Apache Doris 实践
官方使用指南:https://doris.incubator.apache.org/zh-CN/docs/install/source-install/compilation-with-docker/
手动安装
-
下载二进制安装包https://apache-doris-releases.oss-accelerate.aliyuncs.com/apache-doris-2.1.5-bin-x64.tar.gz
-
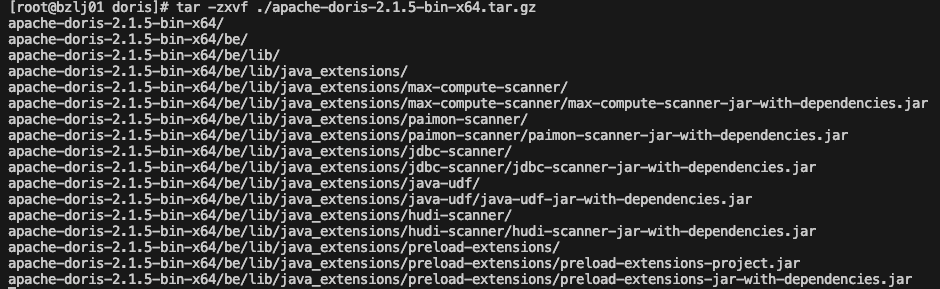
解压安装包
-
配置fe
-
修改fe/conf/fe.conf, 此处配置priority_networks网段地址
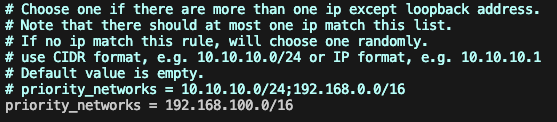
-
启动fe,直接执行/bin/start_fe.sh --daemon命令

-
验证fe启动状态。
-
使用mysql客户端连接fe,执行`mysql -uroot -P9030 -h192.168.100.199`, 如果正常会显示
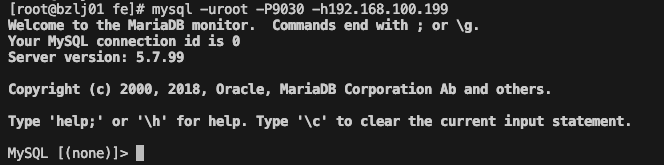
-
执行`show frontends`可以查看状态

-
-
-
配置be
-
修改/be/conf/be.conf,配置JAVA_HOME路径和priority_networks
-
注册be到fe中,执行alter system add backend “192.168.100.199:9050”
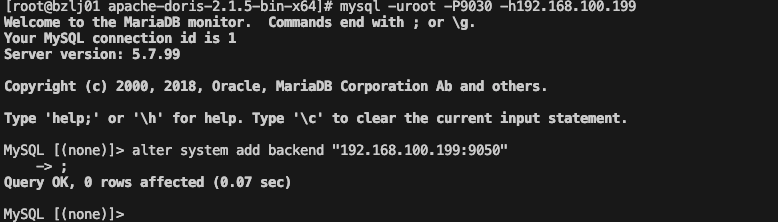
-
启动be。执行/be/start_be.sh --daemon
-
验证be节点。

-
-
通过mysql client登录Doris数据库
-
通过 MySQL Client 登录 Doris 集群。mysql -uroot -P<fe_query_port> -h<fe_ip_address>
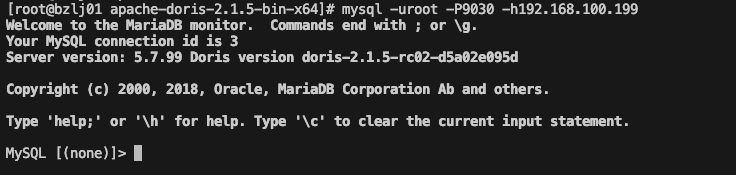
-
修改默认密码。

-
创建测试数据库及表。注意由于只有一个be,因此需要手动配置replication_num为1

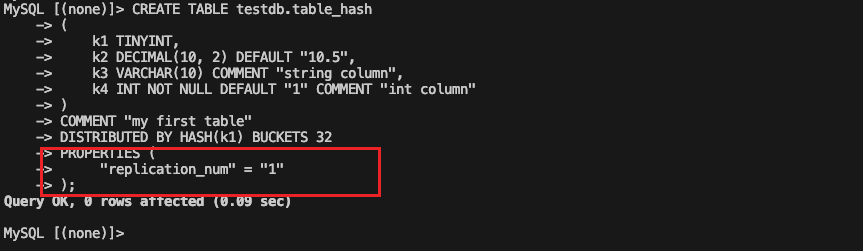
-
插入数据,并验证查询。
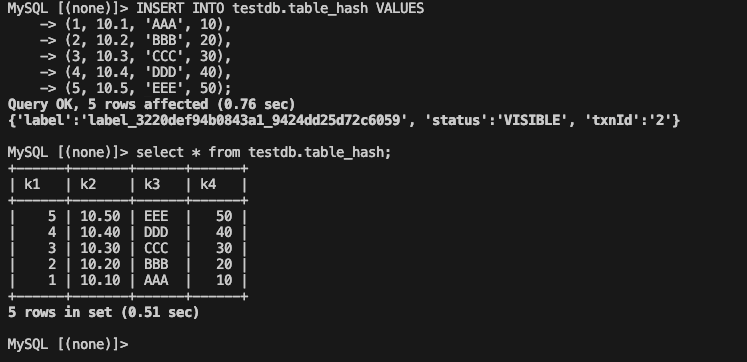
-
-
通过Web登录。在浏览器中输入 http://fe_ip:fe_port, 比如http://192.168.100.199:8030登录Doris控制台
数据表设计
数据模型
在 Doris 中,数据以表(Table)的形式进行逻辑上的描述。一张表包括行(Row)和列(Column)。Row 即用户的一行数据,Column 用于描述一行数据中不同的字段。
Column 可以分为两大类:Key 和 Value。从业务角度看,Key 和 Value 可以分别对应维度列和指标列。Doris 的 Key 列是建表语句中指定的列,建表语句中的关键字 unique key 或 aggregate key 或 duplicate key 后面的列就是 Key 列,除了 Key 列剩下的就是 Value 列。
Doris 的数据模型主要分为 3 类:
-
明细模型(Duplicate Key Model):允许指定的 Key 列重复;适用于必须保留所有原始数据记录的情况。在某些多维分析场景下,数据既没有主键,也没有聚合需求。
-
主键模型(Unique Key Model):每一行的 Key 值唯一;可确保给定的 Key 列不会存在重复行。
-
聚合模型(Aggregate Key Model):可根据 Key 列聚合数据;通常用于需要汇总或聚合信息(如总数或平均值)的情况。
明细模型(Duplicate Key Model)
在建表语句中指定 Duplicate Key,用来指明数据存储按照这些 Key 列进行排序。
比如:建表语句举例如下,指定了按照 timestamp、type 和 error_code 三列进行排序。
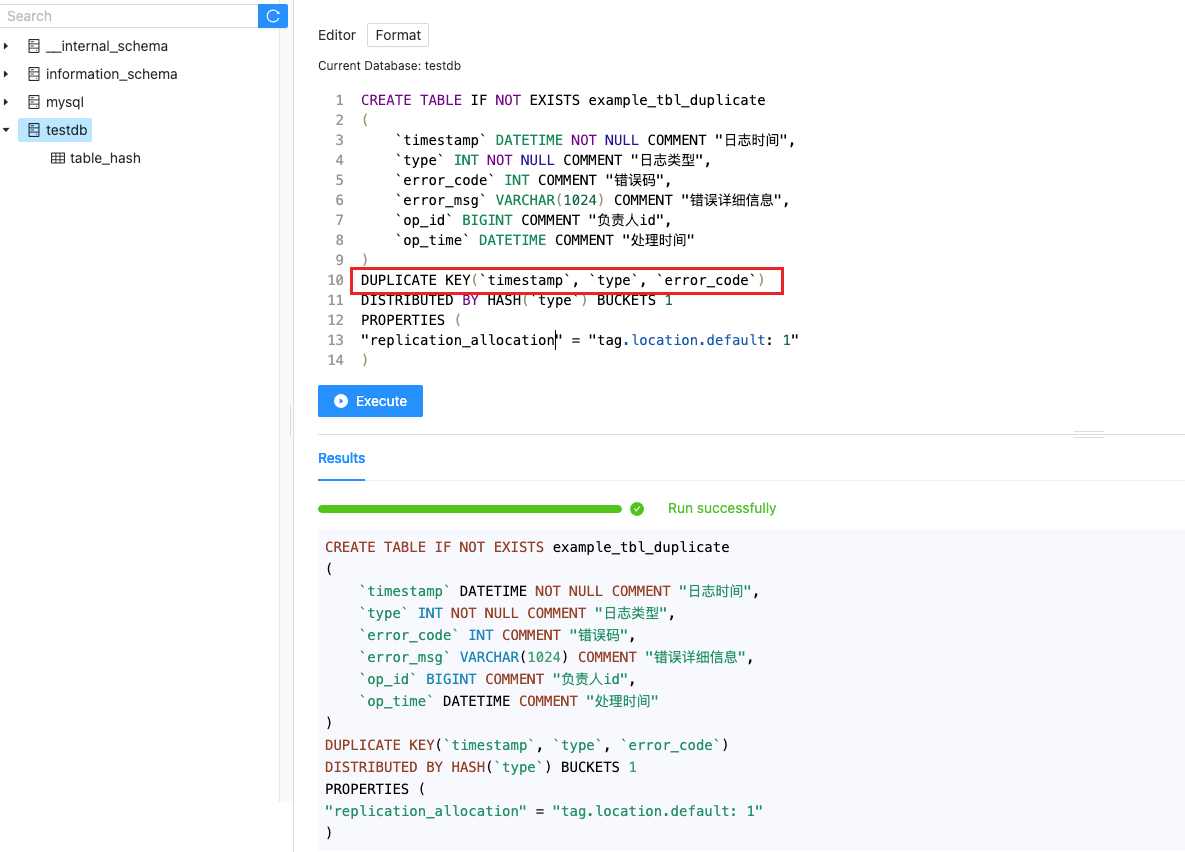
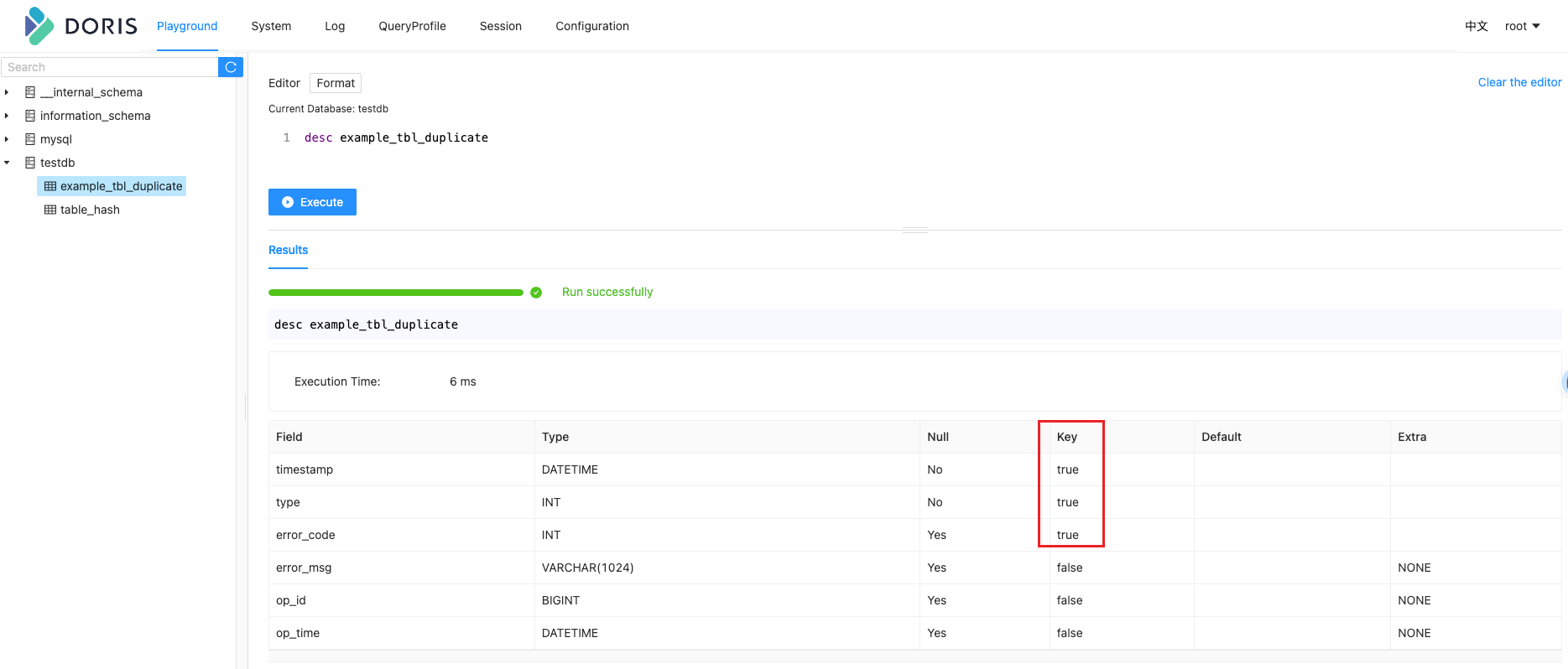
主键模型(Unique Key Model)
当用户有数据更新需求时,可以选择使用主键数据模型(Unique)。主键模型能够保证 Key(主键)的唯一性,当用户更新一条数据时,新写入的数据会覆盖具有相同 key(主键)的旧数据。
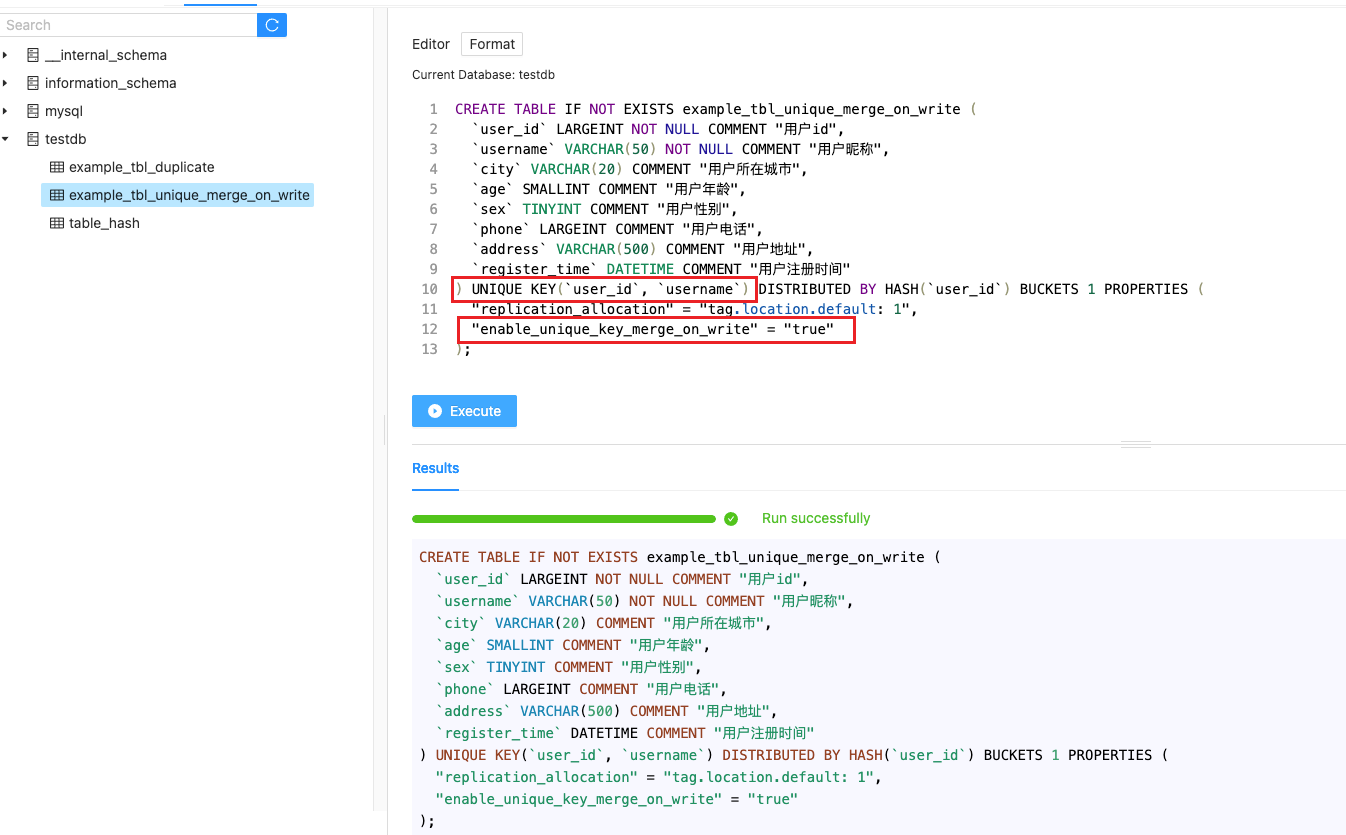
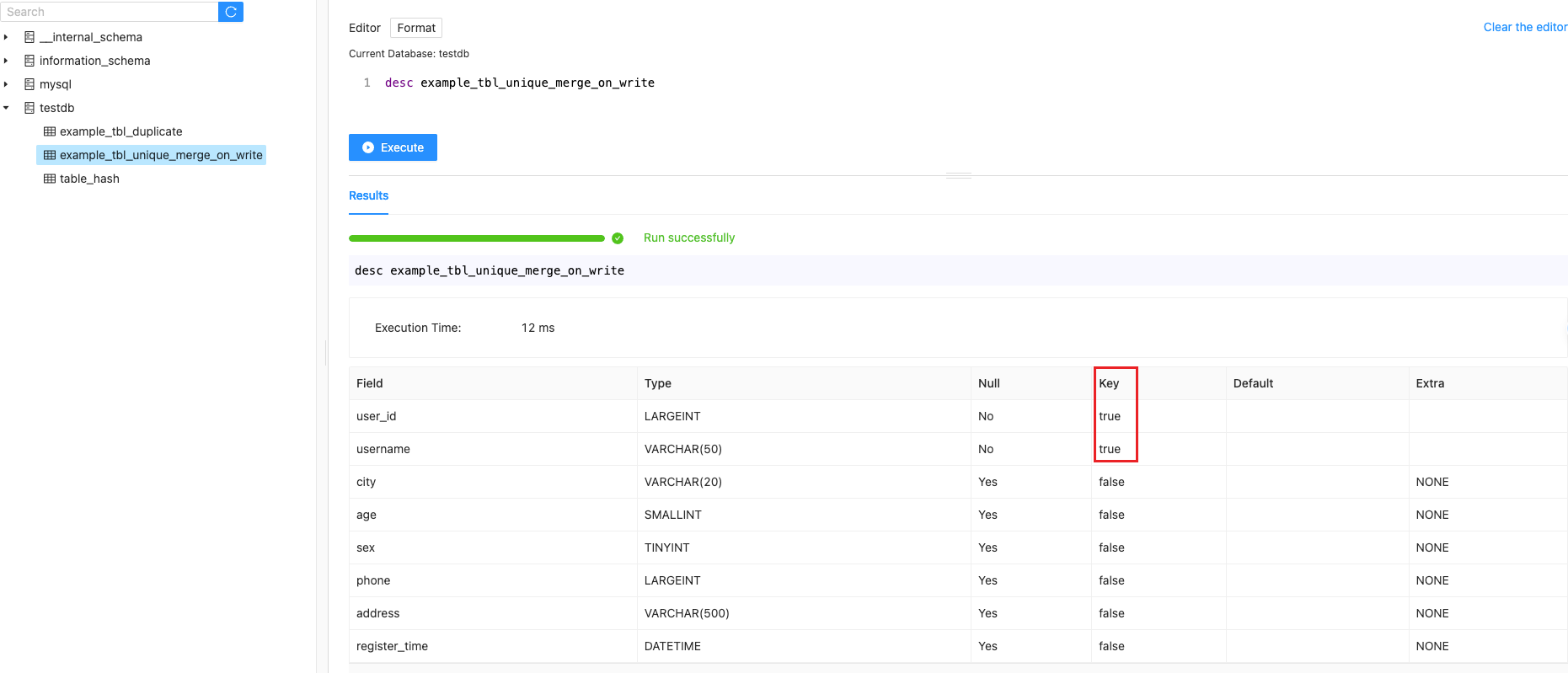
用户需要在建表时添加下面的 property 来开启写时合并。“enable_unique_key_merge_on_write” = “true”.
-
在 2.1 版本中,写时合并将会是主键模型的默认方式。
-
整行更新:Unique 模型默认的更新语意为整行
UPSERT,即 UPDATE OR INSERT,该行数据的 key 如果存在,则进行更新,如果不存在,则进行新数据插入。在整行UPSERT语意下,即使用户使用 insert into 指定部分列进行写入,Doris 也会在 Planner 中将未提供的列使用 NULL 值或者默认值进行填充
聚合模型(Aggregate Model)
Aggregate 模型可以通过预聚合,极大地降低聚合查询时所需扫描的数据量和查询的计算量,非常适合有固定模式的报表类查询场景。但是该模型对 count(*) 查询很不友好。同时因为固定了 Value 列上的聚合方式,在进行其他类型的聚合查询时,需要考虑语意正确性。
aggr_type 聚合类型,支持以下聚合类型:
SUM:求和。适用数值类型。
MIN:求最小值。适合数值类型。
MAX:求最大值。适合数值类型。
REPLACE:替换。对于维度列相同的行,指标列会按照导入的先后顺序,后导入的替换先导入的。
REPLACE_IF_NOT_NULL:非空值替换。和 REPLACE 的区别在于对于 NULL 值,不做替换。这里要注意的是字段默认值要给 NULL,而不能是空字符串,如果是空字符串,会给你替换成空字符串。
HLL_UNION:HLL 类型的列的聚合方式,通过 HyperLogLog 算法聚合。
BITMAP_UNION:BIMTAP 类型的列的聚合方式,进行位图的并集聚合。
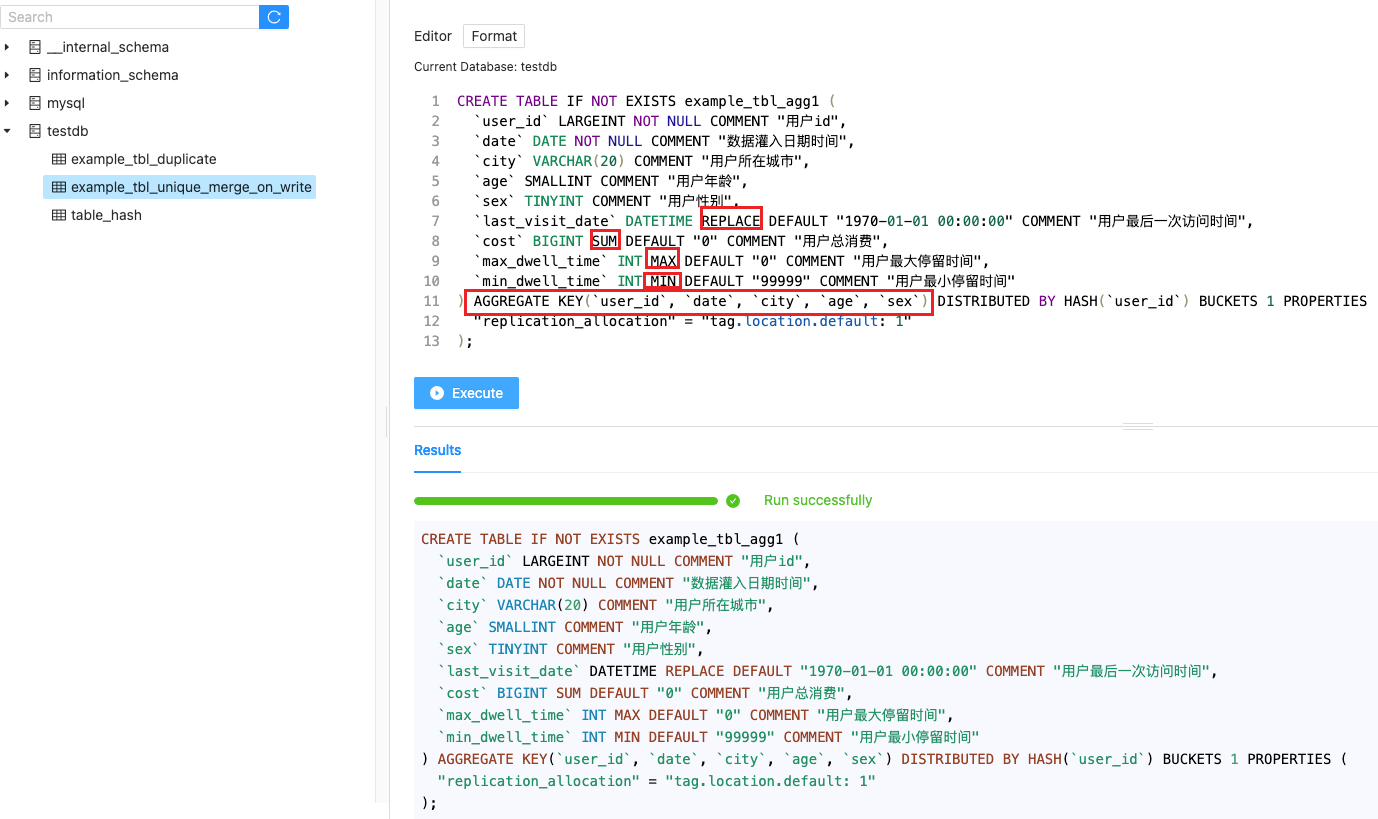
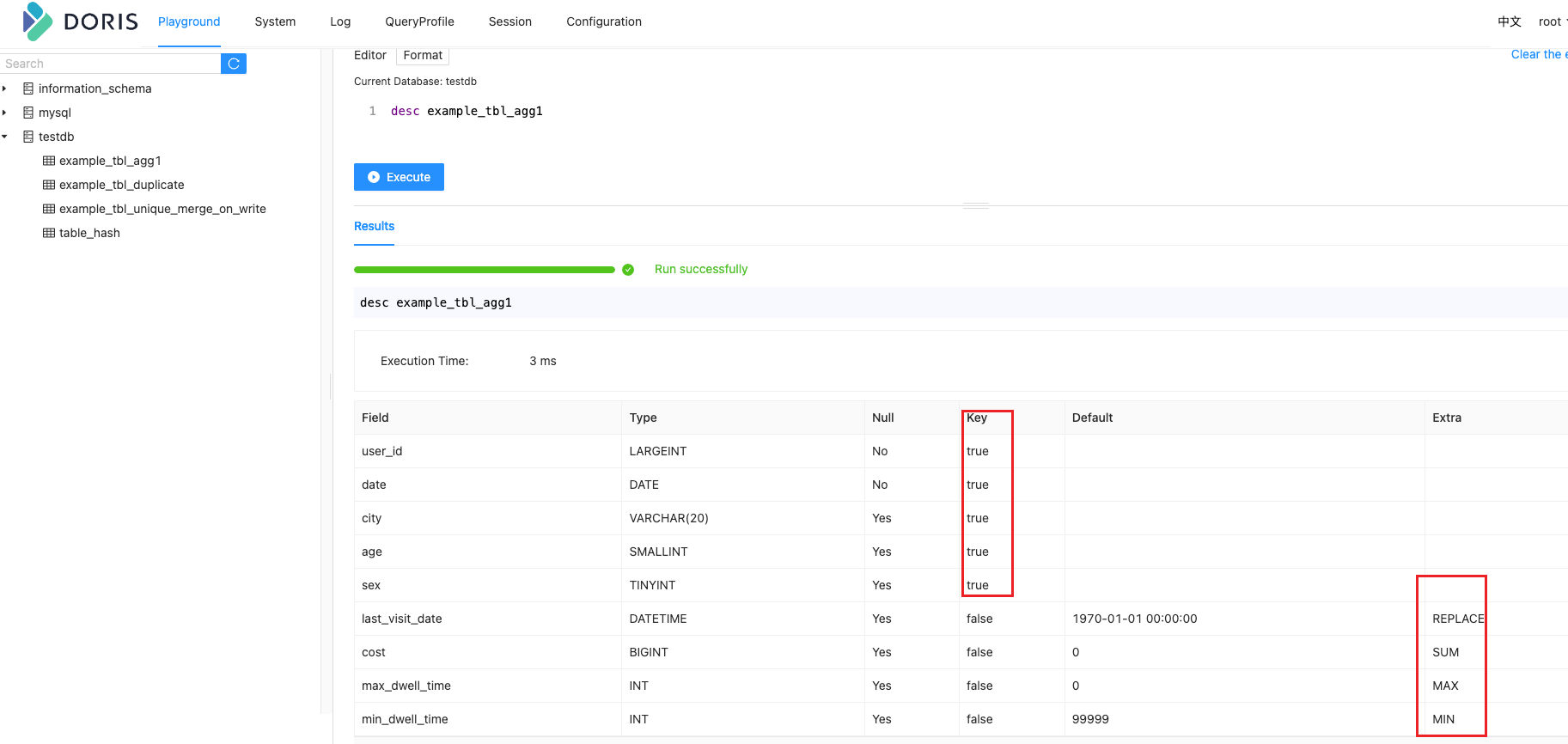
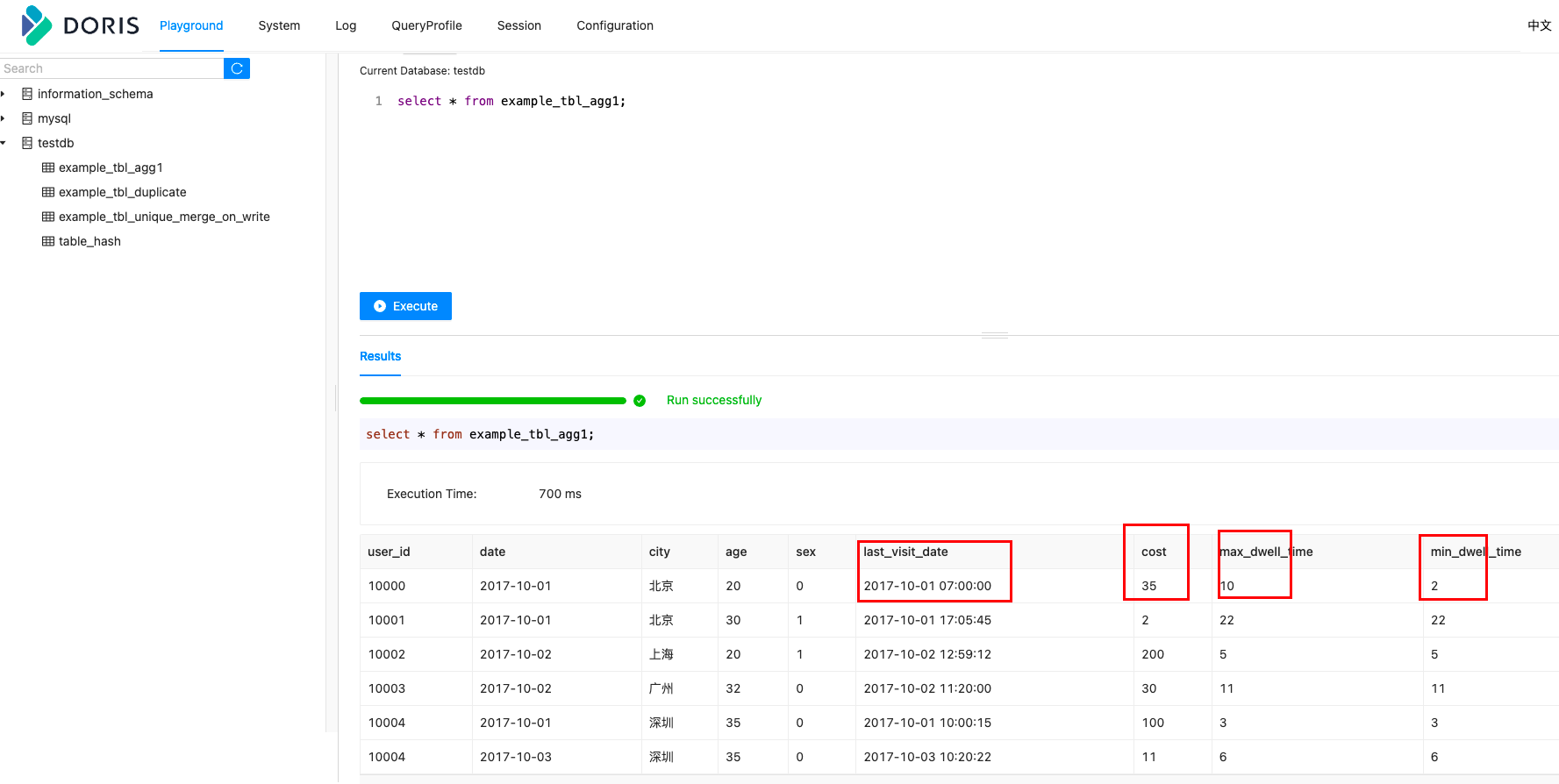
插入数据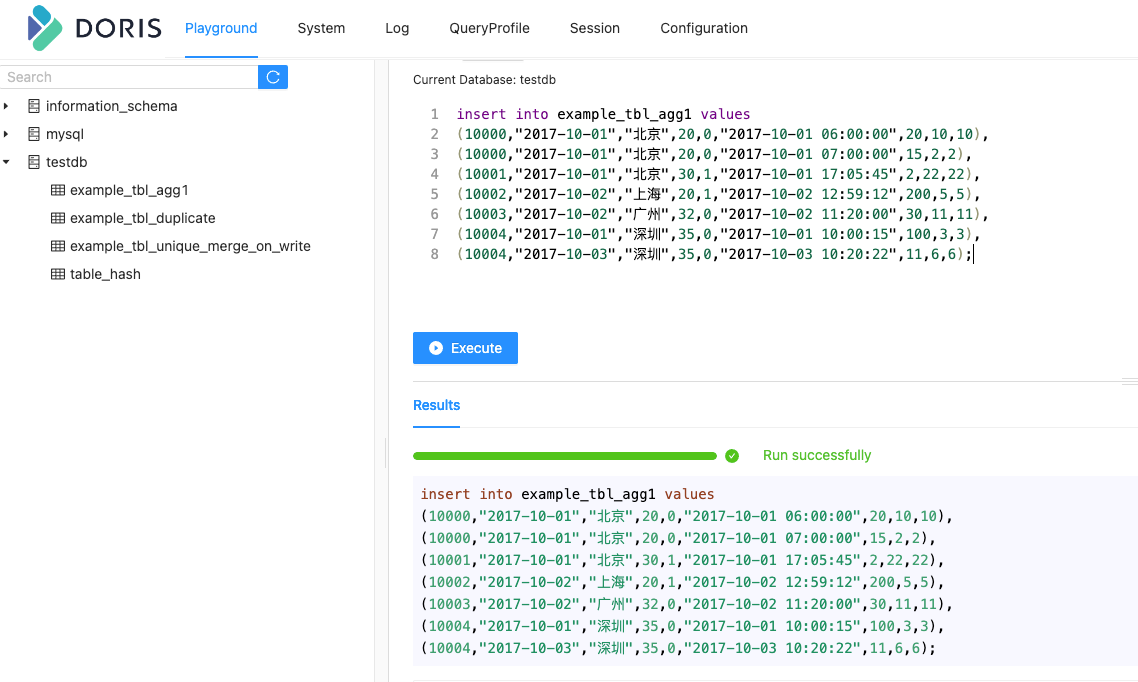
模型选择建议
因为数据模型在建表时就已经确定,且无法修改。所以,选择一个合适的数据模型非常重要。
-
Aggregate 模型可以通过预聚合,极大地降低聚合查询时所需扫描的数据量和查询的计算量,非常适合有固定模式的报表类查询场景。但是该模型对 count(*) 查询很不友好。同时因为固定了 Value 列上的聚合方式,在进行其他类型的聚合查询时,需要考虑语意正确性。
-
Unique 模型针对需要唯一主键约束的场景,可以保证主键唯一性约束。但是无法利用 ROLLUP 等预聚合带来的查询优势。对于聚合查询有较高性能需求的用户,推荐使用自 1.2 版本加入的写时合并实现。
-
Duplicate 适合任意维度的 Ad-hoc 查询。虽然同样无法利用预聚合的特性,但是不受聚合模型的约束,可以发挥列存模型的优势(只读取相关列,而不需要读取所有 Key 列)。
分区分桶
概念
Doris 支持两层的数据划分。第一层是分区(Partition),支持 Range 和 List 的划分方式。第二层是 Bucket(Tablet),支持 Hash 和 Random 的划分方式。建表时如果不建立分区,此时 Doris 会生成一个默认的分区,对用户是透明的。使用默认分区时,只支持 Bucket 划分。
采用两层数据划分的好处:
-
有时间维度或类似带有有序值的维度,可以以这类维度列作为分区列。分区粒度可以根据导入频次、分区数据量等进行评估。
-
历史数据删除需求:如有删除历史数据的需求(比如仅保留最近 N 天的数据)。使用复合分区,可以通过删除历史分区来达到目的。也可以通过在指定分区内发送 DELETE 语句进行数据删除。
-
解决数据倾斜问题:每个分区可以单独指定分桶数量。如按天分区,当每天的数据量差异很大时,可以通过指定分区的分桶数,合理划分不同分区的数据,分桶列建议选择区分度大的列。
手动分区
分区列
-
分区列可以指定一列或多列,分区列必须为 KEY 列。多列分区的使用方式在后面多列分区小结介绍。
-
PARTITION 列默认必须为 NOT NULL 列,如果需要使用 NULL 列,应设置 session variable
allow_partition_column_nullable = true。对于 LIST PARTITION,支持真正的 NULL 分区。对于 RANGE PARTITION,NULL 值会被划归最小的 LESS THAN 分区。 -
不论分区列是什么类型,在写分区值时,都需要加双引号。
-
分区数量理论上没有上限。
-
当不使用分区建表时,系统会自动生成一个和表名同名的,全值范围的分区。该分区对用户不可见,并且不可删改。
-
创建分区时不可添加范围重叠的分区。
Range 分区
分区列通常为时间列,以方便的管理新旧数据。Range 分区支持的列类型 DATE, DATETIME, TINYINT, SMALLINT, INT, BIGINT, LARGEINT。
分区信息,支持四种写法
FIXED RANGE
定义分区的左闭右开区间
PARTITION BY RANGE(col1[, col2, ...])
(
PARTITION partition_name1 VALUES [("k1-lower1", "k2-lower1", "k3-lower1",...), ("k1-upper1", "k2-upper1", "k3-upper1", ...)),
PARTITION partition_name2 VALUES [("k1-lower1-2", "k2-lower1-2", ...), ("k1-upper1-2", MAXVALUE, ))
)
示例如下:
PARTITION BY RANGE(`date`)
(
PARTITION `p201701` VALUES [("2017-01-01"), ("2017-02-01")),
PARTITION `p201702` VALUES [("2017-02-01"), ("2017-03-01")),
PARTITION `p201703` VALUES [("2017-03-01"), ("2017-04-01"))
)
LESS THAN
仅定义分区上界。下界由上一个分区的上界决定。
PARTITION BY RANGE(col1[, col2, ...])
(
PARTITION partition_name1 VALUES LESS THAN MAXVALUE | ("value1", "value2", ...),
PARTITION partition_name2 VALUES LESS THAN MAXVALUE | ("value1", "value2", ...)
)
示例如下:
PARTITION BY RANGE(`date`)
(
PARTITION `p201701` VALUES LESS THAN ("2017-02-01"),
PARTITION `p201702` VALUES LESS THAN ("2017-03-01"),
PARTITION `p201703` VALUES LESS THAN ("2017-04-01"),
PARTITION `p2018` VALUES [("2018-01-01"), ("2019-01-01")),
PARTITION `other` VALUES LESS THAN (MAXVALUE)
)
BATCH RANGE
批量创建数字类型和时间类型的 RANGE 分区,定义分区的左闭右开区间,设定步长。
PARTITION BY RANGE(int_col)
(
FROM (start_num) TO (end_num) INTERVAL interval_value
)
PARTITION BY RANGE(date_col)
(
FROM ("start_date") TO ("end_date") INTERVAL num YEAR | num MONTH | num WEEK | num DAY | 1 HOUR
)
示例如下:
PARTITION BY RANGE(age)
(
FROM (1) TO (100) INTERVAL 10
)
PARTITION BY RANGE(`date`)
(
FROM ("2000-11-14") TO ("2021-11-14") INTERVAL 2 YEAR
)
MULTI RANGE
批量创建 RANGE 分区,定义分区的左闭右开区间
PARTITION BY RANGE(col)
(
FROM ("2000-11-14") TO ("2021-11-14") INTERVAL 1 YEAR,
FROM ("2021-11-14") TO ("2022-11-14") INTERVAL 1 MONTH,
FROM ("2022-11-14") TO ("2023-01-03") INTERVAL 1 WEEK,
FROM ("2023-01-03") TO ("2023-01-14") INTERVAL 1 DAY,
PARTITION p_20230114 VALUES [('2023-01-14'), ('2023-01-15'))
)
List 分区
分区列支持 BOOLEAN, TINYINT, SMALLINT, INT, BIGINT, LARGEINT, DATE, DATETIME, CHAR, VARCHAR 数据类型,分区值为枚举值。只有当数据为目标分区枚举值其中之一时,才可以命中分区。
Partition 支持通过 VALUES IN (...) 来指定每个分区包含的枚举值。
示例如下:
PARTITION BY LIST(city)
(
PARTITION `p_cn` VALUES IN ("Beijing", "Shanghai", "Hong Kong"),
PARTITION `p_usa` VALUES IN ("New York", "San Francisco"),
PARTITION `p_jp` VALUES IN ("Tokyo")
)
List 分区也支持多列分区,示例如下:
PARTITION BY LIST(id, city)
(
PARTITION p1_city VALUES IN (("1", "Beijing"), ("1", "Shanghai")),
PARTITION p2_city VALUES IN (("2", "Beijing"), ("2", "Shanghai")),
PARTITION p3_city VALUES IN (("3", "Beijing"), ("3", "Shanghai"))
)
NULL 分区
PARTITION 列默认必须为 NOT NULL 列,如果需要使用 NULL 列,应设置 session variable allow_partition_column_nullable = true。对于 LIST PARTITION,我们支持真正的 NULL 分区。对于 RANGE PARTITION,NULL 值会被划归最小的 LESS THAN 分区。
动态分区
开启动态分区的表,将会按照设定的规则添加、删除分区,从而对表的分区实现生命周期管理(TTL),减少用户的使用负担。动态分区只支持在 DATE/DATETIME 列上进行 Range 类型的分区。
动态分区适用于分区列的时间数据随现实世界同步增长的情况。此时可以灵活的按照与现实世界同步的时间维度对数据进行分区,自动地根据设置对数据进行冷热分层或者回收。
使用方式
动态分区的规则可以在建表时指定,或者在运行时进行修改。
注意:当前仅支持对单分区列的分区表设定动态分区规则。
CREATE TABLE tbl1
(...)
PROPERTIES
(
"dynamic_partition.prop1" = "value1",
"dynamic_partition.prop2" = "value2",
...
)
ALTER TABLE tbl1 SET
(
"dynamic_partition.prop1" = "value1",
"dynamic_partition.prop2" = "value2",
...
)
创建历史分区规则
当 create_history_partition 为 true,即开启创建历史分区功能时,Doris 会根据 dynamic_partition.start 和 dynamic_partition.history_partition_num 来决定创建历史分区的个数。
假设需要创建的历史分区数量为 expect_create_partition_num,根据不同的设置具体数量如下:
- create_history_partition = true
dynamic_partition.history_partition_num 未设置,即 -1. expect_create_partition_num = end - start;
dynamic_partition.history_partition_num 已设置 expect_create_partition_num = end - max(start, -histoty_partition_num);
- create_history_partition = false 不会创建历史分区,expect_create_partition_num = end - 0;
当 expect_create_partition_num 大于 max_dynamic_partition_num(默认 500)时,禁止创建过多分区。
举例说明:
假设今天是 2021-05-20,按天分区,动态分区的属性设置为,create_history_partition=true, end=3, start=-3,则会根据history_partition_num的设置。
history_partition_num=1,则系统会自动创建以下分区:
p20210519
p20210520
p20210521
p20210522
p20210523
- 表 tbl1 分区列 k1 类型为 DATE,创建一个动态分区规则。按天分区,只保留最近 7 天的分区,并且预先创建未来 3 天的分区
CREATE TABLE tbl1
(
k1 DATE,
...
)
PARTITION BY RANGE(k1) ()
DISTRIBUTED BY HASH(k1)
PROPERTIES
(
"dynamic_partition.enable" = "true",
"dynamic_partition.time_unit" = "DAY",
"dynamic_partition.start" = "-7",
"dynamic_partition.end" = "3",
"dynamic_partition.prefix" = "p",
"dynamic_partition.buckets" = "32"
);
假设当前日期为 2020-05-29。则根据以上规则,tbl1 会产生以下分区:
p20200529: ["2020-05-29", "2020-05-30")
p20200530: ["2020-05-30", "2020-05-31")
p20200531: ["2020-05-31", "2020-06-01")
p20200601: ["2020-06-01", "2020-06-02")
在第二天,即 2020-05-30,会创建新的分区 p20200602: ["2020-06-02", "2020-06-03")
在 2020-06-06 时,因为 dynamic_partition.start 设置为 7,则将删除 7 天前的分区,即删除分区 p20200529。
- 表 tbl1 分区列 k1 类型为 DATETIME,创建一个动态分区规则。按星期分区,只保留最近 2 个星期的分区,并且预先创建未来 2 个星期的分区。
CREATE TABLE tbl1
(
k1 DATETIME,
...
)
PARTITION BY RANGE(k1) ()
DISTRIBUTED BY HASH(k1)
PROPERTIES
(
"dynamic_partition.enable" = "true",
"dynamic_partition.time_unit" = "WEEK",
"dynamic_partition.start" = "-2",
"dynamic_partition.end" = "2",
"dynamic_partition.prefix" = "p",
"dynamic_partition.buckets" = "8"
);
假设当前日期为 2020-05-29,是 2020 年的第 22 周。默认每周起始为星期一。则以上规则,tbl1 会产生以下分区:
p2020_22: ["2020-05-25 00:00:00", "2020-06-01 00:00:00")
p2020_23: ["2020-06-01 00:00:00", "2020-06-08 00:00:00")
p2020_24: ["2020-06-08 00:00:00", "2020-06-15 00:00:00")
其中每个分区的起始日期为当周的周一。同时,因为分区列 k1 的类型为 DATETIME,则分区值会补全时分秒部分,且皆为 0。
在 2020-06-15,即第 25 周时,会删除 2 周前的分区,即删除 p2020_22。
在上面的例子中,假设用户指定了周起始日为 "dynamic_partition.start_day_of_week" = "3",即以每周三为起始日。则分区如下:
p2020_22: ["2020-05-27 00:00:00", "2020-06-03 00:00:00")
p2020_23: ["2020-06-03 00:00:00", "2020-06-10 00:00:00")
p2020_24: ["2020-06-10 00:00:00", "2020-06-17 00:00:00")
- 表 tbl1 分区列 k1 类型为 DATE,创建一个动态分区规则。按月分区,不删除历史分区,并且预先创建未来 2 个月的分区。同时设定以每月 3 号为起始日。
CREATE TABLE tbl1
(
k1 DATE,
...
)
PARTITION BY RANGE(k1) ()
DISTRIBUTED BY HASH(k1)
PROPERTIES
(
"dynamic_partition.enable" = "true",
"dynamic_partition.time_unit" = "MONTH",
"dynamic_partition.end" = "2",
"dynamic_partition.prefix" = "p",
"dynamic_partition.buckets" = "8",
"dynamic_partition.start_day_of_month" = "3"
);
假设当前日期为 2020-05-29。则基于以上规则,tbl1 会产生以下分区:
p202005: ["2020-05-03", "2020-06-03")
p202006: ["2020-06-03", "2020-07-03")
p202007: ["2020-07-03", "2020-08-03")
因为没有设置 dynamic_partition.start,则不会删除历史分区。
假设今天为 2020-05-20,并设置以每月 28 号为起始日,则分区范围为:
p202004: ["2020-04-28", "2020-05-28")
p202005: ["2020-05-28", "2020-06-28")
p202006: ["2020-06-28", "2020-07-28")
自动分区
使用场景
自动分区功能主要解决了用户预期基于某列对表进行分区操作,但该列的数据分布比较零散或者难以预测,在建表或调整表结构时难以准确创建所需分区,或者分区数量过多以至于手动创建过于繁琐的问题。
以时间类型分区列为例,在动态分区功能中,我们支持了按特定时间周期自动创建新分区以容纳实时数据。对于实时的用户行为日志等场景该功能基本能够满足需求。但在一些更复杂的场景下,例如处理非实时数据时,分区列与当前系统时间无关,且包含大量离散值。此时为提高效率我们希望依据此列对数据进行分区,但数据实际可能涉及的分区无法预先掌握,或者预期所需分区数量过大。这种情况下动态分区或者手动创建分区无法满足我们的需求,自动分区功能很好地覆盖了此类需求。
语法
- AUTO RANGE PARTITION
CREATE TABLE `date_table` (
`TIME_STAMP` datev2 NOT NULL COMMENT '采集日期'
) ENGINE=OLAP
DUPLICATE KEY(`TIME_STAMP`)
AUTO PARTITION BY RANGE (date_trunc(`TIME_STAMP`, 'month'))
(
)
DISTRIBUTED BY HASH(`TIME_STAMP`) BUCKETS 10
PROPERTIES (
"replication_allocation" = "tag.location.default: 1"
);
- AUTO LIST PARTITION
CREATE TABLE `str_table` (
`str` varchar not null
) ENGINE=OLAP
DUPLICATE KEY(`str`)
AUTO PARTITION BY LIST (`str`)
(
)
DISTRIBUTED BY HASH(`str`) BUCKETS 10
PROPERTIES (
"replication_allocation" = "tag.location.default: 1"
);
手动分桶
如果使用了分区,则 DISTRIBUTED ... 语句描述的是数据在各个分区内的划分规则。
如果不使用分区,则描述的是对整个表的数据的划分规则。
也可以对每个分区单独指定分桶方式。
分桶列可以是多列,Aggregate 和 Unique 模型必须为 Key 列,Duplicate 模型可以是 key 列和 value 列。分桶列可以和 Partition 列相同或不同。
分桶列的选择,是在 查询吞吐 和 查询并发 之间的一种权衡:
-
如果选择多个分桶列,则数据分布更均匀。如果一个查询条件不包含所有分桶列的等值条件,那么该查询会触发所有分桶同时扫描,这样查询的吞吐会增加,单个查询的延迟随之降低。这个方式适合大吞吐低并发的查询场景。
-
如果仅选择一个或少数分桶列,则对应的点查询可以仅触发一个分桶扫描。此时,当多个点查询并发时,这些查询有较大的概率分别触发不同的分桶扫描,各个查询之间的 IO 影响较小(尤其当不同桶分布在不同磁盘上时),所以这种方式适合高并发的点查询场景。
Bucket 的数量和数据量的建议
-
一个表的 Tablet 总数量等于 (Partition num * Bucket num)。
-
一个表的 Tablet 数量,在不考虑扩容的情况下,推荐略多于整个集群的磁盘数量。
-
单个 Tablet 的数据量理论上没有上下界,但建议在 1G - 10G 的范围内。如果单个 Tablet 数据量过小,则数据的聚合效果不佳,且元数据管理压力大。如果数据量过大,则不利于副本的迁移、补齐,且会增加 Schema Change 或者 Rollup 操作失败重试的代价(这些操作失败重试的粒度是 Tablet)。
-
当 Tablet 的数据量原则和数量原则冲突时,建议优先考虑数据量原则。
-
在建表时,每个分区的 Bucket 数量统一指定。但是在动态增加分区时(
ADD PARTITION),可以单独指定新分区的 Bucket 数量。可以利用这个功能方便的应对数据缩小或膨胀。 -
一个 Partition 的 Bucket 数量一旦指定,不可更改。所以在确定 Bucket 数量时,需要预先考虑集群扩容的情况。比如当前只有 3 台 host,每台 host 有 1 块盘。如果 Bucket 的数量只设置为 3 或更小,那么后期即使再增加机器,也不能提高并发度。
-
举一些例子:假设在有 10 台 BE,每台 BE 一块磁盘的情况下。如果一个表总大小为 500MB,则可以考虑 4-8 个分片。5GB:8-16 个分片。50GB:32 个分片。500GB:建议分区,每个分区大小在 50GB 左右,每个分区 16-32 个分片。5TB:建议分区,每个分区大小在 50GB 左右,每个分区 16-32 个分片。
Random Distribution
-
如果 OLAP 表没有更新类型的字段,将表的数据分桶模式设置为 RANDOM,则可以避免严重的数据倾斜 (数据在导入表对应的分区的时候,单次导入作业每个 batch 的数据将随机选择一个 tablet 进行写入)。
-
当表的分桶模式被设置为 RANDOM 时,因为没有分桶列,无法根据分桶列的值仅对几个分桶查询,对表进行查询的时候将对命中分区的全部分桶同时扫描,该设置适合对表数据整体的聚合查询分析而不适合高并发的点查询。
-
如果 OLAP 表的是 Random Distribution 的数据分布,那么在数据导入的时候可以设置单分片导入模式(将
load_to_single_tablet设置为 true),那么在大数据量的导入的时候,一个任务在将数据写入对应的分区时将只写入一个分片,这样将能提高数据导入的并发度和吞吐量,减少数据导入和 Compaction 导致的写放大问题,保障集群的稳定性。
自动分桶
用户经常设置不合适的 bucket,导致各种问题,这里提供一种方式,来自动设置分桶数。当前只对 OLAP 表生效。
DISTRIBUTED BY HASH(site) BUCKETS AUTO
properties("estimate_partition_size" = "2G")
新增的配置参数 estimate_partition_size 表示一个单分区的数据量。该参数是可选的,如果没有给出则 Doris 会将 estimate_partition_size 的默认值取为 10GB。从上文中已经得知,一个分桶在物理层面就是一个 Tablet,为了获得最好的性能,建议 Tablet 的大小在 1GB - 10GB 的范围内。
那么自动分桶推算是如何保证 Tablet 大小处于这个范围内的呢?
-
若是整体数据量较小,则分桶数不要设置过多
-
若是整体数据量较大,则应使桶数跟总的磁盘块数相关,充分利用每台 BE 机器和每块磁盘的能力。
远程存储
需求场景
未来一个很大的使用场景是类似于 ES 日志存储,日志场景下数据会按照日期来切割数据,很多数据是冷数据,查询很少,需要降低这类数据的存储成本。从节约存储成本角度考虑:
-
各云厂商普通云盘的价格都比对象存储贵
-
在 Doris 集群实际线上使用中,普通云盘的利用率无法达到 100%
-
云盘不是按需付费,而对象存储可以做到按需付费
-
基于普通云盘做高可用,需要实现多副本,某副本异常要做副本迁移。而将数据放到对象存储上则不存在此类问题,因为对象存储是共享的。
解决方案
在 Partition 级别上设置 Freeze time,表示多久这个 Partition 会被 Freeze,并且定义 Freeze 之后存储的 Remote storage 的位置。在 BE 上 daemon 线程会周期性的判断表是否需要 freeze,若 freeze 后会将数据上传到兼容 S3 协议的对象存储和 HDFS 上。
冷热分层支持所有 Doris 功能,只是把部分数据放到对象存储上,以节省成本,不牺牲功能。因此有如下特点:
-
冷数据放到对象存储上,用户无需担心数据一致性和数据安全性问题
-
灵活的 Freeze 策略,冷却远程存储 Property 可以应用到表和 Partition 级别
-
用户查询数据,无需关注数据分布位置,若数据不在本地,会拉取对象上的数据,并 cache 到 BE 本地
-
副本 clone 优化,若存储数据在对象上,则副本 clone 的时候不用去拉取存储数据到本地
-
远程对象空间回收 recycler,若表、分区被删除,或者冷热分层过程中异常情况产生的空间浪费,则会有 recycler 线程周期性的回收,节约存储资源
-
cache 优化,将访问过的冷数据 cache 到 BE 本地,达到非冷热分层的查询性能
-
BE 线程池优化,区分数据来源是本地还是对象存储,防止读取对象延时影响查询性能。
Storage policy 的使用
存储策略是使用冷热分层功能的入口,用户只需要在建表或使用 Doris 过程中,给表或分区关联上 Storage policy,即可以使用冷热分层的功能。
创建 S3 RESOURCE
CREATE RESOURCE "remote_s3"
PROPERTIES
(
"type" = "s3",
"s3.endpoint" = "bj.s3.com",
"s3.region" = "bj",
"s3.bucket" = "test-bucket",
"s3.root.path" = "path/to/root",
"s3.access_key" = "bbb",
"s3.secret_key" = "aaaa",
"s3.connection.maximum" = "50",
"s3.connection.request.timeout" = "3000",
"s3.connection.timeout" = "1000"
);
CREATE STORAGE POLICY test_policy
PROPERTIES(
"storage_resource" = "remote_s3",
"cooldown_ttl" = "1d"
);
CREATE TABLE IF NOT EXISTS create_table_use_created_policy
(
k1 BIGINT,
k2 LARGEINT,
v1 VARCHAR(2048)
)
UNIQUE KEY(k1)
DISTRIBUTED BY HASH (k1) BUCKETS 3
PROPERTIES(
"storage_policy" = "test_policy"
);
创建 HDFS RESOURCE
CREATE RESOURCE "remote_hdfs" PROPERTIES (
"type"="hdfs",
"fs.defaultFS"="fs_host:default_fs_port",
"hadoop.username"="hive",
"hadoop.password"="hive",
"dfs.nameservices" = "my_ha",
"dfs.ha.namenodes.my_ha" = "my_namenode1, my_namenode2",
"dfs.namenode.rpc-address.my_ha.my_namenode1" = "nn1_host:rpc_port",
"dfs.namenode.rpc-address.my_ha.my_namenode2" = "nn2_host:rpc_port",
"dfs.client.failover.proxy.provider.my_ha" = "org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider"
);
CREATE STORAGE POLICY test_policy PROPERTIES (
"storage_resource" = "remote_hdfs",
"cooldown_ttl" = "300"
)
CREATE TABLE IF NOT EXISTS create_table_use_created_policy (
k1 BIGINT,
k2 LARGEINT,
v1 VARCHAR(2048)
)
UNIQUE KEY(k1)
DISTRIBUTED BY HASH (k1) BUCKETS 3
PROPERTIES(
"storage_policy" = "test_policy"
);
关联 Storage policy
对一个已存在的表,关联 Storage policy
AALTER TABLE create_table_not_have_policy set ("storage_policy" = "test_policy");
对一个已存在的 partition,关联 Storage policy
ALTER TABLE create_table_partition MODIFY PARTITION (*) SET("storage_policy"="test_policy");
自增列
对于含有自增列的表,用户在在导入数据时:
-
如果导入的目标列中不包含自增列,则自增列将会被 Doris 自动生成的值填充。
-
如果导入的目标列中包含自增列,则导入数据中该列中的 null 值将会被 Doris 自动生成的值替换,非 null 值则保持不变。需要注意非 null 值会破坏自增列值的唯一性。
唯一性
自增列的唯一性仅保证由 Doris 自动填充的值具有唯一性,而不考虑由用户提供的值,如果用户同时对该表通过显示指定自增列的方式插入了用户提供的值,则不能保证这个唯一性。
聚集性
Doris 保证自增列上自动生成的值是稠密的,但不能保证在一次导入中自动填充的自增列的值是完全连续的,因此可能会出现一次导入中自增列自动填充的值具有一定的跳跃性的现象。这是因为出于性能考虑,每个 BE 上都会缓存一部分预先分配的自增列的值,每个 BE 上缓存的值互不相交。此外,由于缓存的存在,Doris 不能保证在物理时间上后一次导入的数据在自增列上自动生成的值比前一次更大。因此,不能根据自增列分配出的值的大小来判断导入时间上的先后顺序。
语法
创建一个 Dupliciate 模型表,其中一个 key 列是自增列,并设置起始值为 100
CREATE TABLE `demo`.`tbl` (
`id` BIGINT NOT NULL AUTO_INCREMENT(100),
`value` BIGINT NOT NULL
) ENGINE=OLAP
DUPLICATE KEY(`id`)
DISTRIBUTED BY HASH(`id`) BUCKETS 10
PROPERTIES (
"replication_allocation" = "tag.location.default: 3"
);
注意事项
-
仅 Duplicate 模型表和 Unique 模型表可以包含自增列。
-
一张表最多只能包含一个自增列。
-
自增列的类型必须是 BIGINT 类型,且必须为 NOT NULL。
-
自增列手动指定的起始值必须大于等于 0。
数据操作
数据导入
导入概览
支持的数据源
Doris 提供多种数据导入方案,可以针对不同的数据源进行选择不同的数据导入方式。
按场景划分
| 数据源 | 导入方式 |
|---|---|
| 对象存储(s3),HDFS | 使用 Broker 导入数据 |
| 本地文件 | Stream Load, MySQL Load |
| Kafka | 订阅 Kafka 数据 |
| Mysql、PostgreSQL,Oracle,SQLServer | 通过外部表同步数据 |
| 通过 JDBC 导入 | 使用 JDBC 同步数据 |
| 导入 JSON 格式数据 | JSON 格式数据导入 |
按导入方式划分
| 导入方式名称 | 使用方式 |
|---|---|
| Broker Load | 通过 Broker 导入外部存储数据 |
| Stream Load | 流式导入数据 (本地文件及内存数据) |
| Routine Load | 导入 Kafka 数据 |
| Insert Into | 外部表通过 INSERT 方式导入数据 |
| S3 Load | S3 协议的对象存储数据导入 |
| MySQL Load | MySQL 客户端导入本地数据 |
支持的数据格式
不同的导入方式支持的数据格式略有不同。
| 导入方式 | 支持的格式 |
|---|---|
| Broker Load | parquet、orc、csv、gzip |
| Stream Load | csv、json、parquet、orc |
| Routine Load | csv、json |
| MySQL Load | csv |
Stream Load
Stream Load 支持通过 HTTP 协议将本地文件或数据流导入到 Doris 中。Stream Load 是一个同步导入方式,执行导入后返回导入结果,可以通过请求的返回判断导入是否成功。一般来说,可以使用 Stream Load 导入 10GB 以下的文件,如果文件过大,建议将文件进行切分后使用 Stream Load 进行导入。Stream Load 可以保证一批导入任务的原子性,要么全部导入成功,要么全部导入失败。
使用说明
Stream Load 支持导入 CSV、JSON、Parquet 与 ORC 格式的数据。
在导入 CSV 文件时,需要明确区分空值(null)与空字符串:
-
空值(null)需要用 \N 表示,a,\N,b 数据表示中间列是一个空值(null)
-
空字符串直接将数据置空,a, ,b 数据表示中间列是一个空字符串
Stream Load 的主要流程
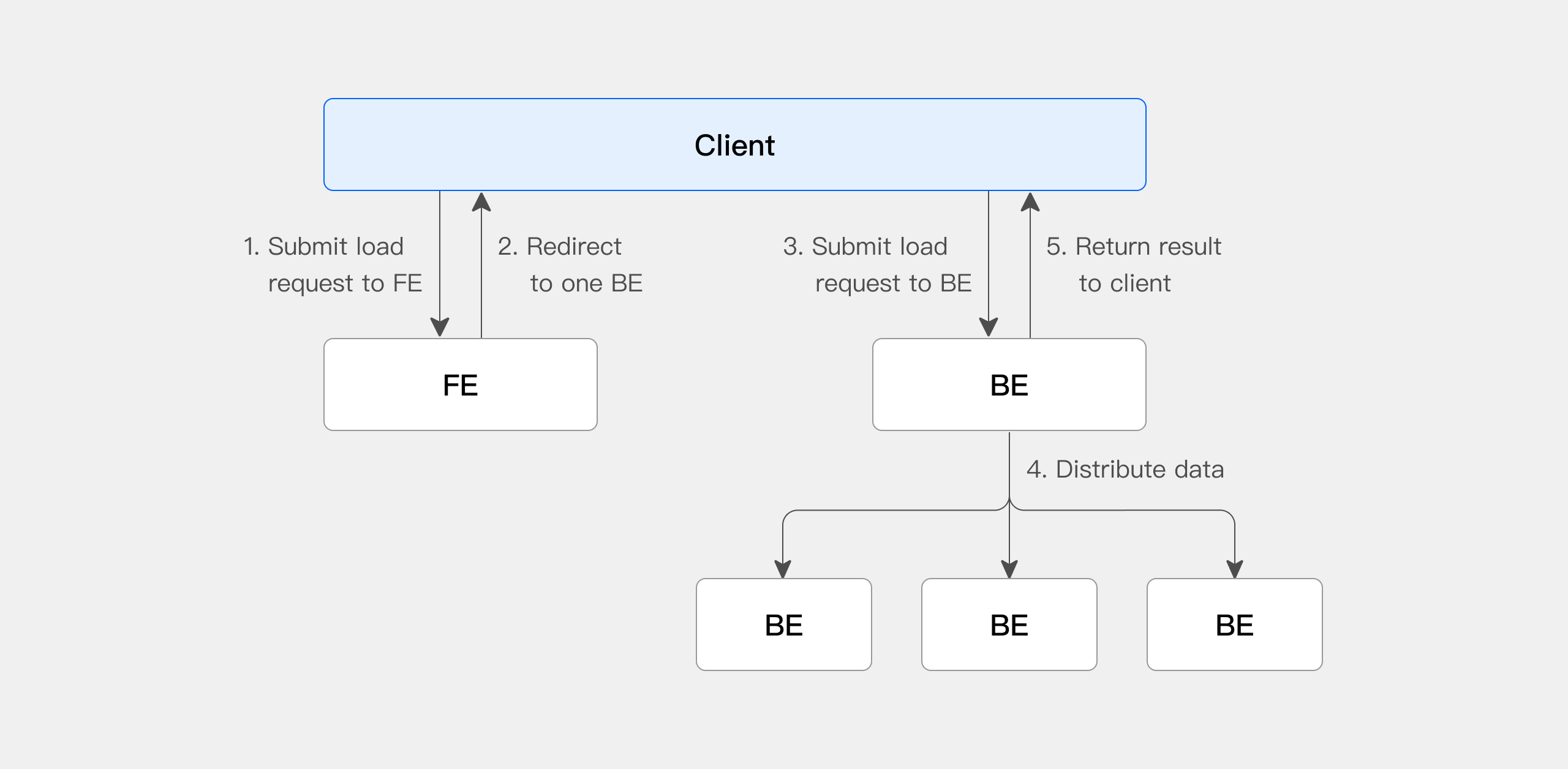
在使用 Stream Load 时,需要通过 HTTP 协议发起导入作业给 FE 节点,FE 会以轮询方式,重定向(redirect)请求给一个 BE 节点以达到负载均衡的效果。也可以直接发送 HTTP 请求作业给指定的 BE 节点。在 Stream Load 中,Doris 会选定一个节点做为 Coordinator 节点。Coordinator 节点负责接受数据并分发数据到其他节点上
-
Client 向 FE 提交 Stream Load 导入作业请求
-
FE 会随机选择一台 BE 作为 Coordinator 节点,负责导入作业调度,然后返回给 Client 一个 HTTP 重定向
-
Client 连接 Coordinator BE 节点,提交导入请求
-
Coordinator BE 会分发数据给相应 BE 节点,导入完成后会返回导入结果给 Client
-
Client 也可以直接通过指定 BE 节点作为 Coordinator,直接分发导入作业
导入 CSV 数据
准备csv文件数据:streamload_example.csv
1,Emily,25
2,Benjamin,35
3,Olivia,28
4,Alexander,60
5,Ava,17
6,William,69
7,Sophia,32
8,James,64
9,Emma,37
10,Liam,64
创建表
CREATE TABLE testdb.test_streamload(
user_id BIGINT NOT NULL COMMENT "用户 ID",
name VARCHAR(20) COMMENT "用户姓名",
age INT COMMENT "用户年龄"
)
DUPLICATE KEY(user_id)
DISTRIBUTED BY HASH(user_id) BUCKETS 10;
如果BE节点数只有一个用下面的语句创建
CREATE TABLE testdb.test_streamload(
user_id BIGINT NOT NULL COMMENT "用户 ID",
name VARCHAR(20) COMMENT "用户姓名",
age INT COMMENT "用户年龄"
)
DUPLICATE KEY(user_id)
DISTRIBUTED BY HASH(user_id) BUCKETS 10
PROPERTIES (
"replication_allocation" = "tag.location.default: 1"
);
通过 curl 命令可以提交 Stream Load 导入作业。
curl --location-trusted -u <doris_user>:<doris_password> \
-H "Expect:100-continue" \
-H "column_separator:," \
-H "columns:user_id,name,age" \
-T streamload_example.csv \
-XPUT http://<fe_ip>:<fe_http_port>/api/testdb/test_streamload/_stream_load
或者直接通过Doris WEB UI页面对某个表进行数据导入,也可以通过专用导入工具 Doris Streamloader,用于将数据导入 Doris 数据库的专用客户端工具。
通过Doris WEB UI页面导入
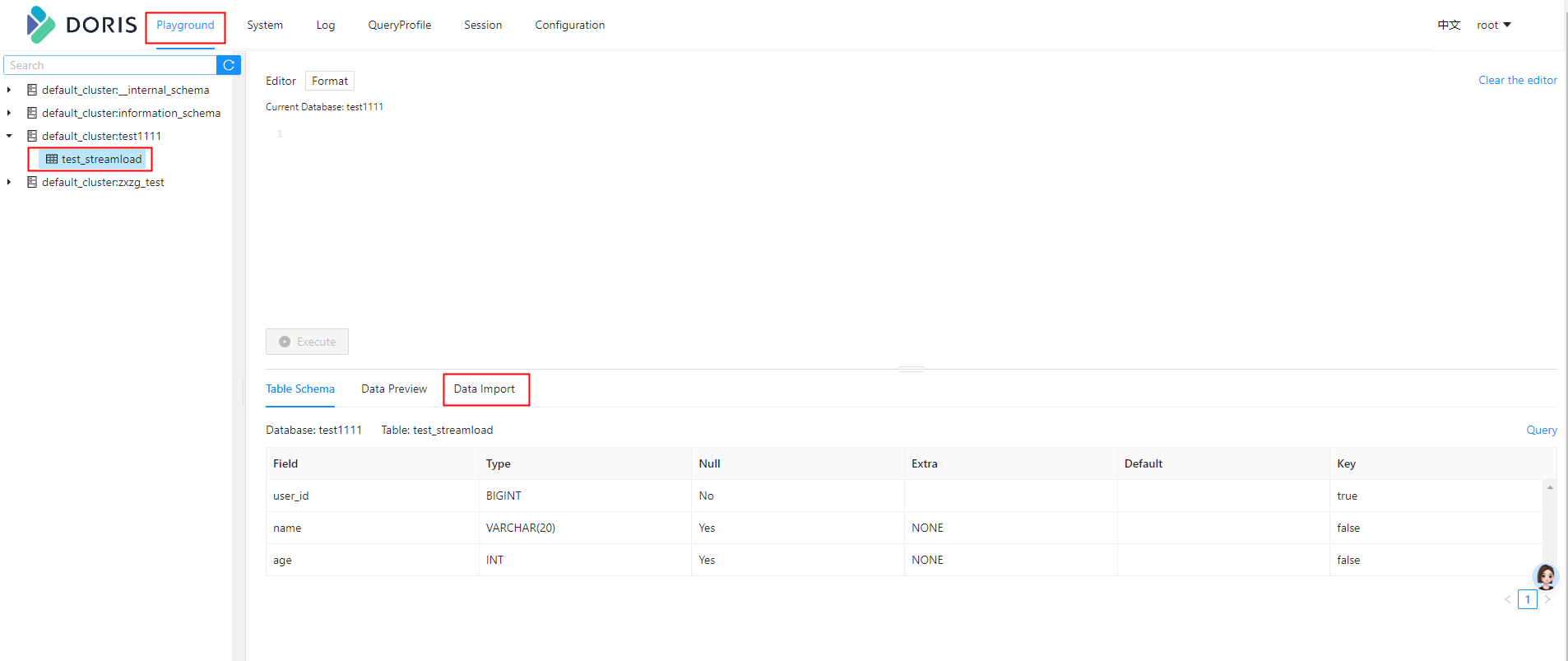
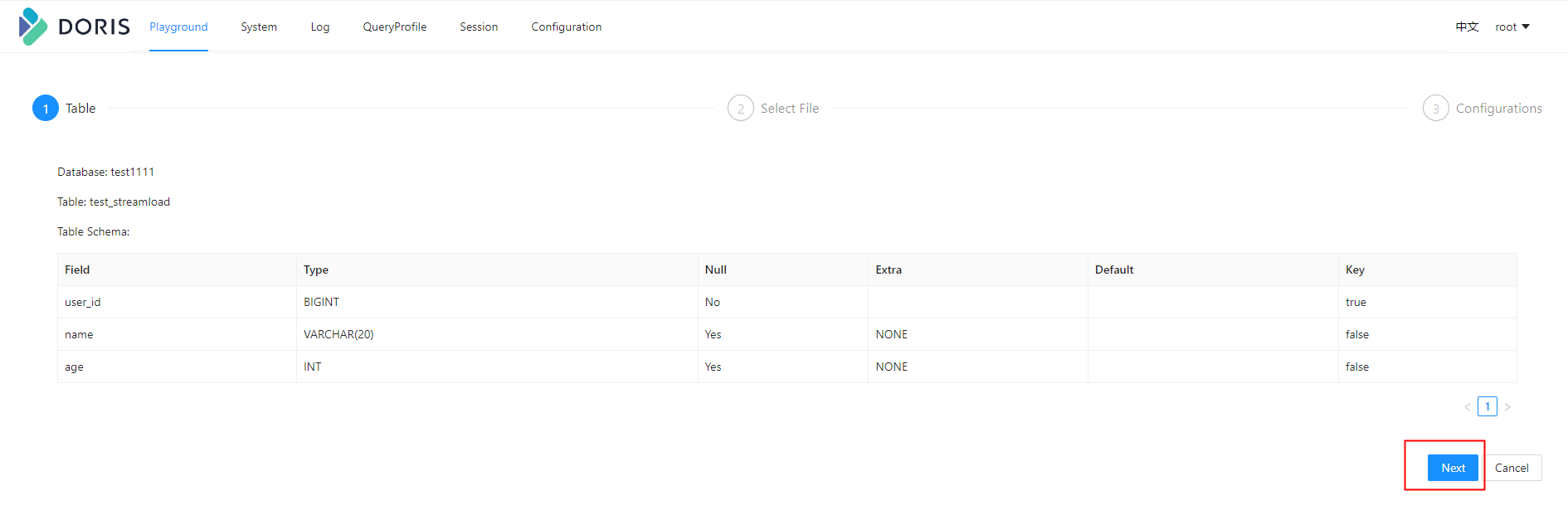
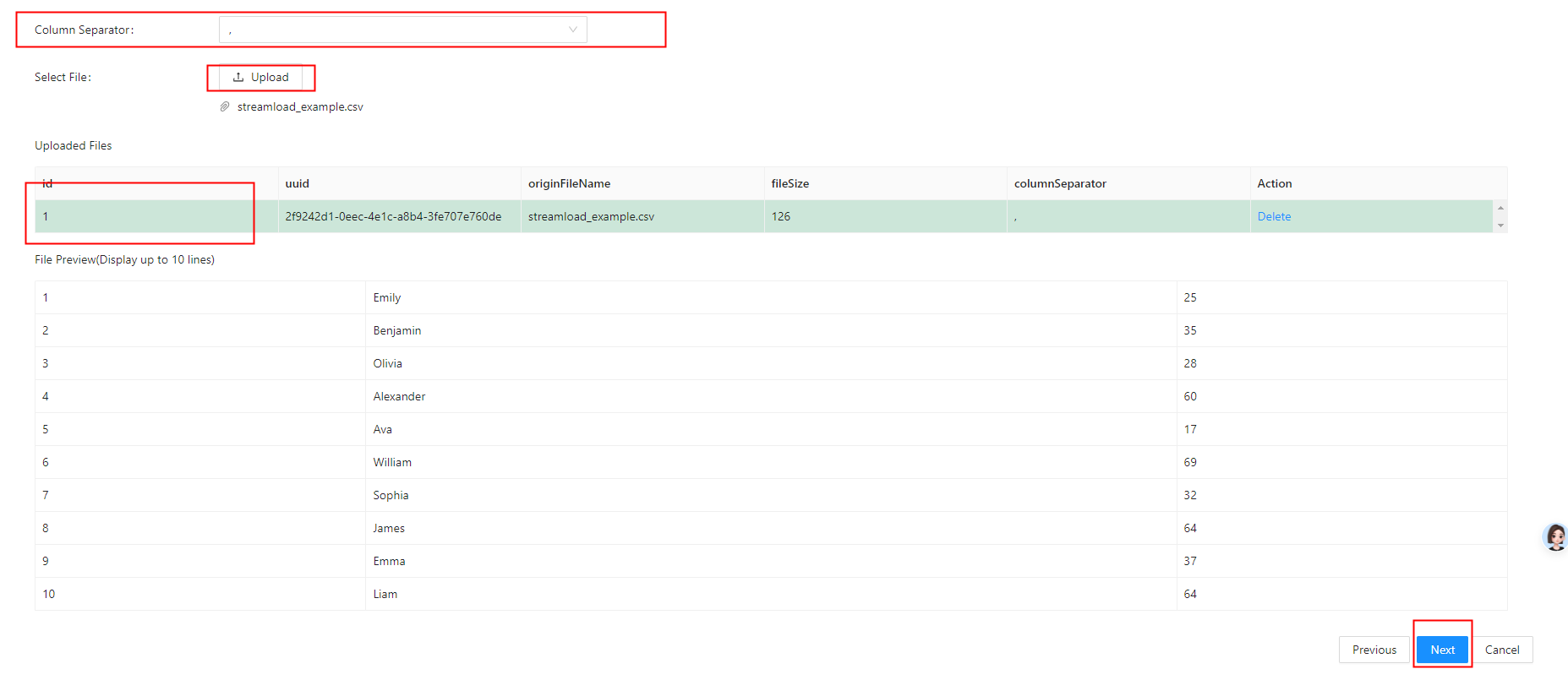
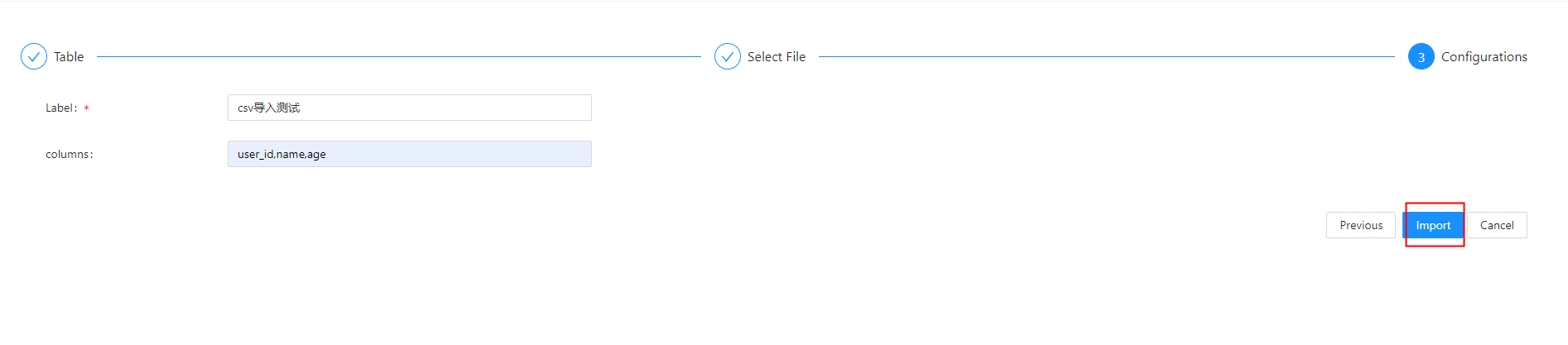
导入JSON数据
准备JSON文件:streamload_example.json
[
{"userid":1,"username":"Emily","userage":25},
{"userid":2,"username":"Benjamin","userage":35},
{"userid":3,"username":"Olivia","userage":28},
{"userid":4,"username":"Alexander","userage":60},
{"userid":5,"username":"Ava","userage":17},
{"userid":6,"username":"William","userage":69},
{"userid":7,"username":"Sophia","userage":32},
{"userid":8,"username":"James","userage":64},
{"userid":9,"username":"Emma","userage":37},
{"userid":10,"username":"Liam","userage":64}
]
通过 curl 命令可以提交 Stream Load 导入作业
curl --location-trusted -u <doris_user>:<doris_password> \
-H "label:124" \
-H "Expect:100-continue" \
-H "format:json" -H "strip_outer_array:true" \
-H "jsonpaths:[\"$.userid\", \"$.username\", \"$.userage\"]" \
-H "columns:user_id,name,age" \
-T streamload_example.json \
-XPUT http://<fe_ip>:<fe_http_port>/api/testdb/test_streamload/_stream_load
Broker Load
Stream Load 是一种推的方式,即导入的数据依靠客户端读取,并推送到 Doris。Broker Load 则是将导入请求发送给 Doris,有 Doris 主动拉取数据,所以如果数据存储在类似 HDFS 或者 对象存储中,则使用 Broker Load 是最方便的。这样,数据就不需要经过客户端,而有 Doris 直接读取导入。
从 HDFS 或者 S3 直接读取,也可以通过 湖仓一体/TVF 中的 HDFS TVF 或者 S3 TVF 进行导入。基于 TVF 的 Insert Into 当前为同步导入,Broker Load 是一个异步的导入方式。
Broker Load 适合源数据存储在远程存储系统,比如 HDFS,并且数据量比较大的场景。
基本原理
用户在提交导入任务后,FE 会生成对应的 Plan 并根据目前 BE 的个数和文件的大小,将 Plan 分给 多个 BE 执行,每个 BE 执行一部分导入数据。
BE 在执行的过程中会从 Broker 拉取数据,在对数据 transform 之后将数据导入系统。所有 BE 均完成导入,由 FE 最终决定导入是否成功。
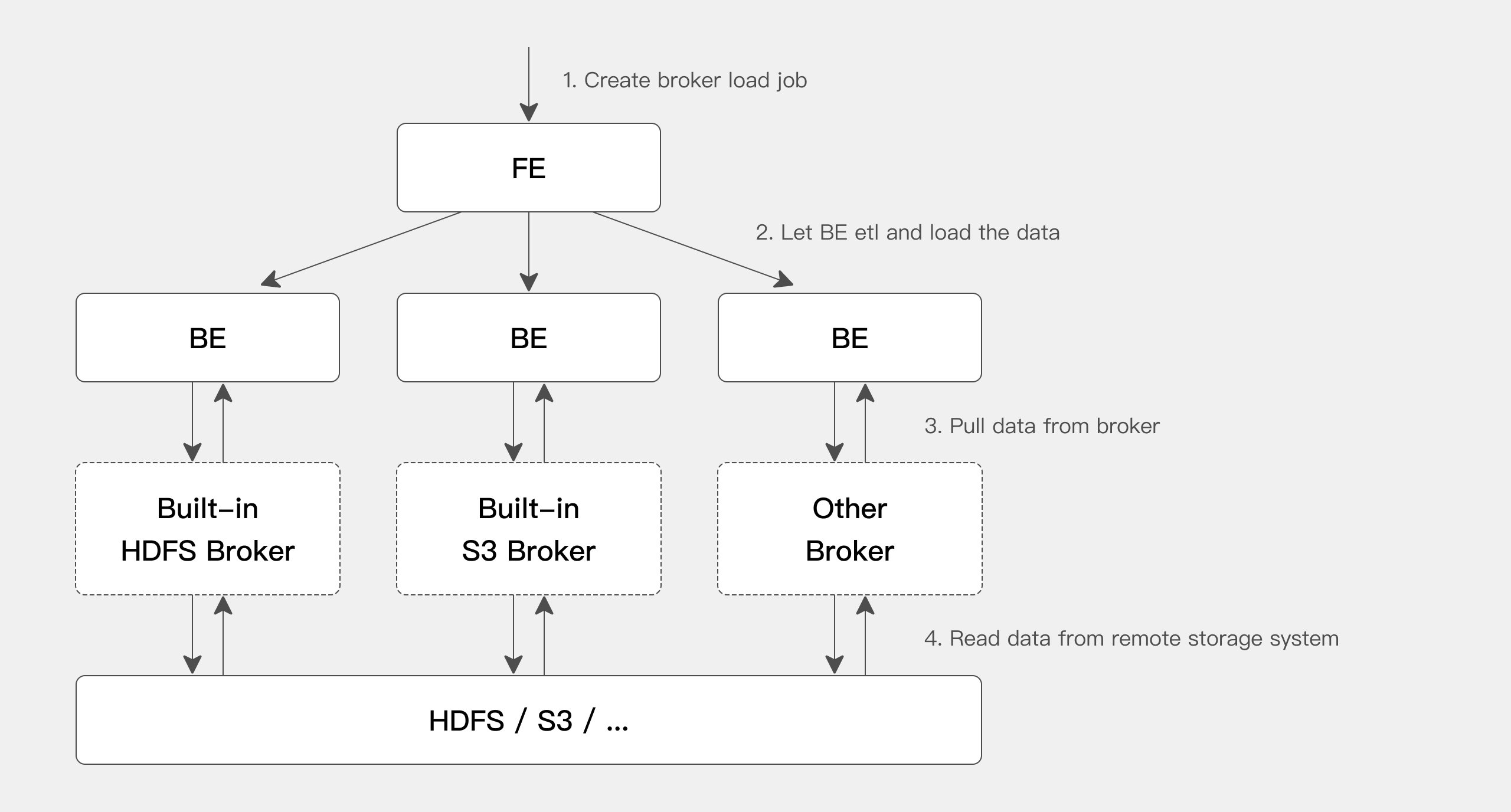
从上图中可以看到,BE 会依赖 Broker 进程来读取相应远程存储系统的数据。之所以引入 Broker 进程,主要是用来针对不同的远程存储系统,用户可以按照 Broker 进程的标准开发其相应的 Broker 进程,Broker 进程可以使用 Java 程序开发,更好的兼容大数据生态中的各类存储系统。由于 broker 进程和 BE 进程的分离,也确保了两个进程的错误隔离,提升 BE 的稳定性。
当前 BE 内置了对 HDFS 和 S3 两个 Broker 的支持,所以如果从 HDFS 和 S3 中导入数据,则不需要额外启动 Broker 进程。如果有自己定制的 Broker 实现,则需要部署相应的 Broker 进程。
导入语法
LOAD LABEL load_label(data_desc1[, data_desc2, ...])WITH [HDFS|S3|BROKER broker_name] [broker_properties][load_properties][COMMENT "comments"];
具体的使用语法,请参考 SQL 手册中的 Broker Load。
查看导入状态
Broker load 是一个异步的导入方式,具体导入结果可以通过 SHOW LOAD 命令查看
mysql> show load order by createtime desc limit 1\G;*************************** 1. row *************************** JobId: 41326624 Label: broker_load_2022_04_15 State: FINISHED Progress: ETL:100%; LOAD:100% Type: BROKER EtlInfo: unselected.rows=0; dpp.abnorm.ALL=0; dpp.norm.ALL=27 TaskInfo: cluster:N/A; timeout(s):1200; max_filter_ratio:0.1 ErrorMsg: NULL CreateTime: 2022-04-01 18:59:06 EtlStartTime: 2022-04-01 18:59:11 EtlFinishTime: 2022-04-01 18:59:11 LoadStartTime: 2022-04-01 18:59:11LoadFinishTime: 2022-04-01 18:59:11 URL: NULL JobDetails: {"Unfinished backends":{"5072bde59b74b65-8d2c0ee5b029adc0":[]},"ScannedRows":27,"TaskNumber":1,"All backends":{"5072bde59b74b65-8d2c0ee5b029adc0":[36728051]},"FileNumber":1,"FileSize":5540}1 row in set (0.01 sec)
取消导入
当 Broker load 作业状态不为 CANCELLED 或 FINISHED 时,可以被用户手动取消。取消时需要指定待取消导入任务的 Label。取消导入命令语法可执行 CANCEL LOAD 查看。
例如:撤销数据库 DEMO 上,label 为 broker_load_2022_03_23 的导入作业
CANCEL LOAD FROM demo WHERE LABEL = "broker_load_2022_03_23";
1. 导入报错:Scan bytes per broker scanner exceed limit:xxx
请参照文档中最佳实践部分,修改 FE 配置项 max_bytes_per_broker_scanner 和 max_broker_concurrency
2. 导入报错:failed to send batch 或 TabletWriter add batch with unknown id
适当修改 query_timeout 和 streaming_load_rpc_max_alive_time_sec。
3. 导入报错:LOAD_RUN_FAIL; msg:Invalid Column Name:xxx
如果是 PARQUET 或者 ORC 格式的数据,则文件头的列名需要与 doris 表中的列名保持一致,如:
(tmp_c1,tmp_c2)SET( id=tmp_c2, name=tmp_c1)
代表获取在 parquet 或 orc 中以 (tmp_c1, tmp_c2) 为列名的列,映射到 doris 表中的 (id, name) 列。如果没有设置 set, 则以 column 中的列作为映射。
注:如果使用某些 hive 版本直接生成的 orc 文件,orc 文件中的表头并非 hive meta 数据,而是(_col0, _col1, _col2, …), 可能导致 Invalid Column Name 错误,那么则需要使用 set 进行映射
4. 导入报错:Failed to get S3 FileSystem for bucket is null/empty
bucket 信息填写不正确或者不存在。或者 bucket 的格式不受支持。使用 GCS 创建带_的桶名时,比如:s3://gs_bucket/load_tbl,S3 Client 访问 GCS 会报错,建议创建 bucket 路径时不使用_。
5. 导入超时
导入的 timeout 默认超时时间为 4 小时。如果超时,不推荐用户将导入最大超时时间直接改大来解决问题。单个导入时间如果超过默认的导入超时时间 4 小时,最好是通过切分待导入文件并且分多次导入来解决问题。因为超时时间设置过大,那么单次导入失败后重试的时间成本很高。
可以通过如下公式计算出 Doris 集群期望最大导入文件数据量:
期望最大导入文件数据量 = 14400s * 10M/s * BE 个数比如:集群的 BE 个数为 10个期望最大导入文件数据量 = 14400s * 10M/s * 10 = 1440000M ≈ 1440G注意:一般用户的环境可能达不到 10M/s 的速度,所以建议超过 500G 的文件都进行文件切分,再导入。
Routine Load
Doris 可以通过 Routine Load 导入方式持续消费 Kafka Topic 中的数据。在提交 Routine Load 作业后,Doris 会持续运行该导入作业,实时生成导入任务不断消费 Kakfa 集群中指定 Topic 中的消息。
基本原理
Routine Load 会持续消费 Kafka Topic 中的数据,写入 Doris 中。
在 Doris 中,创建 Routine Load 作业后会生成一个常驻的导入作业和若干个导入任务:
-
导入作业(load job):一个 Routine Load 对应一个导入作业,导入作业是一个常驻的任务,会持续不断地消费 Kafka Topic 中的数据;
-
导入任务(load task):一个导入作业会被拆解成若干个导入作业,作为一个独立的导入基本单位,以 Stream Load 的方式写入到 BE 中。
Routine Load 的导入具体流程如下图展示:

操作导入作业
创建导入作业
语法
CREATE ROUTINE LOAD [<db_name>.]<job_name> [ON <tbl_name>]
[merge_type]
[load_properties]
[job_properties]
FROM KAFKA [data_source_properties]
[COMMENT "<comment>"]
实际创建语句
create ROUTINE LOAD test1111.kafka_load_job_json ON test_table2
COLUMNS(user_id,name,age)
PROPERTIES(
"format"="json",
"jsonpaths"="[\"$.userId\",\"$.name\",\"$.age\"]",
"desired_concurrent_number"="1"
)
FROM KAFKA(
"kafka_broker_list" = "192.168.100.136:32367",
"kafka_topic" = "doris-test-json",
"kafka_partitions" = "0",
"property.group.id" = "kafka_job",
"property.kafka_default_offsets" = "OFFSET_BEGINNING"
);
查看导入作业
SHOW ROUTINE LOAD FOR test1111.kafka_load_job_json
暂停导入作业
PAUSE ROUTINE LOAD FOR test1111.kafka_load_job_json;
恢复导入作业
RESUME ROUTINE LOAD FOR test1111.kafka_load_job_json;
修改导入作业
ALTER ROUTINE LOAD FOR test1111.kafka_load_job_json
PROPERTIES(
"desired_concurrent_number" = "3"
)
FROM KAFKA(
"kafka_broker_list" = "192.168.88.60:9092",
"kafka_topic" = "test-topic"
);
取消导入作业
停止并删除作业
STOP ROUTINE LOAD FOR test1111.kafka_load_job_json;
导入示例
kafka JSON格式数据导入
创建导入JSON格式数据的任务
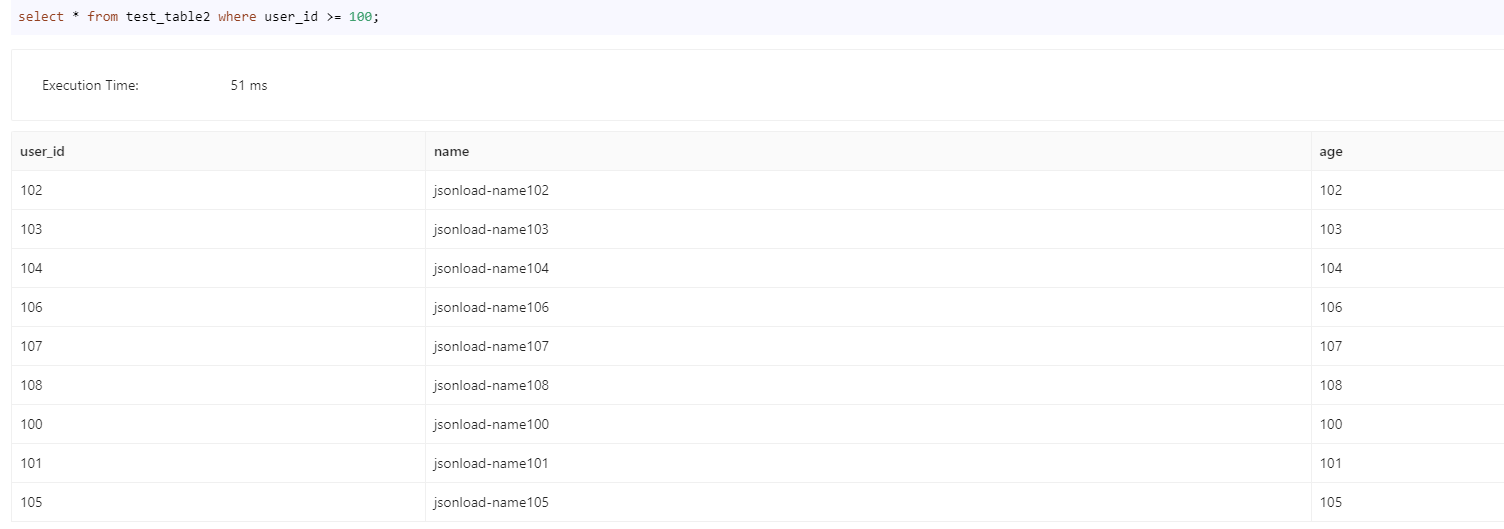
create ROUTINE LOAD test1111.kafka_load_job_json ON test_table2
COLUMNS(user_id,name,age)
PROPERTIES(
"format"="json",
"jsonpaths"="[\"$.userId\",\"$.name\",\"$.age\"]",
"desired_concurrent_number"="1"
)
FROM KAFKA(
"kafka_broker_list" = "192.168.100.136:32367",
"kafka_topic" = "laoqian-topic-csv",
"kafka_partitions" = "0",
"property.group.id" = "kafka_job",
"property.kafka_default_offsets" = "OFFSET_BEGINNING"
);
创建kafka数据
./kafka-console-producer.sh --broker-list 192.168.100.136:32367 --topic laoqian-topic-csv
往topic中写入数据(数据如下:)
{"age":100,"name":"jsonload-name100","userId":100}
{"age":101,"name":"jsonload-name101","userId":101}
{"age":102,"name":"jsonload-name102","userId":102}
{"age":103,"name":"jsonload-name103","userId":103}
{"age":104,"name":"jsonload-name104","userId":104}
{"age":105,"name":"jsonload-name105","userId":105}
{"age":106,"name":"jsonload-name106","userId":106}
{"age":107,"name":"jsonload-name107","userId":107}
{"age":108,"name":"jsonload-name108","userId":108}
./kafka-console-consumer.sh --bootstrap-server 192.168.100.136:32367 --topic laoqian-topic-csv --from-beginning
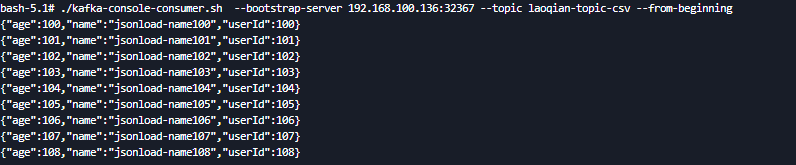
执行结果
Kafka CSV数据写入
kafka数据如下

1,xiaoxiaoli,28
2,xiaoxiaowang,30
3,xiaoxiaoliu,32
4,dadali,34
5,dadawang,36
CSV格式数据导入命令
create ROUTINE LOAD test1111.kafka_load_job_csv ON test_table
COLUMNS TERMINATED BY ",",
COLUMNS(user_id,name,age)
PROPERTIES(
"strict_mode" = "false",
"desired_concurrent_number"="1"
)
FROM KAFKA(
"kafka_broker_list" = "192.168.100.136:32367",
"kafka_topic" = "laoqian-topic-csv2",
"kafka_partitions" = "0",
"property.group.id" = "kafka_job",
"property.kafka_default_offsets" = "OFFSET_BEGINNING"
);
导入结果
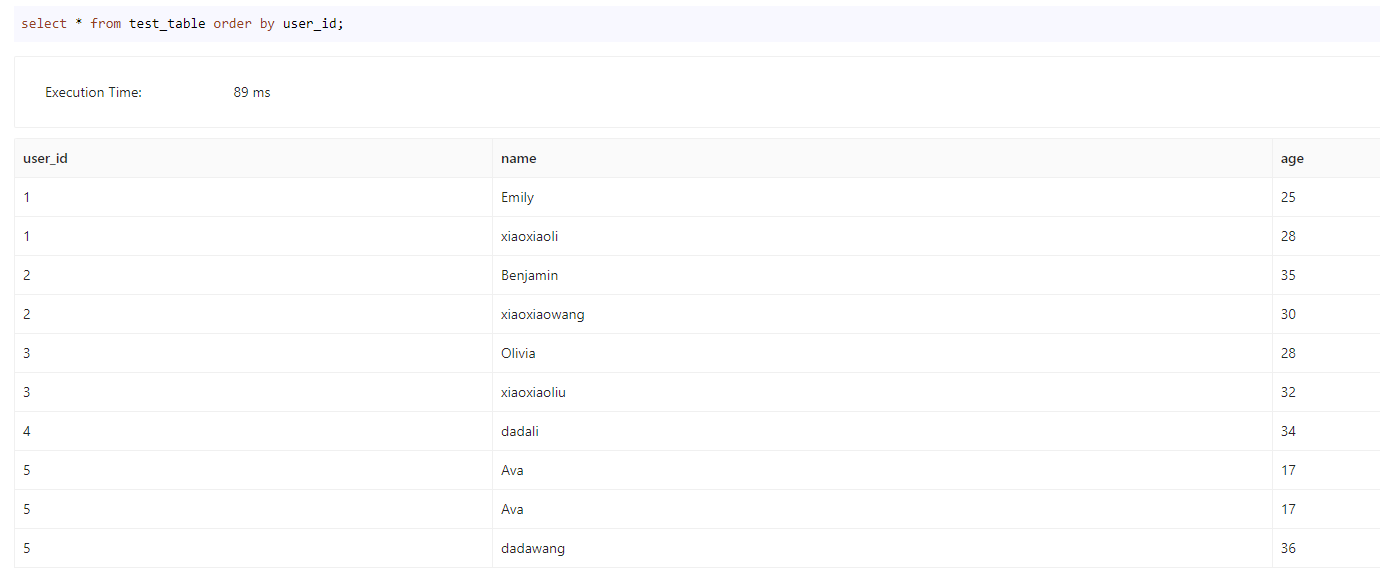
Insert Into
INSERT INTO 支持将 Doris 查询的结果导入到另一个表中。INSERT INTO 是一个同步导入方式,执行导入后返回导入结果。可以通过请求的返回判断导入是否成功。INSERT INTO 可以保证导入任务的原子性,要么全部导入成功,要么全部导入失败。
主要的 Insert Into 命令包含以下两种:
-
INSERT INTO tbl SELECT …
-
INSERT INTO tbl (col1, col2, …) VALUES (1, 2, …), (1,3, …)
使用场景
-
用户希望仅导入几条假数据,验证一下 Doris 系统的功能。此时适合使用 INSERT INTO VALUES 的语法,语法和 MySQL 一样。不建议在生产环境中使用 INSERT INTO VALUES。
-
用户希望将已经在 Doris 表中的数据进行 ETL 转换并导入到一个新的 Doris 表中,此时适合使用 INSERT INTO SELECT 语法。
-
与 Multi-Catalog 外部表机制进行配合,如通过 Multi-Catalog 映射 MySQL 或者 Hive 系统中的表,然后通过 INSERT INTO SELECT 语法将外部表中的数据导入到 Doris 表中存储。
-
通过 Table Value Function(TVF)功能,可以直接将对象存储或 HDFS 上的文件作为 Table 进行查询,并且支持自动的列类型推断。然后,通过 INSERT INTO SELECT 语法将外部表中的数据导入到 Doris 表中存储。
使用案例
- 创建源表
CREATE TABLE test_table(
user_id BIGINT NOT NULL COMMENT "用户 ID",
name VARCHAR(20) COMMENT "用户姓名",
age INT COMMENT "用户年龄"
)
DUPLICATE KEY(user_id)
DISTRIBUTED BY HASH(user_id) BUCKETS 10;
- 使用 INSERT INTO VALUES 向源表导入数据
INSERT INTO test_table (user_id, name, age)
VALUES (1, "Emily", 25),
(2, "Benjamin", 35),
(3, "Olivia", 28),
(4, "Alexander", 60),
(5, "Ava", 17);
- 导入结果查看
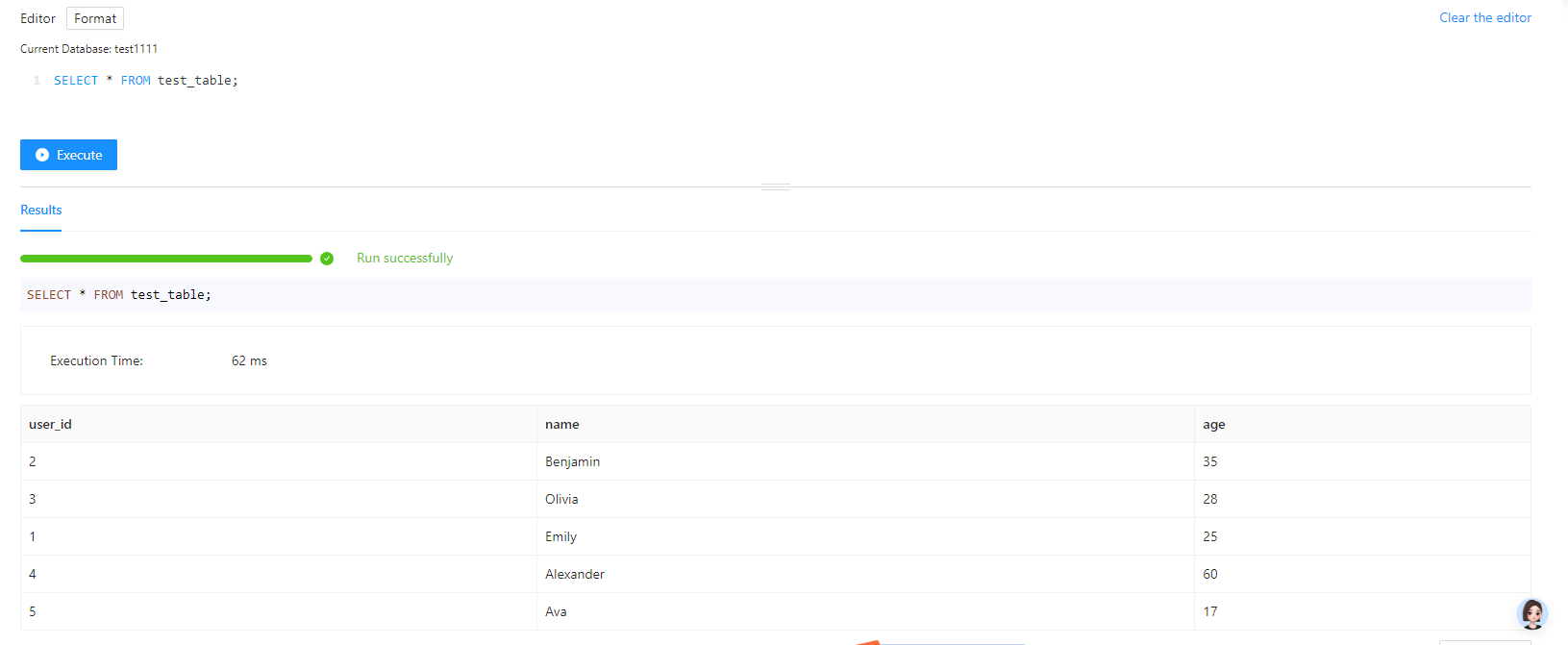
- 在上述操作的基础上,创建一个新表作为目标表(其 schema 与源表相同)
CREATE TABLE test_table2 LIKE test_table;
- 使用 INSERT INTO SELECT 导入到新表
INSERT INTO test_table2
SELECT * FROM test_table WHERE age < 30;
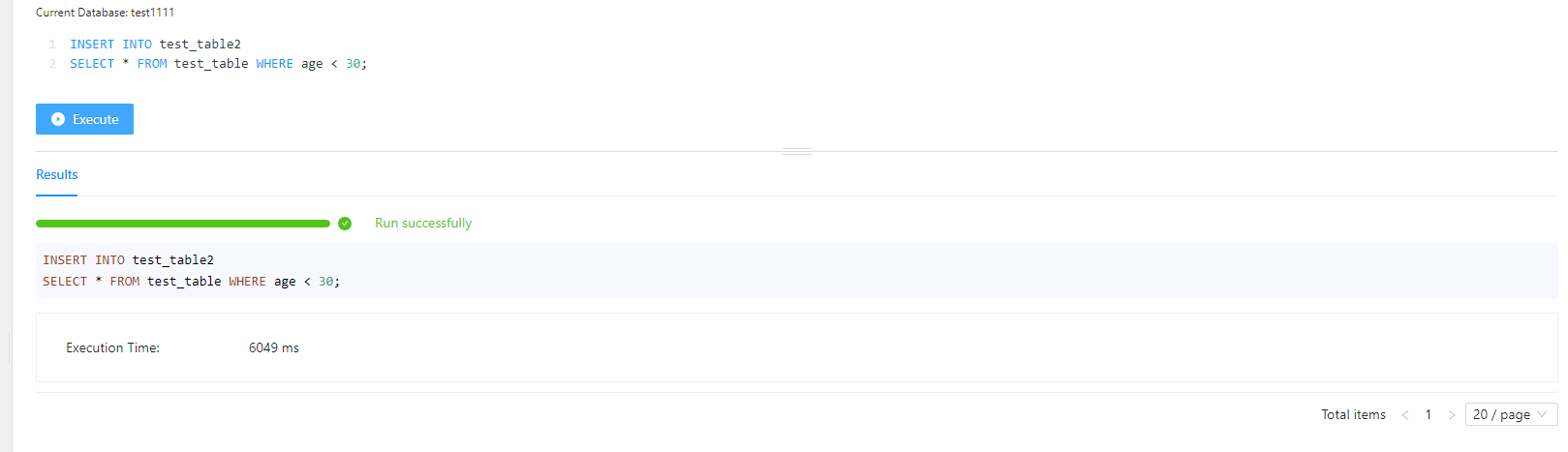
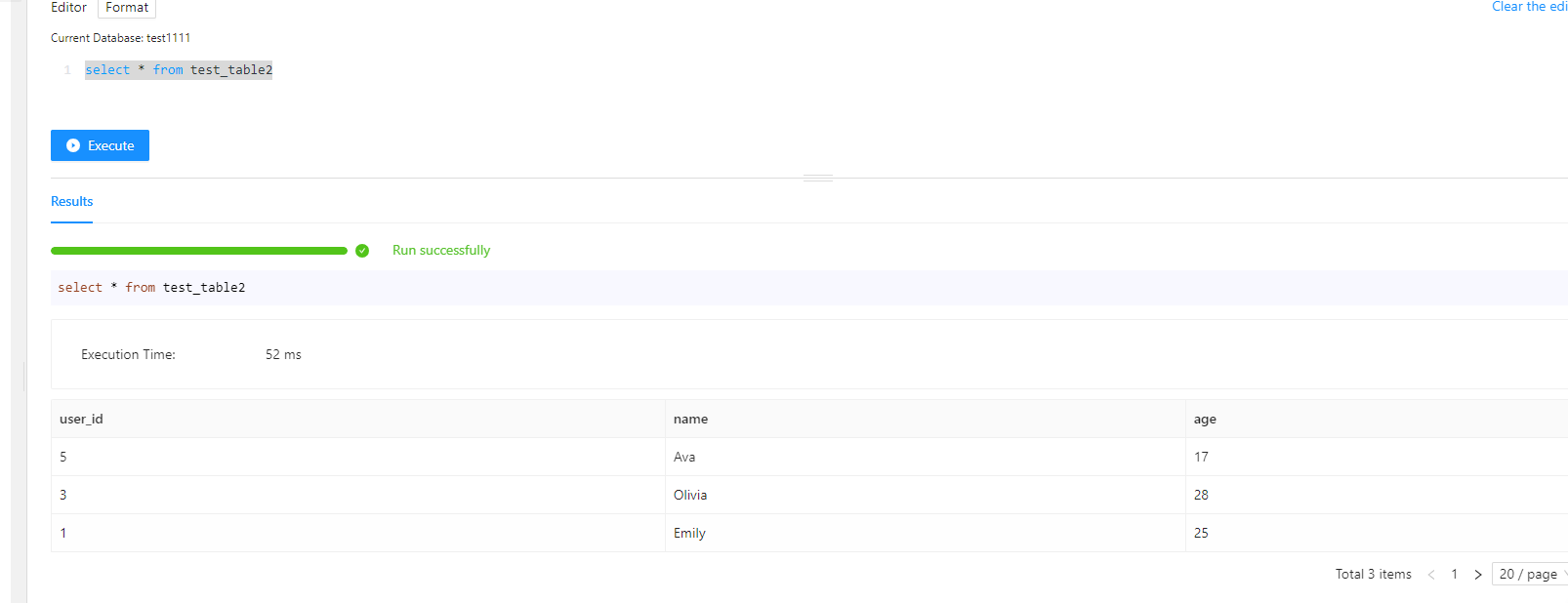
MySQL Load
MySQL Load 与 Stream Load 功能相似,都是导入本地文件到 Doris 集群中。因此 MySQL Load 的实现复用了 Stream Load 的基本导入能力。
- 创建导入数据client_local.csv
1,10
2,20
3,30
4,40
5,50
6,60
- 链接客户端
在执行 LOAD DATA 命令前,需要先链接 MySQL 客户端。
mysql --local-infile -h 192.168.100.136 -P 30903 -u root -D test1111
- 创建测试用表
CREATE TABLE t1 (
pk INT,
v1 INT SUM
) AGGREGATE KEY (pk)
DISTRIBUTED BY hash (pk);
- 运行 LOAD DATA 导入命令
LOAD DATA LOCAL
INFILE 'client_local.csv'
INTO TABLE t1
COLUMNS TERMINATED BY ','
LINES TERMINATED BY '\n';
JSON格式数据导入
目前只有以下导入方式支持 JSON 格式的数据导入:
-
通过S3表函数导入语句:insert into table select * from S3();
-
将本地 JSON 格式的文件通过 STREAM LOAD方式导入。
-
通过 ROUTINE LOAD 订阅并消费 Kafka 中的 JSON 格式消息。
暂不支持其他方式的 JSON 格式数据导入
Stream Load和Routine Load额上面章节已经介绍如何导入JSON格式的数据,不再赘述。
从其他 AP 系统迁移数据
从其他 AP 系统迁移数据到 Doris,可以有多种方式:
-
Hive/Iceberg/Hudi等,可以使用Multi-Catalog来映射为外表,然后使用Insert Into,来将数据导入
-
也可以从原来 AP 系统中到处数据为 CSV 等数据格式,然后再将导出的数据导入到 Doris
-
可以使用 Spark / Flink 系统,利用 AP 系统的 Connector 来读取数据,然后调用 Doris Connector 写入 Doris
除了以上三种方式,SelectDB 提供了免费的可视化的数据迁移工具 X2Doris。
X2Doris 使用
-
产品介绍:https://www.selectdb.com/tools/x2doris
-
立即下载:https://www.selectdb.com/download/tools#x2doris
-
文档地址:https://docs.selectdb.com/docs/ecosystem/x2doris/x2doris-deployment-guide
数据导出
SELECT INTO OUTFILE
支持任意 SQL 结果集的导出。
适用于以下场景:
-
导出数据需要经过复杂计算逻辑的,如过滤、聚合、关联等。
-
适合执行同步任务的场景。
导出到 HDFS
将查询结果导出到文件 hdfs://path/to/ 目录下,指定导出格式为 PARQUET:
SELECT c1, c2, c3 FROM tbl
INTO OUTFILE "hdfs://${host}:${fileSystem_port}/path/to/result_"
FORMAT AS PARQUET
PROPERTIES
(
"fs.defaultFS" = "hdfs://ip:port",
"hadoop.username" = "hadoop"
);
导出到 S3
将查询结果导出到 s3 存储的 s3://path/to/ 目录下,指定导出格式为 ORC,需要提供sk ak等信息。
SELECT * FROM tbl
INTO OUTFILE "s3://path/to/result_"
FORMAT AS ORC
PROPERTIES(
"s3.endpoint" = "https://xxx",
"s3.region" = "ap-beijing",
"s3.access_key"= "your-ak",
"s3.secret_key" = "your-sk"
);
导出到本地
如需导出到本地文件,需在 fe.conf 中添加 enable_outfile_to_local=true并重启 FE。
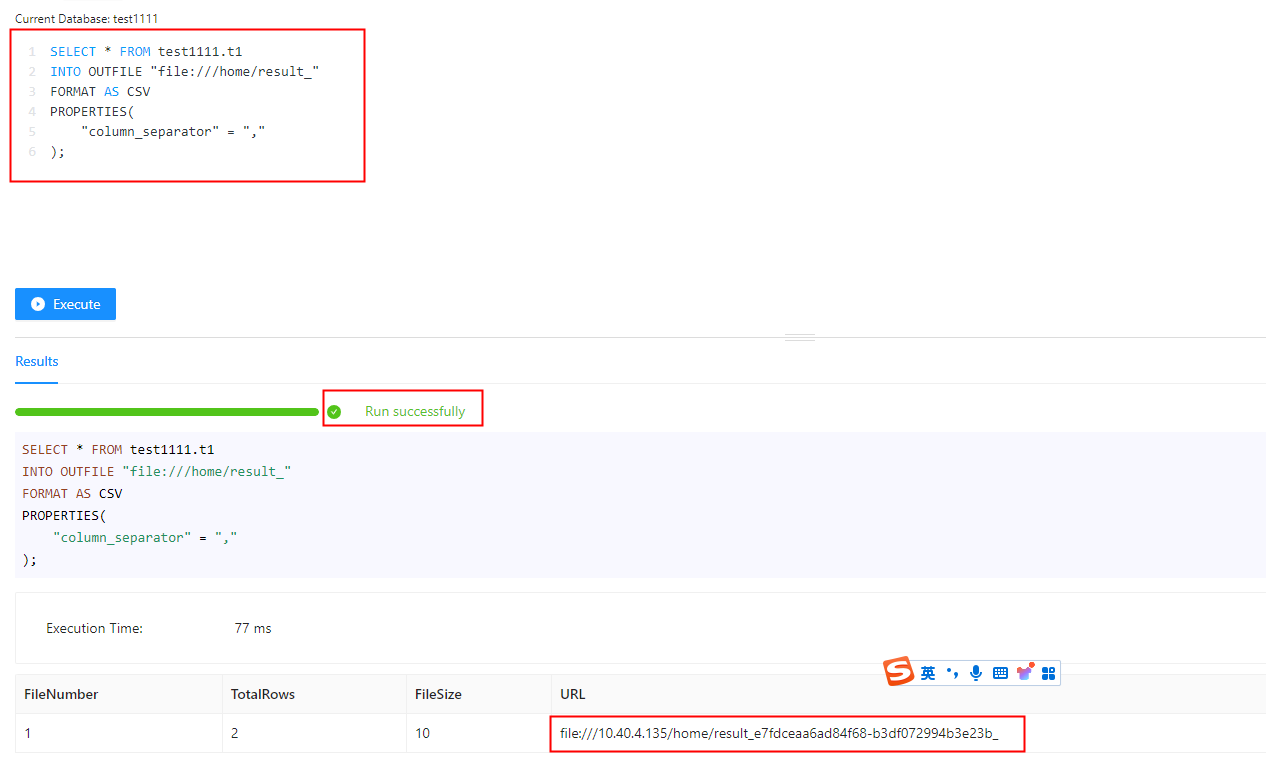
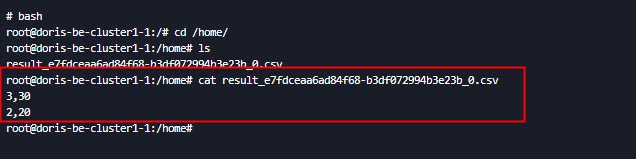
将查询结果导出到 BE 的file:///home/ 目录下,指定导出格式为 CSV,指定列分割符为,
SELECT * FROM test1111.t1
INTO OUTFILE "file:///home/result_"
FORMAT AS CSV
PROPERTIES(
"column_separator" = ","
);
EXPORT
支持表级别的部分或全部数据导出。
适用于以下场景:
-
大数据量的单表导出、仅需简单的过滤条件。
-
需要异步提交任务的场景。
导出到 HDFS
将 db1.tbl1 表的 p1 和 p2 分区中的col1 列和col2 列数据导出到 HDFS 上,设置导出作业的 label 为 mylabel。导出文件格式为 csv(默认格式),列分割符为,,导出作业单个文件大小限制为 512MB。
EXPORT TABLE db1.tbl1
PARTITION (p1,p2)
TO "hdfs://host/path/to/export/"
PROPERTIES
(
"label" = "mylabel",
"column_separator"=",",
"max_file_size" = "512MB",
"columns" = "col1,col2"
)
with HDFS (
"fs.defaultFS"="hdfs://hdfs_host:port",
"hadoop.username" = "hadoop"
);
导出到 S3
将 s3_test 表中的所有数据导出到 s3 上,导出格式为 csv,以不可见字符 “\x07” 作为行分隔符。
EXPORT TABLE s3_test TO "s3://bucket/a/b/c"
PROPERTIES (
"line_delimiter" = "\x07"
) WITH s3 (
"s3.endpoint" = "xxxxx",
"s3.region" = "xxxxx",
"s3.secret_key"="xxxx",
"s3.access_key" = "xxxxx"
)
导出到本地文件系统
export 数据导出到本地文件系统,需要在 fe.conf 中添加enable_outfile_to_local=true并且重启 FE
将 test 表中的所有数据导出到本地存储:
-- parquet 格式
EXPORT TABLE test TO "file:///home/user/tmp/"
PROPERTIES (
"columns" = "k1,k2",
"format" = "parquet"
);
-- orc 格式
EXPORT TABLE test TO "file:///home/user/tmp/"
PROPERTIES (
"columns" = "k1,k2",
"format" = "orc"
);
-- csv_with_names 格式,以‘AA’为列分割符,‘zz’为行分割符
EXPORT TABLE test TO "file:///home/user/tmp/"
PROPERTIES (
"format" = "csv_with_names",
"column_separator"="AA",
"line_delimiter" = "zz"
);
-- csv_with_names_and_types 格式
EXPORT TABLE test TO "file:///home/user/tmp/"
PROPERTIES (
"format" = "csv_with_names_and_types"
);
MySQL DUMP
兼容 MySQL Dump 指令的数据导出。
适用于以下场景:
-
兼容 MySQL 生态,需要同时导出表结构和数据。
-
仅用于开发测试或者数据量很小的情况。
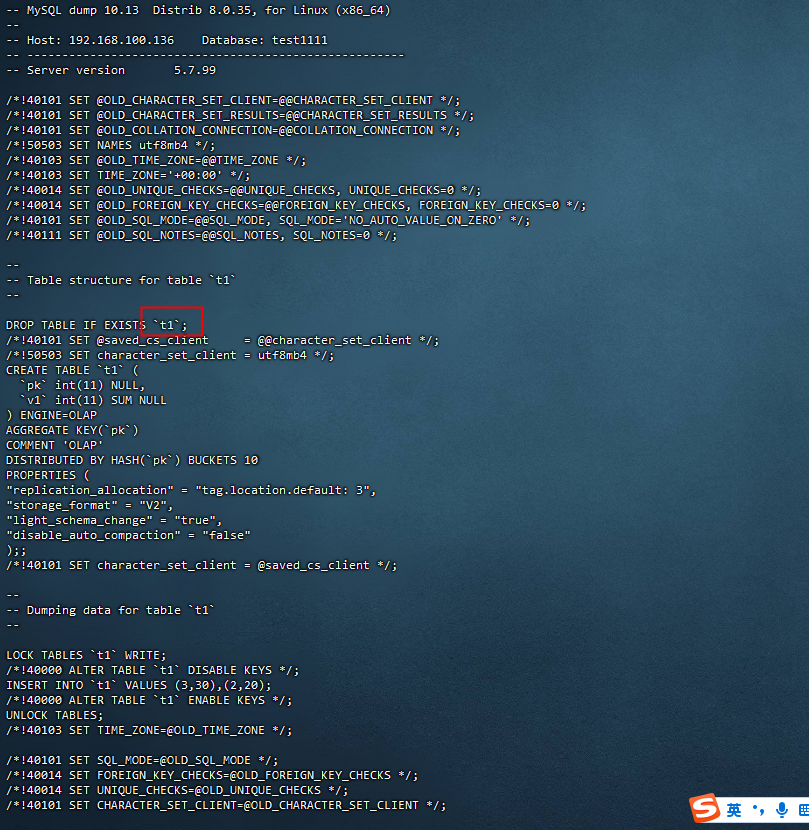
导出 test1111 数据库中的 t1 表
mysqldump -h192.168.100.136 -P30903 -uroot --no-tablespaces --databases test1111 --tables t1

数据更新
数据更新,主要指针对相同 Key 的数据 Value 列的值的更新,这个更新对于主键模型来说,就是替换,对于聚合模型来说,就是如何完成针对 value 列上的聚合。
主键模型的 Update 更新
Update 命令只能在 Unique 数据模型的表中执行
适用场景
-
对满足某些条件的行,修改其取值
-
适合少量数据,不频繁的更新。
创建主键模型的表
CREATE TABLE IF NOT EXISTS test1111.tb_order
(
`order_id` LARGEINT NOT NULL,
`order_amount` INT NOT NULL ,
`order_status` VARCHAR(20)
)
UNIQUE KEY(`order_id`)
DISTRIBUTED BY HASH(`order_id`) BUCKETS 1
PROPERTIES (
"replication_allocation" = "tag.location.default: 1",
"enable_unique_key_merge_on_write" = "true"
);
-- 新增一条数据
insert into tb_order values(1, 100, '待付款');
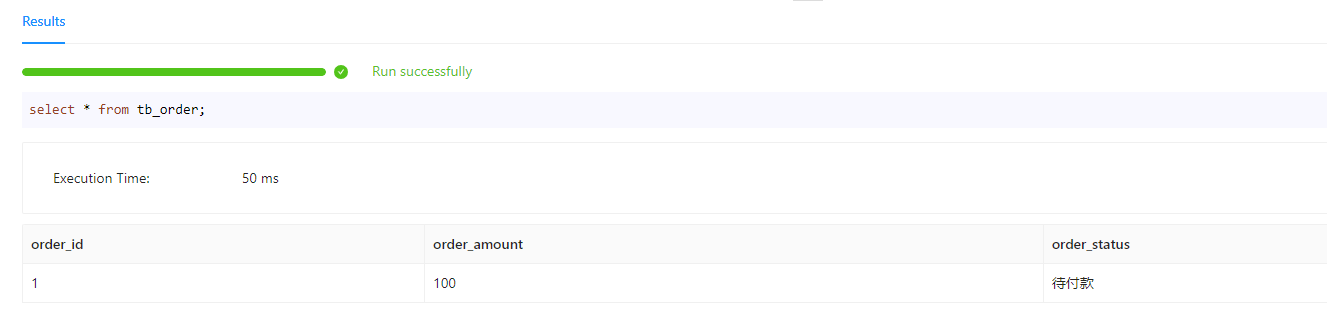
存在一张订单表,其中订单 id 是 Key 列,订单状态,订单金额是 Value 列。数据状态如下:
| 订单 id | 订单金额 | 订单状态 |
|---|---|---|
| 1 | 100 | 待付款 |
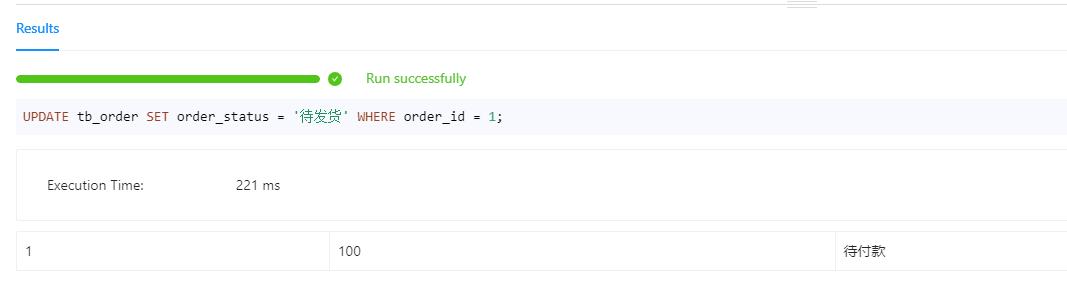
更新订单id为1的订单的订单状态为”待发货“
UPDATE tb_order SET order_status = '待发货' WHERE order_id = 1;
执行结果
主键模型的 导入 更新
所有列更新
使用 Doris 支持的 Stream Load,Broker Load,Routine Load,Insert Into 等导入方式,往主键模型(Unique 模型)中进行数据导入时,如果没有相应主键的数据行,就执行插入新的数据,如果有相应主键的数据行,就进行更新。也就是说,Doris 主键模型的导入是一种“upsert”模式。
部分列更新
部分列更新,主要是指直接更新表中某些字段值,而不是全部的字段值。可以采用 Update 语句来进行更新,这种 Update 语句一般采用先将整行数据读出,然后再更新部分字段值,再写回。这种读写事务非常耗时,并且不适合大批量数据写入。Doris 在主键模型的导入更新,提供了可以直接插入或者更新部分列数据的功能,不需要先读取整行数据,这样更新效率就大幅提升了。
适用场景
-
实时的动态列更新,需要在表中实时的高频更新某些字段值。例如用户标签表中有一些关于用户最新行为信息的字段需要实时的更新,以实现广告/推荐等系统能够据其进行实时的分析和决策。
-
将多张源表拼接成一张大宽表
-
数据修正
示例
依旧以订单表为例,目前订单id为1的订单状态为“待发货”
| 订单 id | 订单金额 | 订单状态 |
|---|---|---|
| 1 | 100 | 待发货 |
修改该订单为“已发货”。
通过StreamLoad 更新
准备导入文件的数据
$touch update_order.csv
$echo 1,已发货 > update_order.csv
$cat update_order.csv
1,已发货

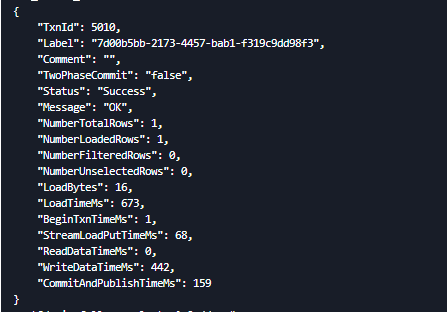
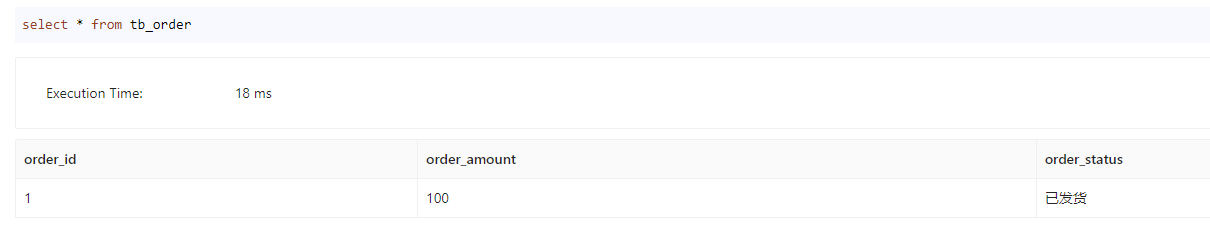
执行命令
curl --location-trusted -u root: -H "partial_columns:true" -H "column_separator:," -H "columns:order_id,order_status" -T /docs/update_order.csv http://192.168.100.136:30803/api/test1111/tb_order/_stream_load
执行结果
INSRT INTO更新
set enable_unique_key_partial_update=true;
INSERT INTO order_tbl (order_id, order_status) values (1,'待发货');
聚合模型的导入更新
所有列更新
使用 Doris 支持的 Stream Load,Broker Load,Routine Load,Insert Into 等导入方式,往聚合模型(Agg 模型)中进行数据导入时,都会将新的值与旧的聚合值,根据列的聚合函数产出新的聚合值,这个值可能是插入时产出,也可能是异步 Compaction 时产出,但是用户查询时,都会得到一样的返回值。
部分列更新
创建用例表
CREATE TABLE tb_order_agg (
order_id int(11) NULL,
order_amount int(11) REPLACE_IF_NOT_NULL NULL,
order_status varchar(100) REPLACE_IF_NOT_NULL NULL
) ENGINE=OLAP
AGGREGATE KEY(order_id)
COMMENT 'OLAP'
DISTRIBUTED BY HASH(order_id) BUCKETS 1
PROPERTIES (
"replication_allocation" = "tag.location.default: 1"
);
-- 新增一条数据
INSERT INTO tb_order_agg values (1,100,'待发货');
Stream Load 更新
curl --location-trusted -u root: -H "column_separator:," -H "columns:order_id,order_status" -T /docs/update_order.csv http://192.168.100.136:30903/api/test1111/tb_order_agg/_stream_load
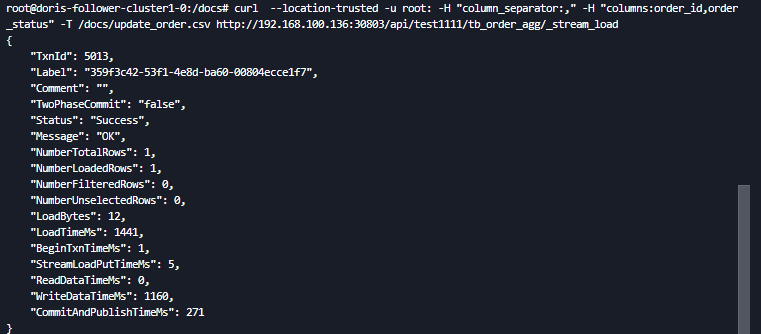

Insert Into 更新
INSERT INTO tb_order_agg (order_id, order_status) values (1,'已完成');

数据删除
Delete 操作
Delete 操作语句通过 MySQL 协议,对指定的 table 或者 partition 中的数据进行按条件删除。Delete 删除操作不同于基于导入的批量删除,它类似 Insert into 语句,是一个同步过程。所有的 Delete 操作在 Doris 中是一个独立的导入作业,一般 Delete 语句需要指定表和分区以及删除的条件来筛选要删除的数据,并将会同时删除 base 表和 rollup 表的数据。
示例
test_table表数据如下:
| user_id | name | age |
|---|---|---|
| 1 | Emily | 25 |
| 4 | Alexander | 60 |
| 2 | Benjamin | 35 |
| 3 | Olivia | 28 |
| 5 | Ava | 17 |
delete from test_table where age > 50
执行后表数据
| user_id | name | age |
|---|---|---|
| 2 | Benjamin | 35 |
| 3 | Olivia | 28 |
| 5 | Ava | 17 |
| 1 | Emily | 25 |
操作方式与MYSQL没有太大的区别,除了可以指定分区。
DELETE FROM table_name [table_alias]
[PARTITION partition_name | PARTITIONS (partition_name [, partition_name])]
WHERE column_name op { value | value_list } [ AND column_name op { value | value_list } ...];
批量删除
为什么不直接用Delete操作删除数据,而还要额外引入批量删除?
Delete 操作的局限性
使用 Delete 语句的方式删除时,每执行一次 Delete 都会生成一个空的 rowset 来记录删除条件,并产生一个新的数据版本。每次读取都要对删除条件进行过滤,如果频繁删除或者删除条件过多时,都会严重影响查询性能。
Insert 数据和 Delete 数据穿插出现
对于类似于从事务数据库中,通过 CDC 进行数据导入的场景,数据中 Insert 和 Delete 一般是穿插出现的,面对这种场景当前 Delete 操作也是无法实现。
批量删除只工作在 Unique 模型(否则会报错)。
原理
通过在 Unique 表上增加一个隐藏列DORIS_DELETE_SIGN来实现。
FE 解析查询时,遇到 * 等扩展时去掉DORIS_DELETE_SIGN,并且默认加上 DORIS_DELETE_SIGN != true 的条件,BE 读取时都会加上一列进行判断,通过条件确定是否删除。
- 导入
导入时在 FE 解析时将隐藏列的值设置成 DELETE ON 表达式的值。
- 读取
读取时在所有存在隐藏列的上增加DORIS_DELETE_SIGN != true 的条件,be 不感知这一过程,正常执行。
- Cumulative Compaction
Cumulative Compaction 时将隐藏列看作正常的列处理,Compaction 逻辑没有变化。
- Base Compaction
Base Compaction 时要将标记为删除的行的删掉,以减少数据占用的空间。
示例
查看是否启用批量删除
show variables like 'show_hidden_columns'

启用批量删除
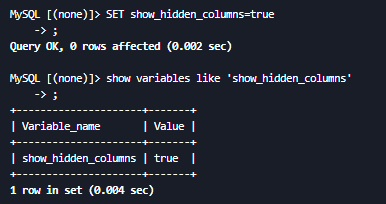
注意:
在Doris WebUI页面操作doris数据库,设置属性时会报错:Unsupported statement type。 需要到fe所在机器或者容器上连接mysq client,然后执行相关设置。
# FE_IP 为 FE 的监听地址, FE_QUERY_PORT 为 FE 的 MYSQL 协议服务的端口,在 fe.conf 中对应 query_port, 默认为 9030.
mysql -h FE_IP -P FE_QUERY_PORT -u USER_NAME
向tb_order表中插入数据
insert into tb_order (order_id,order_amount,order_status) values (2, 200, '待发货'),(3,300, '代付款'),(4,400,'待付款'),(5,5,'已完成');
表tb_order有如下数据
| order_id | order_amount | order_status |
|---|---|---|
| 1 | 100 | 已发货 |
| 2 | 200 | 待发货 |
| 3 | 300 | 代付款 |
| 4 | 400 | 待付款 |
| 5 | 5 | 已完成 |
通过导入方式删除该表数据(将与导入数据 Key 相同的数据全部删除, 即:删除order_id=3的数据)

curl --location-trusted -u root: -H "column_separator:," -H "columns:order_id,order_amount,order_status" -H "merge_type: DELETE" -T /docs/batch_del_test.csv http://192.168.100.136:30803/api/test1111/tb_order/_stream_load
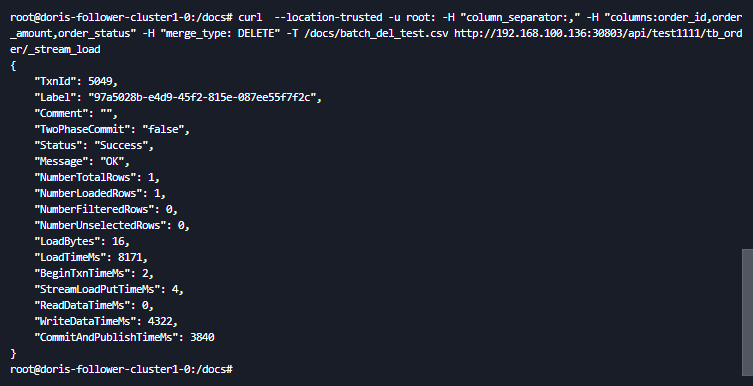
执行删除后表中数据
| order_id | order_amount | order_status |
|---|---|---|
| 1 | 100 | 已发货 |
| 2 | 200 | 待发货 |
| 4 | 400 | 待付款 |
| 5 | 5 | 已完成 |

连接上mysql client,设置“启用批量删除”,查看tb_order的表结构和数据
root@doris-follower-cluster1-0:/docs# mysql -h 192.168.100.136 -P 30903 -u rootWelcome to the MariaDB monitor. Commands end with ; or \g.Your MySQL connection id is 86
Server version: 5.7.99 Doris version doris-2.0.0-alpha1-Unknown
Copyright (c) 2000, 2018, Oracle, MariaDB Corporation Ab and others.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
MySQL [(none)]> show variables like 'show_hidden_columns';
+---------------------+-------+
| Variable_name | Value |
+---------------------+-------+
| show_hidden_columns | false |
+---------------------+-------+
1 row in set (0.002 sec)
MySQL [(none)]> set show_hidden_columns=true;
Query OK, 0 rows affected (0.002 sec)
MySQL [(none)]> desc test1111.tb_order;
+-----------------------+-------------+------+-------+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-----------------------+-------------+------+-------+---------+-------+
| order_id | LARGEINT | No | true | NULL | |
| order_amount | INT | No | false | NULL | NONE |
| order_status | VARCHAR(20) | Yes | false | NULL | NONE |
| __DORIS_DELETE_SIGN__ | TINYINT | No | false | 0 | NONE |
| __DORIS_VERSION_COL__ | BIGINT | No | false | 0 | NONE |
+-----------------------+-------------+------+-------+---------+-------+
5 rows in set (0.002 sec)
MySQL [(none)]> select * from test1111.tb_order;
+----------+--------------+--------------+-----------------------+-----------------------+
| order_id | order_amount | order_status | __DORIS_DELETE_SIGN__ | __DORIS_VERSION_COL__ |
+----------+--------------+--------------+-----------------------+-----------------------+
| 1 | 100 | 已发货 | 0 | 4 |
| 2 | 200 | 待发货 | 0 | 5 |
| 3 | 300 | 代付款 | 1 | 6 |
| 4 | 400 | 待付款 | 0 | 5 |
| 5 | 5 | 已完成 | 0 | 5 |
+----------+--------------+--------------+-----------------------+-----------------------+
5 rows in set (0.018 sec)
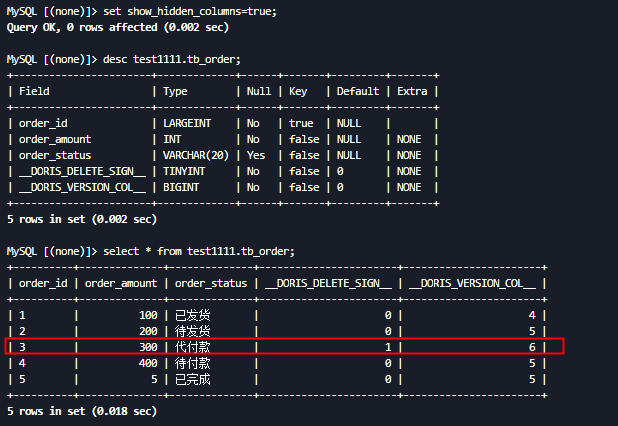
数据查询
数据查询
Select 查询
Select 语法
SELECT
[hint_statement, ...]
[ALL | DISTINCT | DISTINCTROW | ALL EXCEPT ( col_name1 [, col_name2, col_name3, ...] )]
select_expr [, select_expr ...]
[FROM table_references
[PARTITION partition_list]
[TABLET tabletid_list]
[TABLESAMPLE sample_value [ROWS | PERCENT]
[REPEATABLE pos_seek]]
[WHERE where_condition]
[GROUP BY [GROUPING SETS | ROLLUP | CUBE] {col_name | expr | position}]
[HAVING where_condition]
[ORDER BY {col_name | expr | position}
[ASC | DESC], ...]
[LIMIT {[offset,] row_count | row_count OFFSET offset}]
[INTO OUTFILE 'file_name']
使用举例
大多数查询与mysql一致,下面主要列出一些特别的
--查询除了学生年龄的所有信息
select * except(age) from student;
公用表表达式(CTE)
公用表表达式(Common Table Expression)定义一个临时结果集,您可以在 SQL 语句的范围内多次引用。CTE 主要用于 SELECT 语句中。
要指定公用表表达式,请使用 WITH 具有一个或多个逗号分隔子句的子句。每个子条款都提供一个子查询,用于生成结果集,并将名称与子查询相关联。下面的示例定义名为的 CTE cte1 和 cte2 中 WITH 子句,并且是指在它们的顶层 SELECT 下面的 WITH 子句:
WITH
cte1 AS(SELECT a,b FROM table1),
cte2 AS(SELECT c,d FROM table2)
SELECT b,d FROM cte1 JOIN cte2
WHERE cte1.a = cte2.c;
项目整合使用
项目代码地址:https://gitlab.bicitech.cn/bzlj/doris-demo/-/tree/master
doris k8s部署:http://192.168.100.136:30880/projects/doris/statefulsets
doris WEB-UI: http://192.168.100.137:30803/Playground 账号:root 密码空
与ORM框架整合
多数据源配置
spring:
application:
name: demo-doris
datasource:
doris:
name: doris
#jdbc-url: jdbc:mysql://<fe_ip>:<query-port>/dbName
jdbc-url: jdbc:mysql://192.168.100.136:30903/test1111?allowMultiQueries=true&useSSL=false&useUnicode=true&characterEncoding=utf-8
username: root
password:
driver-class-name: com.mysql.cj.jdbc.Driver
mysql:
name: mysql
jdbc-url: jdbc:mysql://localhost:3306/testing?allowMultiQueries=true&useSSL=false&useUnicode=true&characterEncoding=utf-8
username: root
password: 123456
driver-class-name: com.mysql.cj.jdbc.Driver
package com.example.demo.config;
import com.baomidou.mybatisplus.core.MybatisConfiguration;
import com.baomidou.mybatisplus.extension.spring.MybatisSqlSessionFactoryBean;
import org.apache.ibatis.logging.stdout.StdOutImpl;
import org.apache.ibatis.session.SqlSessionFactory;
import org.mybatis.spring.SqlSessionTemplate;
import org.mybatis.spring.annotation.MapperScan;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.boot.jdbc.DataSourceBuilder;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.core.io.support.PathMatchingResourcePatternResolver;
import javax.sql.DataSource;
@Configuration
@MapperScan(basePackages = "com.example.demo.dao.doris" , sqlSessionFactoryRef = "dorisSqlSessionFactory")
public class DorisConfig {
private static final String MAPPER_LOCATION = "classpath:mapper/doris/*.xml";
private static final String TYPE_ALIASES_PACKAGE = "com.example.demo.bean.*";
@Bean("dorisDataSource")
@ConfigurationProperties(prefix = "spring.datasource.doris")
public DataSource getDb1DataSource(){
return DataSourceBuilder.create().build();
}
@Bean("dorisSqlSessionFactory")
public SqlSessionFactory dorisSqlSessionFactory(@Qualifier("dorisDataSource") DataSource dataSource) throws Exception {
MybatisSqlSessionFactoryBean bean = new MybatisSqlSessionFactoryBean ();
bean.setDataSource(dataSource);
bean.setMapperLocations(new PathMatchingResourcePatternResolver().getResources(MAPPER_LOCATION));
bean.setTypeAliasesPackage(TYPE_ALIASES_PACKAGE);
MybatisConfiguration configuration = new MybatisConfiguration();
configuration.setMapUnderscoreToCamelCase(true);
configuration.setCacheEnabled(false);
configuration.setCallSettersOnNulls(true);
configuration.setLogImpl(StdOutImpl.class);
bean.setConfiguration(configuration);
return bean.getObject();
}
//Doris是否需要配置事务
/*@Bean(name = "dorisTransactionManager")
public DataSourceTransactionManager dorisTransactionManager(@Qualifier("dorisDataSource") DataSource dataSource) {
return new DataSourceTransactionManager(dataSource);
}*/
@Bean("dorisSqlSessionTemplate")
public SqlSessionTemplate dorisSqlSessionTemplate(@Qualifier("dorisSqlSessionFactory") SqlSessionFactory sqlSessionFactory){
return new SqlSessionTemplate(sqlSessionFactory);
}
}
package com.example.demo.config;
import com.baomidou.mybatisplus.core.MybatisConfiguration;
import com.baomidou.mybatisplus.extension.spring.MybatisSqlSessionFactoryBean;
import org.apache.ibatis.logging.stdout.StdOutImpl;
import org.apache.ibatis.session.SqlSessionFactory;
import org.mybatis.spring.SqlSessionFactoryBean;
import org.mybatis.spring.SqlSessionTemplate;
import org.mybatis.spring.annotation.MapperScan;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.boot.jdbc.DataSourceBuilder;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.annotation.Primary;
import org.springframework.core.io.support.PathMatchingResourcePatternResolver;
import org.springframework.jdbc.datasource.DataSourceTransactionManager;
import javax.sql.DataSource;
@Configuration
@MapperScan(basePackages = "com.example.demo.dao.mysql", sqlSessionFactoryRef = "mysqlSqlSessionFactory")
public class MysqlConfig {
//这里是mapper.xml路径, 根据自己的项目调整
private static final String MAPPER_LOCATION = "classpath:mapper/mysql/*.xml";
//这里是数据库表对应的entity实体类所在包路径, 根据自己的项目调整
private static final String TYPE_ALIASES_PACKAGE = "com.example.demo.bean.*";
@Primary //这个注解的意思是默认使用当前数据源
@Bean(name="mysqlDataSource")
@ConfigurationProperties(prefix = "spring.datasource.mysql")
public DataSource mysqlDataSource() {
return DataSourceBuilder.create().build();
}
@Primary
@Bean("mysqlSqlSessionFactory")
public SqlSessionFactory mysqlSqlSessionFactory(@Qualifier("mysqlDataSource") DataSource dataSource) throws Exception {
MybatisSqlSessionFactoryBean bean = new MybatisSqlSessionFactoryBean ();
bean.setDataSource(dataSource);
bean.setMapperLocations(new PathMatchingResourcePatternResolver().getResources(MAPPER_LOCATION));
bean.setTypeAliasesPackage(TYPE_ALIASES_PACKAGE);
MybatisConfiguration configuration = new MybatisConfiguration();
configuration.setMapUnderscoreToCamelCase(true);
configuration.setCacheEnabled(false);
configuration.setCallSettersOnNulls(true);
configuration.setLogImpl(StdOutImpl.class);
bean.setConfiguration(configuration);
return bean.getObject();
}
/**
* 配置事务管理
*/
@Bean(name = "mysqlTransactionManager")
@Primary
public DataSourceTransactionManager mysqlTransactionManager(@Qualifier("mysqlDataSource") DataSource dataSource) {
return new DataSourceTransactionManager(dataSource);
}
@Primary
@Bean("mysqlSqlSessionTemplate")
public SqlSessionTemplate mysqlSqlSessionTemplate(@Qualifier("mysqlSqlSessionFactory") SqlSessionFactory sqlSessionFactory){
return new SqlSessionTemplate(sqlSessionFactory);
}
}
CURD使用方式与mysql没有区别。
调用doris提供的API
关于doris官方提到的数据操作问题:使用 Stream Load 访问 FE 的公网地址导入数据,被重定向到内网 IP?
当 stream load 的连接目标为 FE 的 http 端口时,FE 仅会随机选择一台 BE 节点做 http 307 redirect 操作,因此用户的请求实际是发送给 FE 指派的某一个 BE 的。而 redirect 返回的是 BE 的 ip,也即内网 IP。所以如果你是通过 FE 的公网 IP 发送的请求,很有可能因为 redirect 到内网地址而无法连接。
通常的做法,一种是确保自己能够访问内网 IP 地址,或者是给所有 BE 上层架设一个负载均衡,然后直接将 stream load 请求发送到负载均衡器上,由负载均衡将请求透传到 BE 节点。
目前采用的是第二种,即在be上层架设一个负载均衡。访问直接访问be上层的负载均衡(192.168.100.136:32372),不再直接访问fe。
CSV文件数据
1,10
2,20
3,30
4,40
5,50
6,60
JSON数据
[
{"userid":1,"username":"Emily","userage":25},
{"userid":2,"username":"Benjamin","userage":35},
{"userid":3,"username":"Olivia","userage":28},
{"userid":4,"username":"Alexander","userage":60},
{"userid":5,"username":"Ava","userage":17},
{"userid":6,"username":"William","userage":69},
{"userid":7,"username":"Sophia","userage":32},
{"userid":8,"username":"James","userage":64},
{"userid":9,"username":"Emma","userage":37},
{"userid":10,"username":"Liam","userage":64}
]
STREAM LOAD导入CSV文件
@Override
public void load(MultipartFile multipartFile, String dbName, String tableName) throws IOException {
if (multipartFile == null || multipartFile.isEmpty()) {
return;
}
String loadUrl = buildLoadUrl(dorisBeProperties.getHost(), dorisBeProperties.getPort(), dbName, tableName);
try (CloseableHttpClient client = HTTP_CLIENT_BUILDER.build()) {
HttpPut put = new HttpPut(loadUrl);
put.removeHeaders(HttpHeaders.CONTENT_LENGTH);
put.removeHeaders(HttpHeaders.TRANSFER_ENCODING);
put.setHeader(HttpHeaders.EXPECT, "100-continue");
put.setHeader(HttpHeaders.AUTHORIZATION, basicAuthHeader(dorisFeProperties.getUser(), dorisFeProperties.getSecret()));
// You can set stream load related properties in the Header, here we set label and column_separator.
put.setHeader("label", UUID.randomUUID().toString());
put.setHeader("column_separator", ",");
// Set up the import file. Here you can also use StringEntity to transfer arbitrary data.
// File uploadFile = new File("e:/doris/client_local.csv");
// FileEntity entity = new FileEntity(uploadFile);
// put.setEntity(entity);
// 传输文件的几种方式
// 1、StringEntity
StringEntity stringEntity = new StringEntity(new String(multipartFile.getBytes()), ContentType.MULTIPART_FORM_DATA);
put.setEntity(stringEntity);
// 2、InputStreamEntity
InputStreamEntity isEntity = new InputStreamEntity(multipartFile.getInputStream());
put.setEntity(isEntity);
try (CloseableHttpResponse response = client.execute(put)) {
String loadResult = "";
if (response.getEntity() != null) {
loadResult = EntityUtils.toString(response.getEntity());
}
final int statusCode = response.getStatusLine().getStatusCode();
if (statusCode != 200) {
log.error(String.format("Stream load failed. status: %s load result: %s", statusCode, loadResult));
// throw new IOException(String.format("Stream load failed. status: %s load result: %s", statusCode, loadResult));
}
log.info("Get load result: " + loadResult);
}
}
}
STREAM LOAD导入JSON数据
/**
* JSON格式的数据导入
* @param jsonData
* @throws Exception
*/
@Override
public void load(String jsonData, String dbName, String tableName) throws Exception {
try (CloseableHttpClient client = HTTP_CLIENT_BUILDER.build()) {
String loadUrl = buildLoadUrl(dorisBeProperties.getHost(), dorisBeProperties.getPort(), dbName, tableName);
HttpPut put = new HttpPut(loadUrl);
put.removeHeaders(HttpHeaders.CONTENT_LENGTH);
put.removeHeaders(HttpHeaders.TRANSFER_ENCODING);
put.setHeader(HttpHeaders.EXPECT, "100-continue");
put.setHeader(HttpHeaders.AUTHORIZATION, basicAuthHeader(dorisFeProperties.getUser(), dorisFeProperties.getSecret()));
// You can set stream load related properties in the Header, here we set label and column_separator.
put.setHeader("label", UUID.randomUUID().toString());
// put.setHeader("column_separator", ",");
put.setHeader("format", "json");
put.setHeader("jsonpaths", "[\"$.userid\", \"$.username\", \"$.userage\"]");
put.setHeader("columns", "user_id,name,age");
// 如果JSON数据是数组,则需要添加strip_outer_array=TRUE
put.setHeader("strip_outer_array", "true");
// Set up the import file. Here you can also use StringEntity to transfer arbitrary data.
StringEntity entity = new StringEntity(jsonData,"UTF-8");
put.setEntity(entity);
try (CloseableHttpResponse response = client.execute(put)) {
String loadResult = "";
if (response.getEntity() != null) {
loadResult = EntityUtils.toString(response.getEntity());
}
final int statusCode = response.getStatusLine().getStatusCode();
if (statusCode != 200) {
throw new IOException(String.format("Stream load failed. status: %s load result: %s", statusCode, loadResult));
}
System.out.println("Get load result: " + loadResult);
}
}
}