server rpcbind
等待安装完成,安装完成以后在用户根目录下创建一个名为“Linux”的文件夹,以后所有 的东西都放到这个“Linux”文件夹里面,在“Linux”文件夹里面新建…

Qt获取本机Mac地址、Ip地址
一、简述
今天给大家分享一个获取本机IP地址和Mac地址的方法,经过多次测试,台式机、笔记本等多个设备,暂时没有发现问题。
由于很多时候本地安装了虚拟机、蓝牙、无线网卡或者其他设备等,会有多个Mac地址,所以需要进…

【828华为云征文|如何轻松部署“未知表白墙”项目:华为云Flexus X实例指南】
文章目录 华为云 Flexus X 实例:开启高效云服务的新纪元部署【未知表白墙】项目准备工作具体操作指南服务器环境确认宝塔软件商店操作域名解析未知表白墙登录页修改管理员账号和密码未知表白墙管理页面基础设置表白管理 未知表白墙效果查看 总结 华为云 Flexus X 实…