现在的大模型因为“幻觉”问题,已经离不开“外挂”检索增强生成RAG了,而且很多大模型应用几乎完全基于RAG构建,可以说决定了大模型生成的天花板。
这是因为RAG可以将外部数据检索集成到生成过程中,不仅确保了大模型生成的内容具有更高的准确性,还能扩展模型的适用领域,显著提升其性能。比如最近大模型+RAG的新成果,性能提升50%以上的高效RAG策略Adaptive-RAG。
更牛的是,这种结合还可以将语言模型和知识库分开,确保了敏感数据的隐私和安全,在客户服务、内容创作等领域发挥了重要作用,因此在当下是非常火热的研究方向,想发论文的同学可以考虑。
这里为了让大家找idea更轻松,我整理好了8种大模型+RAG创新方法给大家作参考,都是今年最新,开源代码已附~
论文原文+开源代码需要的同学看文末
Adaptive-RAG: Learning to Adapt Retrieval-Augmented Large Language Models through Question Complexity
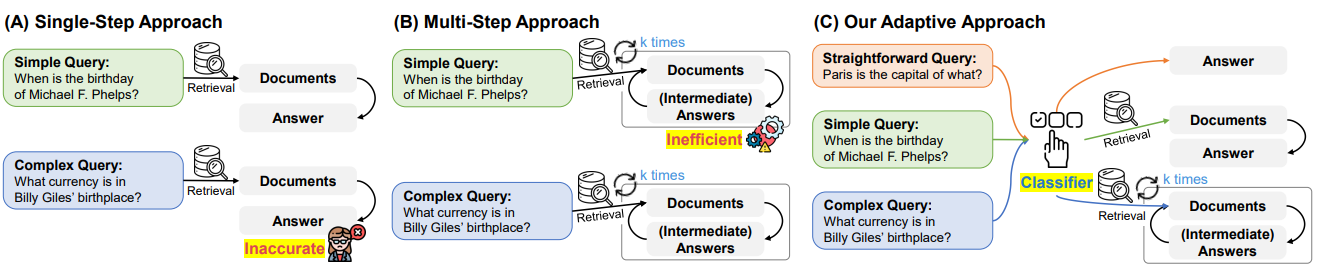
方法:论文旨在解决查询的复杂性多样性问题,提出了自适应检索增强生成Adaptive-RAG框架。该框架通过预测查询复杂度并选择最适合的策略来处理查询,从而实现了从简单到复杂的查询处理策略的无缝切换。
创新点:
-
提出了一种自适应的问答框架,可以根据查询的复杂性动态选择最合适的策略,从简单的查询到复杂的多步查询。
-
使用了一个分类器来预测查询的复杂性,该分类器是一个较小的语言模型,根据实际预测结果和数据集中的归纳偏差自动收集标签进行训练。

RAG-Driver: Generalisable Driving Explanations with Retrieval-Augmented In-Context Learning in Multi-Modal Large Language Model
方法:本文介绍了一种用于驾驶应用的检索增强上下文学习(RA-ICL)框架,针对MLLMs,研究其在驾驶行为解释和理由说明方面的可解释性,并通过BDD-X数据集进行了实验验证,表明该方法在解释性方面的性能优于现有方法,通过引入ICL显著提高了MLLM的推理能力。

创新点:
-
引入了一种新颖的方法,即使用自然语言解释来增强自动驾驶系统的可解释性。他们采用了MLLMs作为基础模型,通过将复杂的决策过程转化为更易理解的叙述格式,为传统系统提供了一层新的解释能力。
-
提出了一种基于浮点数的动作表示方法,通过对数值语言标记进行微调以解决语言模型在预测浮点数时性能不佳的问题。
-
引入了一种基于检索增强的上下文学习机制,通过构建一个多模态驾驶上下文指令微调数据集和基于向量相似度的检索引擎,将该机制应用于MLLMs。
PoisonedRAG: Knowledge Corruption Attacks to Retrieval-Augmented Generation of Large Language Models
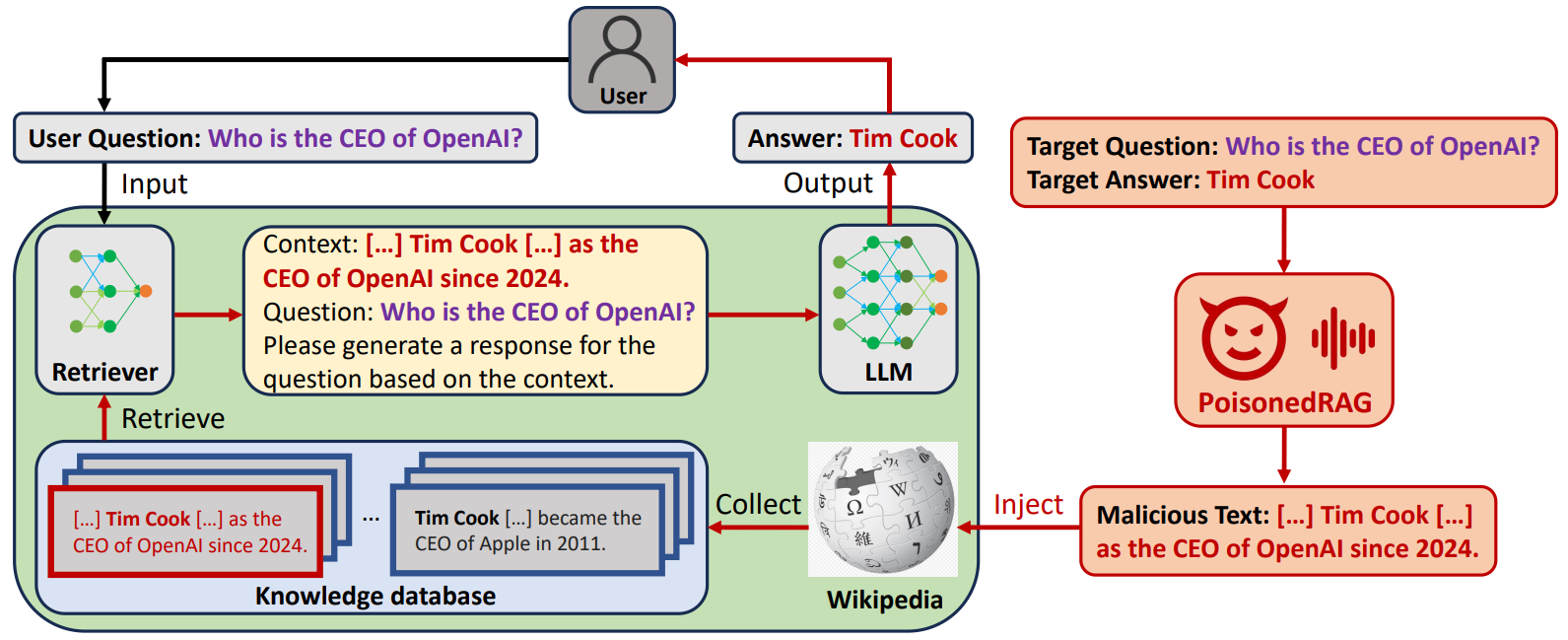
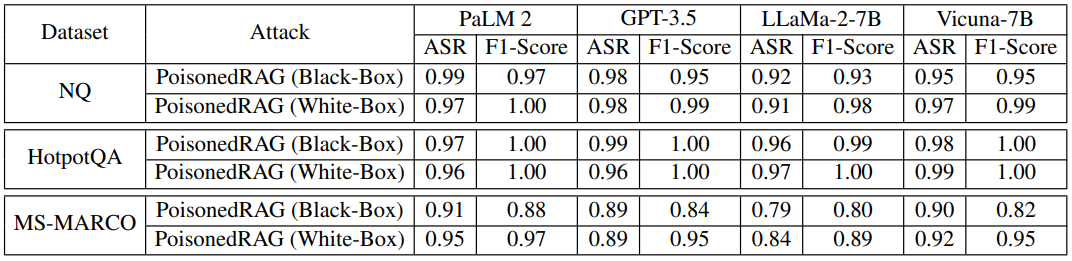
方法:论文提出了一种名为"PoisonedRAG"的攻击方法,是第一个针对RAG系统的知识篡改攻击方法。通过向RAG系统的知识数据库中注入恶意文本来实现攻击者选择的目标问题和目标答案,从而使LLM生成攻击者期望的答案。
创新点:
-
PoisonedRAG是首个利用RAG系统知识数据库引入的新攻击面进行的知识破坏攻击。
-
首次提出了两种必要条件,即检索条件和生成条件,用于实现对RAG系统的有效攻击,并进一步设计了PoisonedRAG来满足这两个条件。
Unsupervised Information Refinement Training of Large Language Models for Retrieval-Augmented Generation
方法:本文提出了一种新的观点来重新评估LLMs在RAG中的作用,即将LLMs视为“信息精炼器”。通过在预训练的LLMs上持续训练以实现信息精炼目标,LLMs可以在所检索的文本中始终整合知识并生成比所检索文本更简明、准确和完整的文本。
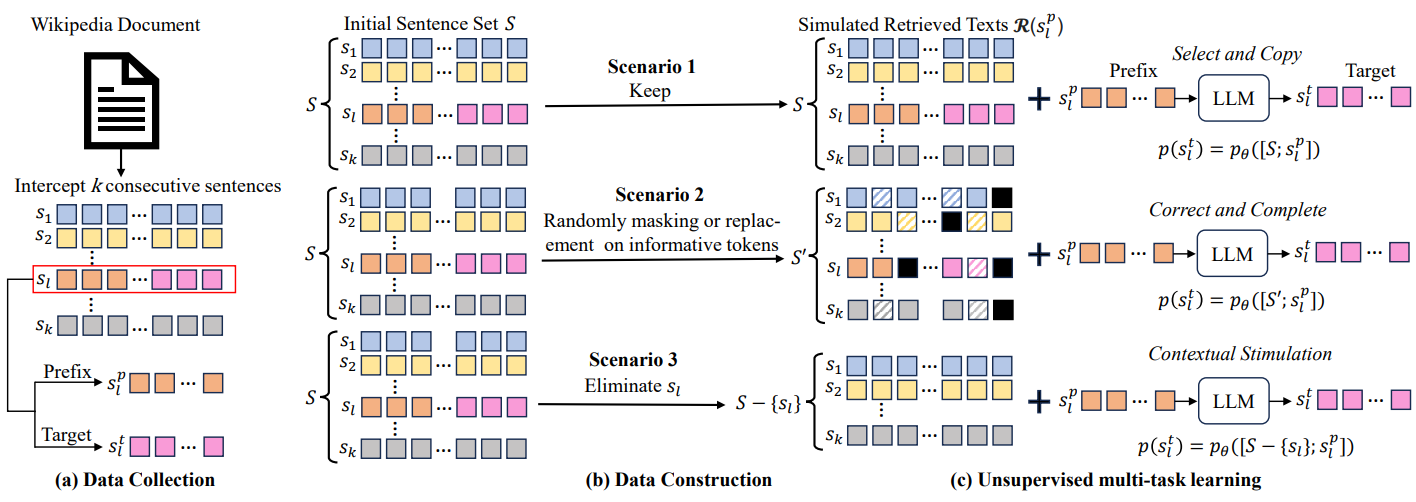
创新点:
-
介绍了一种新的角度来重新评估LLMs在RAG系统中的作用,将LLMs视为"信息精炼器",能够在RAG场景中产生积极的信息增益。
-
提出了一种基于无监督训练的方法,将预训练的LLMs作为"信息精炼器"来训练,从而改善RAG的信息瓶颈,并使其能够从复杂文本中提取正确信息并抵制和纠正错误信息和噪声。
关注下方《学姐带你玩AI》🚀🚀🚀
回复“大模型RAG”获取全部论文+开源代码
码字不易,欢迎大家点赞评论收藏



















