ER模型之三范式:
其实范式有很多,这一系列范式就是指在设计关系型数据库时,需要遵从的不同的规范。关系型数据库的范式一共有六种,分别是第一范式(1NF)、第二范式(2NF)、第三范式(3NF)、巴斯-科德范式(BCNF)、第四范式(4NF)和第五范式(5NF)。遵循的范式级别越高,数据冗余性就越低。
关于范式的注意:
每个范式,都是用来规定某种结构或数据要求——后一范式都是在前一范式已经满足的情况用来“加强要求”!
我们在实践中,基本满足三范式,就可以满足我们的绝大部分需求
第一范式:
(1FN) 原子性(储存的数据不可具备可再发性)
原子性比较容易理解 一个例子就看明白了
例如, 我们有一张学生表,表中有 学生,课程,学分等字段

假如写成上面的样子,就完全不符合原子性
需要修改为

此时,就符合了第一范式
第二范式:
(2FN)唯一性(不能存在部分函数依赖)
第二范式中 需要实现每一行数据具有唯一可区分的特性,并不能有部分依赖关系
通常,给一个表加主键(也是推荐做法),就可以做到“唯一可区分”
一个例子:

上面这张表,虽然符合了第一范式的特点,但是不符合“不能存在部分函数依赖” ( 学分与课程存在依赖关系,成绩又与学生存在依赖关系 ),所以并不符合第二范式的特点
可以将以上学生表修改为三张表:
1) 学生信息表:图表中只有学生的个人信息,不包含其他的信息

2) 课程信息表: 只包含与课程有关的信息

3) 成绩信息表: 学分与课程存在依赖,学生又和成绩存在关系,则可以通过联合主键

第三范式:
(3FN)独立性(消除依赖传递)
假设有 A B C D四个字段
其中 B 依赖与 A 、 C 又依赖于 B (B--->A C---->B)这就是所谓的依赖传递关系
第三范式中要消除此关系:
还是一个例子:

上面这张表乍一看,既符合了第一范式,又符合了第二范式的特点,但是并不符合第三范式
因为表中的 “院系电话” 是依赖于 “院系的” 、而 “院系” 又是依赖于学生的 传递依赖出现,范式不符合
正确表设计:
1) 学生信息表:

2) 院系信息表:

这样建表的好处是:
即使院系表中的信息需要修改,也并不需要更改所属院系学生的信息了
总结:
简要说明数据库的三范式
1NF --> 字段必须是原子的,不能拆分的,比如5台电脑
2NF --> 不能存在部分依赖的情况,比如学生所在的系跟分数没关系,系单独摘出去
3NF --> 不能出现传递依赖,学号--> 系名 --> 系主任
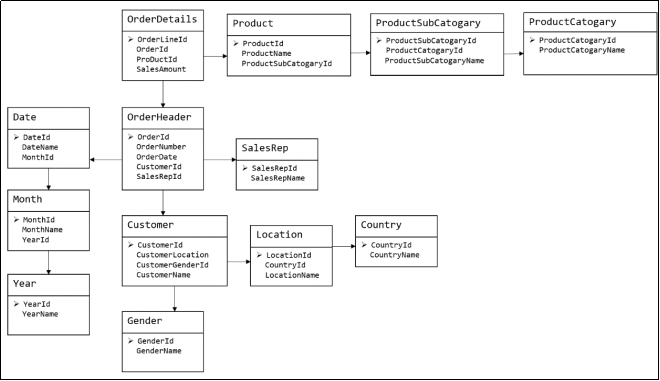
这种建模方法的出发点是整合数据,其目的是将整个企业的数据进行组合和合并,并进行规范处理,减少数据冗余性,保证数据的一致性。这种模型并不适合直接用于分析统计。