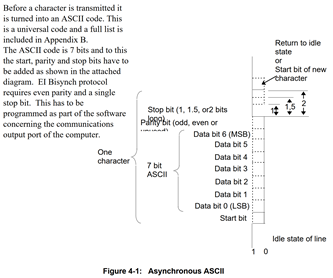
GBDT(Gradient Boosting Decision Tree,梯度提升决策树)是一种集成学习方法,主要用于回归和分类任务。它的基本思想是通过迭代地构建一系列弱学习器(通常是决策树),并将这些弱学习器组合成一个强学习器。下面详细介绍GBDT的原理及其公式推导过程。
GBDT算法原理
GBDT算法通过构建多个决策树,将它们的结果相加以得到最终的预测结果。在每一轮迭代中,新加入的树会尝试修正已有模型的错误,具体而言,新树会尝试拟合已有模型预测结果与真实标签之间的残差。
初始模型
初始模型通常是一个简单的常数函数,表示所有样本的平均响应值:
迭代过程
在每轮迭代中,我们计算当前模型预测值与真实值之间的残差,并用新树来拟合这些残差:

其中 𝜆 是一个正则化参数,称为学习率或步长,用来控制每次迭代更新的幅度,避免过拟合。
公式推导过程

公式推导实例
假设我们使用平方损失函数,那么在每次迭代时,我们需要计算的负梯度为:
通过这样的方式不断迭代,直到达到预定的迭代次数或满足停止条件为止。
本文的讲解会比较基础,作者在CSDN上线了更详细、系统的机器学习,包含数学基础、机器学习理论和代码实战、项目实战 机器学习理论和实战 可以试听
代码示例
下面提供一个使用Python和Scikit-Learn库来实现GBDT进行乳腺癌预测的示例代码
import numpy as np
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix
# 加载数据
data = load_breast_cancer()
X = data.data
y = data.target
# 数据切分
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建GBDT分类器
gbdt = GradientBoostingClassifier(
# learning_rate:学习率,默认为0.1,较小的学习率可以带来更好的模型,但需要更多的迭代次数。
learning_rate=0.1,
# n_estimators:基学习器的数量,默认为100,增加基学习器的数量通常可以提高模型性能。
n_estimators=100,
# max_depth:决策树的最大深度,默认为3,较大的深度可能会导致过拟合。
max_depth=3,
random_state=42
)
# 训练模型
gbdt.fit(X_train, y_train)
# 预测
y_pred = gbdt.predict(X_test)
# 评估模型
accuracy = accuracy_score(y_test, y_pred)
report = classification_report(y_test, y_pred)
confusion = confusion_matrix(y_test, y_pred)
print(f"Accuracy: {accuracy:.2f}")
print("Classification Report:")
print(report)
print("Confusion Matrix:")
print(confusion)注意事项
在实际应用GBDT算法时,还需要注意以下几点:
过拟合预防:通过设置学习率、树的最大深度、最小样本分割等参数来控制模型复杂度,防止过拟合。
随机性引入:通过随机选取部分数据或特征进行训练,增强模型的泛化能力。
超参数调优:合理选择迭代次数、树的深度、学习率等超参数,以获得最佳模型性能。
GBDT因其出色的性能和灵活性,在工业界得到了广泛应用,特别是在推荐系统、金融风控等领域