摘要
主动对话在大语言模型(LLMs)时代中是一个实际且具有挑战性的对话问题,其中对话策略规划是提升LLMs主动性的重要关键。现有的大多数研究通过各种提示方案或使用口头AI反馈迭代增强处理特定案例的能力,以实现LLMs的对话策略规划。然而,这些方法要么受限于冻结状态下LLMs的策略规划能力,要么难以迁移到新案例中。在本研究中,我们引入了一种新的对话策略规划范式,旨在为主动对话问题制定策略,利用可调语言模型插件作为即插即用的对话策略规划器,命名为PPDPP(Plug-and-Play Dialogue Policy Planner)。
具体而言,我们开发了一个新颖的训练框架,既能在现有的人工标注数据上进行监督微调,也能通过基于目标的AI反馈和由LLM自我对话模拟收集的动态交互数据进行强化学习。通过这种方式,LLM驱动的对话代理不仅能够在训练后推广到不同的案例中,还可以通过简单替换已学习的插件,适用于不同的应用场景。
此外,我们还提出在交互设置下评估对话系统的策略规划能力。实验结果表明,在三种不同的主动对话应用场景(包括谈判、情感支持和辅导对话)中,PPDPP始终显著优于现有方法。
主要工作
本文的主要工作如下:
- 提出了一种新的对话策略规划范式,名为PPDPP(Plug-and-play Policy Dialogue Planner),用于为大语言模型(LLM)驱动的对话代理制定策略。PPDPP通过插拔式语言模型插件来执行对话策略规划,使LLM可以进行更灵活的对话管理。
- 开发了一个新的训练框架,该框架结合了有监督微调和基于自我博弈模拟的强化学习。通过人类注释数据的有监督微调和从目标导向的AI反馈中学习,增强了模型的策略规划能力。
- 该方法不仅能够在训练后推广到不同的对话案例,还能够通过替换学习到的插件应用于不同的领域和任务,而无需影响LLM的核心响应生成能力。
- 提出了在交互式环境中评估对话系统策略规划能力的方案,并在多个主动对话任务中验证了该框架的有效性。实验结果表明,PPDPP在谈判、情感支持和教学对话三个不同的主动对话任务上均显著优于现有方法 。
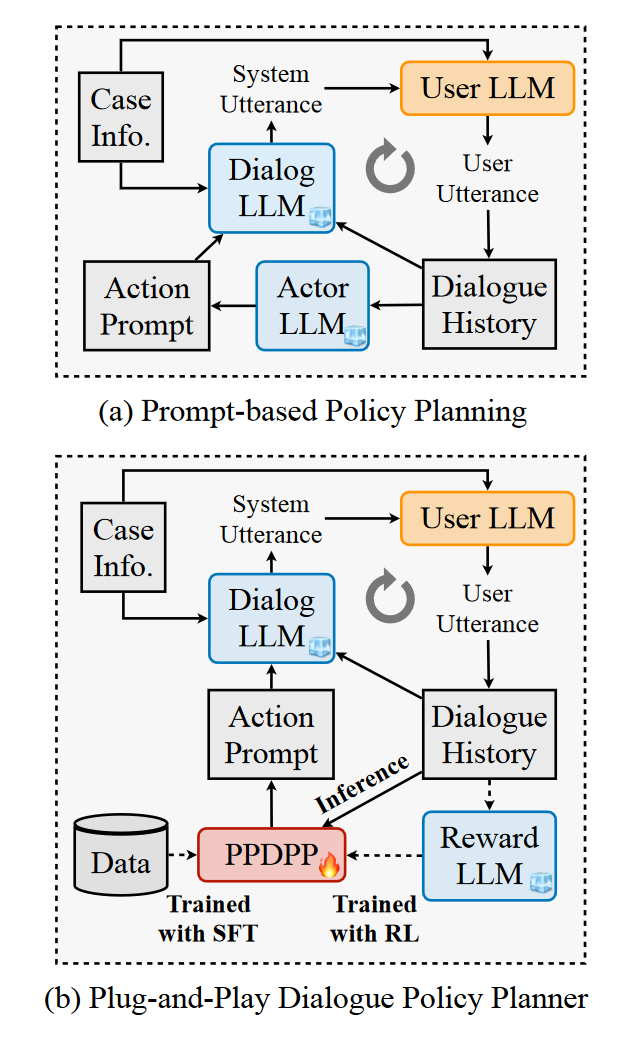
图 1:两种基于 LLM 的主动对话系统的架构。虚线将在推理阶段被遮挡。
介绍
论文引入了一种新颖的对话策略规划范式,利用一个可调的语言模型插件(命名为“即插即用对话策略规划器”PPDPP)来为大语言模型(LLM)制定策略。如图1(b)所示,PPDPP充当策略代理,预测对话代理在下一轮中应采取的对话策略。该策略首先可以通过现有的人类注释语料库进行有监督微调。然后,我们采用自我博弈范式,提示两个LLM(一个作为助手,一个作为用户)根据不同的案例背景信息进行角色扮演对话,以模拟对话代理和实际用户之间的多轮交互动态环境。对于每个案例,这两个LLM分别承担不同的,通常是相互竞争的目标(例如,在谈判对话中,买家试图获得更有利的价格,而卖家则希望达成更高的价格)。与此同时,第三个LLM作为奖励模型,提供目标导向的语言反馈,指示目标的完成情况,这些反馈将被转换为用于强化学习(RL)的标量奖励。当达到目标或达到最大对话轮次时,我们利用RL算法进一步调整策略代理,以收集的交互数据和目标导向的AI反馈为基础进行优化。通过这种方式,LLM驱动的对话代理不仅比基于提示的方法展现出更强的适应性,还可以通过简单地切换调优后的插件,在不影响LLM的上下文理解和响应生成能力的前提下,适用于各种不同的应用场景。
为了克服传统回合级别响应评价指标的限制,我们进一步提出了一种基于LLM的交互式评价方法,利用上述的LLM用户模拟器和奖励模型。这种方法能够模拟多样的用户与助手之间的交互,以评估成功率和达到指定目标的平均回合数。我们在三个不同的主动对话问题上进行了广泛的实验,包括谈判、情感支持和辅导对话。实验结果证明了所提出的PPDPP框架在现有LLM对话系统上的优越性,表明PPDPP能够有效且高效地引导对话以达成预定目标。
方法
MDP Environment(马尔可夫环境)
MDP 环境
我们将对话过程建模为马尔可夫决策过程(MDP)。在每个回合
t
t
t,根据对对话历史的观察,对话系统选择一个动作
a
t
∈
A
a_t \in A
at∈A,其中
A
A
A 是由领域专家预先定义的一组候选策略。随后,用户角色对该动作作出回应。这个过程一直重复,直到对话目标实现或达到最大回合数
T
T
T。目标是学习一个策略
π
\pi
π,以最大化在观察到的对话过程中累积奖励的期望值:
π ∗ = arg max π ∈ Π [ ∑ t = 0 T r ( s t , a t ) ] \pi^* = \arg \max_{\pi \in \Pi} \left[ \sum_{t=0}^{T} r(s_t, a_t) \right] π∗=argπ∈Πmax[t=0∑Tr(st,at)]
其中, s t s_t st 表示对话历史的状态, r ( ⋅ ) r(\cdot) r(⋅) 是中间奖励,表示为 r t r_t rt。
Plug-and-Play Dialogue Policy Planner(即插即用对话策略规划器)
如图 1(b) 所示,采用了一个较小的模型作为插件,用于控制LLM驱动的对话代理中的对话策略规划。我们使用一个可调的预训练语言模型,例如 RoBERTa(Liu et al., 2019),作为对话策略规划器,用于预测动作 a t a_t at。在进行交互式在线学习之前,可以通过现有的对话语料库 D \mathcal{D} D 进行有监督的微调(SFT) 来初始化PPDPP。具体来说,给定对话历史 { u 1 s y s , u 1 u s r , . . . , u t − 1 s y s , u t − 1 u s r } \{ u_1^{sys}, u_1^{usr}, ..., u_{t-1}^{sys}, u_{t-1}^{usr} \} {u1sys,u1usr,...,ut−1sys,ut−1usr} 作为当前状态 s t s_t st,SFT 过程旨在最小化预测的动作 a t a_t at 与每个标注回合 t t t 中的人工标注动作 y t y_t yt 之间的交叉熵损失:
a t = PPDPP ( u 1 s y s , u 1 u s r , . . . , u t − 1 s y s , u t − 1 u s r ) (2) a_t = \text{PPDPP}(u_1^{sys}, u_1^{usr}, ..., u_{t-1}^{sys}, u_{t-1}^{usr}) \tag{2} at=PPDPP(u1sys,u1usr,...,ut−1sys,ut−1usr)(2)
L c = − 1 ∣ D ∣ ∑ d ∈ D 1 T d ∑ t = 1 T d a t log y t (3) L_c = - \frac{1}{|\mathcal{D}|} \sum_{d \in \mathcal{D}} \frac{1}{T_d} \sum_{t=1}^{T_d} a_t \log y_t \tag{3} Lc=−∣D∣1d∈D∑Td1t=1∑Tdatlogyt(3)
其中, T d T_d Td 表示对话的轮次数。尽管基于语料的学习通常会导致次优策略,这样的初始化应该有助于加速交互式在线训练的收敛过程。
自我博弈互动
在交互式在线学习过程中,我们提示两个LLM分别作为用户和助手,进行自我博弈对话,模拟动态的用户-助手交互。每个LLM会接收到角色和相应对话目标的任务描述。例如,在情感支持对话中,患者(用户)将接收到关于情感问题原因的情境描述,而治疗师(助手)将接收到任务描述,帮助减少用户的情绪困扰并引导他们解决问题。在教学对话中,学生(用户)将接收到关于其知识状态的描述,而老师(助手)将接收到教授用户掌握特定练习的任务描述。
当轮到助手时,PPDPP首先基于互动历史预测下一个动作 a t a_t at。预测的动作会映射到一个预定义的自然语言指令 M a ( a t ) \mathcal{M}_a(a_t) Ma(at)。然后助手生成基于对话历史和自然语言动作指令的策略响应:
u t s y s = LLM s y s ( p s y s ; M a ( a t ) ; u 1 s y s , u 1 u s r , . . . , u t − 1 s y s , u t − 1 u s r ) (4) u_t^{sys} = \text{LLM}_{sys}(p_{sys}; \mathcal{M}_a(a_t); u_1^{sys}, u_1^{usr}, ..., u_{t-1}^{sys}, u_{t-1}^{usr}) \tag{4} utsys=LLMsys(psys;Ma(at);u1sys,u1usr,...,ut−1sys,ut−1usr)(4)
接着,用户角色基于更新的对话历史生成响应,其中包括 u t s y s u_t^{sys} utsys:
u t u s r = LLM u s r ( p u s r ; u 1 s y s , u 1 u s r , . . . , u t − 1 s y s , u t − 1 u s r , u t s y s ) (5) u_t^{usr} = \text{LLM}_{usr}(p_{usr}; u_1^{sys}, u_1^{usr}, ..., u_{t-1}^{sys}, u_{t-1}^{usr}, u_t^{sys}) \tag{5} utusr=LLMusr(pusr;u1sys,u1usr,...,ut−1sys,ut−1usr,utsys)(5)
其中, p s y s p_{sys} psys 和 p u s r p_{usr} pusr 是相应的提示词。这个过程会重复,直到达到终止状态。总体而言,在自我博弈互动中有三种状态:1) 进行中:对话仍在继续,尚未达到目标;2) 目标完成:指定的对话目标完成,例如解决寻求者的情感问题或学生掌握练习;3) 目标失败:如果对话达到最大回合数但未能完成目标,则被视为失败。
LLM作为奖励模型
我们引入了第三个LLM作为奖励模型,命名为 L L M r w d LLM_{rwd} LLMrwd,它有两个功能:(1)在对话过程中确定目标的完成情况;(2)通过标量奖励评估策略结果。具体来说,我们提示奖励模型回答一个多选问题,以生成目标导向的AI反馈。我们进一步定义了一个映射 M r ( ⋅ ) \mathcal{M}_r(\cdot) Mr(⋅) 来将语言反馈转换为标量奖励。
由于规划结果的主观性以及LLM生成的输出的差异性,我们遵循一种常见做法(Wang等,2023e),通过对奖励LLM生成的序列进行采样来缓解这些问题。一般来说,我们通过对目标导向的AI反馈采样 l l l 次,获得标量值 v t v_t vt,并将其转换为标量值,具体计算公式为:
v t = 1 l ∑ i = 1 l M r ( LLM r w d ( p r w d ; u 1 s y s , u 1 u s r , . . . , u t − 1 s y s , u t − 1 u s r , u t s y s , u t u s r ; τ ) ) (6) v_t = \frac{1}{l} \sum_{i=1}^{l} \mathcal{M}_r \left( \text{LLM}_{rwd}(p_{rwd}; u_1^{sys}, u_1^{usr}, ..., u_{t-1}^{sys}, u_{t-1}^{usr}, u_t^{sys}, u_t^{usr}; \tau) \right) \tag{6} vt=l1i=1∑lMr(LLMrwd(prwd;u1sys,u1usr,...,ut−1sys,ut−1usr,utsys,utusr;τ))(6)
其中, p r w d p_{rwd} prwd 是提示词。我们首先使用 v t v_t vt 来确定自我博弈互动的状态。如果 v t v_t vt 不低于某一阈值 ϵ \epsilon ϵ,我们将状态视为目标完成。如果对话达到终止状态,包括目标完成和目标失败,我们将获得奖励 r t = v t r_t = v_t rt=vt。如果没有完成目标,我们会给予一个小的负奖励,例如, r t = − 0.1 r_t = -0.1 rt=−0.1,以惩罚对话过长,从而促进更高效的目标完成。
强化学习
当达到目标或对话达到最大轮次时,我们获得目标导向的奖励 r t r_t rt。我们将策略代理表示为 π ( a t ∣ s t ) \pi(a_t|s_t) π(at∣st),其返回在状态 s t s_t st 下采取动作 a t a_t at 的概率。为了优化策略代理,我们使用简单的策略梯度方法(Sutton等,1999),公式如下:
θ ← θ − α ∇ log π θ ( a t ∣ s t ) R t (7) \theta \leftarrow \theta - \alpha \nabla \log \pi_{\theta}(a_t|s_t) R_t \tag{7} θ←θ−α∇logπθ(at∣st)Rt(7)
其中, θ \theta θ 表示策略网络的参数, α \alpha α 表示策略网络的学习率, R t R_t Rt 是从第 t t t 轮到最后一轮 T T T 的累积总奖励:
R t = ∑ t ′ = t T γ T − t ′ r t ′ R_t = \sum_{t'=t}^{T} \gamma^{T-t'} r_{t'} Rt=t′=t∑TγT−t′rt′
其中, γ \gamma γ 是用于折扣未来奖励相对于即时奖励的折扣因子。
在推理过程中,调优后的PPDPP直接基于对话历史提供动作提示,引导对话LLM生成下一轮的响应,而奖励LLM则不会使用(如图1(b)所示)。通过这种方式,使用调优后的PPDPP的LLM驱动对话代理可以直接应用于不同的新情况,无需为每个新案例进行多次迭代模拟。
方法分析
推理阶段工作流程
在推理阶段,经过训练的 PPDPP 作为对话策略规划器,指导 LLM(大型语言模型)驱动的对话代理与真实用户进行交互。整个过程不再使用奖励模型 L L M r w d LLM_{rwd} LLMrwd
具体流程如下:
-
初始化对话: 对话开始时,系统准备好初始的对话历史 s t s_t st,可能为空或包含初始信息。
-
策略规划器预测动作:
- 输入: 对话历史 s t s_t st(包括系统和用户的所有前述话语)。
- 过程: PPDPP(如使用经过微调的 RoBERTa)根据 s t s_t st 预测下一步应采取的策略动作 a t a_t at。
- 输出: 动作 a t a_t at,例如 “询问用户需求”、“提供建议” 等。
-
动作映射为指令:
- 将预测的动作 a t a_t at 映射为预定义的自然语言指令 M a ( a t ) \mathcal{M}_a(a_t) Ma(at),例如将动作 “询问用户需求” 映射为指令 “请询问用户他们目前面临的主要问题是什么。”
-
LLM 生成系统回复:
- 输入:
- L L M s y s LLM_{sys} LLMsys(系统的 LLM),如 GPT-4。
- 提示词 p s y s p_{sys} psys。
- 自然语言动作指令 M a ( a t ) \mathcal{M}_a(a_t) Ma(at)。
- 对话历史 s t s_t st。
- 过程: LLM_{sys} 基于 M a ( a t ) \mathcal{M}_a(a_t) Ma(at) 和 s t s_t st 生成系统的下一轮回复 u t s y s u_t^{sys} utsys。
- 输出: 系统回复 u t s y s u_t^{sys} utsys。
- 输入:
-
与用户交互:
- 用户回复: 真实用户阅读 u t s y s u_t^{sys} utsys 后,生成他们的回复 u t u s r u_t^{usr} utusr。
- 更新对话历史: 将 u t s y s u_t^{sys} utsys 和 u t u s r u_t^{usr} utusr 添加到对话历史 s t s_t st 中,形成新的状态 s t + 1 s_{t+1} st+1。
-
循环迭代: 重复步骤 2 至 5,直到对话达到终止条件,例如目标完成或达到最大回合数。
注意事项:
- 无奖励模型参与: 在推理阶段,奖励模型 L L M r w d LLM_{rwd} LLMrwd 不参与对话过程,因为策略规划器已经在训练阶段学会了如何选择合适的策略。
- 灵活适应新场景: 通过更换 PPDPP,可以在不影响 LLM 核心响应生成能力的情况下,适用于不同的应用场景。
训练阶段工作流程
训练阶段包括有监督微调和基于自我博弈的强化学习两部分。整个流程旨在优化策略规划器,使其能够在与用户的交互中选择最佳策略,达到预定的对话目标。
具体流程如下:
1. 有监督微调(Supervised Fine-Tuning,SFT)
目的: 初始化 PPDPP,使其具备基本的策略预测能力,加速后续强化学习的收敛。
流程:
- 数据准备: 使用现有的人类注释对话语料库 D \mathcal{D} D,其中每一轮对话都有人工标注的策略动作 y t y_t yt。
- 训练:
- 输入: 对话历史 s t s_t st,对应的人工标注动作 y t y_t yt。
- 过程: 最小化预测动作
a
t
a_t
at 与
y
t
y_t
yt 之间的交叉熵损失:
L c = − 1 ∣ D ∣ ∑ d ∈ D 1 T d ∑ t = 1 T d a t log y t L_c = - \frac{1}{|\mathcal{D}|} \sum_{d \in \mathcal{D}} \frac{1}{T_d} \sum_{t=1}^{T_d} a_t \log y_t Lc=−∣D∣1d∈D∑Td1t=1∑Tdatlogyt - 输出: 初始化后的策略规划器 PPDPP。
2. 基于自我博弈的强化学习(Reinforcement Learning via Self-Play)
目的: 通过模拟动态的用户-助手交互,收集数据,进一步优化策略规划器。
流程:
2.1 自我博弈互动
- 角色设定:
- L L M _ s y s LLM\_{sys} LLM_sys(助手): 扮演对话系统,具有特定的对话目标。
- L L M _ u s r LLM\_{usr} LLM_usr(用户): 扮演用户,具有相应的目标或情境描述。
- 交互过程:
- 助手回合:
- 策略预测: PPDPP 根据当前对话历史 s t s_t st 预测下一步动作 a t a_t at。
- 动作映射: 将 a t a_t at 映射为自然语言指令 M a ( a t ) \mathcal{M}_a(a_t) Ma(at)。
- 生成回复: L L M s y s LLM_{sys} LLMsys 基于 M a ( a t ) \mathcal{M}_a(a_t) Ma(at) 和 s t s_t st 生成系统回复 u t s y s u_t^{sys} utsys。
- 用户回合:
- 生成回复: L L M u s r LLM_{usr} LLMusr 基于更新的对话历史 s t s_t st(包括 u t s y s u_t^{sys} utsys)生成用户回复 u t u s r u_t^{usr} utusr。
- 更新对话历史: 将 u t s y s u_t^{sys} utsys 和 u t u s r u_t^{usr} utusr 添加到 s t s_t st,形成新的状态 s t + 1 s_{t+1} st+1。
- 判断终止: 根据对话是否达到目标、达到最大回合数等条件,判断是否终止。
- 助手回合:
2.2 LLM 作为奖励模型
- 目的: 评估策略效果,提供强化学习的奖励信号。
- 过程:
- 生成反馈:
- 输入: 对话历史 s t s_t st,包括最新的系统和用户回复。
- 过程: 奖励模型 LLM_{rwd} 被提示回答一个与对话目标相关的多选问题,生成目标导向的 AI 反馈。
- 采样多次: 为了减少主观性和输出差异性,对 LLM_{rwd} 的输出进行 l l l 次采样。
- 映射奖励: 将语言反馈通过映射函数
M
r
(
⋅
)
\mathcal{M}_r(\cdot)
Mr(⋅) 转换为标量奖励
v
t
v_t
vt:
v t = 1 l ∑ i = 1 l M r ( LLM r w d ( ⋅ ) ) v_t = \frac{1}{l} \sum_{i=1}^{l} \mathcal{M}_r \left( \text{LLM}_{rwd}(\cdot) \right) vt=l1i=1∑lMr(LLMrwd(⋅)) - 判定状态:
- 目标完成: 如果 v t ≥ ϵ v_t \geq \epsilon vt≥ϵ(阈值),则视为目标完成。
- 目标失败: 如果达到最大回合数且未完成目标,则视为目标失败。
- 给予奖励:
- 目标完成或失败: r t = v t r_t = v_t rt=vt。
- 继续对话: r t = − 0.1 r_t = -0.1 rt=−0.1,以惩罚过长的对话。
- 生成反馈:
2.3 强化学习更新策略
- 目的: 基于累积奖励优化策略规划器,使其选择能最大化预期累积奖励的动作。
- 过程:
- 计算累积奖励:
R t = ∑ t ′ = t T γ T − t ′ r t ′ R_t = \sum_{t'=t}^{T} \gamma^{T-t'} r_{t'} Rt=t′=t∑TγT−t′rt′
其中, γ \gamma γ 是折扣因子。 - 策略梯度更新:
θ ← θ − α ∇ log π θ ( a t ∣ s t ) R t \theta \leftarrow \theta - \alpha \nabla \log \pi_{\theta}(a_t|s_t) R_t θ←θ−α∇logπθ(at∣st)Rt
其中, θ \theta θ 为策略网络参数, α \alpha α 为学习率。
- 计算累积奖励:
2.4 循环迭代
- 重复步骤 2.1 至 2.3: 不断进行自我博弈互动,收集数据,更新策略。
- 直到收敛: 当策略规划器的性能满足预期,或达到训练迭代次数,停止训练。
总结
-
推理阶段:
- 使用训练好的 PPDPP 作为策略规划器,根据对话历史预测动作,指导 LLM 生成系统回复。
- 与真实用户交互, 不再使用奖励模型。
- 灵活适应不同场景, 通过更换 PPDPP,可应用于不同的任务。
-
训练阶段:
- 有监督微调: 初始化策略规划器,使其具备基本策略预测能力。
- 自我博弈互动: 模拟用户和助手的对话,收集交互数据。
- 奖励模型评估: 使用 L L M r w d LLM_{rwd} LLMrwd 评估对话效果,提供奖励信号。
- 强化学习优化: 基于累积奖励,更新策略规划器参数。
- 循环迭代: 持续进行自我博弈和策略优化,直到策略性能稳定。
通过上述流程,PPDPP 能够有效地学习对话策略,在推理阶段指导 LLM 生成有策略的回复,提升对话代理的主动性和目标完成效率。