做到这里,其实只是想探索下新的检测框架、探索下atlas下ACL的推理方式。整个过程持续了3-4周把,回顾一下,感觉还是需要一些技巧才能拿下,如果没有任何经验的是断难搞定此代码的。主要基于华为的官方例子,里面修改了原始代码中某些库不支持的问题、解决了模型转化过程中的一些问题,发现了ACL不支持多线程的问题。
路漫漫、吾上下,纵使困顿难行,亦当砥砺奋进。

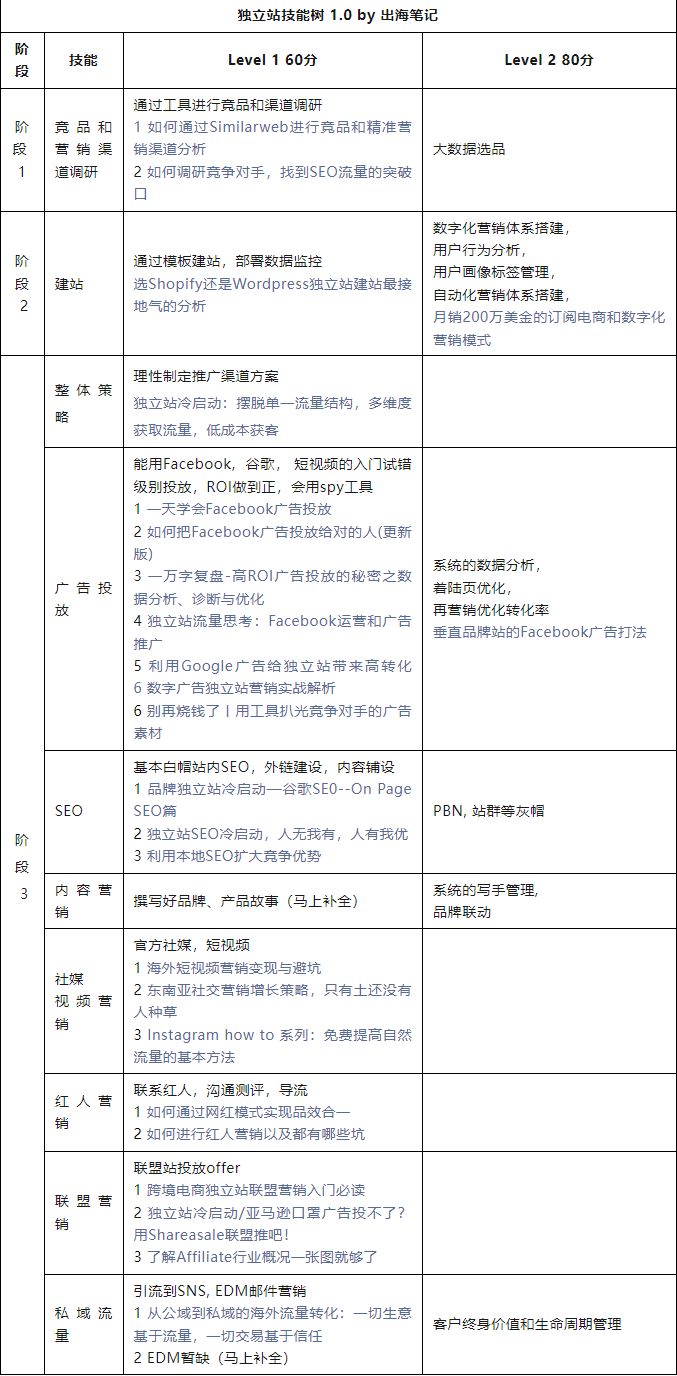
数据集制作标注:
数据集为网上搜集的,共计1407张。实用labelimg进行标注,大概花了1个多星期。
本着取之于民用之于民的思想,也分享出来,(https://download.csdn.net/download/qq_14845119/89775339),需要自提。

数据集目录结构如下,

模型训练:
训练yolov7-tiny模型
python train.py --workers 8 --device 1 --batch-size 32 --data data/sleep.yaml --img 640 640 --cfg cfg/training/yolov7-tiny-sleep.yaml --weights ./yolov7.pt --name yolov7 --hyp data/hyp.scratch.tiny.yaml训练结果,

可视化效果,

训练yolov7模型
python train.py --workers 8 --device 0 --batch-size 32 --data data/sleep.yaml --img 640 640 --cfg cfg/training/yolov7-sleep.yaml --weights ./yolov7.pt --name yolov7 --hyp data/hyp.scratch.p5.yaml训练结果,

可视化效果,

这里对比的训练的yolov7、yolov7-tiny两个模型,从精度上的明显差距,最终选择了yolov7模型作为最终模型。
模型转化:
Pt模型转化onnx模型,
python export.py --weights runs/train/yolov73/weights/best.pt --grid --end2end --simplify --topk-all 100 --iou-thres 0.65 --conf-thres 0.35 --img-size 640 640 --max-wh 640
首先使用Netron工具查看模型最终输出的3个节点的名称,得到模型的3个输出节点名称。

cd model/
atc --model=yolov7.onnx --framework=5 --output=yolov7 --soc_version=Ascend310P3 --out_nodes="/model/model.105/m.0/Conv:0;/model/model.105/m.1/Conv:0;/model/model.105/m.2/Conv:0" --input_shape="images:1,3,640,640"

后处理转化:
cd src/
python3 postProcessOperator.py
cd model/
atc --model=postprocess.onnx --soc_version=Ascend310P3 --output=postprocess --framework=5 --input_shape='img_info:1,4'

后处理postProcessOperator.py代码如下,
import onnx
from onnx import helper
h, w = 640, 640
boxNum = 3
outNUm = 3
#classes = 80
classes = 1
coords = 4
f_h, f_w = h // 8, w // 8
# yolov7x anchor
anchor = [12.0, 16.0,
19.0, 36.0,
40.0, 28.0,
36.0, 75.0,
76.0, 55.0,
72.0, 146.0,
142.0, 110.0,
192.0, 243.0,
459.0, 401.0]
#input_shape_0 = [1, 255, 80, 80]
#input_shape_1 = [1, 255, 40, 40]
#input_shape_2 = [1, 255, 20, 20]
input_shape_0 = [1, 18, 80, 80]
input_shape_1 = [1, 18, 40, 40]
input_shape_2 = [1, 18, 20, 20]
img_info_num = 4
max_boxes_out = 6 * 1024
box_num = 8
pre_nms_topn = 1024
post_nms_topn = 1024
relative = 1
out_box_dim = 2
obj_threshold = 0.25
score_threshold = 0.25
iou_threshold = 0.45
input_0 = helper.make_tensor_value_info("input_0", onnx.TensorProto.FLOAT, input_shape_0)
input_1 = helper.make_tensor_value_info("input_1", onnx.TensorProto.FLOAT, input_shape_1)
input_2 = helper.make_tensor_value_info("input_2", onnx.TensorProto.FLOAT, input_shape_2)
crd_align_len = f_h * f_w
obj_align_len = boxNum * f_h * f_w
coord_data_0 = helper.make_tensor_value_info("yolo_coord_0", onnx.TensorProto.FLOAT,
['batch', boxNum * 4, crd_align_len])
obj_prob_0 = helper.make_tensor_value_info("yolo_obj_0", onnx.TensorProto.FLOAT,
['batch', obj_align_len])
classes_prob_0 = helper.make_tensor_value_info("yolo_classes_0", onnx.TensorProto.FLOAT,
['batch', classes, obj_align_len])
yolo_pre_node_0 = helper.make_node('YoloPreDetection',
inputs = ["input_0"],
outputs = ["yolo_coord_0", "yolo_obj_0", "yolo_classes_0"],
boxes = boxNum,
coords = coords,
classes = classes,
yolo_version ='V5',
name = "yolo_pre_node_0")
f_h, f_w = f_h // 2, f_w // 2
crd_align_len = f_h * f_w
obj_align_len = boxNum * f_h * f_w
coord_data_1 = helper.make_tensor_value_info("yolo_coord_1", onnx.TensorProto.FLOAT,
['batch', boxNum * 4, crd_align_len])
obj_prob_1 = helper.make_tensor_value_info("yolo_obj_1", onnx.TensorProto.FLOAT,
['batch', obj_align_len])
classes_prob_1 = helper.make_tensor_value_info("yolo_classes_1", onnx.TensorProto.FLOAT,
['batch', classes, obj_align_len])
yolo_pre_node_1 = helper.make_node('YoloPreDetection',
inputs = ["input_1"],
outputs = ["yolo_coord_1", "yolo_obj_1", "yolo_classes_1"],
boxes = boxNum,
coords = coords,
classes = classes,
yolo_version = 'V5',
name = "yolo_pre_node_1")
f_h, f_w = f_h // 2, f_w // 2
crd_align_len = f_h * f_w
obj_align_len = boxNum * f_h * f_w
coord_data_2 = helper.make_tensor_value_info("yolo_coord_2", onnx.TensorProto.FLOAT,
['batch', boxNum * 4, crd_align_len])
obj_prob_2 = helper.make_tensor_value_info("yolo_obj_2", onnx.TensorProto.FLOAT,
['batch', obj_align_len])
classes_prob_2 = helper.make_tensor_value_info("yolo_classes_2", onnx.TensorProto.FLOAT,
['batch', coords, obj_align_len])
yolo_pre_node_2 = helper.make_node('YoloPreDetection',
inputs=["input_2"],
outputs=["yolo_coord_2", "yolo_obj_2", "yolo_classes_2"],
boxes=boxNum,
coords = coords,
classes = classes,
yolo_version='V5',
name="yolo_pre_node_2")
# create yolo detection output layer
img_info = helper.make_tensor_value_info("img_info", onnx.TensorProto.FLOAT, ['batch', img_info_num])
box_out = helper.make_tensor_value_info("box_out", onnx.TensorProto.FLOAT, ['batch', max_boxes_out])
box_out_num = helper.make_tensor_value_info("box_out_num", onnx.TensorProto.INT32, ['batch', box_num])
yolo_detect_node = helper.make_node('YoloV5DetectionOutput',
inputs = [f"yolo_coord_{i}" for i in range(outNUm)] +
[f"yolo_obj_{i}" for i in range(outNUm)] +
[f"yolo_classes_{i}" for i in range(outNUm)] +
['img_info'],
outputs = ['box_out', 'box_out_num'],
boxes = boxNum,
coords = coords,
classes = classes,
pre_nms_topn = pre_nms_topn,
post_nms_topn = post_nms_topn,
relative = relative,
out_box_dim = out_box_dim,
obj_threshold = obj_threshold,
score_threshold = score_threshold,
iou_threshold = iou_threshold,
biases = anchor,
name ='YoloV5DetectionOutput')
# make graph
graph = helper.make_graph(
nodes = [yolo_pre_node_0, yolo_pre_node_1, yolo_pre_node_2, yolo_detect_node],
name = "yolo",
inputs = [input_0, input_1, input_2, img_info],
outputs = [box_out, box_out_num]
)
onnx_model = helper.make_model(graph, producer_name="onnx-parser")
onnx_model.opset_import[0].version = 12
onnx.save(onnx_model, "./models/postprocess.onnx")
注意这里要根据自己的实际训练参数,修改classes、anchor、input_shape_0、input_shape_1、input_shape_2等变量的数值。
推理代码编写:
import os
import cv2
import time
import numpy as np
from label import labels
import sys
sys.path.append("./acllite/python/")
from acllite_imageproc import AclLiteImage
from acllite_imageproc import AclLiteImageProc
from acllite_model import AclLiteModel
from acllite_resource import AclLiteResource
from acllite_logger import log_info
class YOLOV7_NMS_ONNX(object):
def __init__(self,):
self.yolo_model_path = "./models/yolov7.om" # string
self.yolo_model = None
self.yolo_model_width = 640
self.yolo_model_height = 640
#self.yolo_result = None
self.postprocess_model = None
self.postprocess_model_path = "./models/postprocess.om"
#self.postprocess_input = None
#self.postprocess_result = None
self.resource = None
#self.image = None
#self.resized_image = None
self.init_resource()
def init_resource(self):
# init acl resource
self.resource = AclLiteResource()
self.resource.init()
# load yolo model from file
self.yolo_model = AclLiteModel(self.yolo_model_path)
# load postprocess model from file
self.postprocess_model = AclLiteModel(self.postprocess_model_path)
def yolo_process_input(self, image):
image = image[:,:,::-1]
resized = cv2.resize(image, (self.yolo_model_width, self.yolo_model_height))
new_image = resized.astype(np.float32)
new_image = new_image / 255.0
resized_image = new_image.transpose(2, 0, 1).copy()
#self.resized_image = new_image
#self.image = image
return resized_image
def postprocess_process_input(self, yolo_result):
# construct image info
image_info = np.array([self.yolo_model_width, self.yolo_model_height,
self.yolo_model_width, self.yolo_model_height],
dtype=np.float32)
#yolo_result.reverse()
# construct postprocess input
postprocess_input = [*yolo_result, image_info]
return postprocess_input
def yolo_inference(self, resized_image):
# inference
yolo_result = self.yolo_model.execute([resized_image])
return yolo_result
def postprocess_inference(self, postprocess_input):
postprocess_result = self.postprocess_model.execute(postprocess_input)
return postprocess_result
def postprocess_get_reslut(self, src_image, postprocess_result):
box_num = postprocess_result[1][0, 0]
box_info = postprocess_result[0].flatten()
scale_x = src_image.shape[1] / self.yolo_model_width
scale_y = src_image.shape[0] / self.yolo_model_height
# get scale factor
#if scale_x > scale_y:
# max_scale = scale_x
#else:
# max_scale = scale_y
ids = []
scores = []
boxes = []
for n in range(int(box_num)):
id = int(box_info[5 * int(box_num) + n])
score = box_info[4 * int(box_num) + n]
top_left_x = box_info[0 * int(box_num) + n] * scale_x#max_scale
top_left_y = box_info[1 * int(box_num) + n] * scale_y#max_scale
bottom_right_x = box_info[2 * int(box_num) + n] * scale_x#max_scale
bottom_right_y = box_info[3 * int(box_num) + n] * scale_y#max_scale
if id ==0:
ids.append(id)
scores.append(float(score))
boxes.append([int(top_left_x), int(top_left_y), int(bottom_right_x), int(bottom_right_y)])
return ids, scores, boxes
def release_resource(self):
# release resource includes acl resource, data set and unload model
self.yolo_model.__del__()
self.postprocess_model.__del__()
self.resource.__del__()
AclLiteResource.__del__ = lambda x: 0
AclLiteModel.__del__ = lambda x: 0
def process(self, image):
resized_image = self.yolo_process_input(image)
yolo_result = self.yolo_inference(resized_image)
postprocess_input = self.postprocess_process_input(yolo_result)
postprocess_result = self.postprocess_inference(postprocess_input)
ids, scores, boxes = self.postprocess_get_reslut(image, postprocess_result)
return ids, scores, boxes
def draw(self, image, ids, scores, boxes):
colors = [0, 0, 255]
# draw the boxes in original image
for id, score, box in zip(ids, scores, boxes):
label = labels[id] + ":" + str("%.2f" % score)
cv2.rectangle(image, (box[0], box[1]), (box[2], box[3]), colors)
p3 = (max(box[0], 15), max(box[1], 15))
cv2.putText(image, label, p3, cv2.FONT_ITALIC, 0.6, colors, 2)
return image
def __del__(self):
self.release_resource()
def test_images():
current_dir = os.path.dirname(os.path.abspath(__file__))
images_path = os.path.join(current_dir, "./data")
all_path = []
for path in os.listdir(images_path):
if path.split(".")[-1] != 'mp4':
total_path = os.path.join(images_path, path)
all_path.append(total_path)
print(all_path)
if len(all_path) == 0:
raise Exception("the directory is empty, please download image")
net = YOLOV7_NMS_ONNX()
for images_path in all_path:
image = cv2.imread(images_path)
t1 = time.time()
ids, scores, boxes = net.process(image)
src_image = net.draw(image, ids, scores, boxes)
t2 = time.time()
print("time cost:", t2-t1)
output_path = os.path.join("./out", os.path.basename(images_path))
cv2.imwrite(output_path, src_image)
log_info("success")
def test_video():
yolov7 = YOLOV7_NMS_ONNX()
# Open the video file
video_path = "./data/sleep.mp4"
cap = cv2.VideoCapture(video_path)
fourcc = cv2.VideoWriter_fourcc('X', 'V', 'I', 'D') # 确定视频被保存后的编码格式
output = cv2.VideoWriter("output.mp4", fourcc, 25, (852, 480)) # 创建VideoWriter类对象
# Loop through the video frames
while cap.isOpened():
# Read a frame from the video
success, frame = cap.read()
if success:
# Run YOLOv8 tracking on the frame, persisting tracks between frames
t1 = time.time()
ids, scores, boxes = yolov7.process(frame)
t2 = time.time()
annotated_frame = yolov7.draw(frame, ids, scores, boxes)
t3 = time.time()
print("time", t2-t1, t3-t2,t3-t1)
output.write(annotated_frame)
# Display the annotated frame
# Break the loop if 'q' is pressed
if cv2.waitKey(1) & 0xFF == ord("q"):
break
else:
# Break the loop if the end of the video is reached
break
# Release the video capture object and close the display window
cap.release()
cv2.destroyAllWindows()
if __name__ == "__main__":
#test_images()
test_video()
测试效果:

视频测试:
B站找一段睡觉的视频下载下来,这里实用you-get工具,
you-get 当 代 高 三 牲 睡 觉 图 鉴_哔哩哔哩_bilibili,实际效果如下,

其他问题记录:
本来自己是想做一个grpc的架构的,可是实际做的过程中发现华为的AclLiteModel实现的很差,对于进程、线程这些非常不友好,必须得是一个进程,同样的上下文才可以得到正确的推理结果。最终也没好的解决方法,重新修改了架构。
华为官方文档链接(aclmdlExecute-模型加载与执行-AscendCL API参考-应用开发(C++)-推理应用开发-CANN商用版6.0.1开发文档-昇腾社区)

参考链接:
https://github.com/WongKinYiu/yolov7
Ascend/modelzoo-GPL - Gitee.com
samples: CANN Samples - Gitee.com