0 来自GPU的hello world
在visua studio 中新建一个CUDA runtime项目,然后把kernel.cu中的代码删掉,输入以下代码
#include"cuda_runtime.h"
#include"device_launch_parameters.h"
#include<stdio.h>
__global__ void hello_from_gpu(void) {
printf("Hello from GPU!\n");
}
int main(void) {
hello_from_gpu<<<1, 1>>>();
cudaDeviceSynchronize();
return 0;
}
hello_from_gpu<<<1, 1>>>();该条代码可能会飘红标错,可以不用管
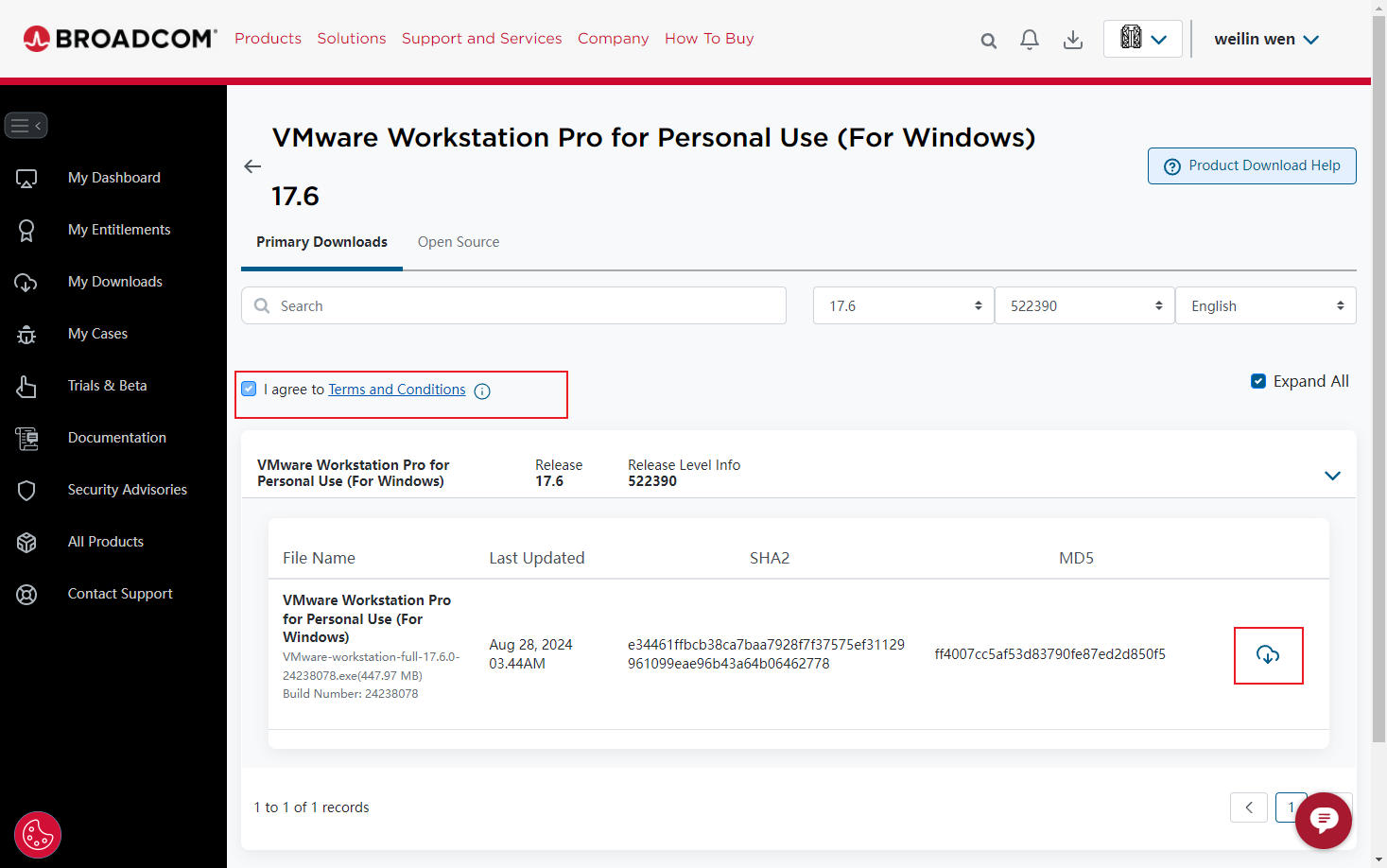
输出结果如下

如果创建了CUDA runtime项目依旧无法直接运行,请确保是否正确安装了CUDA,或者在项目设置中添加以下三个cuda文件路径


1 只有主机函数的CUDA程序
CUDA程序的编译器驱动(compilerdriver)nvcc支持编译纯粹的C++代码,所以可以写一个C++代码,然后修改后缀为.cu,然后使用nvcc去编译(nvcc会把C++的部分交给C++编译器去编译,然后其余部分则自己编译)
请打开一个记事本,输入以下代码,然后保存为后缀为.cu的文件

#include<stdio.h>
int main(void)
{
printf("Hello world!");
return 0;
}
在该文件目录下打开终端,输入nvcc hello.cu -o hello,会把hello.cu文件,使用nvcc将其编译为一个hello的.exe文件,输入.\hello,输出结果如下

2 使用核函数的CUDA程序
上一个例子只是使用nvcc编译器进行编译,但是并没有调用GPU,下面将介绍如何在GPU中的输出Hello world!,在《CUDA编程》1.GPU硬件与CUDA环境搭建中已经介绍了,GPU必须在CPU的控制之下,才能进行运算,所以一个典型的、简单的CUDA程序的结构具有下面的形式:

hsot对device的调用是通过核函数(kernel function)来实现的。
CUDA中的核函数与C++中的函数必须被限定词__global__ 修饰,前后是双下划线,核函数的返回类型必须是void,void和__global__次序随意,下面是一个核函数。
__global__ void hello_from_gpu(void) {
printf("Hello from GPU!\n");
}
2.1 分析hello world代码
请关注main()函数部分
#include"cuda_runtime.h"
#include"device_launch_parameters.h"
#include<stdio.h>
__global__ void hello_from_gpu(void) {
printf("Hello from GPU!\n");
}
int main(void) {
hello_from_gpu<<<1, 1>>>();
cudaDeviceSynchronize();
return 0;
}
2.1.1 核函数的调用格式
①hello_from_gpu<<<1, 1>>>();与C++格式函数hello_from_gpu();相比,多一个一对三尖括号,里面还有用逗号隔开的两个数字。因为一个GPU中有多个核心,即可以支持多线程(thread),所以host在调用一个核函数时,必须指明需要在设备中指派多少个线程
核函数中的线程常组织为若干线程块(thread_block):三括号中的第一个数字可以看作线程块的个数,第二个数字可以看作每个线程块中的线程数。
一个核函数的全部线程块构成一个网格(grid),而线程块的个数就记为网格大小(grid_size)。每个线程块中含有同样数目的线程,该数目称为线程块大小(block_size),则
核函数中总的线程数 = Grid_size x Block_size
所以三尖括号意义是<<<Grid_size , Block_size>>>,所以,在上述程序中,主机只指派了设备的一个线程,网格大小和线程块大小都是1,即1 x 1 = 1
② 核函数中也支持printf(),但只支持<stdio.h>,不支持C++的
③cudaDeviceSynchronize();是调用了一个CUDA的runtime的函数API,去掉这个函数就打印不出字符串,作用是同步主机与设备,所以能够促使缓冲区刷新,后面会详解该函数
3 CUDA中的线程组织
3.1 核函数中使用多个线程
一个GPU往往有几千个计算核心,而总的线程数必须至少等于计算核心数时才有可能充分利用GPU中的全部计算资源。
实际上,总的线程数大于计算核心数时才能更充分地利用GPU中的计算资源,因为这会让计算和内存访问之间及不同的计算之间合理地重叠,从而减小计算核心空闲的时间。
假设线程我们要使用8个线程进行运算,代码如下
#include"cuda_runtime.h"
#include"device_launch_parameters.h"
#include<stdio.h>
__global__ void hello_from_gpu(void) {
printf("Hello from GPU!\n");
}
int main(void) {
hello_from_gpu<<<2, 4>>>();
cudaDeviceSynchronize();
return 0;
}
输出结果如下,会输出8行 Hello from GPU!:

核函数中代码的执行方式是“单指令-多线程”,即每一个线程都执行同一串指令。
3.2 使用线程索引
每个线程在核函数中都有一个唯一的身份标识,代码中使用了grid_size 、block_size,所以可以使用这两个参数来表明每个线程。
#include"cuda_runtime.h"
#include"device_launch_parameters.h"
#include<stdio.h>
__global__ void hello_from_gpu(void) {
const int tid = threadIdx.x;//线程id
const int bid = blockIdx.x;//线程块id
printf("Hello from GPU! tid:%d bid:%d\n",tid,bid);
}
int main(void) {
hello_from_gpu<<<2, 4>>>();
cudaDeviceSynchronize();
return 0;
}
输出结果如下,便可以看出每一句输出来自于拿哪一个线程块的哪一个线程:

注意:每个线程块的计算是相互独立的,所以有时候会是bid:1先执行完,有时会是bid:0先执行完
3.3 推广至多维网络
blockIdx 和 threadIdx 是类型为 uint3 的变量,即结构如下:

即可以用结构体dim3定义“多维”的网格和线程块,例如我们要定义一个2 x 2 x 1的grid和2 x 3 x 1的block,结果如下:
而在核函数中的线程组织图如下所示:

grid的形状为2 x 2 x 1,所以有4个block;
block的形状是3 x 2 x 1,所以每个block中有6个线程
一个线程块中的线程还可以细分为不同的线程束(threadwarp),目前所有的GPU架构都是32,所以,一个线程束就是连续的32个线程。即一个线程块中第0到第31个线程属于第0个线程束,第32到第63个线程属于第1个线程束,依此类推。

修改代码如下:
#include"cuda_runtime.h"
#include"device_launch_parameters.h"
#include<stdio.h>
__global__ void hello_from_gpu(void) {
const int tidx = threadIdx.x;
const int tidy = threadIdx.y;
const int bid = blockIdx.x;
printf("Hello from tid:(%d,%d) bid:%d\n",tidx,tidy,bid);
}
int main(void) {
hello_from_gpu<<<2, 4>>>();
cudaDeviceSynchronize();
return 0;
}
输出结果是:

3.4 网格与线程块大小的限制
CUDA中对能够定义的网格大小和线程块大小做了限制。
- 网格大小在x、y和z这3个方向的最大允许值分别为2^31-1、65535和65535。
- 线程块大小在x、y和z这3个方向的最大允许值分别为1024、1024和64。
- 线程块总的大小,即blockDim.x、blockDim.y和blockDim.z的乘积不能大于1024,即不管如何定义,一个线程块最多只能有1024个线程。
4 CUDA中的头文件
在使用nvcc编译器驱动编译.cu文件时,将自动包含必要的CUDA头文件,如<cuda.h>和<cuda_runtime.h>,且为<cuda.h>包含了<stdlib.h>,但在visual studio里编写时,需要手动添加
5 用nvcc编译CUDA程序时,计算能力问题
CUDA的编译器驱动(compilerdriver)nvcc先将全部源代码分离为host代码和device代码。主机代码完整地支持C++语法,但设备代码只部分地支持C++。
nvcc先将设备代码编译为PTX伪汇编代码,再将PTX代码编译为二进制的cubin目标代码。
在将源代码编译为PTX代码时,需要用选项-arch=compute_XY指定一个虚拟架构的计算能力;在将PTX代码编译为cubin代码时,需要用选项-code=sm_ZW指定一个真实架构的计算能力
真实架构的计算能力必须等于或者大于虚拟架构的计算能力
所以

可以编译,但下面的设置则不能编译,因为虚拟架构计算能力小于真实架构

本文的程序在编译时并没有通过编译选项指定计算能力。这是因为编译器有一个默认的计算能力。

设置计算能力的必要性:
- 兼容性:不同的 GPU 架构有不同的指令集和硬件特性。通过设置计算能力,你可以确保生成的代码能够在特定的 GPU 上运行。如果不设置计算能力,nvcc 默认可能会生成针对最新架构的代码,这可能导致代码在旧的 GPU 上无法运行。
- 性能优化:不同的 GPU 架构有不同的优化策略。设置计算能力可以确保 nvcc 生成的代码针对特定的 GPU 进行优化,从而提高性能。
以下是一些常见的计算能力及其对应的 GPU 架构: