昨天给大家分享了:如何在手机端用 Ollama 跑大模型
有小伙伴问:为啥要选择 Ollama?
不用 Ollama,还能用啥?据猴哥所知,当前大模型加速的主流工具有:Ollama、vLLM、llama.cpp 等。
那我到底该用哪个呢?
今日分享:带大家在手机端分别跑通 Ollama、vLLM、llama.cpp,并给出评测结论。
友情提醒:本文实操,请确保已在手机端准备好 Linux 环境,具体参考上篇教程。
1. 三者区别
以下是我对三者的简单认识:
- llama.cpp:基于C++重写了 LLaMa 的推理代码,是一种推理框架。支持动态批处理,支持混合推理。
- Ollama:利用了 llama.cpp 提供的底层能力(如量化),小白易上手。
- vLLM:基于Python,采用PagedAttention高效管理注意力KV内存,支持动态批处理。
此外,三者的模型权重存储也不同:
-
llama.cpp:只支持 gguf 格式的模型,可以自己生成或从 huggingface 等平台下载 gguf 格式的模型;
-
Ollama:支持从项目的 Library 下载,也可以自己生成,有自己的存储格式;
-
vLLM:支持从 huggingface/modelscope 等平台下载的模型文件。
Qwen2 对这3个方案都有支持,为此本文将以 qwen2:0.5b 进行实测。
2. Ollama
项目地址:https://github.com/ollama/ollama
如何安装 Ollama,之前的教程已经介绍得很详细了:本地部署大模型?Ollama 部署和实战,看这篇就够了。
上篇中我们采用的是 Ollama+OpenWebUI 的镜像,如果端侧不需要 webui,可以用官方最新镜像,拉起一个容器:
sudo docker run -d -v ollama:/root/.ollama -p 1002:11434 --restart unless-stopped --name ollama ollama/ollama
注意:因为官方镜像托管在 docker.hub,国内下载会失败👇

如果你也遇到docker 镜像下载失败的问题,一定记得打开代理!关于如何配置docker镜像代理,我打算单独开一篇教程,敬请期待!
进入容器,运行 qwen2:0.5b:
sudo docker exec -it ollama /bin/bash
ollama run qwen2:0.5b
然后,查看 ollama 的 server api 是否成功启动:
netstat -ntlp
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp6 0 0 :::11434 :::* LISTEN 1/ollama
没问题,在宿主机上,写一个测试用例吧:
def test_ollama():
url = 'http://localhost:1002/api/chat'
data = {
"model": "qwen2:0.5b",
"messages": [
{ "role": "user", "content": "你好" }
],
"stream": False
}
response = requests.post(url, json=data)
print(response.text)
返回示例如下:
{"model":"qwen2:0.5b","created_at":"2024-09-15T01:31:49.502405293Z","message":{"role":"assistant","content":"你好!有什么问题或需要帮助的地方吗?我很乐意回答您的问题。"},"done_reason":"stop","done":true,"total_duration":1052511042,"load_duration":94924636,"prompt_eval_count":9,"prompt_eval_duration":52884000,"eval_count":17,"eval_duration":900186000}
3. vLLM
项目地址:https://github.com/vllm-project/vllm
支持的模型列表:https://docs.vllm.ai/en/latest/models/supported_models.html
vLLM 的安装较为复杂,pip 包的安装方式,需要你的环境中支持 CUDA 12.1:
pip install vllm
显然在端侧无法搞定,为此只能选择源码安装,这里一路踩了不少坑,分享出来,供小伙伴们参考。
3.1 camke 版本问题
参考官方文档进行安装:https://docs.vllm.ai/en/latest/getting_started/cpu-installation.html
如果安装过程中遇到报错:
CMake Error at CMakeLists.txt:1 (cmake_minimum_required):
CMake 3.26 or higher is required. You are running version 3.16.3
看看你的 cmake 版本,低于 3.26 就得重新安装:
camke --version
前往https://cmake.org/download/,找到最新版 cmake:
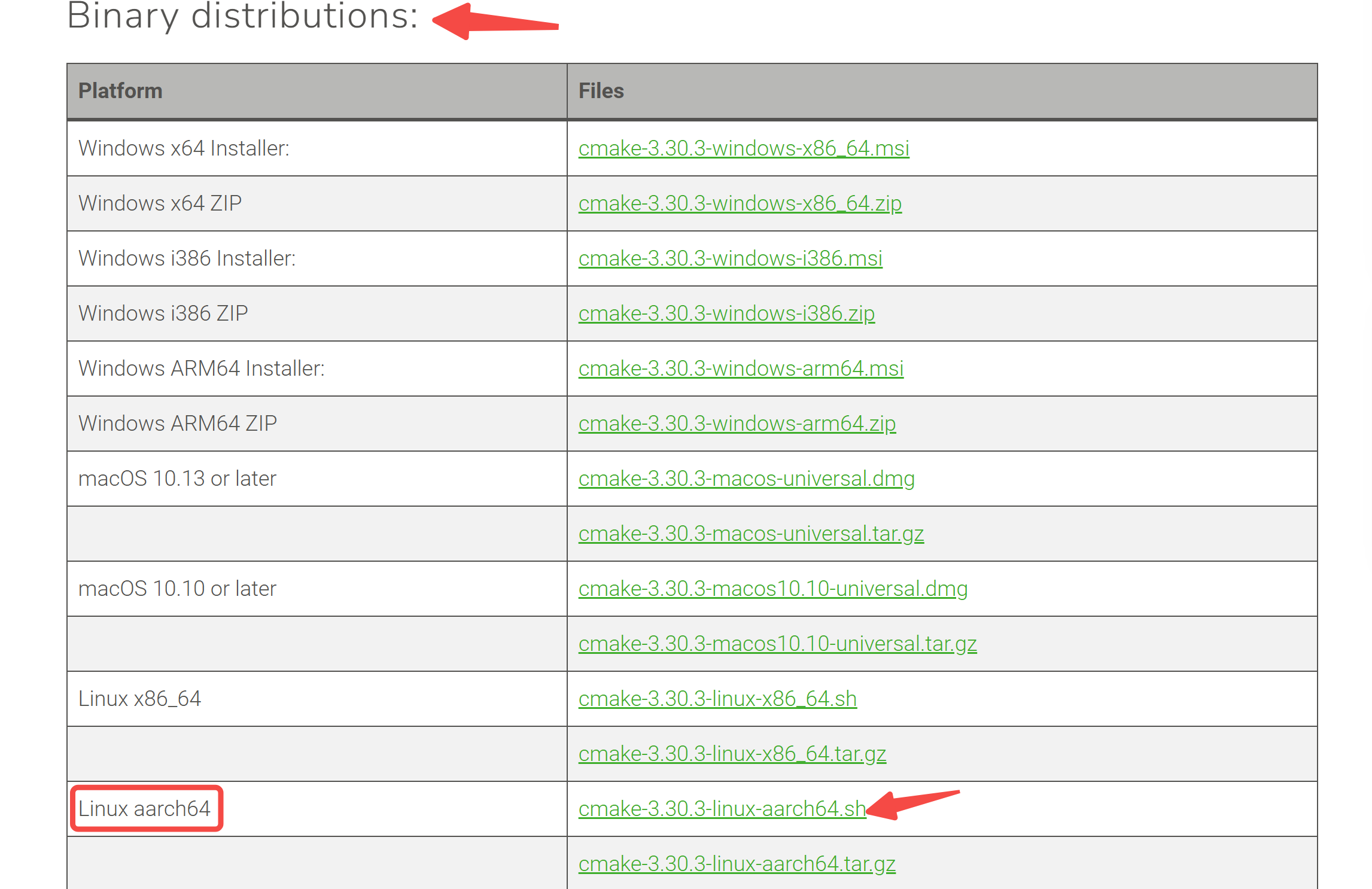
一键安装,并添加到系统环境变量:
sh cmake-3.30.3-linux-aarch64.sh
export PATH=/home/aidlux/tools/cmake-3.30.3-linux-aarch64/bin:$PATH
3.2 指令集问题
最后一步,安装 vLLM:
VLLM_TARGET_DEVICE=cpu python setup.py install
报错了:
CMake Error at cmake/cpu_extension.cmake:82 (message):
vLLM CPU backend requires AVX512 or AVX2 or Power9+ ISA support.
可以发现,vLLM 项目对硬件的要求很高,需要 CPU 支持 AVX512、AVX2 或 Power9+ 高级指令集,而对于 ARM 架构 的 CPU,通常并不支持 AVX2 和 AVX512,这两是 Intel 和 AMD CPU 的扩展指令集。
无解了!
只好放弃 vLLM~
4. llama.cpp
4.1 下载项目并编译
执行如下指令:
git clone https://github.com/ggerganov/llama.cpp
cd llama.cpp/
make
在目录下会生成一系列可执行文件,比如:
- llama-cli:用于推理模型;
- llama-quantize:用于量化模型;
- llama-server:提供模型 API 服务
4.2 下载模型并转换
首先准备环境:
conda create -n llamacpp python=3.12
conda activate llamacpp
pip install -r requirements.txt
下载模型到 models/ 目录下:
cd models
sudo apt-get install git-lfs
# or
git lfs install
git clone https://www.modelscope.cn/qwen/Qwen2-0.5B-Instruct.git
如果下载地址中没有 GGUF 格式的文件,需执行模型转换脚本:
python convert_hf_to_gguf.py models/Qwen2-0.5B-Instruct/
当然,如果下载的模型有 GGUF 格式的版本,直接使用即可。
4.3 推理测试
指定模型地址:
./llama-cli -m models/Qwen2-0.5B-Instruct/Qwen2-0.5B-Instruct-F
16.gguf -p hello -n 256
有输出就没问题!
4.4 OpenAI API
执行如下指令,会拉起一个 REST API服务,且兼容 OpenAI 格式!
./llama-server -m models/Qwen2-0.5B-Instruct/Qwen2-0.5B-Instruct-F16.gguf --host 0.0.0.0 --port 2001
# 放到后台运行
nohup ./llama-server -m models/Qwen2-0.5B-Instruct/Qwen2-0.5B-Instruct-F16.gguf --host 0.0.0.0 --port 2001 > log.txt 2>&1 &
为此,调用示例代码如下:
from openai import OpenAI
client = OpenAI(api_key='xx', base_url='http://localhost:2001/v1')
completion = client.chat.completions.create(
model='qwen2',
messages=[{'role': 'user', 'content': '为什么天空是蓝色的'}],
stream=False
)
print(completion.choices[-1].message.content)
api_key 和 model 随便填就行,因为只启动了一个模型。
5. Ollama 和 llama.cpp 评测对比
我们采用如下的提示词,分别调用 5 次:
messages = [{'role': 'user', 'content': '为什么天空是蓝色的'}]
评测代码如下:
import time
for i in range(5):
start_time = time.time()
text = test_ollama()
end_time = time.time()
print(f"第{i+1}次调用:{end_time-start_time}秒, token/s:{len(text)/(end_time-start_time)}")
注:这里并没有严格计算 token 数量,直接使用输出文本字数进行平均耗时对比。
Ollama 调用耗时:
第1次调用:9.803798913955688秒, token/s:26.214327961598745
第2次调用:10.22051048278808秒, token/s:26.90667951107877
第3次调用:16.36184406280517秒, token/s:25.36388920509305
第4次调用:12.29462456703186秒, token/s:26.596989458047645
第5次调用:7.711999416351318秒, token/s:27.87863281526547
llama.cpp 调用耗时:
第1次调用:18.27004337310791秒, token/s:11.932100846617535
第2次调用:18.72978639602661秒, token/s:15.750313098209284
第3次调用:15.97263455390930秒, token/s:14.149199948025263
第4次调用:7.018653631210327秒, token/s:14.39022429471037
第5次调用:21.80415105819702秒, token/s:15.409909750817134
从上述结果可以发现:同款模型,在不进行量化的前提下,Ollama 的速度是 llama.cpp 的近两倍!
写在最后
本文通过实测 Ollama / llama.cpp / vLLM,解答了端侧部署大模型该用哪款框架的问题。
不知大家用的什么方案,欢迎评论区交流。
如果对你有帮助,不妨点个免费的赞和收藏备用。
为方便大家交流,新建了一个 AI 交流群,欢迎感兴趣的小伙伴加入。
最近打造的微信机器人小爱(AI)也在群里,想进群体验的朋友,公众号后台「联系我」即可,拉你进群。






![[数据集][图像分类]茶叶病害分类数据集6749张7类别](https://i-blog.csdnimg.cn/direct/f0b1ccf3bbf1454e80c9c9efffb02e45.png)









