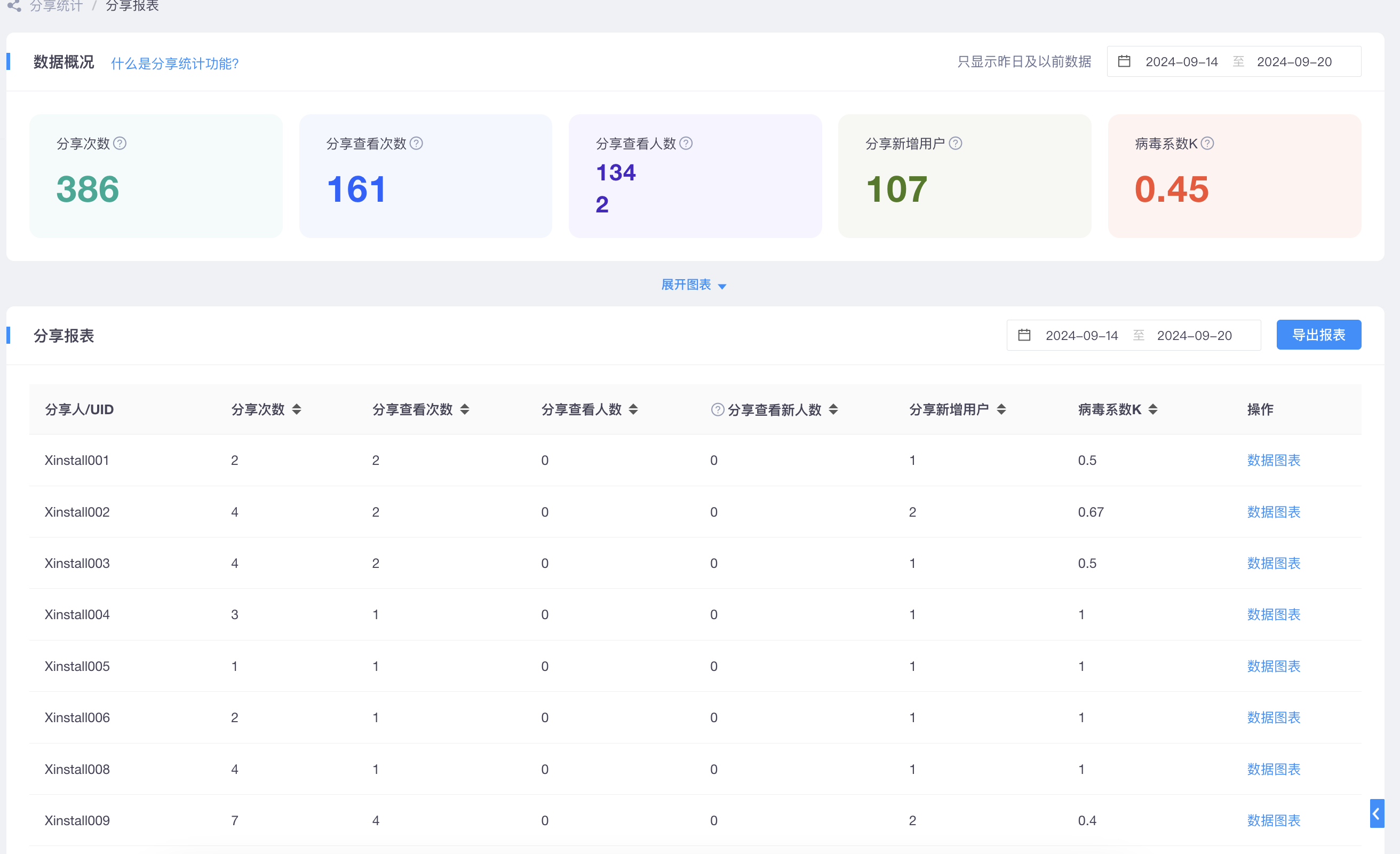
🛸0. 前言
内存管理是个很复杂的东西,一般的程序员在写应用层代码的时候根本就不会关注内存的使用,尤其是 GC 语言自带垃圾回收机制,很多同学都使用过 C 语言中的 malloc,但很少有人能知道 malloc 其实是个很复杂的实现,源代码 6000+行,并且不好理解,本次剖析的ptmalloc 是在 2001 年出来的,但互联网上相关的文章也很少,本次会较为详细的剖析ptmalloc 的实现,大家可以提前去看一下张彦飞老师的文章聊聊C语言中的malloc申请内存的内部原理,最好还看过侯捷老师内存管理视频下 STL 二级分配器和VC6中malloc的实现,对理解本文的阐述会很有帮助。
🚅1. 一些基本约定
本文剖析的源代码来源于 glibc 源码,下载地址是 http://ftp.gnu.org/gnu/glibc/ 。使用的源码版本是 2.12.1,与飞哥文章中的一致。
考虑到源代码很复杂,不可能面面俱到,也没必要面面俱到,所以在以下方面会进行简化:会忽略一些不重要的宏定义开关(默认为关);默认不在debug模式下(其实调试模式下就是分配的chunk多了一些内容);默认系统版本为 64 位,指针为 8 字节,size_t 和 INTERNAL_SIZE_T 都为 8 字节;
🚅2. 核心结构体
看源代码还是老规矩,先从核心的结构体看起,其实 ptmalloc 下的核心结构体就两个,如下所示:

有多个分配区,其中 fastbinsY、top、last_remainder、bins[] 都指向 malloc_chunk 结构图,也就是基本的分配块(这里先大致有个印象就行,后面会详细说)。
🚈2.1 malloc_chunk(内存块)
源代码中的定义如下:
struct malloc_chunk
{
INTERNAL_SIZE_T prev_size; /* Size of previous chunk (if free). 表示前一个内存块的大小(仅在前一个内存块是空闲块时有效)*/
INTERNAL_SIZE_T size; /* Size in bytes, including overhead. 当前内存块的大小,单位为字节,包含了块的元数据(overhead)*/
struct malloc_chunk *fd; /* double links -- used only if free. 指向双向链表中下一个空闲块的指针*/
struct malloc_chunk *bk; // 指向双向链表中上一个空闲块的指针
/* Only used for large blocks: pointer to next larger size. */
struct malloc_chunk *fd_nextsize; /* double links -- used only if free. 指向下一个更大尺寸类别的空闲块的指针*/
struct malloc_chunk *bk_nextsize; // 指向上一个更大尺寸类别的空闲块的指针
};
画出结构示意图:

相信这张图片大家并不陌生,多篇文章中都有提到,我们来仔细剖析一下
🚝2.1.1 prev_size
首先第一个字段为 prev_size,记录的是前一块的大小,好像莫名其妙,首先他是在这一块还没有分配出去的时候(if free)才有用的字段,我们都知道会把空闲的内存块以双向链表的形式串起来,所以有个这个字段,就可以快速定位到前一块的开始位置(前端)
🚝2.1.2 size(A | M | P)
size字段,记录当前内存块的大小,注意包含头部的大小,这个字段显然是有意义的,然后还有A/M/P 这三个标志位,这三个是什么呢?我在 malloc_chunk 定义里面没有看到啊?我们在源代码中找一找这三个
/* size field is or'ed with PREV_INUSE when previous adjacent chunk in use */
#define PREV_INUSE 0x1
/* check for mmap()'ed chunk */
#define IS_MMAPPED 0x2
/* size field is or'ed with NON_MAIN_ARENA if the chunk was obtained
from a non-main arena. This is only set immediately before handing
the chunk to the user, if necessary. */
#define NON_MAIN_ARENA 0x4这下就明白了,P 字段表示前一块是否被占用,M 字段表示当前内存块是否为 MMAP 分配的,A字段表示是否是主分配区;他们的值分别为1(0001)/ 2(0010)/ 4(0100),他们是属于 size的一部分,如果你没有相关基础,或许会问是怎么样把这些标志嵌入到 size 中的?其实 ptmalloc分配的内存块都是 16 字节对齐的,最小分配的内存块为 32 字节,16 字节对齐也就意味着 size 的低4 位全为 0,所以可以用来填充标志位,当然也要有函数来设置和还原这些标志位。这个技巧几乎在所有的内存池和内存管理中都用到的,是通用的手法。
/* extract inuse bit of previous chunk */
#define prev_inuse(p) ((p)->size & PREV_INUSE)
/* check for mmap()'ed chunk */
#define chunk_is_mmapped(p) ((p)->size & IS_MMAPPED)
/* check for chunk from non-main arena */
#define chunk_non_main_arena(p) ((p)->size & NON_MAIN_ARENA)
/* Bits to mask off when extracting size */
#define SIZE_BITS (PREV_INUSE | IS_MMAPPED | NON_MAIN_ARENA)
/* Get size, ignoring use bits */
#define chunksize(p) ((p)->size & ~(SIZE_BITS))🚝2.1.3 *fd 和 *bk字段
这两个字段也是在当前内存块还没有分配出去的时候,双向链表的前向和后向指针,注意他们其实是嵌入到 user data 中的,这个也是内存管理都会涉及到的技巧,就是当分配出去之后,这两个指针是没有的,会被用户数据覆盖掉,当没有分配出去,就来充当指针,类似于 union 联合体。示意图如下:

🚈2.2 malloc_state结构体
源代码如下:
struct malloc_state
{
/* Serialize access. */
mutex_t mutex;
/* Flags (formerly in max_fast). */
int flags;
#if THREAD_STATS
/* Statistics for locking. Only used if THREAD_STATS is defined. */
long stat_lock_direct, stat_lock_loop, stat_lock_wait;
#endif
/* Fastbins */
mfastbinptr fastbinsY[NFASTBINS];
/* Base of the topmost chunk -- not otherwise kept in a bin */
mchunkptr top;
/* The remainder from the most recent split of a small request */
mchunkptr last_remainder;
/* Normal bins packed as described above */
mchunkptr bins[NBINS * 2 - 2];
/* Bitmap of bins */
unsigned int binmap[BINMAPSIZE];
/* Linked list */
struct malloc_state *next;
#ifdef PER_THREAD
/* Linked list for free arenas. */
struct malloc_state *next_free;
#endif
/* Memory allocated from the system in this arena. */
INTERNAL_SIZE_T system_mem;
INTERNAL_SIZE_T max_system_mem;
};我们来重点关注那些指向 malloc_chunk 的字段
🚝2.2.1 fastbins
首先 mfastbinptr 就是指向 malloc_chunk 的指针
typedef struct malloc_chunk *mfastbinptr;我们首先来算一下这个数组的长度 NFASTBINS,利用源代码中的这些内容:
// 定义了快速存储池的数量
#define NFASTBINS (fastbin_index(request2size(MAX_FAST_SIZE)) + 1)
// 支持的最大快速存储池请求大小
#define MAX_FAST_SIZE (80 * SIZE_SZ / 4)
// 将用户请求的字节数 req 转换为内部可用的内存块大小,确保对齐并满足最小大小要求
#define request2size(req) \
(((req) + SIZE_SZ + MALLOC_ALIGN_MASK < MINSIZE) ? MINSIZE : ((req) + SIZE_SZ + MALLOC_ALIGN_MASK) & ~MALLOC_ALIGN_MASK)
#define fastbin_index(sz) \
((((unsigned int)(sz)) >> (SIZE_SZ == 8 ? 4 : 3)) - 2)可以算出 NFASTBINS 的值为 10,也就是说 fastbin 数组的长度为 10。
这里来说说 fastbin 到底是什么,我们首先来看看作者的注释
/*
Fastbins
An array of lists holding recently freed small chunks. Fastbins
are not doubly linked. It is faster to single-link them, and
since chunks are never removed from the middles of these lists,
double linking is not necessary. Also, unlike regular bins, they
are not even processed in FIFO order (they use faster LIFO) since
ordering doesn't much matter in the transient contexts in which
fastbins are normally used.
Chunks in fastbins keep their inuse bit set, so they cannot
be consolidated with other free chunks. malloc_consolidate
releases all chunks in fastbins and consolidates them with
other free chunks.
*/
/*
Fastbins(快速存储池)
一个数组,包含了最近释放的小块。快速存储池不是双向链接的。
单向链接速度更快,而且由于这些块从不会从列表中间移除,
所以不需要双向链接。此外,与常规存储池不同,它们甚至
不以先进先出的顺序处理(它们使用更快的后进先出),因为
在快速存储池通常使用的短暂上下文中,顺序并不重要。
快速存储池中的块保持它们的“使用中”位设置,
因此无法与其他空闲块合并。malloc_consolidate
释放快速存储池中的所有块,并将它们与其他空闲块合并。
*/可以看到,fastbin 是用来处理小块的,并且是最近释放的小块,用单向链表来加快速度,还可以通过合并操作,后面我们可以看到,合并后进入 unsortedbin。关于 fastbin目前大家有个印象就好,只需要知道是个特殊的部分,加快小块内存的分配。
fastbins 相关操作函数:
// 用于访问 ar_ptr(一个管理内存分配的结构体)中的 fastbins 数组的第 idx 个元素。fastbinsY 是一个数组,存储着指向不同大小的快速存储池链表的指针
#define fastbin(ar_ptr, idx) ((ar_ptr)->fastbinsY[idx])
/* offset 2 to use otherwise unindexable first 2 bins */
// 将内存块的大小 sz 转换为对应的快速存储池索引
#define fastbin_index(sz) \
((((unsigned int)(sz)) >> (SIZE_SZ == 8 ? 4 : 3)) - 2)
重点来看看 fastbin_index,就是将传入的 sz 除以 16 并减 2,比如传入 32,得到 0,传入 48,得到 1,最大可传入 176(176 为调整后的大小,用户最大可以输入 160)得到索引为 9。后面我们可以看到,并不都是这样的,其实 fastbin 可以处理的小区块的大小界定是由用户指定的,并不都是32-176 字节交由 fastbin 处理。
🚝2.2.2 top
顶部块和 fastbin一样,也是属于特殊的一块,来看看作者的解释
/*
Top
The top-most available chunk (i.e., the one bordering the end of
available memory) is treated specially. It is never included in
any bin, is used only if no other chunk is available, and is
released back to the system if it is very large (see
M_TRIM_THRESHOLD). Because top initially
points to its own bin with initial zero size, thus forcing
extension on the first malloc request, we avoid having any special
code in malloc to check whether it even exists yet. But we still
need to do so when getting memory from system, so we make
initial_top treat the bin as a legal but unusable chunk during the
interval between initialization and the first call to
sYSMALLOc. (This is somewhat delicate, since it relies on
the 2 preceding words to be zero during this interval as well.)
*/
/*
顶部块
最顶部的可用块(即,紧邻可用内存末端的块)有特殊处理。
它从不包含在任何存储池中,仅在没有其他块可用时使用,并且如果其尺寸非常大(参见 M_TRIM_THRESHOLD),会被释放回系统。
由于顶部块最初指向自身的存储池,并且初始大小为零,这样在第一次调用 malloc 时强制进行扩展,因此我们避免在 malloc 中编写任何特殊代码来检查它是否已经存在。
但是,当从系统获取内存时,我们仍然需要进行检查,因此我们让 initial_top 在初始化和第一次调用 sYSMALLOc 之间的时间段内,将该存储池视为合法但不可用的块。
(这有点复杂,因为它依赖于在此期间前两个字是零。)
*/可以看到顶部快不属于存储池(bins),尺寸非常大,当尺寸大于 128KB 的时候会被系统收回,大家先大致有个印象
🚈2.3 bins
这里很重要,是正常情况下内存分配的主力,包含了 smallbins/largebins/unsortedbins 这三部分
先来看看数组的长度:NBINS * 2 - 2
// 总的bins数量为128
#define NBINS 128可以看到数组长度为 128 * 2 - 2 = 254 个,这是个神奇的数字,首先我们要注意,这里的 254 代表的是 bins 指针有 254 个,实际上 bin 只有 127 个,这里要说一下每个 bin 是如何管理 chunk 的,将相同或者相近的内存块用双向链表串联起来之后,交由一个特定的 bin 管理,每一个 bin 都需要两个指针,分别指向第一个c hunk 和最后一个 chunk,示意图如下:

具体 bin 中的两个指针是用的 chunk 中的 fd 和 bk 指针。
✈️2.2.3.1 smallbins
// 判断给定的尺寸sz是否属于小尺寸bins的范围
#define in_smallbin_range(sz) \
((unsigned long)(sz) < (unsigned long)MIN_LARGE_SIZE)
// 计算给定尺寸sz在小尺寸bins中的索引 32 --> 2; 48 --> 3; 64 --> 4; ...... 1008 --> 63
#define smallbin_index(sz) \
(SMALLBIN_WIDTH == 16 ? (((unsigned)(sz)) >> 4) : (((unsigned)(sz)) >> 3))
smallbins 负责 32-1008 字节的内存分配,索引从 2 开始(对应 32 字节)到 63 结束(对应 1008字节),一共用了 62 个 bins,大于 1024 字节的就交由 largebins 处理。示意图如下所示:

✈️2.2.3.2 largebins
// 1024 --> 64; 4096 --> 99; 5000 --> 100; 16384 --> 114; 32768 --> 118; 262144 --> 125; 524288(min) --> 126
#define largebin_index_64(sz) \
(((((unsigned long)(sz)) >> 6) <= 48) ? 48 + (((unsigned long)(sz)) >> 6) : ((((unsigned long)(sz)) >> 9) <= 20) ? 91 + (((unsigned long)(sz)) >> 9) \
: ((((unsigned long)(sz)) >> 12) <= 10) ? 110 + (((unsigned long)(sz)) >> 12) \
: ((((unsigned long)(sz)) >> 15) <= 4) ? 119 + (((unsigned long)(sz)) >> 15) \
: ((((unsigned long)(sz)) >> 18) <= 2) ? 124 + (((unsigned long)(sz)) >> 18) \
: 126)
largebins 比较特殊,smallbins 中数值都是等差增长的,每个相差 16 字节,largebins 为了加快计算速度,数值是有所偏差的,较大的 bins 按照近似对数间隔分布,这种分布方式可以减少了 bins 的数量,具体大家可以看看这个 large_index 的计算方法,我带入了一些特殊的数值计算了一下,1024字节对应索引 64,4096 字节对应索引 99,32768 字节对应索引 118,当传入大于等于 524288 字节(512KB)时,索引均为 126(最大索引),也就是说最好一个bin处理 0.5MB 到 1MB 之间的内存块。大于 1MB 的交给 MMAP 处理,largebins 共占用 63 个 bin。
✈️2.2.3.3 unsortedbins
未排序的块部分,先看看作者是如何解释的
/*
Unsorted chunks
All remainders from chunk splits, as well as all returned chunks,
are first placed in the "unsorted" bin. They are then placed
in regular bins after malloc gives them ONE chance to be used before
binning. So, basically, the unsorted_chunks list acts as a queue,
with chunks being placed on it in free (and malloc_consolidate),
and taken off (to be either used or placed in bins) in malloc.
The NON_MAIN_ARENA flag is never set for unsorted chunks, so it
does not have to be taken into account in size comparisons.
*/
/*
未排序的块
所有来自块拆分的剩余部分,以及所有返回的块,
首先被放置在“未排序”桶中。然后在 malloc 给它们一个
在分类前使用的机会后,它们会被放置到常规桶中。
因此,基本上,unsorted_chunks 列表充当一个队列,
在 free(和 malloc_consolidate)时将块放置在其中,
并在 malloc 中将其取出(用于使用或放入桶中)。
对于未排序的块,从不设置 NON_MAIN_ARENA 标志,
因此在大小比较时不需要考虑它。
*/可以看到是所有来自块拆分和返回的块部分,可以认为是一个缓存,那他所有哪个 bin 呢?我们已经知道smallbins使用索引 2-63,largebins使用索引 64-126,只剩下索引 0 和 1 未使用,这里unsortedbins 使用索引为了的 bin。
/* The otherwise unindexable 1-bin is used to hold unsorted chunks. */
#define unsorted_chunks(M) (bin_at(M, 1))到目前为止,我们已经大体上知道了这些 bins 的作用,数量上也刚刚好对的上。
🚅3、free函数
在讲述 malloc 函数之前,先来看看 free 是怎么做的。为什么先讲 free 呢?以为只有理解了 free 才能更好的明白 malloc 函数,并且 free 函数相较于 malloc 函数来说代码较短(只有 100+ 行),较好理解,free 总体的函数框架如下所示:

我们来一步一步慢慢看:
🚈3.1 变量定义部分
INTERNAL_SIZE_T size; /* 当前要释放的内存块的大小 */
mfastbinptr *fb; /* 与当前内存块大小相关的 fastbin */
mchunkptr nextchunk; /* 下一个连续的内存块 */
INTERNAL_SIZE_T nextsize; /* 下一个内存块的大小 */
int nextinuse; /* 下一个内存块是否正在被使用 */
INTERNAL_SIZE_T prevsize; /* 前一个内存块的大小 */
mchunkptr bck; /* 用于链接的临时变量 */
mchunkptr fwd; /* 用于链接的临时变量 */
const char *errstr = NULL;这些变量用于管理内存块以及内存合并的过程。
🚈3.2 获取大小并检查状态
size = chunksize(p);
check_inuse_chunk(av, p);chunksize(p):获取当前内存块的大小,来看看具体函数实现
// 获取块 p 的实际大小,忽略标志位
#define chunksize(p) ((p)->size & ~(SIZE_BITS))忽略标志位后计算内存块的实际大小,很好理解。
check_inuse_chunk(av, p):检查当前内存块是否正在被使用。如果内存块已经被释放而没有使用,调用这个函数是为了避免内存双重释放或其他内存错误。
🚈3.3 处理fastbin
if ((unsigned long)(size) <= (unsigned long)(get_max_fast()))
{
if (__builtin_expect(perturb_byte, 0))
free_perturb(chunk2mem(p), size - SIZE_SZ);
set_fastchunks(av);
unsigned int idx = fastbin_index(size);
fb = &fastbin(av, idx);
p->fd = *fb;
*fb = p;
}fastbin 是用于快速处理小块内存的链表。当一个内存块大小小于等于 get_max_fast() 时,它会被放入对应的 fastbin。我们来看看这个神奇的 get_max_fast() 函数:
#define set_max_fast(s) \
global_max_fast = (((s) == 0) \
? SMALLBIN_WIDTH \
: ((s + SIZE_SZ) & ~MALLOC_ALIGN_MASK))
#define get_max_fast() global_max_fast
// 小尺寸bins的宽度,通常等于内存对齐的大小(MALLOC_ALIGNMENT)
#define SMALLBIN_WIDTH MALLOC_ALIGNMENT
#define MALLOC_ALIGNMENT (2 * SIZE_SZ)如果不指定s的值,get_max_fast() 得到的值居然只有 16 字节!要知道 malloc 分配的最小内存块大小为 32 字节!当初一开始看到这里的时候让我十分疑惑,在默认情况下其实 fastbins 根本就没有被开启,需要用户根据自己的程序指定小区快的界限。作者的注释也证明的这一点:
/*
Set value of max_fast.
Use impossibly small value if 0.
Precondition: there are no existing fastbin chunks.
Setting the value clears fastchunk bit but preserves noncontiguous bit.
*/
/*
设置 max_fast 的值。
如果值为 0,则使用一个不可能的极小值。
前提条件:没有现存的 fastbin 块。
设置该值会清除 fastchunk 位,但保留 noncontiguous 位。
*/set_fastchunks() 用来标记这个 arena 中有 fastbin 的块需要处理。
#define set_fastchunks(M) ((M)->flags &= ~FASTCHUNKS_BIT) // 设置标志位,表示有快速存储池块这一部分代码的作用是将要释放的内存块插入到合适的 fastbin 链表中,以加快后续分配和释放。
🚈3.4 处理非fastbins(非mmap)并合并
else if (!chunk_is_mmapped(p))
{
nextchunk = chunk_at_offset(p, size);
nextsize = chunksize(nextchunk);
if (!prev_inuse(p))
{
prevsize = p->prev_size;
size += prevsize;
p = chunk_at_offset(p, -((long)prevsize));
unlink(p, bck, fwd);
}
if (!nextinuse)
{
unlink(nextchunk, bck, fwd);
size += nextsize;
}
else
clear_inuse_bit_at_offset(nextchunk, 0);chunk_is_mmapped(p):判断当前块是否是通过 mmap 分配的内存块,mmap 分配的内存块不会存储在堆上,因此不能像普通块那样处理。
// 检查块 p 是否通过 mmap 分配
#define chunk_is_mmapped(p) ((p)->size & IS_MMAPPED)chunk_at_offset(p, size):获取下一个连续内存块的地址。结合着内存块图来理解就行
// 返回位于块 p 之后偏移 s 字节处的块指针
#define chunk_at_offset(p, s) ((mchunkptr)(((char *)(p)) + (s)))prev_inuse(p):判断前一个块是否正在使用,如果没有使用,合并前一个块与当前块。
// 检查给定块 p 的 size 字段中的 PREV_INUSE 标志位,以确定前一个块是否被占用
#define prev_inuse(p) ((p)->size & PREV_INUSE)
unlink():将下一个块从其所属的链表中移除,准备进行合并。这个函数比较复杂,感兴趣的同学可以去读源代码。
这一部分代码的功能是检测当前内存块是否可以与前后相邻的块进行合并,以避免内存碎片化。
🚈3.5 插入到unsortedbins
bck = unsorted_chunks(av);
fwd = bck->fd;
if (__builtin_expect(fwd->bk != bck, 0))
{
errstr = "free(): corrupted unsorted chunks";
goto errout;
}
p->fd = fwd;
p->bk = bck;
bck->fd = p;
fwd->bk = p;
set_head(p, size | PREV_INUSE);
set_foot(p, size);
check_free_chunk(av, p);当前块会被插入到 unsorted bin(无序链表)中。这是内存管理器的一个临时区域,用来放置刚刚被释放的块,以便稍后在需要时重新分配。set_head() 和 set_foot():更新块的头部和尾部信息,标记合并后的块大小和状态。
// 直接设置块 p 的头部为 s,这会覆盖所有的标志位
#define set_head(p, s) ((p)->size = (s))
// 设置块 p 的脚部(仅在块未使用时)为 s。脚部通常用于双向链接或快速访问前一个块的大小
#define set_foot(p, s) (((mchunkptr)((char *)(p) + (s)))->prev_size = (s))🚈3.6 处理top块
else{
size += nextsize;
set_head(p, size | PREV_INUSE);
av->top = p;
check_chunk(av, p);
}这里比较简单,很好理解。
🚈3.7 判断是否需要快速合并
if ((unsigned long)(size) >= FASTBIN_CONSOLIDATION_THRESHOLD)
{
if (have_fastchunks(av))
malloc_consolidate(av);如果块的大小大于 FASTBIN_CONSOLIDATION_THRESHOLD,系统会执行块的合并操作,防止内存碎片化,合并 fastbin 的函数为 malloc_consolidate(),感兴趣的同学可以去看一下,对链表操作熟悉的同学可以很容易看懂。
🚈3.8 处理主堆和非主堆的内存修建以及释放mmap分配的块
if (av == &main_arena)
{
#ifndef MORECORE_CANNOT_TRIM
if ((unsigned long)(chunksize(av->top)) >=
(unsigned long)(mp_.trim_threshold))
sYSTRIm(mp_.top_pad, av);
#endif
}
else
{
heap_info *heap = heap_for_ptr(top(av));
assert(heap->ar_ptr == av);
heap_trim(heap, mp_.top_pad);
}
}
#ifdef ATOMIC_FASTBINS
if (!have_lock)
{
assert(locked);
(void)mutex_unlock(&av->mutex);
}
#endif
}
else
{
#if HAVE_MMAP
munmap_chunk(p);
#endif
}大致上就是处理内存释放,包括将块插入到 fastbin 或 unsorted bin 中,检查相邻块是否可以合并,以及在合适的情况下进行内存合并操作,以减少内存碎片化。
🚅4、malloc函数——万里长征
终于到了最为复杂的 malloc 函数,这个函数非常的长,有 600+ 行,先来看看函数的总览图:

可以看到非常的复杂,上述还是简化后的效果,一共有七个部分,有六个部分与分配有关,分配的尝试顺序为:fastbins → smallbins → unsortedbins → largebins → top chunk → mmap。
🚈4.1 初始化变量部分
static Void_t* _int_malloc(mstate av, size_t bytes) {
INTERNAL_SIZE_T nb; // 标准化的请求大小
unsigned int idx; // 关联的bin索引
mbinptr bin;
mchunkptr victim; // 正在检查/选择的块
INTERNAL_SIZE_T size; // 选中块的大小
int victim_index;
mchunkptr remainder; // 剩余部分
unsigned long remainder_size;
unsigned int block;
unsigned int bit;
unsigned int map;
mchunkptr fwd;
mchunkptr bck;
const char *errstr = NULL;
checked_request2size(bytes, nb); // 加上cookie并调整大小
// ......
}这里是对一系列后续需要使用的变量初始化过程,比较特殊的是将选择的块称为victim(受害者,还蛮生动形象的),剩余部分为 remainder。
关注一下这个 checked_request2size(bytes, nb) 函数,其内部又调用了 request2size(req) 函数,这是个上调并对齐函数,一直没讲他,这个操作也是内存管理的固有技巧。
#define request2size(req) \
(((req) + SIZE_SZ + MALLOC_ALIGN_MASK < MINSIZE) ?
MINSIZE : ((req) + SIZE_SZ + MALLOC_ALIGN_MASK)
& ~MALLOC_ALIGN_MASK)🚈4.2 fastbins分配
if ((unsigned long)(nb) <= (unsigned long)(get_max_fast()))
{
idx = fastbin_index(nb);
mfastbinptr *fb = &fastbin(av, idx);
victim = *fb;
if (victim != 0)
{
*fb = victim->fd;
check_remalloced_chunk(av, victim, nb);
void *p = chunk2mem(victim);
if (__builtin_expect(perturb_byte, 0))
alloc_perturb(p, bytes);
return p;
}
}首先尝试从 fastbins 中分配,因为这个速度最快,也很有可能可以从中分配,这个 get_max_fast()函数已经讲过的,要由用户自己定义小区块的大小界定。然后就是一套标准操作,取索引,分配指针,然后讲指向 chunk 的指针改为指向 mem(user data 的开始)的指针。
#define chunk2mem(p) ((Void_t *)((char *)(p) + 2 * SIZE_SZ))🚈4.3 smallbins分配
然后尝试从 smallbins 分配,和 fastbins 比较类似。
if (in_smallbin_range(nb))
{
idx = smallbin_index(nb); // >=1
bin = bin_at(av, idx); // 获取对应索引idx的bin
if ((victim = last(bin)) != bin) // 判断bin中是否有可用的块
{
if (victim == 0) /* initialization check */
malloc_consolidate(av); // 初始化
else // 处理找到的victim块
{
bck = victim->bk; // 获取前一块
set_inuse_bit_at_offset(victim, nb); // 设置块为已使用状态
// 更新指针
bin->bk = bck;
bck->fd = bin;
if (av != &main_arena)
victim->size |= NON_MAIN_ARENA;
void *p = chunk2mem(victim);
if (__builtin_expect(perturb_byte, 0))
alloc_perturb(p, bytes);
return p;
}
}
}
需要注意的是,如果分配失败,要合并 fastbins 中的小区块。
🚈4.4 unsortedbins分配
然后就到了比较复杂的 unsortedbins 分配,首先合并小区块,这里有一段作者的解释:
/*
If this is a large request, consolidate fastbins before continuing.
While it might look excessive to kill all fastbins before
even seeing if there is space available, this avoids
fragmentation problems normally associated with fastbins.
Also, in practice, programs tend to have runs of either small or
large requests, but less often mixtures, so consolidation is not
invoked all that often in most programs. And the programs that
it is called frequently in otherwise tend to fragment.
如果这是一个大请求,请在继续之前合并 fastbins。
虽然在查看是否有可用空间之前清空所有 fastbins 可能看起来过于繁琐,但这样可以避免通常与 fastbins 相关的碎片化问题。
此外,实际上,程序通常会有一系列的小请求或大请求,而很少有混合请求,因此在大多数程序中合并操作并不经常被调用。而那些频繁调用合并操作的程序通常倾向于碎片化。
*/然后判断请求的是不是 smallbins 范围的,这里你肯定会感到疑惑,smallbins 范围的不是已经在之前处理了吗?怎么这里还要判断,这个问题我也是被卡住了很久,其实这里判断是不是小区块,是因为在之前 smallbins 中可能分配之后,然后进入到 unsortedbins 分配环节,有没有这种可能呢?当然是可能的,比如说 smallbins 中已经没有区块了这种极端情况。
然后判断当前的缓存块能不能满足要求,如果可以就直接分配,如果不行,就将缓存块根据大小放入对应的 fastbins 和 smallbins 中,这里充分诠释了缓存的意义!
这里最后还有一个避免超时的操作,是为了防止遍历 unsorted bin 占用过多时间。
🚈4.5 largebins分配
然后进入到 largebins 分配环节,这里比较特殊的是大块内存往往需要分割,用了跳表来加速查找,还涉及到 binmap 的遍历,这个 binmap 之前一直没讲,其实就是一个位图,用来表示这128个 bins 是否已被占用,这也是内存管理上的惯用技巧。
// 表示在位操作中用于计算块索引时所使用的偏移量.BINMAPSHIFT 设置为 5,意味着 BITSPERMAP 是 32,因为 1 << 5 = 32。这与每个映射字使用 32 位的设计相符
#define BINMAPSHIFT 5
// BITSPERMAP 表示每个 binmap 词(word)中的位数,也就是 32 位(1U << 5 = 32)。这表示每个存储池映射的词可以追踪 32 个不同的 bin
#define BITSPERMAP (1U << BINMAPSHIFT)
// BINMAPSIZE 计算了 binmap 的大小,即存储池总数(NBINS)除以每个映射词的位数(32)。这样可以确定需要多少个 binmap 词来追踪所有存储池
#define BINMAPSIZE (NBINS / BITSPERMAP)
// idx2block(i) 将 bin 的索引 i 转换为所在的 binmap 词的索引。通过将索引 i 右移 BINMAPSHIFT(即 5 位),实现除以 32 的效果
#define idx2block(i) ((i) >> BINMAPSHIFT)
// idx2bit(i) 计算出 bin 对应的具体位。它通过对 i 进行与运算来获得 i 在 binmap 词内的具体位置,然后左移对应的位数来生成一个位掩码
#define idx2bit(i) ((1U << ((i) & ((1U << BINMAPSHIFT) - 1))))
// mark_bin(m, i) 用于标记存储池 i 为非空。它将 binmap 的相应位设置为 1,表示该存储池已经被占用
#define mark_bin(m, i) ((m)->binmap[idx2block(i)] |= idx2bit(i))
// unmark_bin(m, i) 用于取消标记存储池 i,将相应的位清零,表示该存储池为空
#define unmark_bin(m, i) ((m)->binmap[idx2block(i)] &= ~(idx2bit(i)))
// get_binmap(m, i) 用于检查存储池 i 是否被标记。它返回 binmap 中该位置的位,如果该位为 1,表示该存储池非空,反之为空
#define get_binmap(m, i) ((m)->binmap[idx2block(i)] & idx2bit(i))
🚈4.6 top chunk分配
use_top:
victim = av->top;
size = chunksize(victim);
if ((unsigned long)(size) >= (unsigned long)(nb + MINSIZE))
{
remainder_size = size - nb;
remainder = chunk_at_offset(victim, nb);
av->top = remainder;
set_head(victim, nb | PREV_INUSE |
(av != &main_arena ? NON_MAIN_ARENA : 0));
set_head(remainder, remainder_size | PREV_INUSE);
check_malloced_chunk(av, victim, nb);
void *p = chunk2mem(victim);
return p;
}
else if (have_fastchunks(av))
{
assert(in_smallbin_range(nb));
malloc_consolidate(av);
idx = smallbin_index(nb);
}top chunk 就是最顶部的可用块(即,紧邻可用内存末端的块),有特殊处理。它从不包含在任何存储池中,仅在没有其他块可用时使用。代码也是比较好理解的。
🚈4.7 MMAP分配
如果前面都失败了,或者神奇的内存块大于 1MB,就用 MMAP 分配:
else {
void *p = sYSMALLOc(nb, av);
if (p != NULL && __builtin_expect(perturb_byte, 0))
alloc_perturb(p, bytes);
return p;
}🚅5.0 结束语
可以看到 ptmalloc 的实现是十分复杂宏大的,强烈建议大家对照着源代码来阅读本文,我在阅读源码的时候收获和感悟是很多的,但要写出文章来又感觉少了一半,大家可以自己去阅读源码,自己整理这个过程,如果是应届生朋友,可以在简历上写熟悉 malloc,用自己的话表达出来。
本来是想要让小白也能看懂,但实在是内容过于复杂,写出来感觉没有基础的同学是很难看懂的,我也总感觉还有一些内容没有写出来,最好去看看侯捷老师的视频课,会发现基本上 malloc 的实现大同小异,甚至有了解过STL二级分配器的同学,可以明显的感受到这些技巧都是这么的熟悉!后续还会继续优化文章内容,使其更加易于理解。