单链表的定义(实现)
比较顺序表和单链表的物理存储结构就能够清楚地发现二者的区别

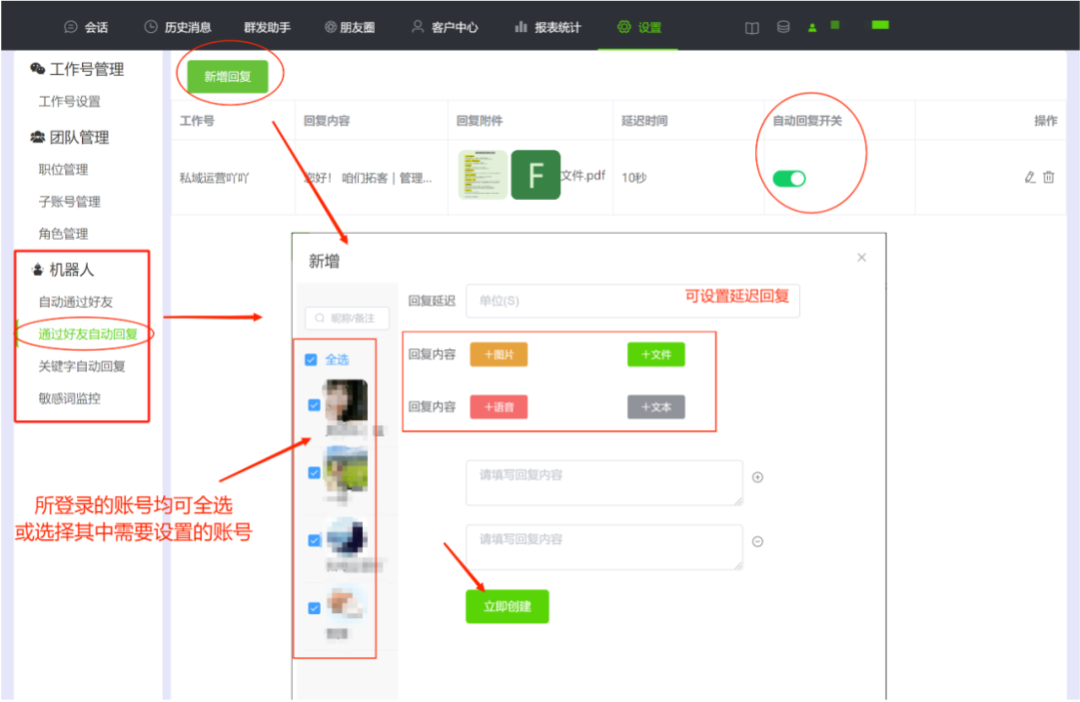
用代码定义一个单链表
typedef struct LNode{
ElemType data; //每个结点存放一个数据元素
struct LNode* next; //指针指向下一个结点
}LNode, *LinkList;
//要表示一个单链表时,只需声明一个头指针L,指向单链表的第一个结点
LNode* L; //➡️ 强调这是一个结点
LinkList L; //➡️ 强调这是一个单链表
//以上两种声明方式都可以,建议使用第二种,代码可读性更强
单链表的初始化
不带头节点的单链表
typedef struct LNode{
ElemType data;
struct LNode* next;
}LNode, *LinkList;
bool InitList(LinkList* L){ //初始化一个空的单链表
*L = NULL; //空表,暂时没有任何结点,防止脏数据
return true;
}
int main(){
LinkList L; //声明一个指向单链表的指针
InitList(&L); //初始化一个空表
//...
return 0;
}
带头节点的单链表
typedef struct LNode{
ElemType data;
struct LNode* next;
}LNode, *LinkList;
//初始化一个单链表(带头节点)
bool InitList(LinkList* L){
*L = (LNode*)malloc(sizeof(LNode));
if(*L == NULL)
return false;
(*L)->next = NULL;
return true;
}
int main(){
LinkList L; //声明一个指向单链表的指针
if (InitList(&L)) { // 初始化一个空表,传递指针的地址
printf("单链表初始化成功\n");
} else {
printf("单链表初始化失败\n");
}
//...
return 0;
}
总结
不带头结点,写代码更麻烦
对第一个数据结点和后续数据结点的处理需要用不同的代码逻辑
对空表和非空表的处理需要用不同的代码逻辑
带头结点,写代码更方便
本文主要参考《王道计算机考研 数据结构》课程视频