在不查询格式情况下分析确定 Intel HEX 格式
Hex文件内容
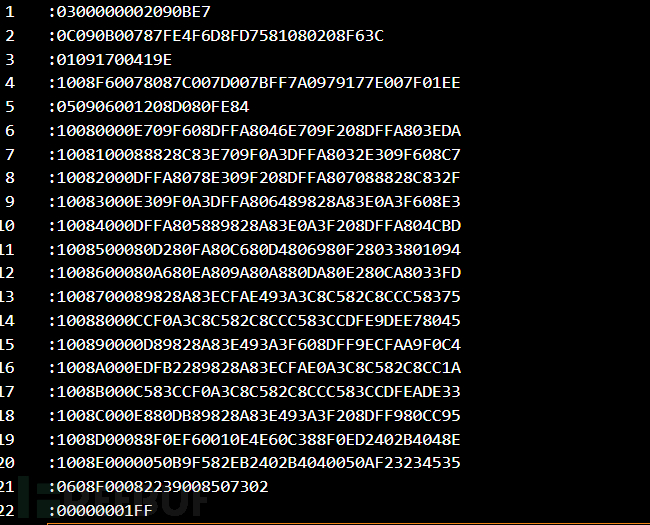
:0300000002090BE7
:0C090B00787FE4F6D8FD7581080208F63C
:01091700419E
:1008F60078087C007D007BFF7A0979177E007F01EE
:050906001208D080FE84
:10080000E709F608DFFA8046E709F208DFFA803EDA
:1008100088828C83E709F0A3DFFA8032E309F608C7
:10082000DFFA8078E309F208DFFA807088828C832F
:10083000E309F0A3DFFA806489828A83E0A3F608E3
:10084000DFFA805889828A83E0A3F208DFFA804CBD
:1008500080D280FA80C680D4806980F28033801094
:1008600080A680EA809A80A880DA80E280CA8033FD
:1008700089828A83ECFAE493A3C8C582C8CCC58375
:10088000CCF0A3C8C582C8CCC583CCDFE9DEE78045
:100890000D89828A83E493A3F608DFF9ECFAA9F0C4
:1008A000EDFB2289828A83ECFAE0A3C8C582C8CC1A
:1008B000C583CCF0A3C8C582C8CCC583CCDFEADE33
:1008C000E880DB89828A83E493A3F208DFF980CC95
:1008D00088F0EF60010E4E60C388F0ED2402B4048E
:1008E0000050B9F582EB2402B4040050AF23234535
:0608F00082239008507302
:00000001FF
返回Keil中分析反汇编程序
机器码为02090B
在第一行中
:03000000-02090B-E7

而在第二行090B作为段地址,由此推断第二个位置是存放2Bytes的地址的
:0C-090B-00787FE4F6D8FD7581080208F6-3C
跟进地址090B后发现首个机器码是
C:0x090B 787F MOV R0,#0x7F0850EB - 1
所以现在需要分隔00
:0C-090B-00-787FE4F6D8FD7581080208F6-3C
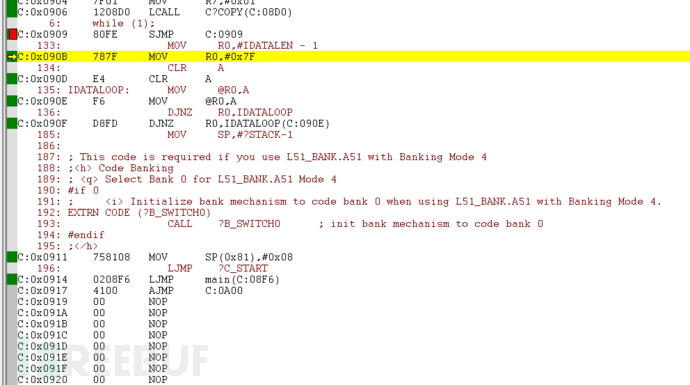
仔细发现前0C似乎是一个长度大小,转为10进制为12。计算载荷长度为24,由此推断0C是12Bytes。

现在确定了每一段的结构
:<载荷长度>:<段地址>:<类型>:<载荷>:<校验>
def parse_hex_file(hex_file_path):
"""Parse Intel HEX file and return a list of (address, data_bytes) tuples."""
records = []
try:
with open(hex_file_path, 'r') as file:
for line in file:
line = line.strip()
if not line or line[0] != ':':
continue
record_length = int(line[1:3], 16)
address = int(line[3:7], 16)
record_type = int(line[7:9], 16)
data = line[9:9 + record_length * 2]
checksum = int(line[9 + record_length * 2:11 + record_length * 2], 16)
if record_type == 0x00: # Data record
data_bytes = bytearray.fromhex(data)
records.append((address, data_bytes))
elif record_type == 0x01: # End of File record
break
except Exception as e:
print(f"Error reading file: {e}")
return records
def hex_to_assembly(data_bytes, start_address):
"""Convert a byte array to C51 assembly code."""
assembly_code = []
i = 0
while i < len(data_bytes):
opcode = data_bytes[i]
if opcode == 0x02 and i + 2 < len(data_bytes): # LJMP addr
addr = (data_bytes[i + 1] << 8) | data_bytes[i + 2]
assembly_code.append(f"LJMP {addr:04X}")
i += 3
elif opcode == 0x78: # MOV R0, #data
data = data_bytes[i + 1]
assembly_code.append(f"MOV R0, #{data:02X}")
i += 2
elif opcode == 0xE4: # CLR A
assembly_code.append("CLR A")
i += 1
elif opcode == 0xF6: # MOV @R0, A
assembly_code.append("MOV @R0, A")
i += 1
elif opcode == 0xD8 and i + 2 < len(data_bytes): # DJNZ R0, addr
addr = (data_bytes[i + 1] << 8) | data_bytes[i + 2]
assembly_code.append(f"DJNZ R0, {addr:04X}")
i += 3
elif opcode == 0x75 and i + 2 < len(data_bytes): # MOV Rn, data
reg = data_bytes[i + 1]
data = data_bytes[i + 2]
assembly_code.append(f"MOV R{reg}, #{data:02X}")
i += 3
elif opcode == 0x80 and i + 1 < len(data_bytes): # SJMP addr
offset = data_bytes[i + 1]
address = start_address + i + 2 + offset
assembly_code.append(f"SJMP {address:04X}")
i += 2
elif opcode == 0x90 and i + 1 < len(data_bytes): # NOP
assembly_code.append("NOP")
i += 1
else:
# Handle other opcodes or unknown opcodes
assembly_code.append(f"DB {opcode:02X}") # Unknown opcode
i += 1
return assembly_code
def main():
hex_file_path = "test.hex" # Path to your .hex file
data_records = parse_hex_file(hex_file_path)
for address, data_bytes in data_records:
print(f"Address: {address:04X}")
assembly_code = hex_to_assembly(data_bytes, address)
for line in assembly_code:
print(f" {line}")
if __name__ == "__main__":
main()
通过以上简单的程序可以进行反汇编
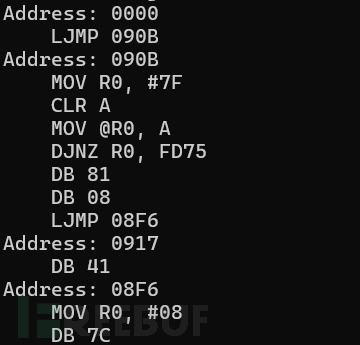
反汇编
除了使用IDA Pro反汇编,如果你没有IDA正版激活,还可以使用免费版的8051 Disassembler
https://www.spicelogic.com/Products/8051-disassembler-1
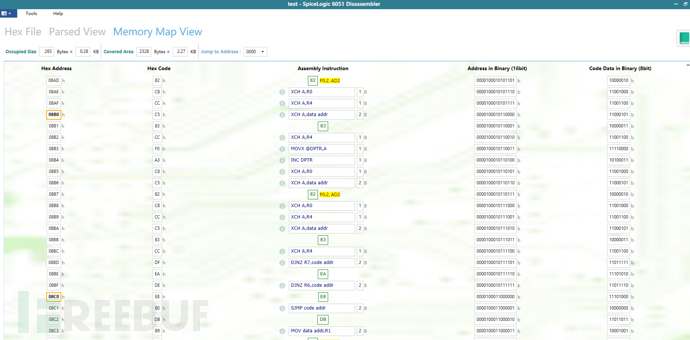
利用场景:LCD解锁系统,若密码忘记,则可以通过仅存在hex文件,来反汇编分析出解锁密码。