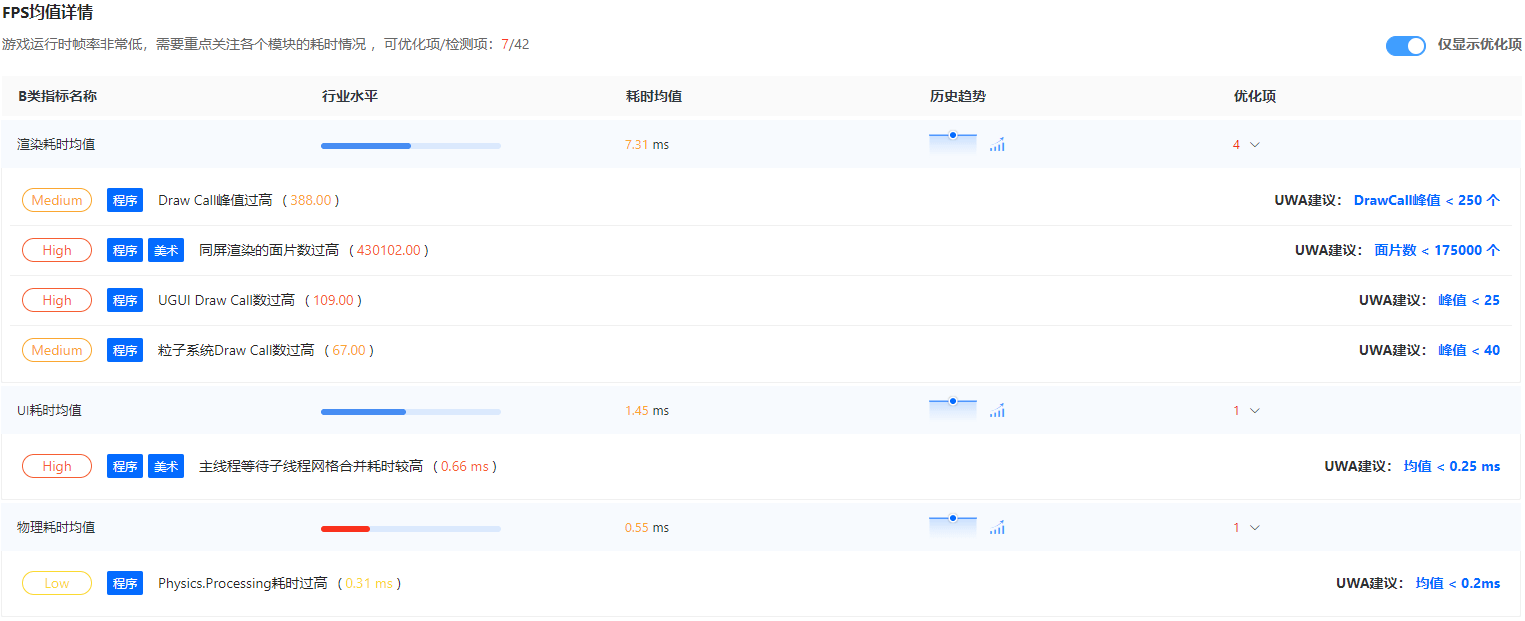
文章目录
- 综合实践三 基于深度残差神经网络的皮肤癌检测
- 实现步骤1:图像数据预处理
- 实现步骤2:模型构建
- 实现步骤3:性能度量
- 提交要求
- 1 基于深度残差神经网络的皮肤癌检测代码
- 2 结果分析
综合实践三 基于深度残差神经网络的皮肤癌检测
皮肤镜图像是检查皮肤癌黑色素瘤的主要手段。本实践项目通过构建深度残差神经网络提取皮肤镜图像的高维特征,使用残差学习防止网络梯度退化,降低网络训练的难度,实现黑色素瘤的有效识别。
实践项目所使用的数据集由多名患者的皮肤癌组织纤维图像组成,分为训练集和预测集,每部分包含良性(benign,标签定义为1)和恶性(malignant,标签定义为0)两种。
请将皮肤癌组织显微图像进行预处理,并在处理后的数据集基础上,运用基于深度残差神经网络模型对训练集进行训练,并对测试集进行预测。
实现步骤1:图像数据预处理
- 安装
Pillow,numpy,scikit-learn,keras,tensorflow和matplotlib库; - 对图像数据进行归一化和格式转换。将“jpg”图像传输到数组
IMG,并将所有数据转换成矩阵形式; - 定义标签,良性定义标签为 1,恶性定义标签为 0;
- 分别合并训练集和测试集中的良性肿瘤数据和恶性肿瘤数据;
实现步骤2:模型构建
- 使用 Keras 库中的
ImageDataGenerator()函数进行数据增强; - 读取预处理后的图像,划分训练集和测试集;
- 使用
Sequential()建立模型,并进行模型训练; - 使用测试数据对模型进行测试;
- 对模型进行评估;
实现步骤3:性能度量
- 绘制模型精度折线图,查看训练效果;
- 输出显示恶性的预测结果前 8 个图像;
- 输出显示良性的预测结果前 8 个图像;
提交要求
- 提交实现本实践任务的所有代码(可执行,非.doc、.txt 等文本格式);
- 提交综合实践任务书(word 格式),包括小组成员分工、分析目的、数据预处理、算法介绍、结果分析等内容;
- 提交“四、性能度量”中 2 和 3 输出的图像;
1 基于深度残差神经网络的皮肤癌检测代码
在虚拟环境下进行该任务--基于深度残差神经网络的皮肤癌检测
anaconda下的虚拟环境,python版本是3.10
我的虚拟环境路径: D:\envs\miniconda\envs\cancer_detection
conda create -n cancer_detection python=3.10
conda activate cancer_detection
conda deactivate
安装要使用的包
pip install Pillow numpy scikit-learn keras tensorflow matplotlib
import time
from keras.src.layers import Conv2D, MaxPooling2D, Flatten, Dense
from keras import Sequential, Input
import os
from PIL import Image
import numpy as np
from sklearn.model_selection import train_test_split
from keras.src.optimizers import Adam
from keras.src.legacy.preprocessing.image import ImageDataGenerator
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score, confusion_matrix
import matplotlib.pyplot as plt
# 显示中文
plt.rcParams['font.sans-serif'] = ['SimHei']
# 显示负号
plt.rcParams['axes.unicode_minus'] = False
# 从指定的文件夹中加载图像
def load_images_from_folder(folder, class_name):
jpg_path = os.path.join(folder, class_name) #data/train/benign
images = []
# 添加计数器
count = 0
#遍历指定路径下的所有文件名
for filename in os.listdir(jpg_path):
img = Image.open(os.path.join(jpg_path, filename)) #224*224
if img is not None:
img = np.array(img) / 255.0 # 归一化,将图像像素值归一化到0-1
images.append(img)
count += 1 # 更新计数器
return images, count
# 训练集文件夹路径 测试集文件夹路径
train_folder = "data/train"
test_folder = "data/test"
# 第一个类别名称 # 第二个类别名称
class1_name = "benign"
class2_name = "malignant"
train_class1_images, train_class1_count = load_images_from_folder(train_folder, class1_name)
train_class2_images, train_class2_count = load_images_from_folder(train_folder, class2_name)
test_class1_images, test_class1_count = load_images_from_folder(test_folder, class1_name)
test_class2_images, test_class2_count = load_images_from_folder(test_folder, class2_name)
print("类别 {} 的训练集图像数目: {}".format(class1_name, train_class1_count))
print("类别 {} 的训练集图像数目: {}".format(class2_name, train_class2_count))
print("类别 {} 的测试集图像数目: {}".format(class1_name, test_class1_count))
print("类别 {} 的测试集图像数目: {}".format(class2_name, test_class2_count))
类别 benign 的训练集图像数目: 1440
类别 malignant 的训练集图像数目: 1197
类别 benign 的测试集图像数目: 360
类别 malignant 的测试集图像数目: 300
# 定义标签
train_class1_labels = np.ones(len(train_class1_images))
train_class2_labels = np.zeros(len(train_class2_images))
test_class1_labels = np.ones(len(test_class1_images))
test_class2_labels = np.zeros(len(test_class2_images))
# 合并训练集和测试集的图片和标签
benign_images = np.concatenate((train_class1_images, test_class1_images)) #训练集和验证集中的良性图片
benign_labels = np.concatenate((train_class1_labels, test_class1_labels))
malignant_images = np.concatenate((train_class2_images, test_class2_images)) #训练集和验证集中的恶性图片
malignant_labels = np.concatenate((train_class2_labels, test_class2_labels))
#查看合并后的图像数量
total_benign_images = benign_images.shape[0]
total_malignant_images = malignant_images.shape[0]
print("合并后的良性图片数量:", total_benign_images)
print("合并后的恶性图片数量:", total_malignant_images)
print("benign_labels的数量:", benign_labels.shape[0])
print("malignant_labels的数量:", malignant_labels.shape[0])
合并后的良性图片数量: 1800
合并后的恶性图片数量: 1497
benign_labels的数量: 1800
malignant_labels的数量: 1497
# 划分训练集和测试集
X = np.concatenate((benign_images, malignant_images))
y = np.concatenate((benign_labels, malignant_labels))
# 输出X的数量
print("X的数量:", X.shape[0])
# 输出y的数据量
print("y的数据量:", y.shape[0])
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
X的数量: 3297
y的数据量: 3297
# 开始计时
start_time = time.time()
#简单的卷积神经网络(CNN)模型
input_shape = (224, 224, 3)
model = Sequential()
model.add(Input(shape=input_shape))
model.add(Conv2D(32, (3, 3), activation='relu'))
model.add(MaxPooling2D((2, 2)))
model.add(Flatten())
model.add(Dense(64, activation='relu'))
model.add(Dense(10, activation='softmax'))
input_data = np.random.rand(1, 224, 224, 3)
output = model(input_data)
# 编译模型,Adam优化器的默认学习率通常是0.001
model.compile(optimizer=Adam(), loss='sparse_categorical_crossentropy', metrics=['accuracy'])
#使用Adam优化器、稀疏类别交叉熵损失函数和准确率评估指标来编译模型
# 定义数据增强操作
datagen = ImageDataGenerator(
rotation_range=20, # 随机旋转角度范围(0~20度)
width_shift_range=0.1, # 水平平移范围(相对于总宽度的比例)
height_shift_range=0.1, # 垂直平移范围(相对于总高度的比例)
horizontal_flip=True, # 随机水平翻转
)
# 使用数据增强生成器对训练数据进行增强,并设置批量大小为32
train_generator = datagen.flow(X_train, y_train, batch_size=32) #32
# 使用增强后的数据训练模型,共进行10个周期的训练
history = model.fit(train_generator, epochs=10)
# # 使用测试数据对模型进行测试
y_pred = model.predict(X_test)
#每一行代表一个样本的预测概率分布,沿着每一行(即每个样本)寻找最大值的索引
y_pred_classes = np.argmax(y_pred, axis=1)
# 结束计时
end_time = time.time()
# 计算和输出所花费的时间
elapsed_time = end_time - start_time
print(f"进程完成所需时间: {elapsed_time:.2f} 秒")
83/83 ━━━━━━━━━━━━━━━━━━━━ 39s 421ms/step - accuracy: 0.5926 - loss: 12.5544
Epoch 2/10
83/83 ━━━━━━━━━━━━━━━━━━━━ 34s 383ms/step - accuracy: 0.7577 - loss: 0.4838
Epoch 3/10
83/83 ━━━━━━━━━━━━━━━━━━━━ 33s 383ms/step - accuracy: 0.7646 - loss: 0.4563
Epoch 4/10
83/83 ━━━━━━━━━━━━━━━━━━━━ 32s 364ms/step - accuracy: 0.7697 - loss: 0.4524
Epoch 5/10
83/83 ━━━━━━━━━━━━━━━━━━━━ 32s 369ms/step - accuracy: 0.7690 - loss: 0.4457
Epoch 6/10
83/83 ━━━━━━━━━━━━━━━━━━━━ 32s 374ms/step - accuracy: 0.7890 - loss: 0.4195
Epoch 7/10
83/83 ━━━━━━━━━━━━━━━━━━━━ 32s 368ms/step - accuracy: 0.7764 - loss: 0.4321
Epoch 8/10
83/83 ━━━━━━━━━━━━━━━━━━━━ 32s 369ms/step - accuracy: 0.7921 - loss: 0.4323
Epoch 9/10
83/83 ━━━━━━━━━━━━━━━━━━━━ 37s 428ms/step - accuracy: 0.7821 - loss: 0.4326
Epoch 10/10
83/83 ━━━━━━━━━━━━━━━━━━━━ 34s 391ms/step - accuracy: 0.7929 - loss: 0.4186
21/21 ━━━━━━━━━━━━━━━━━━━━ 1s 49ms/step
进程完成所需时间: 349.87 秒
# 计算评估指标
accuracy = accuracy_score(y_test, y_pred_classes)
precision = precision_score(y_test, y_pred_classes, average='weighted') #计算加权平均值
recall = recall_score(y_test, y_pred_classes, average='weighted')
f1 = f1_score(y_test, y_pred_classes, average='weighted')
confusion = confusion_matrix(y_test, y_pred_classes)
print('Accuracy:', accuracy)
print('Precision:', precision)
print('Recall:', recall)
print('F1 Score:', f1)
print('Confusion Matrix:', confusion)
# 保存数据
if not os.path.exists('./结果分析'):
os.makedirs('./结果分析')
with open('./结果分析/计算评估指标.txt', 'a') as f:
f.write('计算评估指标\n')
f.write(f'Accuracy: {accuracy}\n')
f.write(f'Precision: {precision}\n')
f.write(f'Recall: {recall}\n')
f.write(f'F1 Score: {f1}\n')
f.write(f'Confusion Matrix: {confusion}\n')
Accuracy: 0.8106060606060606
Precision: 0.8103019434437978
Recall: 0.8106060606060606
F1 Score: 0.8094419197353939
Confusion Matrix: [[211 74]
[ 51 324]]
# 提取训练精度和验证精度数据
train_accuracy = history.history['accuracy']
loss = history.history['loss']
# 绘制精度折线图
plt.plot(train_accuracy, label='Training Accuracy')
plt.plot(loss, label='loss')
plt.title('Model Accuracy')
plt.ylabel('Accuracy')
plt.xlabel('Epoch')
plt.ylim(0, 1)
plt.legend()
plt.savefig('./结果分析/Model Accuracy.png')
plt.show()

# 预测结果数组 y_pred_classes 中找出所有预测为恶性(值为0)的索引,然后取前8个索引。
malignant_pred_indices = np.where(y_pred_classes == 0)[0][:8]
# 使用这些索引从测试数据集 X_test 中提取对应的图像数据
malignant_pred_images = X_test[malignant_pred_indices]
# 在一个2x4的子图网格中显示恶性预测图像。
for i, image in enumerate(malignant_pred_images): # 遍历恶性预测图像列表,同时获取每个图像及其索引。
plt.subplot(2, 4, i + 1) #创建一个2行4列的子图网格,并将当前图像放置在子图中
plt.imshow(image.squeeze(), cmap='gray') #灰度颜色映射显示图像,移除单维度条目,确保图像数据的形状正确
plt.axis('off')
plt.title(f'Malignant {i + 1}') #为当前子图设置标题
plt.savefig('./结果分析/恶性预测结果.png')
plt.show()

# 获取良性预测结果前8个图像的索引
benign_pred_indices = np.where(y_pred_classes == 1)[0][:8]
# 获取良性预测结果前8个图像
benign_pred_images = X_test[benign_pred_indices]
# 显示良性预测结果前8个图像
for i, image in enumerate(benign_pred_images):
plt.subplot(2, 4, i + 1)
plt.imshow(image.squeeze(), cmap='gray')
plt.axis('off')
plt.title(f'Benign {i + 1}')
plt.savefig('./结果分析/良性预测结果.png')
plt.show()

2 结果分析
1.任务分工
2.分析目的
通过构建神经网络提取皮肤镜图像的高维特征,实现黑色素瘤的有效识别。
3.数据预处理
(1)格式转换
使用np.array(img),将“jpg” 图像传输到阵列 IMG,并将所有数据转换成矩阵形式
(2)对图像数据进行归一化
使用np.array(img) / 255.0,将每个像素值除以255.0,可以将像素值缩放到0到1之间的范围,实现归一化
(3)定义标签, 良性定义标签为 1, 恶性定义标签为 0;
train_class1_labels = np.ones(len(train_class1_images))
创建一个长度为与良性类别图像数目等同的数组,数组中的所有元素都为1。这表示良性肿瘤数据中的所有图像都属于类别1,良性定义标签为 1;
train_class2_labels = np.zeros(len(train_class2_images))
创建一个长度为与恶性类别图像数目等同的数组,数组中的所有元素都为0。这表示恶性肿瘤数据中的所有图像都属于类别0,恶性定义标签为 0。
(4)分别合并训练集和测试集中的良性肿瘤数据和恶性肿瘤数据
benign_images = np.concatenate((train_class1_images, test_class1_images))
benign_labels = np.concatenate((train_class1_labels, test_class1_labels))
将原数据集中分别属于训练集和测试集的同类别数据进行组合,即两个数组按照它们的第一个维度(通常是行)进行拼接,得到完整的良性肿瘤数据集和恶性肿瘤数据集,其对应标签同样方式进行组合,保证图片与标签的类别对应关系。
4.算法介绍
建立一个简单的卷积神经网络模型,其中包括:
- 输入层:input_shape = (224, 224, 3)定义了输入图像的形状,其中224x224是图像的宽度和高度,3是图像的通道数(通常对应于RGB三个颜色通道)。
- 模型构建:使用Sequential()创建了一个序列化的模型,然后通过.add()方法依次添加各个层。
- Conv2D(32, (3, 3), activation=‘relu’):添加了一个卷积层,有32个过滤器,每个过滤器的大小为3x3,激活函数为ReLU。
- MaxPooling2D((2, 2)):添加了一个最大池化层,池化窗口大小为2x2。
- Flatten():将多维的卷积层输出展平为一维,以便连接到全连接层。
- Dense (64, activation=‘relu’):添加了一个全连接层,有64个神经元,激活函数为ReLU。
- Dense(2, activation=‘softmax’):添加了另一个全连接层,作为输出层,有2个神经元(对应于2个类别),激活函数为softmax,用于多分类任务。
5.结果分析
(1)模型精度折线图
见上图
模型采用Adam优化器,sparse_categorical_crossentropy损失函数,训练10轮,根据图像可以看出模型损失函数逐渐下降,准确率逐渐上升。
(2)评价指标结果
- 准确率(Accuracy):0.8257575757575758,表示模型预测正确的样本占总样本的比例为82.58%。这是一个相对较高的准确率,说明模型在大多数情况下能够正确预测。
- 精确率(Precision):0.8256871986269648,表示模型预测为正例的样本中真正为正例的比例为82.57%。精确率关注的是模型预测为正例的准确性,较高的精确率意味着模型预测出的正例中错误的可能性较低。
- 召回率(Recall):0.8257575757575758,表示实际为正例的样本中被模型正确预测为正例的比例为82.58%。召回率关注的是模型能够找出所有正例的能力,较高的召回率意味着模型能够识别出更多的真实正例。
- F1 Score:0.8257204698469889,F1 Score是精确率和召回率的调和平均值,用于综合评价模型的性能。较高的F1 Score意味着模型在精确率和召回率之间取得了较好的平衡
(3)混淆矩阵
Confusion Matrix: [[256 29]
[ 87 289]]
含义如下:
- 第一行第一列(256):表示实际为正类且被模型正确预测为正类的数量。
- 第一行第二列(29):表示实际为正类但被模型错误预测为负类的数量(即假阴性,Type I错误)。
- 第二行第一列(87):表示实际为负类但被模型错误预测为正类的数量(即假阳性,Type II错误)。
- 第二行第二列(289):表示实际为负类且被模型正确预测为负类的数量。
每次运行会有小差异
计算评估指标
Accuracy: 0.8257575757575758
Precision: 0.8395988183724034
Recall: 0.8257575757575758
F1 Score: 0.8265118719664174
Confusion Matrix: [[256 29]
[ 86 289]]
计算评估指标
Accuracy: 0.8106060606060606
Precision: 0.8103019434437978
Recall: 0.8106060606060606
F1 Score: 0.8094419197353939
Confusion Matrix: [[211 74]
[ 51 324]]
(4)输出显示恶性的预测结果前 8 个图像
见上文
(5)输出显示良性的预测结果前 8 个图像
见上文