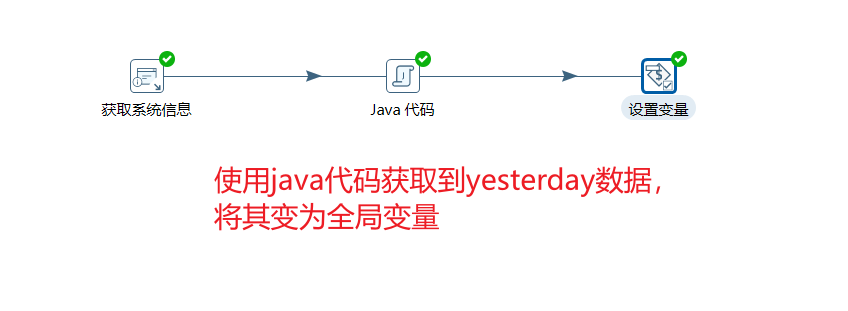
1. 环境
python版本:3.11.9
2.完整代码
import sqlite3
import time
from funasr import AutoModel
import sounddevice as sd
import numpy as np
from pypinyin import lazy_pinyin
# 模型参数设置
chunk_size = [0, 10, 5]
encoder_chunk_look_back = 7
decoder_chunk_look_back = 5
model = AutoModel(model="D:\SpeechRecognize\speech_paraformer-large-vad-punc_asr_nat-zh-cn-16k-common-vocab8404-pytorch")
# 假设模型要求的采样率为 16000
fs = 16000
duration = 3 #时间
chunk_stride = chunk_size[1] * 960
cache = {}
window_size = 3
# 连接到 SQLite 数据库,如果不存在则会创建新的数据库文件
conn = sqlite3.connect('speech_recognition.db')
cursor = conn.cursor()
# 创建表格
cursor.execute('''
CREATE TABLE IF NOT EXISTS speech_data
(text TEXT, time_stamp TEXT, batch TEXT)
''')
while True:
start_time = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())
myrecording = sd.rec(int(fs * duration), samplerate=fs, channels=1)
sd.wait()
speech_chunk = myrecording.flatten()
# 噪声处理
filtered_chunk = np.convolve(speech_chunk, np.ones(window_size) / window_size, mode='same')
speech_chunk = filtered_chunk
is_final = False
res = model.generate(input=speech_chunk, cache=cache, is_final=is_final, chunk_size=chunk_size,
encoder_chunk_look_back=encoder_chunk_look_back,
decoder_chunk_look_back=decoder_chunk_look_back)
text_result=''.join(lazy_pinyin(str(res[0]['text']))).replace(" ", "")
# 唤醒词
s1=''.join(lazy_pinyin(str("小爱")))
print(s1)
print(text_result)
if s1 in text_result:
print("我在,我要做什么")
cursor.execute("INSERT INTO speech_data (text, time_stamp, batch) VALUES (?,?,?)",
(text_result, start_time, 'eerr'))
conn.commit()
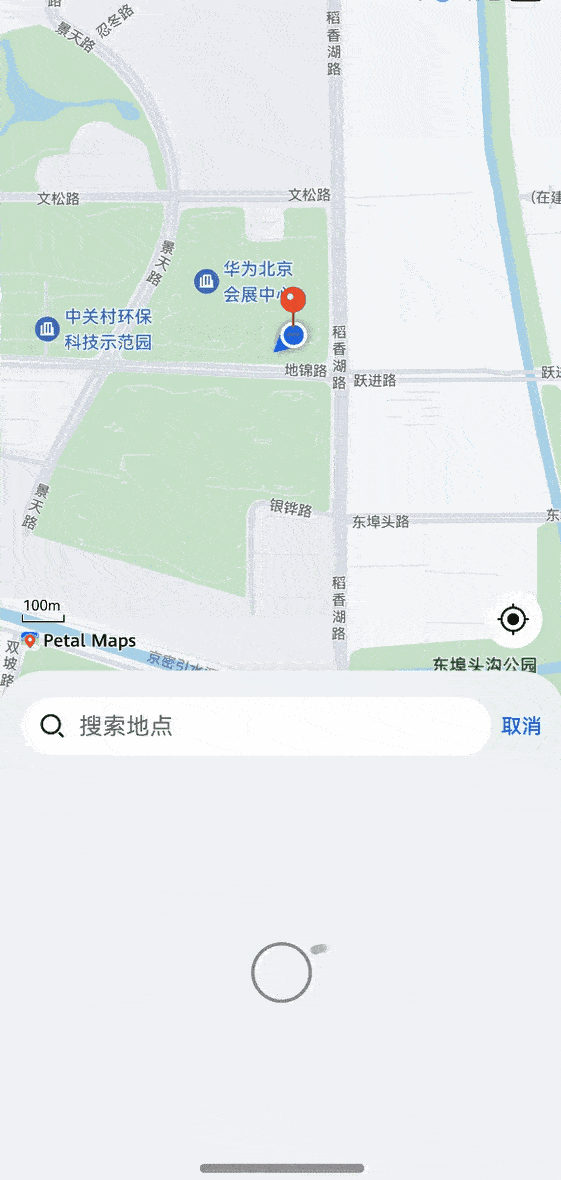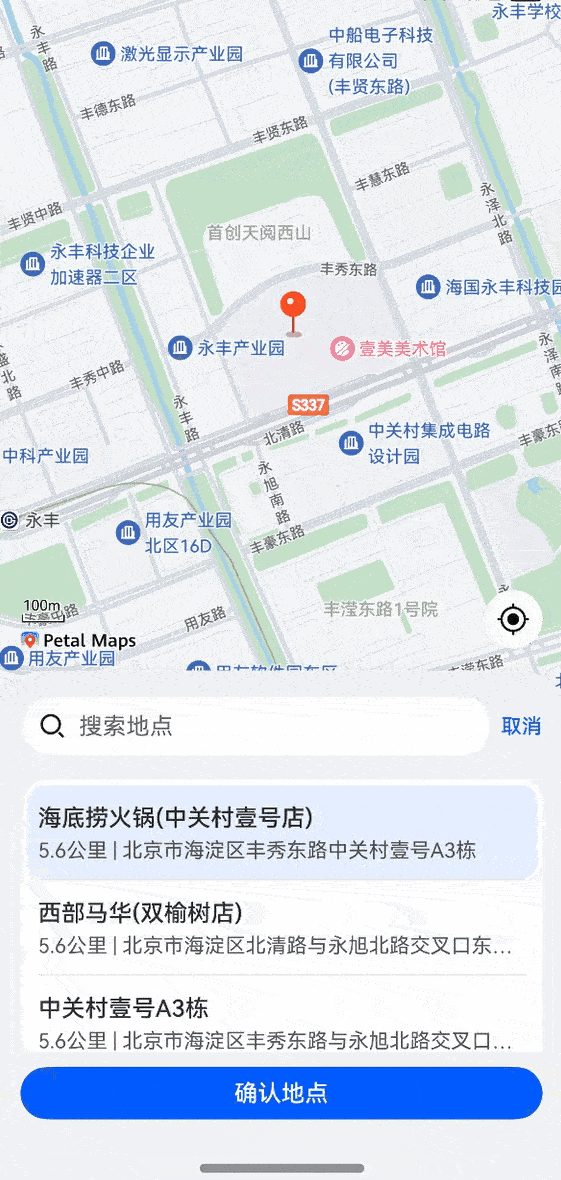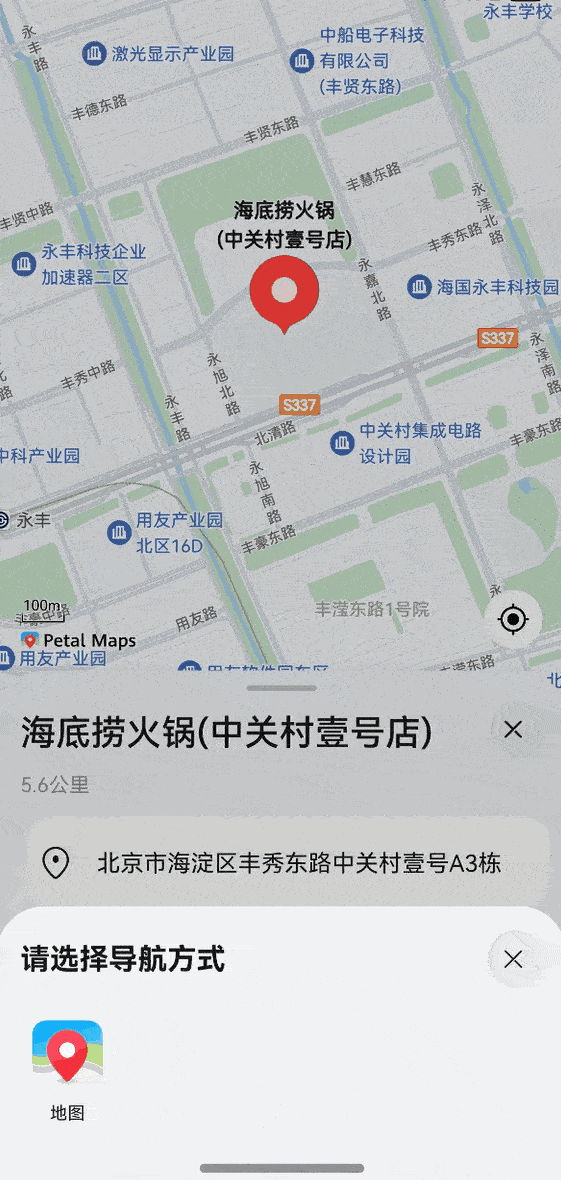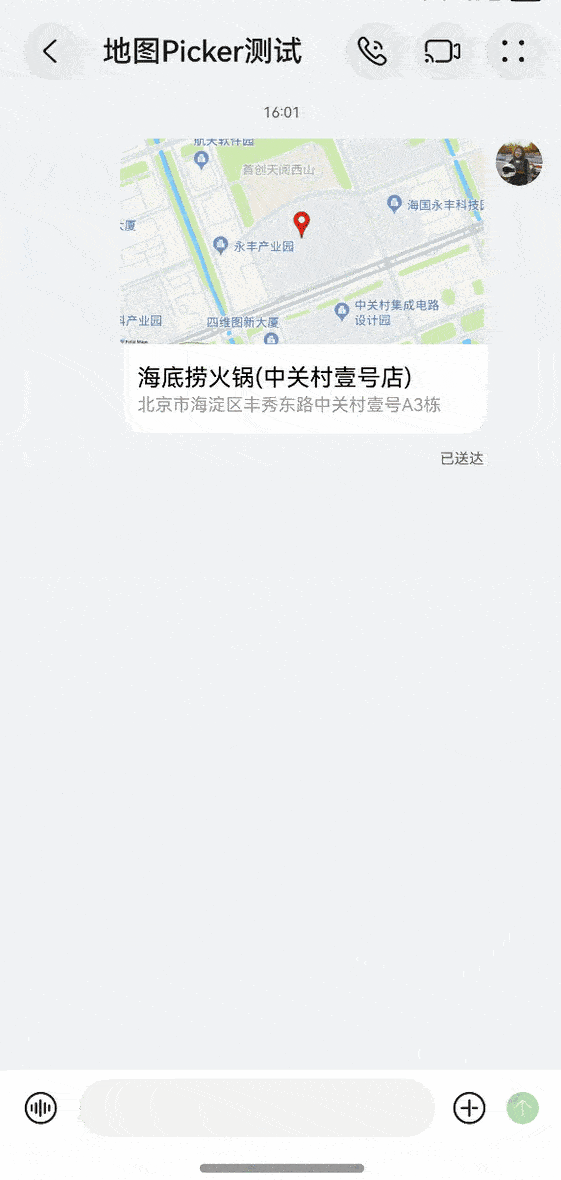
3.效果

4.问题
1.必须有麦克风才能跑起来
2.关于模型包,可以直接从模型社区下载(实在找不到可私信我)
3.最后的效果与你电脑的显卡有直接联系