关联比赛: 第二届数据库大赛—Tair性能挑战
赛题分析
赛题要求实现一个基于persistent memory(AEP)的持久化键值存储系统,并要求从数据正确性和系统读写性能两个方面来考虑系统设计。
正确性
数据正确性包括数据写入的持久性和原子性两个方面。
持久性
系统需要保证在写操作成功返回后数据不会丢失。这部分较为简单,我们使用memcpy()向AEP写入键值对,只需要在写入地址调用pmem_persist()即可保证数据的持久化。在每次系统启动时可以扫描AEP上持久化的键值对建立数据索引,确保数据不会丢失。
原子性
系统需要保证数据的写入要么成功,要么丢弃,不能读到不正确的数据。由于AEP内部仅保证8B大小的原子更新,若系统在向AEP写入键值对的过程中断电,可能存在仅部分数据被写入的情况,因此系统需要在重启时发现并丢弃这部分未写完的数据。
一种保证原子写入的方式是在每个键值对末尾追加一个tag表示写入完成。但是,由于CPU对指令的乱序执行,若将tag和键值对一起写入AEP并持久化,可能出现的一种情况是tag先于键值对落盘,因此需要在持久化键值对后再发起一次独立的写操作来写入tag,这样需要调用两次pmem_persist()。通过实验我们发现这种方法写入tag的性能开销较大,因此弃用了该方案,转用checksum在重建数据索引时检测数据的正确性。
性能
性能测试分为纯写和读写混合两个阶段,均由16个线程并发发起请求,其中读写混合阶段会存在较多热点访问。
为了有效释放AEP的性能,我们主要围绕着以下两点设计系统:
-
尽量保证对AEP的顺序写入。AEP内部的最小存取单位为256B,因此顺序写可以有效减少写放大,性能优于随机写。
-
减少线程间资源竞争。AEP有较高的带宽和较低的延迟,此时CPU开销很容易成为性能瓶颈,其中线程间的资源竞争对性能的影响尤其明显。因此我们尽可能让各线程独占所需资源来降低线程同步开销和CPU等待时间。
针对热点访问,我们尝试了使用DRAM做数据缓存,但是我们发现仅L3 cache便能缓存大量热点数据,同时AEP的读延迟与DRAM相比差距也较小,使用DRAM缓存键值对并无明显效果,因此最终仅使用DRAM缓存了部分数据索引信息。
最后,写操作中含有较多数据更新,同时value大小存在变化。由于赛题存在严格的空间限制,如何高效利用存储空间也需要纳入考虑。
系统设计
整体架构
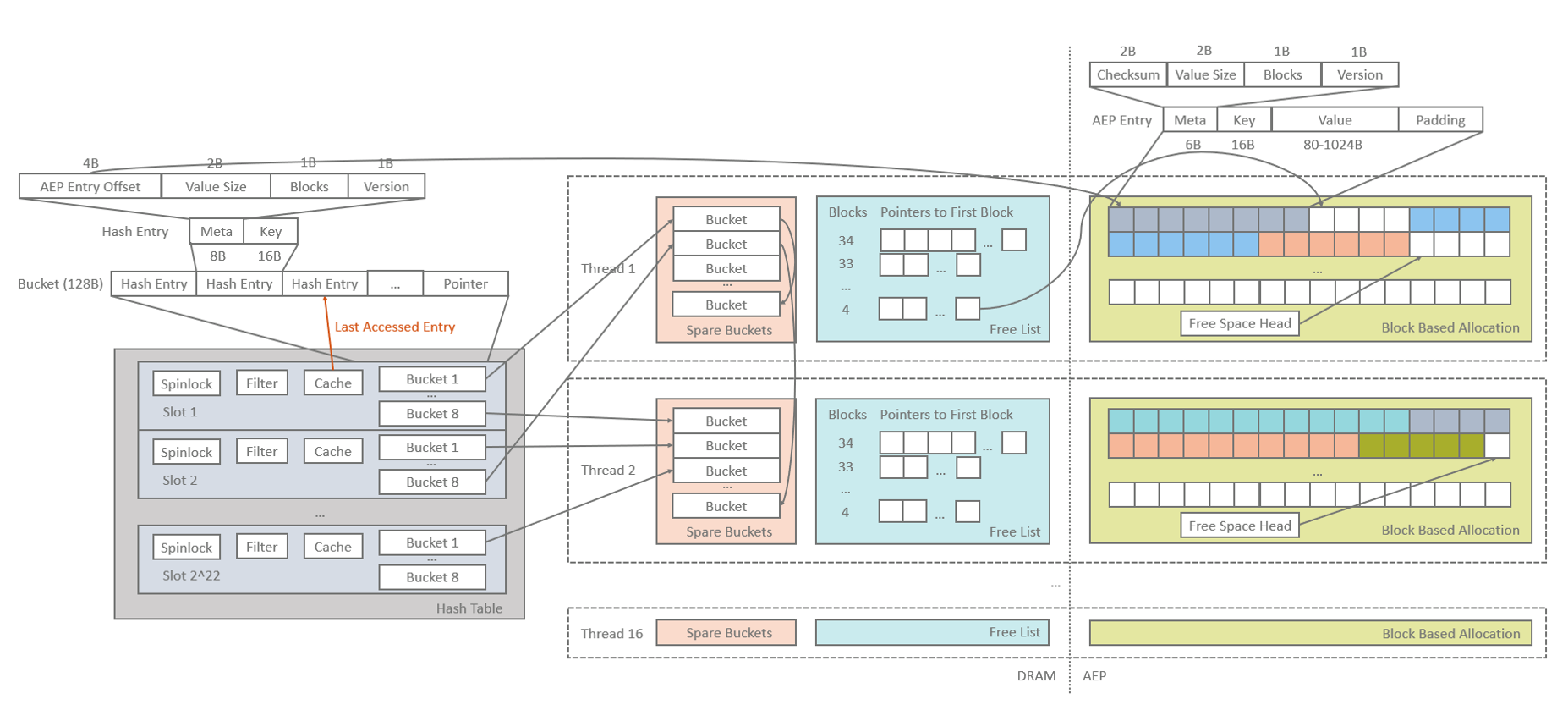
基于上述分析,我们设计了下图所示的系统架构。系统由AEP和DRAM两部分组成,分别存储键值数据和管理索引等元数据信息。AEP在程序中被映射为一大块内存空间,我们以block为单位分配这部分空间,并在DRAM中以Free List结构管理键值对更新后释放的空间。数据索引为Hash Table结构,采用数组+链表结合的设计,该hash table可以无锁进行并发读访问,同时写操作以粒度较小的hash分片(slot)加锁,每个分片还包含bloom filter和hash cache来加速索引数据的写入和查询。
所有在运行时分配的DRAM和AEP空间均按写入线程分组,每个写线程独占一组空间,确保没有资源竞争。
下面详细介绍我们对存储和索引部分的设计。
存储设计
如前文所述,为了方便对AEP空间的管理,我们将AEP空间切分为若干32字节的block,并以block作为空间分配的最小单位。从程序的角度看,AEP空间以mmap的方式映射为一大块内存空间,我们将该空间均分成16组,每个写入线程独占一组空间,以消除线程同步开销。每组空间的管理分为下图所示两部分:
-
Block based allocation。Block是AEP空间的最小分配单位,线程在写入键值对时根据键值数据的大小向上取整分配block。为了充分利用AEP的顺序写性能,无论是写入新键值对还是更新已有键值对,均优先以追加的形式写入(Free Space Head),被更新的键值对将其占用的block记录到Free list中,仅当尾部空间用尽后才开始从Free List中分配空间。
-
Free list。Free list保存在DRAM中,是一组空闲空间链表,记录了被更新的value释放的空间。每个链表保存某一固定大小可用空间的地址(即n个连续的空闲block)。从free list中为键值对分配空间时,我们不对分配的空间做切分,以减少空间的管理开销。为了缓解因此引发的内部碎片问题,我们在分配空间时采用best fit策略,从最小的free list开始搜索。
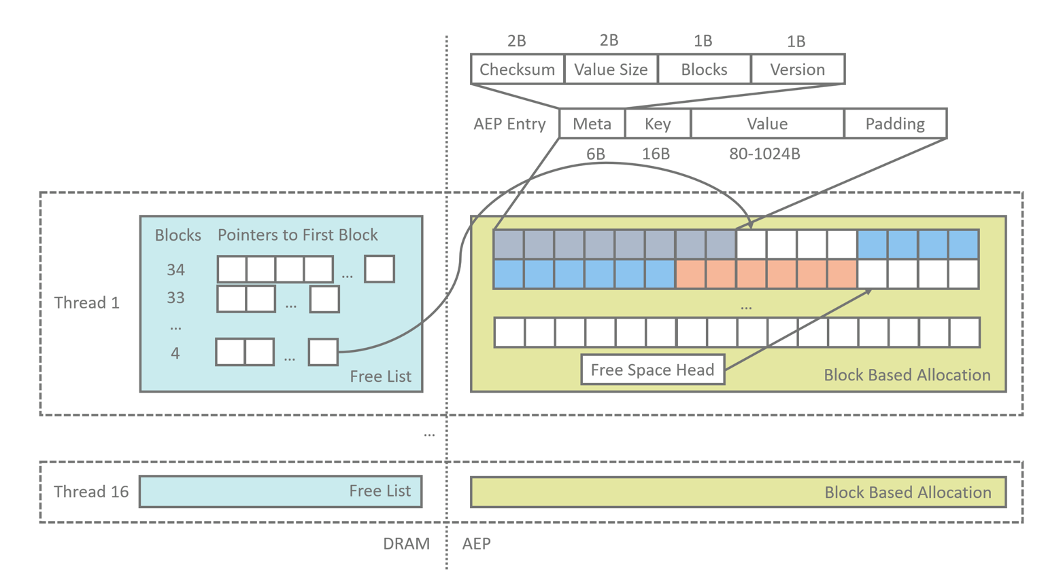
写入AEP的数据记录由键值对本身以及相关元数据组成,元数据包括:
-
Checksum,用于在数据重建阶段判断键值对是否有效
-
Value size,即value的实际大小
-
Blocks,上文提到我们不对free list分配的空间做切分,因此用该项元数据记录实际占用的block数量
-
Version,该键值对的版本号,用于系统重启时的索引重建
数据写入流程的介绍见后文读写流程部分。
索引设计
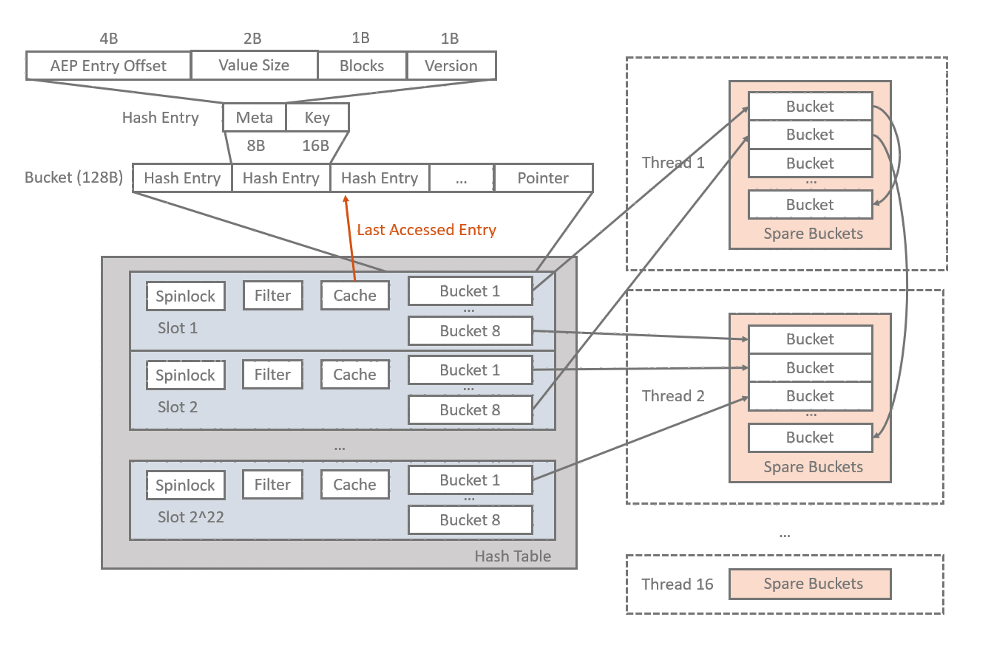
系统的索引部分是一个hash table,其中每个hash entry维护key和value在AEP中的地址信息(Meta),包括:
-
AEP entry offset,表示value所在block在AEP空间中的偏移量
-
Value size,表示value的实际大小
-
Blocks,表示实际为value分配的block数量
-
Version,表示索引的value的版本号,用于系统重启时的索引重建
Hash table采用数组加链表的设计。每个Hash bucket是一个hash entry的数组,数组大小可调整,这样能更高效地利用CPU cache。我们在系统启动时直接分配出8GB内存用于存储Hash table,其中4GB根据bucket大小存储连续的2^n个bucket,键值对根据key的hash值低n位决定其所在的bucket。剩余4GB作为spare空间,当某bucket被写满后,从spare空间中分配一个新的bucket,与前面的bucket组成链表。这种按需分配空间的链表结构能有效避免hash不均匀引起的空间浪费。
类似于对AEP空间的管理,我们将spare空间同样均分成16份由写线程独占,消除空间分配的线程同步开销。
该Hash table可以保证读操作的无锁访问,但是写操作仍是互斥的,因此需要以较小的粒度加锁来减少对锁的争用。然而,如果为每个bucket都分配一个独立的锁则内存开销太高。因此,我们将连续的若干bucket组成一个分片(slot),并以slot为粒度加锁。Slot包含以下部分:
-
Spinlock,使用spinlock避免内核态/用户态之间的切换开销
-
Filter,在读写索引时使用bloom filter快速判断key是否存在,在写索引时若发现key不存在则可以跳过对bucket的查询,直接将索引插入到bucket末尾
-
Cache,指向最后访问的hash entry,加速对热点的数据访问
索引重建
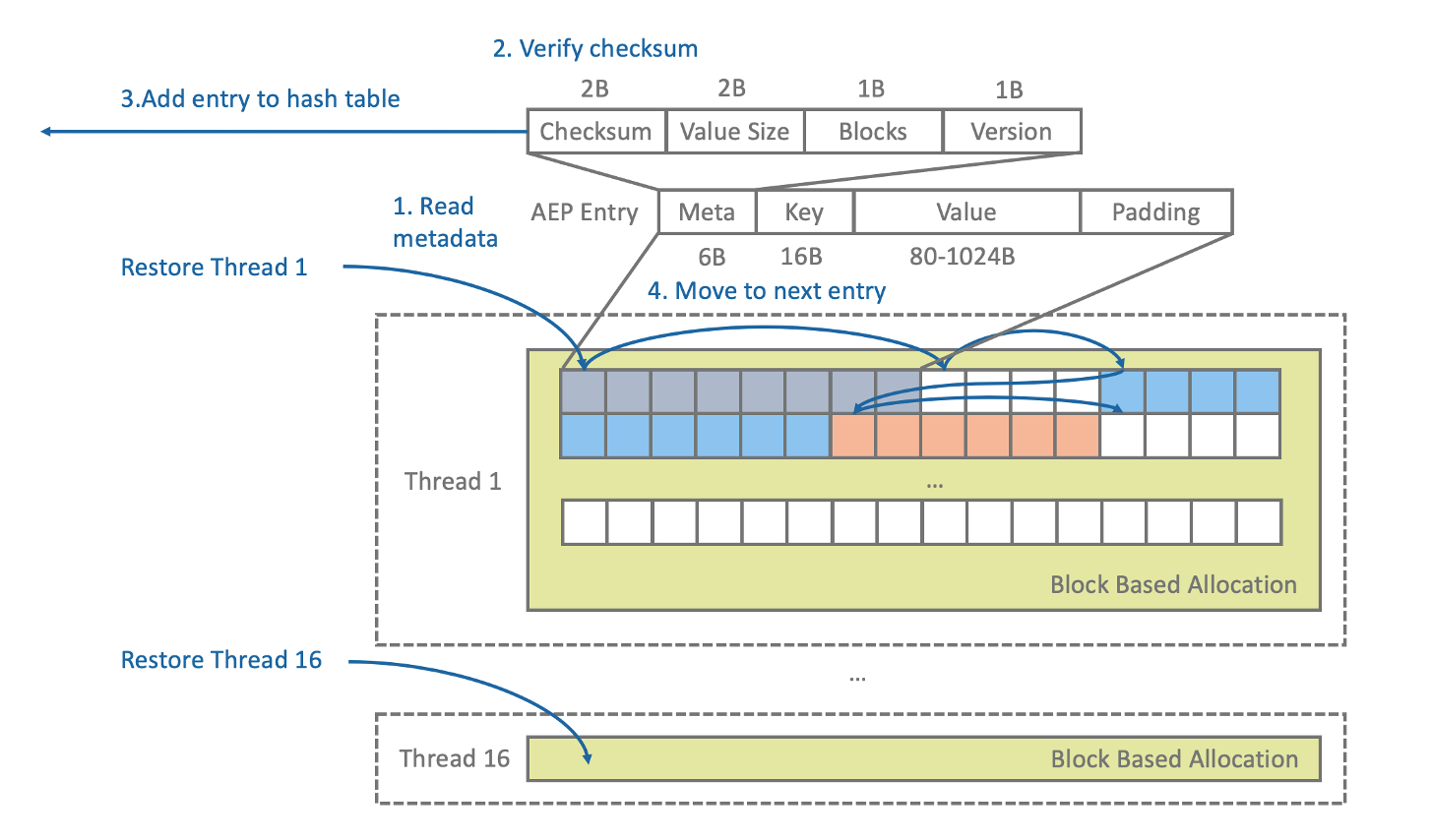
在每次系统重启后,我们用多个线程遍历AEP上的键值对来重建索引。由于在AEP上记录有每个键值对实际分配的block数量,因此很容易找到下一个键值对的起始偏移量。对每个键值对,首先重新计算checksum,与AEP上记录的checksum做对比判断其有效性,然后将有效键值对的索引写入Hash table。
由于我们在写操作中会重复利用被释放的空间,因此在遍历时可能存在较新版本的键值对先于旧版本键值对出现,我们在遇到重复键值对时通过对比数据记录与hash entry中的version信息来分辨其版本新旧,决定是否覆盖已写入的索引,并将旧版本键值对占据的空间记录到free list中。
读写流程
下面介绍数据读写流程。
-
读流程。读操作比较简单,首先计算key的hash值,根据对应slot的filter判断key是否存在,若不存在则直接返回。若存在,则查看cache中是否记录有当前key的hash entry,若否,则从bucket中搜索该key的hash entry,然后根据hash entry记录的地址信息从AEP读取数据,并更新cache。
-
写流程。写操作首先计算键值数据的checksum以及key的hash值,然后从线程对应的AEP分组中申请空间。接着,搜索Hash table获得hash entry的写入位置,搜索时首先对键值对所属slot加锁,然后通过filter查看key是否在对应bucket中存在,若不存在则直接将写入位置设为bucket链表的末尾,否则逐个从bucket中查找该key的hash entry记为写入位置。在写入新的entry时若发现bucket已满,则从线程对应的spare空间中分配一个新的bucket,将地址指针记录在前一bucket的末尾。在搜索hash table后,我们可以根据hash entry得到当前键值对的version,将当前version+1作为最新version,将其连同checksum、value大小以及分配的block数量记录到键值对的meta信息中,接着将meta信息和键值对一起写入AEP,最后向hash table的写入位置更新hash entry。注意我们对hash table的写入是最后进行的,因此可以确保读操作不会读到错误的数据。
细节优化
以上是对系统主要部分的介绍,除此以外我们还做了一些细节上的优化,包括内存页预读,缓存预取以及快速内存拷贝。
- 内存页预读。由于PMEM是以内存映射的方式访问的,在系统初始化后写操作会产生较多的page fault,存在一定性能开销。因此,我们在系统初次启动的初始化阶段提前访问整个PMEM空间,避免运行时产生page fault。
for (int i = 0; i < THREAD_NUM; i++) {
ths_init.emplace_back([=]() {
memset_movnt_sse2_clflushopt(aep_value_log_ + (uint64_t)i * PMEM_SIZE / THREAD_NUM,
0, PMEM_SIZE / THREAD_NUM);
}
- 缓存预取。我们令hash bucket大小与cache line大小对齐,在搜索hash table时使用_mm_prefetch()命令提前将下一块bucket预取到cache中,以加速查询速度。
_mm_prefetch(&hash_cache_[slot], _MM_HINT_T0);
...
_mm_prefetch(bucket_base, _MM_HINT_T0);
_mm_prefetch(bucket_base + 64, _MM_HINT_T0);
...
- 快速内存操作。系统中大量数据与元数据的写入和比较都是以memcpy/memcmp进行的,为了优化执行速度,我们针对不同大小数据的内存操作做了不同的实现。对于固定大小的小数据如key(16B),使用sse指令优化,并取得了一定效果;对于较大的数据如value,我们尝试了使用avx指令作优化,但是效果并不明显,因此在最终版本中没有采用。
inline int memcmp_16(const void *a, const void *b) {
register __m128i xmm0, xmm1;
xmm0 = _mm_loadu_si128((__m128i *)(a));
xmm1 = _mm_loadu_si128((__m128i *)(b));
__m128i diff = _mm_xor_si128(xmm0, xmm1);
if (_mm_testz_si128(diff, diff))
return 0; // equal
else
return 1; // non-equal
}
inline void memcpy_16(void *dst, const void *src) {
__m128i m0 = _mm_loadu_si128(((const __m128i *)src) + 0);
_mm_storeu_si128(((__m128i *)dst) + 0, m0);
}
总结
上述系统最终成绩为38.3秒,其中写阶段为29秒,读写混合阶段为9.3秒。我们介绍了所做的各类优化,但是其中一些优化,比如Bloom filter的引入并没有带来期望的性能提升,还需进一步思考。此外,我们仅利用了CPU的L3 cahe来缓存热点数据,至于在DRAM中缓存数据,我们仅在实现读无锁前进行了测试,得到了对性能没有提升的结论,在引入无锁操作后或许会更加有效,但是由于时间关系最后没有尝试。
通过本次比赛,我们对AEP的性能特征有了更好的了解,如果未来还有类似机会,希望能取得更好的成绩。
查看更多内容,欢迎访问天池技术圈官方地址:tair性能挑战赛攻略心得-Zzzzz_天池技术圈-阿里云天池