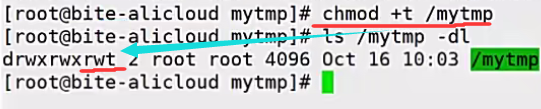
[pdf | code | proj]

- LRM能否用于3D数字人重建?问题在于:1)缺少3D数字人数据;2)重建任意姿态的3D数字人不利于后续绑定和驱动。
- 构建3D数字人数据集:在VRoidHub上采集数据,得到13746个风格化角色,分别渲染固定视角和固定标准姿态下的图片和随机角度和姿态下的图片,用以训练以图片为条件的多角度扩散模型。
- 映射到标准姿态:输入一张任意姿态的人像图片,首先生成标准姿态下的四角度图片,其次重建3D角色(微调LRM,Large Reconstruction Model),最后通过Auto-Rigging等操作实现3D角色的驱动。
方法
Anime3D Dataset
- 从VRoidHub上收集了14500动漫角色,去除非人数据,剩下13746个角色模型。
- 使用threevrm渲染角色。包含:标准姿态(A-pose)和随机姿态。其中,随机姿态包含从Mixamo中获取的10个人体骨架,例如:坐、唱、走等,同时会随机更改嘴巴、眼睛以产生新表情。
- 训练阶段,使用4个标准姿态图片{0, 90, 180, 270}和1个随机姿态图片{-90, 90}作为训练对。

Multi-view Image Generation and Pose Canonicalization

- 目标是输入任意姿态下的正面图片,输出标准姿态下的四个正交角度图片。
- 本文认为IP-Adaptor使用CLIP图片特征,无法细粒度描述人物纹理细节。因此,本文提出IDUNet,将参考图片patch-level的纹理特征嵌入到去噪过程中。
- 具体来说,Multi-view UNet与MVDream类似,在Multiview SelfAttn中,四个视角特征交互。在CrossAttn中,ID和CLIP-encoded image features合并作为K和V,四个视角作为Q:

- 同时,本文使用OpenPose,通过Pose Encoder得到的编码直接加到latent noise上。
-
3D Character Generation

- 微调LRM。LRM使用NeRF,从NeRF中提取的几何表面噪声多。类似Magic3D,本文使用两阶段微调策略:1)训练triplane-NeRF,生成角色的粗几何和外观。2)更改重建网络的解码器为预测singed distance functions (SDFs)。
- 除了MSE loss,本文还使用mask loss(BCE损失监督Alpha通道,产生干净背景)和LPIPS loss:

- Extract Mesh & UV unwrap:使用DMTet从tri-plane中提取mesh和粗UV map。在提取mesh上使用Laplacian Smooth,减少表面噪声。
- DMTet:使用四面体表征3D。四面体上顶点具有可学习特征,预测偏移量和是否在物体内部。如果四面体所有顶点都不在物体内部则会被去除,如果存在部分顶点在物体内部,则根据规则分裂四面体,以逐步精细化。在构建好DMTet后,则可根据顶点是否在物体内部提取Mesh表面。
- UV map:对于Mesh,每个顶点都会保存UV map坐标,用于获取颜色。UV unwrap用于将3D模型颜色投影到uv map上。
- Normal map:对于Mesh,每个顶点会保存三维的法向量值,表征光线的反射,用于在平面上模拟细节纹理。
- Texture Aggregation:直接提取的UV map效果不佳,本文进一步使用生成的四角度图片改善纹理。本文使用NvDiffRast作为渲染器。将四张图片反投影回纹理空间,使用泊松混合将反投影纹理图和粗纹理图混合得到最终的纹理图。在反投影过程中,使用normal map和相机视角做内积,去除内积大于-0.2的点,即将不合理的反投影点去除掉。
实验
- 训练时间:多视角扩散模型在8卡A800上训练5天;LRM在8卡A800上微调1天。
- 数据集划分:训练集测试集50:1。
2D Multi-view Generation


3D Character Generation

Comparision with IP-Adapter

Generation Speed

User Study

Ablation Study
IDUNet是否需要训练?需要

是否需要Pose Embedding Network?需要

是否需要A-pose?需要

应用
- 使用AccuRig绑定,使用Warudo渲染












![[mysql]mysql排序和分页](https://i-blog.csdnimg.cn/direct/5177960b2c45494b854c1548bec698c4.png)