在之前的文章中,我们讲述了OrionX vGPU基于SSH模式、以及Jupyter模式下的最佳实践(文末附回顾链接~),今天,让我们走进CodeServer模式的最佳实践。
-
• CodeServer模式:微软的VSCode的服务器版本,近年很多企业在采用该工具,使用资源的方式类似Jupyter,也是部署在虚机或者容器当中。
环境准备
环境包含物理机器或者虚机,网络环境、GPU卡,操作系统以及容器平台。
硬件环境
本次POC环境准备三台虚机,其中一台CPU节点,两台GPU节点,每台GPU节点有一块T4卡。
操作系统为ubuntu 18.04
管理网络:千兆TCP
远程调用网络:100G RDMA
Kubernetes环境
三个节点安装K8S环境,可以使用kubeadm来安装,或者一些部署工具:
-
• kubekey
-
• kuboard-spray
当前部署kubernetes环境如下:
root@sc-poc-master-1:~# kubectl get node
NAME STATUS ROLES AGE VERSION
sc-poc-master-1 Ready control-plane,master,worker 166d v1.21.5
sc-poc-worker-1 Ready worker 166d v1.21.5
sc-poc-worker-2 Ready worker 166d v1.21.5其中master为CPU节点,worker节点为2个T4 GPU节点。
OrionX vGPU池化环境
参考趋动科技《OrionX 实施方案-K8S版》
部署完之后我们可以在OrionX的namespace查看OrionX组件:
root@sc-poc-master-1:~# kubectl get pod -n orion
NAME READY STATUS RESTARTS AGE
orion-container-runtime-hgb5p 1/1 Running 3 63d
orion-container-runtime-qmghq 1/1 Running 1 63d
orion-container-runtime-rhc7s 1/1 Running 1 46d
orion-exporter-fw7vr 1/1 Running 0 2d21h
orion-exporter-j98kj 1/1 Running 0 2d21h
orion-gui-controller-all-in-one-0 1/1 Running 2 87d
orion-plugin-87grh 1/1 Running 6 87d
orion-plugin-kw8dc 1/1 Running 8 87d
orion-plugin-xpvgz 1/1 Running 8 87d
orion-scheduler-5d5bbd5bc9-bb486 2/2 Running 7 87d
orion-server-6gjrh 1/1 Running 1 74d
orion-server-p87qk 1/1 Running 4 87d
orion-server-sdhwt 1/1 Running 1 74d开发机场景:Code Server模式
VScode 是目前非常流行的编辑器之一,深受越来越多的研发人员使用,但是他也有一些限制,比如环境的统一,随时随地的开发,受限于本地电脑的性能等问题,那么如何在享受VScode好用的同时解决以上问题呢,通过code-server web IDE的工具的方式。code-server 是 coder 公司基于微软开源的 Visual Studio Code 开发的一款产品。code-server 的目标是为开发者构建一个便捷统一的开发环境,让开发者能从任意设备、任意位置通过浏览器来进行代码的编写,从而免去了常规的 IDE 开发流程中的环境搭建的问题。
那么本节内容我们基于code-server结合OrionX vGPU打造一个在线云原生AI IDE开发环境,通过OrionX的能力进行动态的调用vGPU资源,实现GPU资源的分时复用,大大提高开发使用效率。
制作镜像
codeserver官方的镜像没有包含CUDA相关程序,所以我们根据自己的需要制作一个带CUDA的镜像,直接使用NVidia官方的CUDA镜像,dockerfile如下
# Dockerfile
FROM nvidia/cuda:11.2.2-cudnn8-devel-ubuntu20.04
# USER root
RUN rm /etc/apt/sources.list.d/cuda.list
RUN rm /etc/apt/sources.list.d/nvidia-ml.list
WORKDIR /root
RUN sed -i 's/archive.ubuntu.com/mirrors.aliyun.com/g' /etc/apt/sources.list
ENV LANG C.UTF-8
RUN apt-get update && DEBIAN_FRONTEND="noninteractive" TZ="Asia/Shanghai" apt-get -y install tzdata
# Install necessary packages
RUN apt-get update && apt-get install -y \
software-properties-common \
wget \
git \
curl \
&& apt-get clean \
&& rm -rf /var/lib/apt/lists/*
RUN add-apt-repository ppa:deadsnakes/ppa
RUN apt install -y python3.8
RUN apt install python3-pip -y
RUN pip install pip -U && pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
COPY install.sh /root/install.sh
RUN sh /root/install.sh
ENTRYPOINT ["code-server", "--host", "0.0.0.0", "/root/code"]
EXPOSE 8080
通过docker build -t codeserver:cuda-112-1 .生成镜像
部署codeserver
这里一样通过K8S来部署,yaml文件如下code-server-deployment.yaml:
apiVersion: v1
kind: Service
metadata:
name: code-server
spec:
ports:
- protocol: TCP
port: 80
targetPort: 8080
selector:
app: code-server
type: NodePort
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: code-server
spec:
selector:
matchLabels:
app: code-server
strategy:
type: Recreate
template:
metadata:
labels:
app: code-server
spec:
nodeName: sc-poc-worker-2
containers:
- image: codeserver:cuda-112-1
name: code-server
ports:
- containerPort: 8080
name: code-server
resources:
requests:
virtaitech.com/gpu: 1
limits:
virtaitech.com/gpu: 1
env:
- name : ORION_DRIVER_ONLY
value : "true"
- name : PASSWORD
value : "code123"
- name : ORION_GMEM
value : "10000"
- name : ORION_RATIO
value : "50"
- name: ORION_VGPU
value: "1"
- name: ORION_RESERVED
value: "0"
- name: ORION_CROSS_NODE
value: "1"
- name: ORION_CLIENT_ID
value: "orion"
- name : ORION_GROUP_ID
valueFrom:
fieldRef:
fieldPath: metadata.uid
- name: ORION_K8S_POD_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: ORION_K8S_POD_UID
valueFrom:
fieldRef:
fieldPath: metadata.uid1、为了方便,svc通过NodePort访问
2、设置了codeserver的访问密码为
code123,后续登录时需要3、同样设置了算力和显存的大小
通过kubectl create -f code-server-deployment.yaml部署,部署之后通过NodePort访问
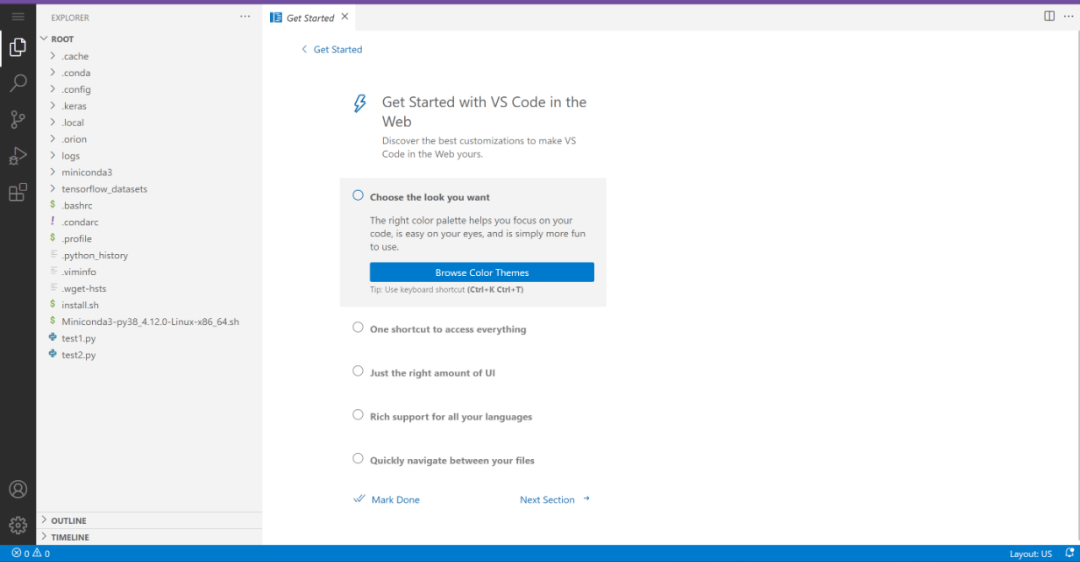
这样一个云原生AI IDE就诞生了,通过界面我们发现这跟VScode一模一样。
使用codeserver进行AI开发
-
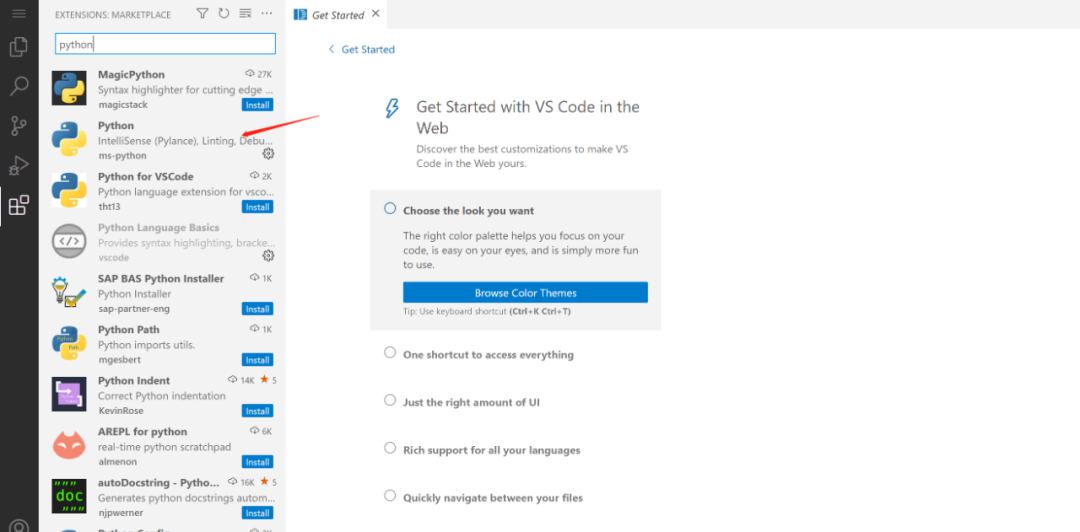
• 首先安装python的插件
通过搜索python,安装python的插件
-
• 安装TensorFlow
安装TensorFlow有多种方法,最常用的就是pip和conda,我们这里通过conda安装,我们在codeserver上通过terminal安装conda,打开terminal在清华大学的源上下载miniconda,
wget https://mirrors.tuna.tsinghua.edu.cn/anaconda/miniconda/Miniconda3-py38_4.12.0-Linux-x86_64.sh
./Miniconda3-py38_4.12.0-Linux-x86_64.sh通过conda创建一个自己的env环境
conda create -n penn-1
# 进入创建的env环境
conda activate penn-1在自己的env环境通过conda安装TensorFlow:
conda install tensorflow-gpu==2.6.2
conda install tensorflow-datasets-
• 测试
我们通过官方的测试用例进行测试,在codeserver创建一个文件,语言选择python,然后贴入以下代码:
import tensorflow as tf
import tensorflow_datasets as tfds
(ds_train, ds_test), ds_info = tfds.load(
'mnist',
split=['train', 'test'],
shuffle_files=True,
as_supervised=True,
with_info=True,
)
def normalize_img(image, label):
"""Normalizes images: `uint8` -> `float32`."""
return tf.cast(image, tf.float32) / 255., label
ds_train = ds_train.map(
normalize_img, num_parallel_calls=tf.data.AUTOTUNE)
ds_train = ds_train.cache()
ds_train = ds_train.shuffle(ds_info.splits['train'].num_examples)
ds_train = ds_train.batch(128)
ds_train = ds_train.prefetch(tf.data.AUTOTUNE)
ds_test = ds_test.map(
normalize_img, num_parallel_calls=tf.data.AUTOTUNE)
ds_test = ds_test.batch(128)
ds_test = ds_test.cache()
ds_test = ds_test.prefetch(tf.data.AUTOTUNE)
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(10)
])
model.compile(
optimizer=tf.keras.optimizers.Adam(0.001),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=[tf.keras.metrics.SparseCategoricalAccuracy()],
)
model.fit(
ds_train,
epochs=6,
validation_data=ds_test,
)官方的测试用例:https://www.tensorflow.org/datasets/keras_example
然后我们选择右上角的三角启动执行任务:
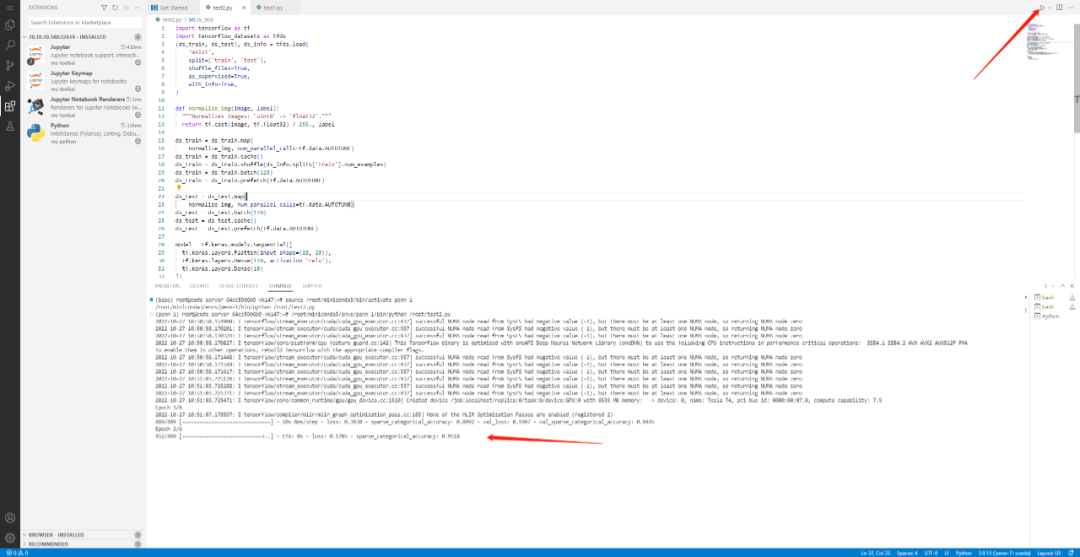
查看OrionX的UI界面,我们看到任务正在执行,同时也可以监控vGPU的资源利用率
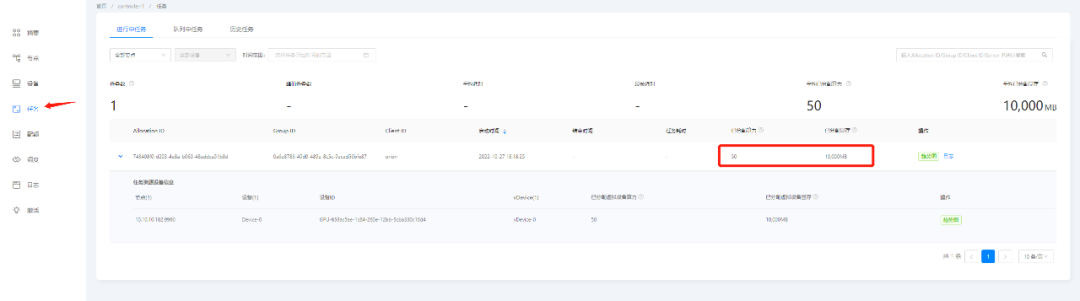
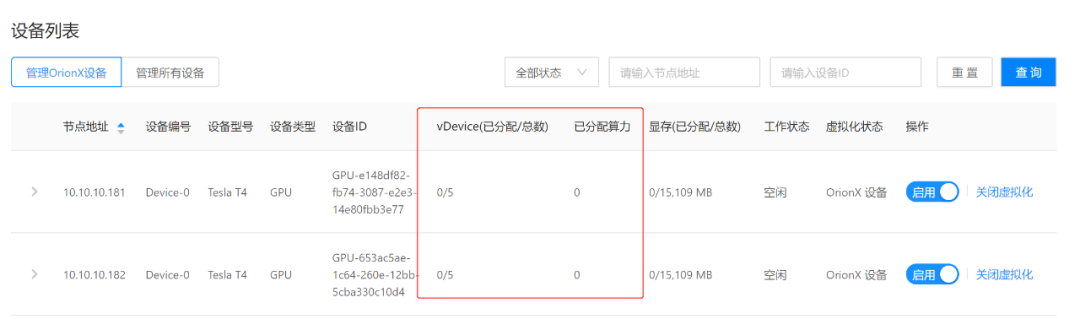
在任务执行完毕,资源自动释放。通过该方式我们同样在企业或者教学当中实现了GPU的分时复用,使得资源利用率大大提高。
以上就是OrionX vGPU在CodeServer模式下的开发机场景的最佳实践,OrionX AI算力资源池化解决方案针对GPU管理粗放给出了相应的解决思路,旨在为用户提高GPU利用率、提供灵活调度平台、统一管理算力资源,实现弹性扩展,按需使用。欢迎留言探讨!